自动驾驶中VLM 与 VLA 的核心区别
- 2026-03-12 13:26:25

VLM(视觉 - 语言模型,Vision–Language Model),而 VLA 指的是视觉 - 语言 - 动作模型(Vision-Language-Action)。当下自动驾驶正朝着高阶智能化发展,多模态大模型成了解决复杂路况感知与决策难题的核心技术,VLM 和 VLA 就是其中的关键代表。二者都实现了视觉与语言的跨模态融合,但在模型定位、架构设计、实际落地应用等方面有着本质区别,这一区别也恰恰体现了自动驾驶从 “能认知理解” 到 “会行动执行” 的;技术演进。下面就从各个维度,把这两者的区别和内在关联讲清楚。
01#
VLM:自动驾驶的 “认知大脑”,主打 “看懂 + 说清楚”
简单来说,VLM 是把视觉和语言能力深度融合的多模态基础模型,它的核心目标就是让自动驾驶系统能理解视觉场景和语言信息之间的关联,还能通过自然语言把这种理解表达出来、完成信息交互。可以说,它是连接 “环境感知” 和 “决策执行” 的认知桥梁,也是让自动驾驶从单纯的 “视觉识别” 升级到 “语义化理解” 的关键所在。
VLM 的架构设计核心围绕视觉 - 语言的跨模态对齐展开,主要分三大模块,而且整个流程都是基于 Transformer 架构做端到端训练的。视觉编码器这块,一般用 CNN(卷积神经网络)或者近些年兴起的 ViT(视觉 Transformer),对道路的图像、视频做分层处理,提取出车辆、行人、交通标志、路面文字这些视觉特征,再把它们编码成计算机能识别的向量,不管是晴天、雨雪天还是夜晚,都能完成全场景的特征提取;语言编解码器则是处理自然语言,不管是交通规则、用户的语音指令还是场景描述,都会先拆分成 Token,再学习这些 Token 之间的语义关联,最终完成语言的输入和生成;而跨模态注意力模块是 VLM 的核心关键,能让语言解码器在生成每个文字 Token 时,自动聚焦到图像里最相关的区域。比如识别 “前方施工” 的提示时,模型会重点关注黄色施工牌、交通锥这些视觉特征,确保视觉信息和语言表达高度匹配。
为了让VLM 适配自动驾驶的车载场景,训练会分两步走:先做预训练,利用互联网上海量的图文数据,让模型掌握通用的视觉 - 语言对应关系;再做领域微调,用自动驾驶专属的数据集,涵盖城市道路、高速、施工区域等不同场景,让模型能精准理解交通场景的语义。
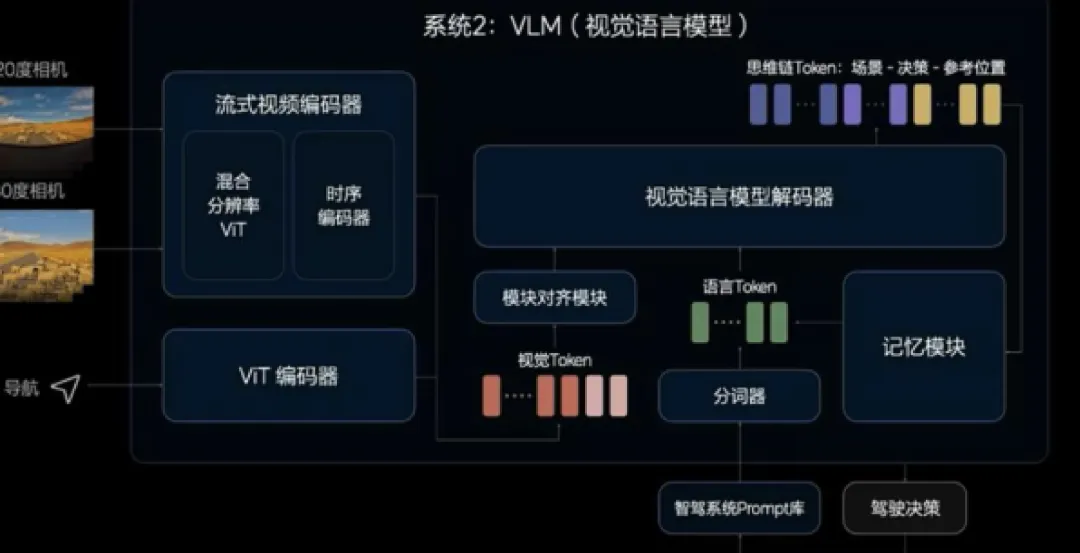
在自动驾驶的实际应用中,VLM 并不直接参与车辆控制,而是给决策系统提供语义化的环境信息和交互能力,算是系统的 “感知理解中枢”。比如车辆行驶中遇到积水、施工、落石这些危险场景,VLM 能识别出来,生成 “前方积水较深,请绕行” 这类自然语言提示,通过车载语音或仪表盘告诉驾驶员;面对那些带文字的交通标识,它不仅能识别图形,还能解析 “限高 3.5 米”“公交车道 7:00-19:00 限行” 这类文字信息,再把信息结构化传递给决策模块;乘客通过语音助手问 “下一个路口能左转吗”“哪条车道能避开拥堵”,VLM 也能结合实时图像和地图数据给出精准的文字回复。
