
🐉 龙哥读论文知识星球来了!公众号每日8篇拆解不够看?星球无上限更AI领域论文、资讯、招聘、招博、开源代码,一站式干货,每日2分钟刷完即赚!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
这篇文章不简单,来自小鹏汽车AI基础设施团队,针对目前交互式自动驾驶世界模型推理速度慢的痛点,提出了一种全新的无需训练的缓存加速方法X-Cache。它不依赖传统的跨去噪步缓存,而是巧妙利用连续视频块之间的物理连续性,在极少的去噪步骤下照样能大量跳过计算,实现了2.6倍的加速且几乎无质量损失。实用性极强,对推动世界模型落地非常有价值,值得每个搞自动驾驶和视频生成的同学仔细研读。
原论文信息如下:
论文标题:
X-Cache: Cross-Chunk Block Caching for Few-Step Autoregressive World Models Inference
发表日期:
2026年04月
发表单位:
小鹏汽车(XPeng Inc.)
原文链接:
https://arxiv.org/pdf/2604.20289v1.pdf
大家好啊,我是龙哥。今天咱们聊点实在的——自动驾驶世界模型怎么跑得又快又好。
现在自动驾驶圈里最火的世界模型,比如咱们之前聊过的GAIA-1、DriveDreamer这些,都能通过视频扩散模型生成高保真的未来视野,配合自回归(AR,Autoregressive)的方式一帧帧往外吐,简直像一个可交互的平行宇宙模拟器。可问题是,这东西算起来太慢了!
你想啊,一辆车有7个摄像头,360度环绕,要实时生成下一帧,还得等外部策略(比如方向盘、油门信号)进来才能继续。这导致推理时根本没办法做“超前”的并行计算。现有的加速方法,比如那些缓存扩散步之间特征的trick,到了只有4步去噪的少步模型(few-step)上就彻底歇菜了——步数太少,步与步之间的冗余被蒸馏掉了,没东西可重用。
那怎么办?小鹏汽车AI基础设施团队最近放了个大招:X-Cache,一个不需要额外训练的缓存方法,直接让DiT推理快了2.6倍,而且画质几乎不受影响!
这方法到底怎么做到的?别急,龙哥带大家一起拆解。
背景:交互式世界模型推理瓶颈
咱们先理清一下问题出在哪。
自动驾驶世界模型通常采用自回归视频扩散框架。什么意思呢?就是一段视频不是一口气生成的,而是一个chunk一个chunk地生。每个chunk大概几帧,生成完当前chunk后,拿着外部策略的新动作指令,再生成下一个chunk。这样就能做到真正的交互式仿真——你打个方向盘,模型立马响应。
