“行业首次将三维重建与视频生成深度耦合,Waymo、nuScenes等主流基准测试全面SOTA。”
就在昨天,就在其他车企还在为“VLA”和“世界模型”吵得不可开交时,小米直接打开一条前所未有的新赛道——重建+生成一体化!
5月26日,小米技术官方正式发布Xiaomi Auto World Model全新框架,其核心创新“重建锚定几何、生成填补想象”彻底改写了过去智驾模型的核心规则。
并且——在Waymo、nuScenes等全球公认的主流基准测试中,小米世界模型全面拿下SOTA(业界最佳) !
或许你觉得这又是厂商的虚无数字营销。但今天我要告诉你:这次不一样。
毫不夸张地说,这是一颗投向自动驾驶技术界的“原子弹”。小米用一整套全新逻辑,重构了AI如何看待、如何预测这个物理世界。
今天我们就来深扒:小米这条不寻常的新路,到底会给汽车带来怎样翻天覆地的认知“开挂”?
一、世界模型:让AI不再是“睁眼瞎”,而是学会“预见未来”
先来简单补个课——什么是“世界模型”?
简单解释就是:给AI装上了一个可以在大脑里“预演未来”的模拟器。传统智驾只能根据摄像头看见的当下画面,判断“前面是车”“左右有人”,然后做被动反应。
而有了世界模型,AI可以在你遇到路口以前,脑海中提前推演这个场景可能发生的上百种变化:
“如果我在这里减速,后面会怎样?”
“如果路边那个小孩突然冲出来,我能刹住吗?”
“如果前车忽然刹车灯全亮,最快应变路线是什么?”
说得直观一点:
普通智驾=只会读当页内容,
世界模型=能预判下一页剧情。
用中国工程院院士更专业的说法,这是把车从“按规则开车”变成“靠理解开车”。世界模型正是那关键一步:让AI理解重力、惯性、动量等物理世界的运行规律,并用最快速度预测未来几秒的演化。
NVIDIA全球副总裁吴新宙在北京车展上直接断言:
世界模型,是自动驾驶最本质的一环。
然而,在这个黄金赛道里,长期存在着两条互不相通的主流技术路线。它们像是被一堵高墙隔开,谁也拿谁没办法。
二、两堵高墙:传统世界模型路线注定撞墙
翻开任何一本自动驾驶的教科书,世界模型大致分两类:
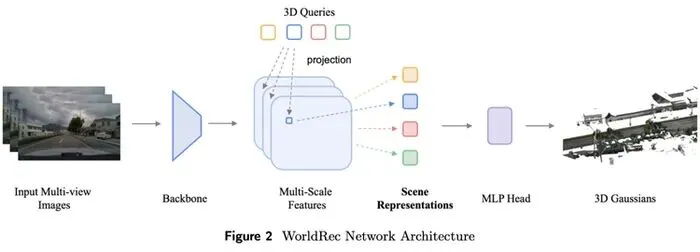
路线一:重建(WorldRec)
从多个摄像头视角的观测数据中,重建出一个精确到厘米级的3D场景模型。
✅ 优势:高保真、强一致性,模拟出来的世界和你现实看到的一模一样。
❌ 劣势:它只能还原已经看到的内容,缺乏想象能力。 也就是说,遇到从未见过的极端场景(比如一辆失控的自行车横冲直撞),它就“宕机”了。人工智能如果不能预判未知,就永远无法应对“黑天鹅”。
路线二:生成(WorldGen)
它直接用扩散模型(就是画图AI用的那套)预测和生成未来的画面,填补你看不见的“未来帧”和“未观测视角”。
✅ 优势:有想象力,能“脑补”出来来。
❌ 劣势:缺乏显式3D结构,长时序下容易漂移失真。 简单说就是——生成的画面越往后越离谱,如果让它在脑子里持续画24秒,画面可能完全脱离物理逻辑。
这就像两个能力各异的工匠:一个手艺极其精准但只会复制已知,一个想象力天马行空但总是搭出歪七扭八的雕塑。
长久以来,行业内只能在这两者间“二选一”。毕竟,要在大脑中同时兼顾物理真实与无限想象,在过去几乎是不可能完成的任务。
直到昨天,小米做了一件从没有人尝试过的事: 把这座高墙彻底推倒。
三、小米的“核裂变式破局”:重建+生成一体化
如果你以为小米只是在“重建”和“生成”两条路之间选了中间路线,那就太小看它了。
Xiaomi Auto World Model的核心创新是什么?答案是——深度耦合!
它不像之前任何系统那样把重建和生成当作独立模块各自为政,而是让它们在一个闭环里互相约束、彼此增益。
具体如何实现呢?