当然,VLM 在车载部署上也有自己的一套逻辑,一般用 “边缘 - 云协同” 的架构:云端完成大规模的预训练和定期微调,再通过 OTA 把优化后的模型权重下发到车端;车端则部署经过剪枝、量化、蒸馏后的轻量级模型,依靠车载 GPU 或 NPU 实现毫秒级的推理。为了保证安全性,系统还会用模型集成、贝叶斯深度学习计算输出的置信度,一旦识别出错,就退回传统多传感器融合的结果。不过 VLM 落地也有几个绕不开的挑战:一是基于开源大语言模型训练的 VLM,在 3D 空间理解和驾驶专业知识上还有欠缺;二是车端芯片的内存带宽和算力有限,限制了模型的参数量,复杂推理很难实现;三是作为独立模型,它和端到端决策系统的协同训练、优化效率都比较低。
02#
VLA:自动驾驶的 “行动中枢”,实现 “看懂 + 听懂 + 做对”
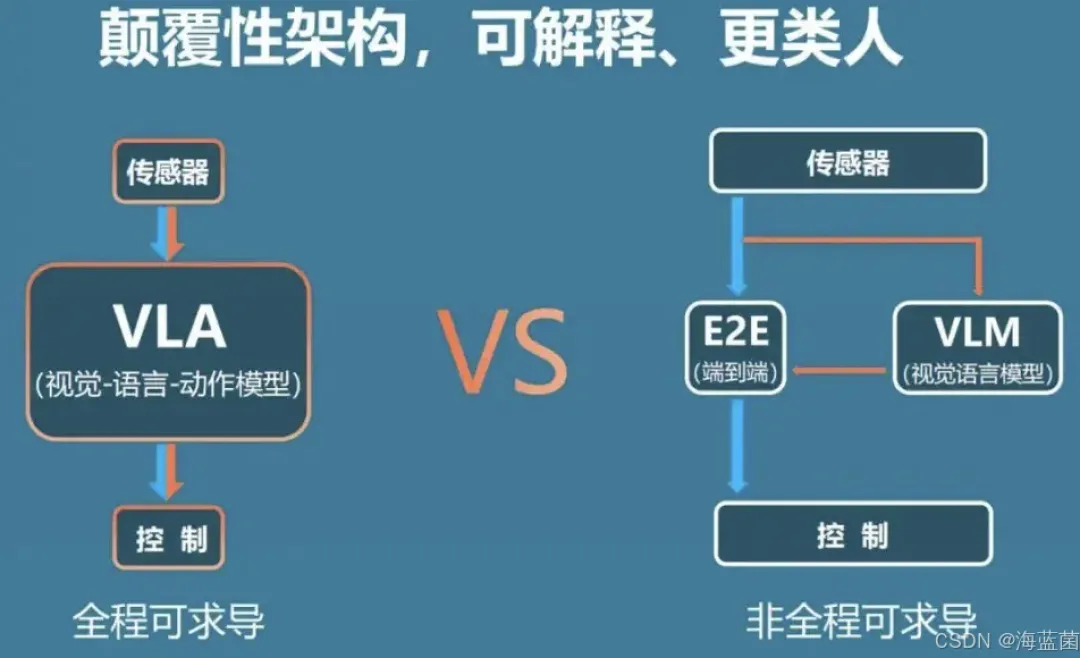
VLA 是 VLM 的高阶升级版本,也是真正面向自动驾驶物理智能体的核心模型。它把视觉感知、语言理解、动作执行三大能力整合在同一个模型框架里,不再局限于单纯的语义表达,而是能直接输出车辆可以执行的控制信号或轨迹规划,实现了自动驾驶 “感知 — 认知 — 执行” 的端到端闭环,这也是它被视作迈向 L4 + 高阶自动驾驶关键技术的原因。
值得一提的是,VLA 并不是 VLM 和端到端模型的简单拼接,而是对整个模块的重新设计。在 VLM 的视觉 - 语言基础上,它新增了 3D 空间智能、动作决策、轨迹优化三大核心模块,以理想汽车的 MindVLA 为例,就能清晰看到它的工作逻辑:3D 空间智能模块会把摄像头、激光雷达的感知数据输入 3D 空间编码器,结合车辆自身的姿态、导航信息生成 3D 特征,再通过 3D 高斯表征完成环境的高精度建模,刚好解决了 VLM 在 3D 空间理解上的短板;语言智能模块采用自研的大语言模型,能直接理解 3D 空间特征,还支持快 / 慢思考双模式,快思考能直接输出动作指令,满足实时性要求,慢思考则通过思维链完成复杂逻辑推理,应对公交车道、无保护左转这类复杂场景;动作决策与轨迹优化模块会把语言推理的结果转换成驾驶行为编码的 Action Token,再通过扩散模型生成车辆的行驶轨迹,同时还能预测其他交通参与者的轨迹,提升复杂路况下的博弈能力,甚至还能支持激进、保守、常规这类驾驶风格的自定义。
为了适配车端部署,VLA 采用 “云端大模型预训练 + 端侧小模型蒸馏” 的策略:云端训练大参数的基座模型,再蒸馏成适合车端的小参数模型,通过混合专家架构和稀疏注意力实现计算稀疏化,保证在 Orin-X、Thor-U 这类车载芯片上能实现 40Hz 以上帧率的实时推理。