但这种因果依赖关系(causal dependency)也带来了计算上的死穴:
- 模型必须等外部策略看到当前chunk的完整输出后才能发出下一个动作,所以没法提前并行计算后面的chunk。
- 为了满足延时要求,模型被蒸馏成少步去噪(比如4步),这样步间冗余几乎为零——传统缓存方法(比如跨去噪步重用特征)直接失效。
- 但是呢,自动驾驶场景又特别适合自回归——场景变化相对较慢,连续的chunk之间物理世界很相似。
这就留下一个巨大的优化空间:与其盯着去噪步之间的冗余,不如看看连续两个视频chunk之间有没有可重用的东西。
来,龙哥先放一张图直观感受一下X-Cache的效果:图1:基线与X-Cache在不同仿真场景下的视觉对比。左边是原始全计算输出,中间是X-Cache输出,右边是放大20倍的残差,基本看不出差异。创新点:跨步缓存新思路
现有缓存方法(比如FlowCache、SCOPE)都是沿着去噪步轴做缓存:第t步和第t+1步的DiT block输入比较相似,所以可以复用部分计算。但少步模型(比如4步)里,每步贡献的更新都是不可忽视的,跨步相似度极低,没法安全重用。
X-Cache反其道而行之——它沿着生成步轴(即chunk序号)做缓存。理由很简单:自动驾驶中物理世界变化是连续的,相邻chunk之间(例如第n个chunk和第n+1个chunk)的DiT block输入非常相似。更重要的是,这种跨chunk的相似性不受去噪步数影响——哪怕只有4步去噪,这种来自物理连续性的冗余依然存在。
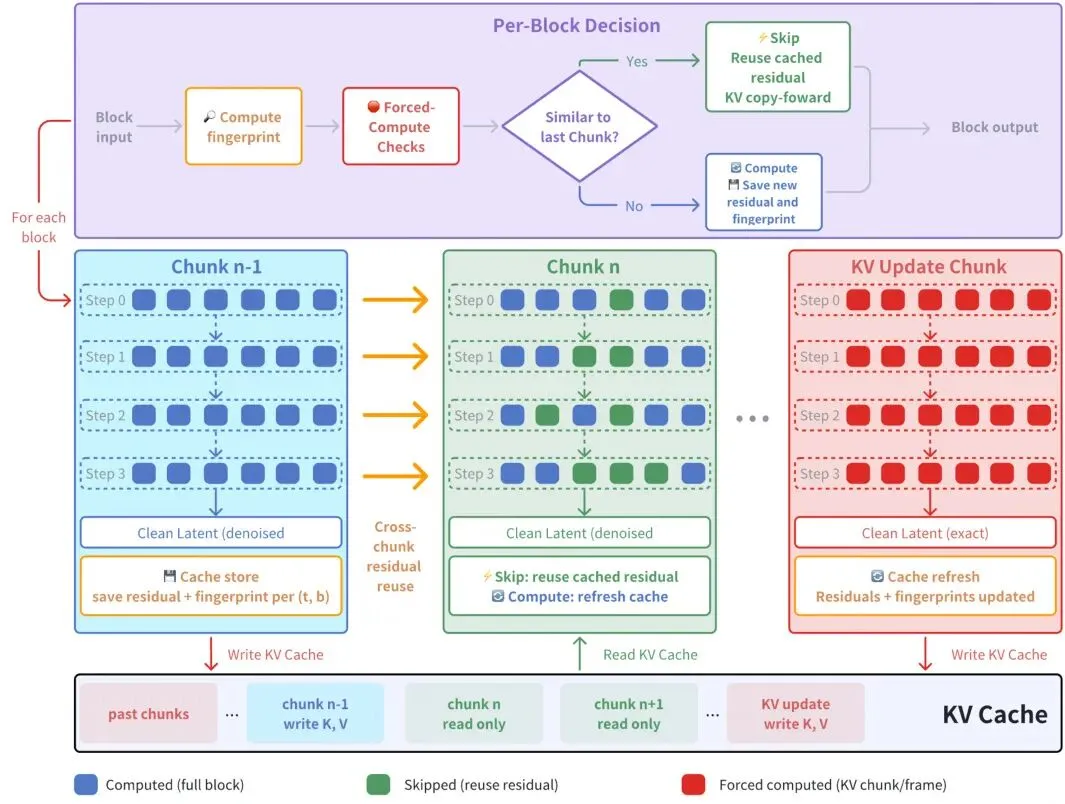
具体怎么做呢?X-Cache为每一个(去噪步t, 块b)位置维护一个缓存,里面存的是上一个chunk在相同位置计算出来的残差(residual)。当当前chunk的对应块输入与缓存指纹足够相似时,就直接把缓存的残差加上作为块的输出,跳过后面的繁重计算。如果不相似,就全计算并更新缓存。
核心创新可以总结为三点:
1. 跨chunk残差缓存——首次利用chunk之间的时域冗余,不受少步蒸馏影响。
2. 结构感知+动作感知的指纹设计——用于高效判断两个chunk输入是否相似,并且把“动作指令”这个关键变化信号直接融入指纹。
3. KV更新帧保护机制——防止缓存误差永久污染自回归KV缓存,强制更新帧必须全计算,阻断误差传播。