1. 重建模块负责构建精确的3D几何——相当于给大脑放上一个稳固的“3D骨架”,提供结构化锚点来约束生成过程的稳定性。
2. 生成模块则负责填补未来帧、未观测视角——“想象”那些重建模块看不到的场景变化。
3. 最关键的是,生成模块不凭空想象,而是以重建渲染的RGB图像为几何骨架,保证想象出来的内容既合理又符合物理布局。
三者交融在一起,迸发出三个让对手后背发凉的“1+1>2”的协同效应:
🛡️ 高稳定性:WorldRec的确定性几何约束,有效抑制长时序自回归中的误差累积与内容漂移。
🎯 高一致性:4D场景表征作为跨帧共享记忆,确保不同时刻、不同视角下场景内容全局一致。
🌍 高真实性:WorldGen的合成内容不仅符合物理布局,还贴近真实传感器观测,显著缩小了“仿真-现实”的领域鸿沟。
这意味着什么?
意味着以前那些千奇百怪、用传统重建方式永远覆盖不到的危险场景,现在都能在虚拟世界里高保真生成并验证。
以“鬼探头”为例——马路上一辆车突然横穿,传统智驾没有数据积累就只能靠运气,而小米世界模型可以在算法层面对这种极端场景进行定向强化训练。
这种“脑补不飘、脑补不乱、脑补保真”的能力,在行业内前所未有。
这才是从“看见”跨越到“理解”的最佳捷径:让车不仅知道你眼前是什么,还能以高置信度预判全局动态。
四、一个现实而残酷的对比:全球主流世界模型都在走哪几步?
为了让你更清楚地了解这次突破的含金量,我们用几个全球主流世界模型来做个直观对比:
🇬🇧Wayve GAIA-3:150亿参数的生成式世界模型,核心用于安全关键场景测试和碰撞场景的“反事实”推演,支持在不同车辆传感器配置下评估同一场景。
🇺🇸 Waymo 世界模型:基于谷歌DeepMind的Genie 3架构,能从文本提示、驾驶输入和场景布局生成可交互3D环境,已能模拟龙卷风等极端天气场景。
🇨🇳 小鹏 X-World:可控制的多视角生成世界模型,基于WAN 2.2视频生成模型构建,输入多相机历史视频流和驾驶动作即可生成对应未来画面。
🇺🇸 特斯拉 FSD VLA世界模型:纯视觉语言思维链驱动,模型参数量大幅提升,导航与路径规划功能全面整合至神经网络。
🇨🇳 蔚来 世界模型+闭环强化学习:国内首个直接操作方向盘与踏板的智驾系统,已升级至“世界模型+监督微调+闭环强化学习”三层训练框架。
🇨🇳 小米 重建+生成一体化:首次深度耦合重建和生成两大技术路线,互锁互益,在Waymo、nuScenes主流基准测试全面SOTA,已在合成数据生成、仿真测试、辅助驾驶学堂三大场景落地。
一目了然——当前行业要么走生成路线,要么走重建路线,彼此割裂。小米是迄今为止唯一一个把这两座“孤岛”用桥梁彻底连接起来的玩家。
五、雷厉风行:已有超过10万CLIPS真实合成数据送训练场
说到这,你可能会问:这些理论我们已看麻木了,说到底能不能打吗?
小米世界框架给出的答案是:不仅仅能打,而且已经打完了,拿到了全满贯。 这套全新的模型已经在小米汽车三大业务场景中成功落地:
🎬 合成数据生成:目前已交付超过10万clips高质量合成数据,直接用于感知模型训练。那些危险、罕见、每年不到百万分之一概率的极端驾驶场景,现在都能通过AI“无中生有”、批量生成并反复磨炼。
🎯 仿真测试:构建闭环仿真环境,可在仿真中复现真实事故并进行定向优化,极大提升了安全验证效率。
🎓 辅助驾驶学堂:利用世界模型动态生成第一人称驾驶教学视频,面向复杂路况时向用户展示正确操作。目前已上线至所有小米车型。
说的再具体一点:当你开着一辆搭载小米世界模型的车进入一个地形复杂的山间急弯时,系统不会像传统智驾那样茫然无措——它已经在虚拟环境中模拟过数百次过弯最优路径,并在你打方向盘的同时持续实时推演路况演化。这才是真正的“AI老司机”的思维方式!
写在最后
小米Auto World Model的出现,让“世界认知推演、智能提前演练”不再是科幻电影中才有的情节。
它从三个本质层面的协同进化,把自动驾驶从“看哪儿撞哪儿”的尴尬时代,一把拉入了“脑补万物,预测所有”的认知新时代。
这也让人不得不感叹,小米汽车在短短两年内,完成了从0到1、从规则到认知的三次技术跃迁。从XLA认知大模型的认知驱动,到OneVL统一三大技术路线,再到如今从“感知”到“推演”的升华,每一次突破都在狂飙。
在实现最终理想形态的L4/L5级完全无人驾驶的道路上,安全、广谱、无限制的高保真世界认知推演是绕不开的基石。
而小米的重构思路,可能已经彻底改变了下一阶段技术竞争的形态。
现在的问题是:等到你下一次拉开智能车门,是坐在副驾让车自由飞驰,还是和AI搭档一起享受顶级推演之旅?

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