在自动驾驶应用中,VLA 是直接面向车辆控制的 “行动中枢”,核心价值就是把语义理解转化为可执行的驾驶行为,解决了传统端到端模型无法应对复杂交通规则、自然语言指令的问题。比如面对公交车道、潮汐车道这类规则多变的场景,它能自主解析路面和标牌上的文字规则,做出变道、直行、等待的动作决策;用户说 “前方出口靠右行驶”“靠边停车” 这类语音指令,它能直接拆解任务,生成精准的驾驶轨迹;遇到行人窜出、前车急刹这类突发情况,能结合环境博弈生成最优的制动、避让轨迹,而不是简单的规则化反应;还能通过人类反馈强化学习,模仿人类的驾驶习惯,实现平滑的加减速、转弯,满足个性化的驾驶需求。
VLA 的落地,其实解决了自动驾驶从 “理解” 到 “行动” 的核心痛点,其中有几个关键的技术突破:一是用 3D 高斯表征替代了传统的 BEV + 占用网络,实现 3D 环境的自监督学习,大幅提升了环境感知的精度和效率;二是快 / 慢思考的切换模式,能根据场景复杂度灵活选择推理方式,既保证实时性,又能让决策更合理;三是扩散模型的轨迹优化,能实现自车和其他车辆轨迹的联合预测,提升复杂路况的博弈能力;四是引入人类反馈强化学习,形成 “人接管 —AI 迭代” 的闭环,让驾驶的安全边际和操作习惯都更优。
03#
VLM 与 VLA 的核心区别,一张表看明白
VLM 和 VLA 同属自动驾驶的多模态大模型体系,而且 VLA 是以 VLM 的视觉 - 语言融合能力为基础发展而来的,但二者在模型定位、架构、功能等方面的本质差异很明显,用一张表就能清晰区分:
说到底,VLM 就是 “看懂 + 说清楚”,只负责对道路环境做语义化理解,和人、其他系统做信息交互,属于自动驾驶的 “感知理解层” 技术;而 VLA 是 “看懂 + 听懂 + 做对”,能把对环境的理解、对指令的接收直接转化为车辆的实际动作,是 “感知 - 决策 - 执行一体化” 的技术。
04#
VLM 与 VLA 的协同融合:从 “分开工作” 到 “一体联动”
很多人会觉得,VLA 作为升级版,会不会慢慢替代 VLM?其实并不会,二者是递进且协同的关系:VLM 是 VLA 的技术基础,为它提供精准的视觉 - 语言语义理解能力;VLA 则是 VLM 的价值落地,让抽象的语义理解变成了实际的驾驶行为。二者的协同发展,也是自动驾驶从 “模块分离” 到 “端到端统一” 的核心趋势。
在VLA 出现之前,自动驾驶行业其实试过 “端到端模型 + VLM” 的组合方案:VLM 负责解析复杂的交通规则和语言指令,再把结果传递给端到端模型去执行决策。但这种方案的短板很明显,两个独立模型的运行频率不一样,协同训练和优化的效率特别低,而且 VLM 本身的 3D 空间理解能力不足,也会影响决策的准确性。
而新一代的VLA 模型,比如理想的 MindVLA,就实现了二者的深度融合:把 VLM 的视觉 - 语言能力融入到 VLA 的 3D 空间智能模块中,让语言理解直接为 3D 环境推理服务,不再是单纯的独立信息输出;同时,VLA 的执行结果还能作为反馈信号,反过来优化 VLM 的语义理解精度,形成 “理解 - 执行 - 优化” 的闭环。这种融合不仅简化了模型的整体架构,还大幅提升了自动驾驶系统的泛化能力和决策效率。
05#