这思路是不是很巧妙?龙哥看到这里直接拍大腿——这才是真正理解问题本质的加速方案!
原理:如何利用连续帧的冗余?
我们先建立数学表示。具体来说,自回归视频扩散的推理过程是这样的:
- 用 n 表示第 n 个chunk的生成步。
- 用 t 表示当前chunk内的去噪步(t = 0,1,…,S-1)。
- 用 b 表示DiT块索引。
第n个chunk,第t去噪步,第b块的输入记为 x_{t,b-1}^{(n)},块函数 f_b 输出残差,输出是 x_{t,b}^{(n)} = x_{t,b-1}^{(n)} + f_b(x_{t,b-1}^{(n)}; c_t^{(n)})。
残差定义为 r_{t,b}^{(n)} = f_b(...) = x_{t,b}^{(n)} - x_{t,b-1}^{(n)}。
下面这张图就展示了整个架构:图2:X-Cache整体架构。展示了跨chunk缓存、双度量门控、KV更新保护等模块。
关键观察:在自动驾驶场景中,相邻chunk的画面变化很小,因此对于相同的(t,b)位置,输入 x_{t,b-1}^{(n)} 和 x_{t,b-1}^{(n-1)} 非常相似。这种冗余不依赖去噪步数,因此在4步模型中也成立。
缓存机制很简单:在第n个chunk完全计算后,把残差 r_{t,b}^{(n)} 缓存起来(索引是(t,b))。在第n+1个chunk,如果门控判定可以跳过,就直接用 x_{t,b-1}^{(n+1)} + (缓存的残差) 作为输出。数学上:
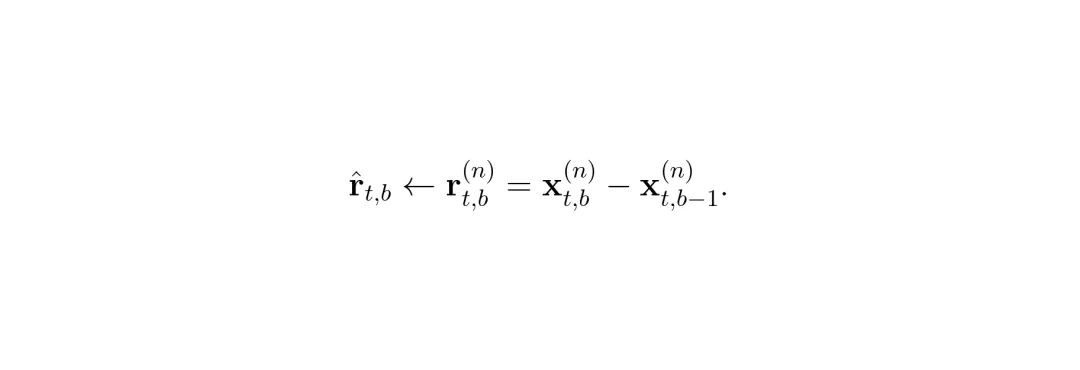
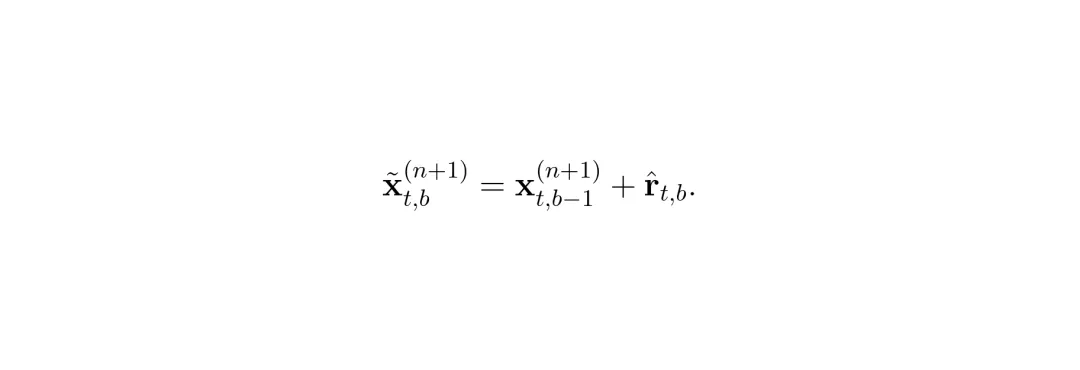 是不是很简单?不过要真正让这个机制work,还需要一个聪明的方法来判断两块输入是否足够相似,以及如何处理特殊情况(比如动作突然改变、KV缓存更新等)。这就引出了X-Cache的核心设计。
是不是很简单?不过要真正让这个机制work,还需要一个聪明的方法来判断两块输入是否足够相似,以及如何处理特殊情况(比如动作突然改变、KV缓存更新等)。这就引出了X-Cache的核心设计。
设计:双度量门控与安全保障
X-Cache的决策核心是一个双度量门控: 同时考察余弦相似度(全局方向变化)和最大token偏差(局部异常)。只有两个度量都满足条件,才跳过块计算。
要计算余弦相似度,就得比较两个chunk在相同(t,b)位置的输入张量。但完整的张量太大了(B×V×L×C),不可能每个块都算一遍。X-Cache构造了一个精巧的指纹(fingerprint):对潜变量在3D时空网格 (F, H, W) 上进行均匀采样,仅抽取少量token(默认32个)组成紧凑表示。还附加了两个辅助信号:
- 全局通道:每个视图组的序列均值,捕捉全局偏移。
- 条件通道:把当前chunk的动作向量(比如方向盘转角、油门)展平后作为额外指纹条目,这样即使潜变量本身变化不大,但动作变了,门控也能直接感知到。
余弦相似度公式如下:
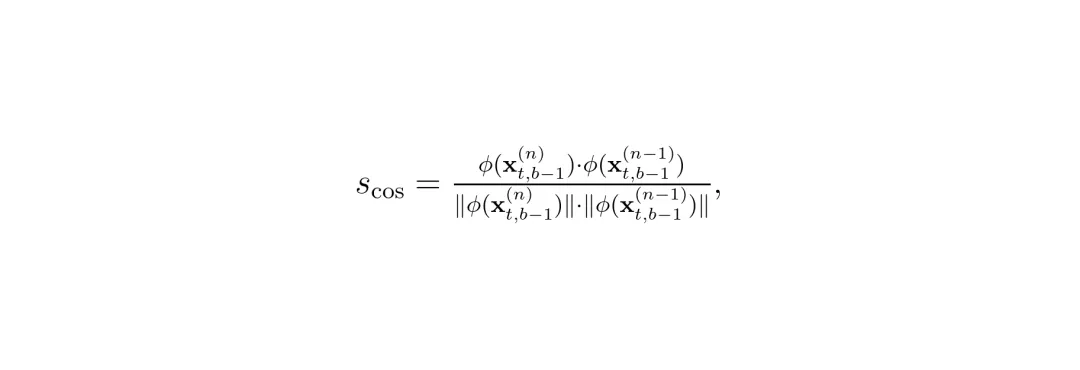 第二个度量是最大相对偏差,用于捕捉局部异常(比如某个空间区域突然变化):
第二个度量是最大相对偏差,用于捕捉局部异常(比如某个空间区域突然变化):
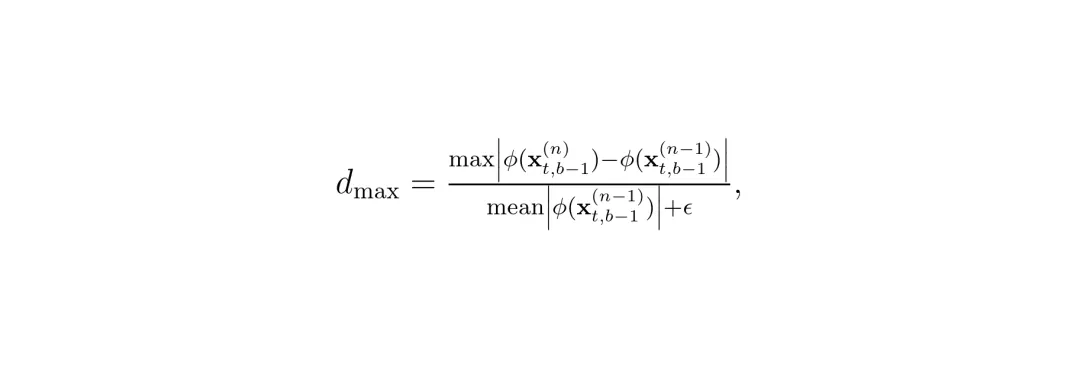
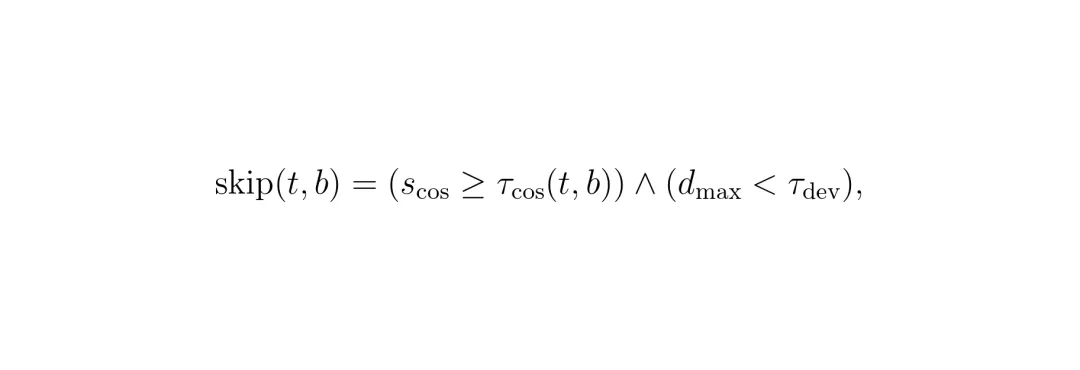 图:块(t,b)被跳过的条件是余弦相似度≥阈值τcos且最大偏差<τdev。
亮点来了:余弦阈值不是固定值,而是自适应的。每个(t,b)位置维护一个指数移动平均(EMA)来跟踪自己的历史相似度,然后设定阈值为(EMA - margin),但至少不低于一个全局质量下限。这样,那些长期保持高相似度的块(比如后方视野变化小)会自动获得更宽松的阈值,跳过更多计算;而变化频繁的块(比如前方有车辆切换车道)则保持保守。公式如下:
图:块(t,b)被跳过的条件是余弦相似度≥阈值τcos且最大偏差<τdev。
亮点来了:余弦阈值不是固定值,而是自适应的。每个(t,b)位置维护一个指数移动平均(EMA)来跟踪自己的历史相似度,然后设定阈值为(EMA - margin),但至少不低于一个全局质量下限。这样,那些长期保持高相似度的块(比如后方视野变化小)会自动获得更宽松的阈值,跳过更多计算;而变化频繁的块(比如前方有车辆切换车道)则保持保守。公式如下:
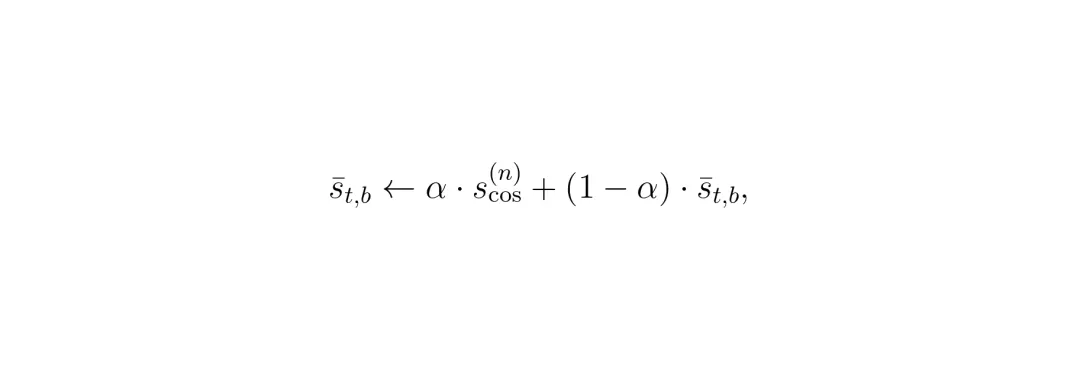
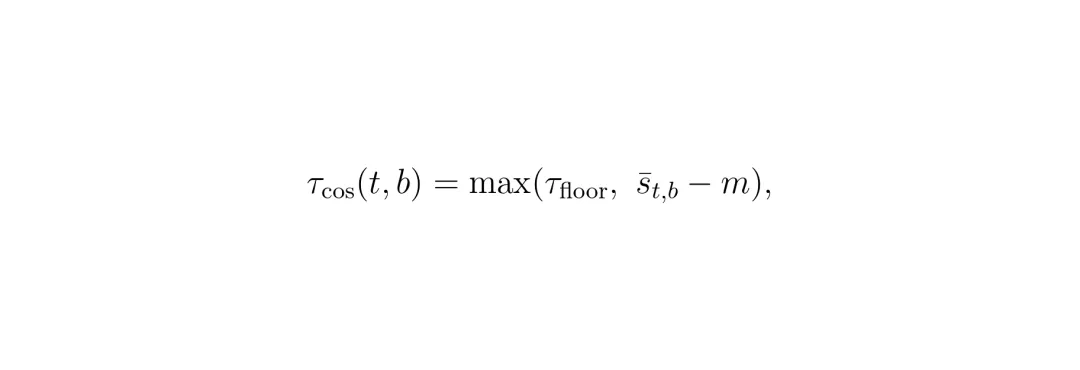 图:自适应阈值计算公式,τfloor=0.97,m=0.02。
除了门控,X-Cache还配备了四层安全机制:
图:自适应阈值计算公式,τfloor=0.97,m=0.02。
除了门控,X-Cache还配备了四层安全机制:
1. 去噪步0保护:t=0时,噪声主导,条件信号影响最大,而且噪声每次都会重新采样,余弦相似度天然较低。默认强制全计算,也可用极严格阈值(0.999)放宽。
2. 锚块(Anchor blocks):前Fn个块(默认Fn=1)无条件全计算,确保最新条件(动作、文字)能通过adaLN-Zero注入并向下游级联传播。
3. KV更新帧保护:当当前chunk负责更新KV缓存时(即其干净潜变量会被写到缓存的时刻),强制全计算。这防止了缓存误差永久污染KV,相当于给KV缓存做了一个“免疫接种”。
4. 最大过期次数:每个(t,b)位置连续跳过的次数不能超过M(默认10次),否则强制更新,避免陈旧缓存。
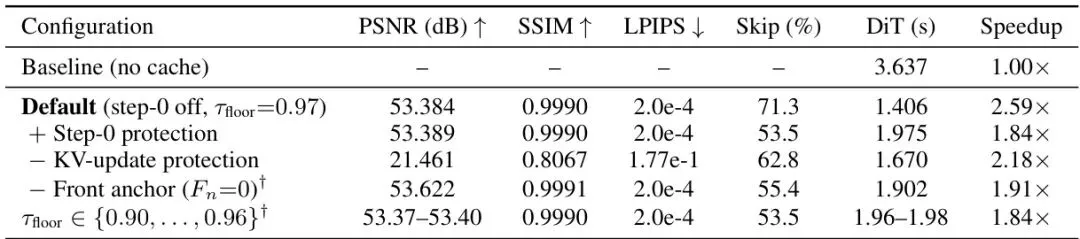
默认参数汇总如下:表1:X-Cache默认超参数。注意:去躁步-0保护默认关闭。效果:71%跳过率,2.6倍加速,质量无损
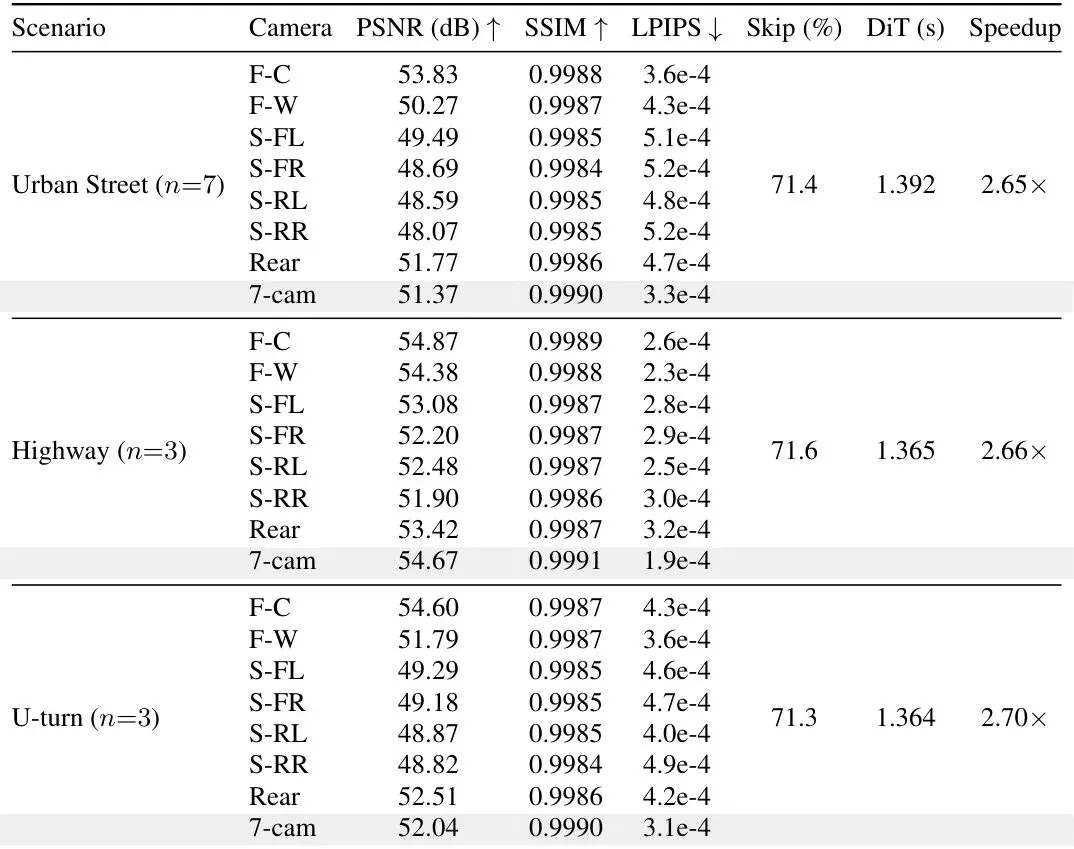
小鹏团队在自家生产的X-World世界模型上(基于WAN 2.2,7个摄像头,4步去噪,滚动KV缓存)进行了全面评估。硬件用的是阿里平头哥的“真武”810E加速器(本文称为PPU)。测试集包含7个城区路段、3个高速路段、3个掉头路段,每个片段264帧(约22秒)。
先看核心实验指标:表2:X-Cache与全计算基线的对比。可以看到在三个场景中,针对7路合成画面,PSNR都保持在51-55dB,SSIM>0.9990,LPIPS<4e-4,跳过率约71%,DiT加速2.65-2.70倍。
大家注意,PSNR在51-55dB是什么概念?通常认为PSNR>40dB就人眼难以区分差异了,X-Cache高到50多dB,基本就是完全看不到差距。再看视觉对比:图3:三个场景的定性对比。每一行:左为全计算基线,中为X-Cache,右为放大20倍的像素残差。基本看不出差异。
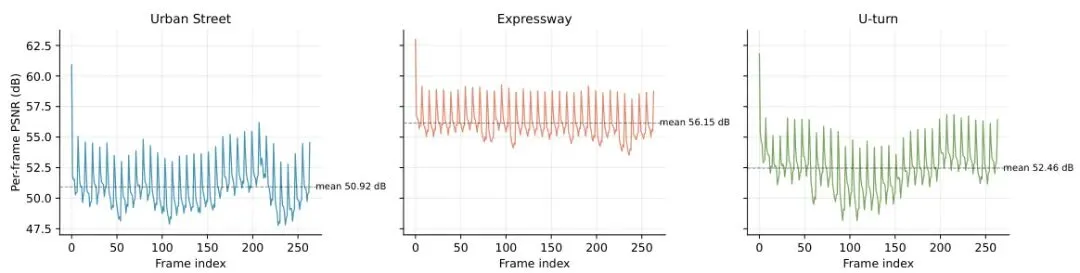
更令人惊讶的是,PSNR帧级曲线没有出现漂移,说明KV更新保护完美阻止了误差累积:图4:每帧PSNR曲线。虚线是均值。可以看到掉头场景中有一段下降(拐弯处),但依然保持在50dB以上,且之后恢复。没有累积漂移。
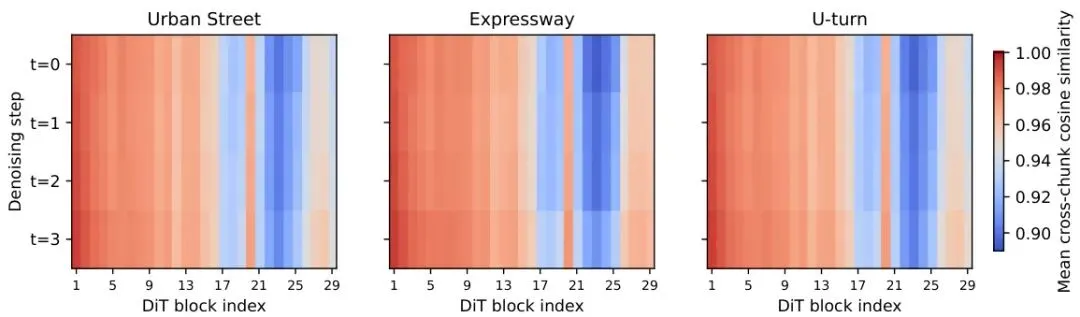