未来发展趋势:从模型升级到实现人类级驾驶智能
随着大模型技术和自动驾驶的深度结合,VLM 和 VLA 的发展方向也很清晰,就是朝着 “统一建模、轻量化、拟人化” 走,二者一起推动自动驾驶向 L4 + 级别量产迈进。
首先是大模型的统一建模,打破VLM 和 VLA 之间的模块边界,打造一个融合了视觉、语言、动作、3D 空间、多传感器的通用智驾大模型,让端到端控制的效率更高;其次是 3D 空间智能的增强,VLM 会补充 3D 空间理解的能力,VLA 则会进一步优化 3D 高斯表征、雷达 / LiDAR/V2X 多传感器融合,实现对复杂道路环境的高精度建模;再者是车端轻量化和实时性的提升,依靠混合专家架构、稀疏注意力、模型蒸馏这些技术,在提升模型能力的同时,保证车端能实现低时延、高帧率的推理,满足车规级的要求;还有拟人化驾驶智能的打造,通过思维链推理、人类反馈强化学习,让 VLA 的决策更贴近人类的驾驶习惯,实现 “因果推理式” 的决策,而不只是简单的行为模仿;最后是多模态交互的升级,融合语音、手势、触摸屏等多种输入方式,让 VLM 和 VLA 能更好地响应人类的指令,实现更自然的人机协同驾驶。
06#
总结
VLM 和 VLA 是自动驾驶多模态大模型发展的两个关键阶段,二者最核心的差异,就是是否实现了从 “语义理解” 到 “动作执行” 的闭环。VLM 筑牢了自动驾驶的 “认知基础”,让系统真正能 “看懂” 道路世界、“听懂” 人类的指令;而 VLA 则实现了从 “认知” 到 “行动” 的跨越,让自动驾驶系统变成了具备类人思维的 “数字驾驶员”。
在高阶自动驾驶的发展过程中,VLM 并不会被淘汰,而是会作为核心能力融入到 VLA 的模型架构中,二者的协同融合会成为主流趋势。未来,随着 3D 空间智能、端侧轻量化、拟人化决策这些技术的不断突破,以 VLA 为核心的多模态大模型,会成为自动驾驶从 “功能堆叠” 迈向 “驾驶替代” 的关键,真正实现人类级的驾驶智能。
扫描下方二维码,添加智驾派小助理微信,免费领取以下材料


随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 打死都要买的3款国产SUV,空间大动力强配置还高,错过拍大腿!
- 7万元预算内5款国产SUV中的佼佼者,放心入手,结实耐用还省事!
- 特斯拉计划2026年在日本推出AI自动驾驶系统 测试车队新增Model Y
- 四维图新:国内唯一面向自动驾驶全面布局企业,与鉴智机器人累计获得680万套智驾方案新增定点
- 德系豪华亲兄弟“跳水”!40万级SUV暴降17万,5.1米大7座+终身质保,奥迪Q6车主要哭了!
- 你还会购买理想L9吗?能SUV,重新定义豪华出行
- 手握15万预算,这6款合资SUV闭眼入!省心耐造开到“退休”都开不坏,才是真“遥遥领先”
- 福特造了一辆21.18W的中型SUV!2.0T、274马力,油耗6.82L喝92油
- 汽车圈新车:MG全新SUV谍照 采用家族化设计语言
- 高性价比家用SUV来了哦!