如果看门控内部行为,会发现跨chunk余弦相似度在不同块之间存在明显分层:图5:跨chunk余弦相似度热图。横轴是块索引(0~26),纵轴是去噪步(0~3)。浅色表示高相似度,深色表示低相似度。可以看到前19个块保持在0.95以上,后6-7个块降到0.90左右(红色框)。三个场景模式几乎一致。
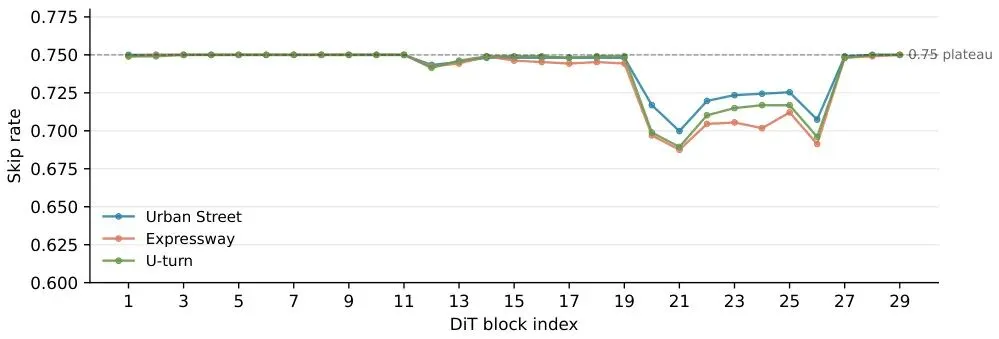
对应的跳过率(skip rate)也表现出相同的分层:图6:每块跳过率。块1-19达到75%的理论上限(因为每4个chunk有一个是KV更新帧需要强制全算),块20-26降到约69%。三个场景曲线几乎重合。表3:消融实验。如果不做KV更新保护,PSNR暴跌到21.46dB,SSIM降到0.8067,画面完全崩坏。移除前锚块(Fn=0)虽然没有崩,但跳过率降到55.4%。默认配置(step-0保护关闭,τfloor=0.97)达到最佳平衡。总结:开启少步自回归世界模型加速新方向
X-Cache这篇工作的价值不在于堆砌技巧,而在于它精准找到了问题的新维度——从跨去噪步缓存转向跨生成步缓存。这个思路转换完美绕开了少步蒸馏带来的障碍,同时巧妙地利用了自动驾驶场景物理连续性这一天然优势。
而且整个方案是训练无关的,即插即用,只修改推理过程,对现有模型完全友好。在X-World上实测2.6倍加速,画质基本无损,这对推动世界模型在车端实时部署意义重大。
当然,也有局限性:目前只在单个PPU上验证,且仅限于一个模型。跨chunk冗余假设依赖于场景变化速度相对生成率而言足够慢,如果轨迹中有极端快速的场景切换(比如突然漂移),那可能效果会打折扣。不过从论文的消融看,最难的掉头场景也扛住了。
总的来说,这是一篇值得所有从事自动驾驶、视频生成、模型推理加速同学细读的工作。
龙迷三问
Q1:X-Cache与其他缓存方法(如FlowCache、SCOPE)的本质区别是什么?其他方法缓存的是相邻去噪步之间的特征,依赖步间冗余;而X-Cache缓存的是相邻生成步(chunk)之间的残差,依赖物理场景的时域连续性。所以X-Cache在少步模型下依然有效,而其他方法会失效。
Q2:什么是KV缓存?为什么需要保护KV更新帧?KV缓存(Key-Value Cache)是自回归模型中的一个技巧:将之前生成的token的Key和Value存储下来,后续生成时直接复用,避免重复计算。在视频自回归中,模型会把过去所有chunk的KV信息存起来,供未来chunk做cross-attention。如果某个chunk的KV被错误计算(比如因为缓存误差),这个错误会被所有后续chunk反复使用,导致永久性质量下降。KV更新帧保护就是强制保障写入KV缓存的那一步是精确计算的,阻断误差传播链条。
Q3:X-Cache训练时需要做什么?对现有模型有要求吗?X-Cache是一个完全训练无关(training-free)的推理加速方法,不需要修改模型、不需要额外训练、不需要微调。只要你的模型是DiT-based自回归视频扩散,有多个块(block),并且生成环境是物理连续的(比如自动驾驶、机器人仿真),就可以直接应用。唯一需要的是能获取到块间输入张量(fingerprint所需)和调整块计算逻辑(跳过或计算)。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★★首次提出跨chunk缓存这一新方向,精准解决了少步自回归推理的痛点。思路清晰,设计巧妙,完全没有跟风而是另辟蹊径。
实验合理度:★★★★☆实验全面,覆盖了城市、高速、掉头三个典型场景,并做了充分的消融。唯一扣分点是仅在一个模型(X-World)上验证,虽然模型有代表性,但缺少在其他世界模型或视频扩散模型上的迁移实验。不过考虑到X-Cache设计的普遍性,这个缺陷不算致命。
学术研究价值:★★★★★提出了一种全新的推理加速维度,对后续世界模型、视频扩散模型、自回归生成模型的加速研究都有很强的启发意义。尤其是训练无关这一点,使得该方法可以立即应用于任何现有模型,学术价值很高。
稳定性:★★★★☆在22秒的长时间生成中PSNR波动极小,没有出现漂移,说明安全机制非常可靠。但掉头场景中间有一段PSNR下降(虽然依然很高),提示在极端快速变化时略有退化。整体是稳定的。
适应性以及泛化能力:★★★★☆跨chunk冗余假设依赖于物理场景的连续性和生成速率。在自动驾驶、机器人、监控视频等慢变场景下应该都很适用。但对于快节奏切换的影视特效或游戏场景,效果可能打折扣。另外,模型需要是自回归且使用多个DiT块,这覆盖了主流的视频扩散模型,适应性算不错。
硬件需求及成本:★★★★★训练无关、推理时额外开销极小(仅做指纹提取和简单阈值比较),几乎不增加硬件负担。而且它是在降低计算量(跳过了大量块),所以是实实在在减少硬件需求。在PPU上实测2.6倍加速,对于资源受限的车载平台非常友好。
复现难度:★★★★☆方法描述非常详细,包括指纹采样方式、阈值更新公式、安全机制细节,伪代码也给了。但缺少开源代码,需要自己实现。对于有经验的团队来说,按论文描述应该可以复现。扣一星是因为没有官方代码。
产品化成熟度:★★★★☆已经在X-World这个产品的推理流水线上验证,证明是可落地的。但需要与策略调度、硬件驱动等系统工程集成。考虑到它是训练无关的,可以快速集成到现有流程中。但离车载实时部署可能还需要额外的硬件适配工作(论文使用阿里平头哥PPU,若换到NVIDIA或华为昇腾需要适配推理引擎)。整体成熟度较高。
可能的问题:论文未与现有跨步缓存方法进行直接对比(作者自己也解释了不是一个赛道),但读者会希望能有一个综合比较。另外,指纹大小为K=32,这个值是否最优?能否自适应调整?长期生成(超过22秒)的稳定性未验证(虽然理论上不漂移)。硬件方面仅在平头哥PPU测试,缺少GPU实验。
[1] X-Cache: Cross-Chunk Block Caching for Few-Step Autoregressive World Models Inference. AI Infra Team, XPeng Inc. arXiv: 2604.20289v1, 2026.[2] X-World: Controllable Egocentric Multi-Camera World Model for Autonomous Driving. (论文中提到的所评估模型,相关文献未在提供的markdown中给出完整引用,此处仅作标注)[3] Yunxuan Li, et al. WAN 2.2: A Family of Video Diffusion Foundation Models. (X-World基于此,原文尾部参考文献有列出,但未给出完整引用信息)*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

🎉 看到小鹏这波操作,是不是感觉自动驾驶世界模型加速有救了?想跟更多自动驾驶、世界模型、端到端的小伙伴一起交流吗?
欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 自动驾驶+上海+小鹏+龙哥),根据格式备注,可更快被通过且邀请进群。
『龙哥读论文』微信群目前包含:图像处理、大模型及智能体、自动驾驶及机器人、AI医疗及AI金融5个群~





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
