仅代表个人观点 |声明
AI生成 | 配图来源
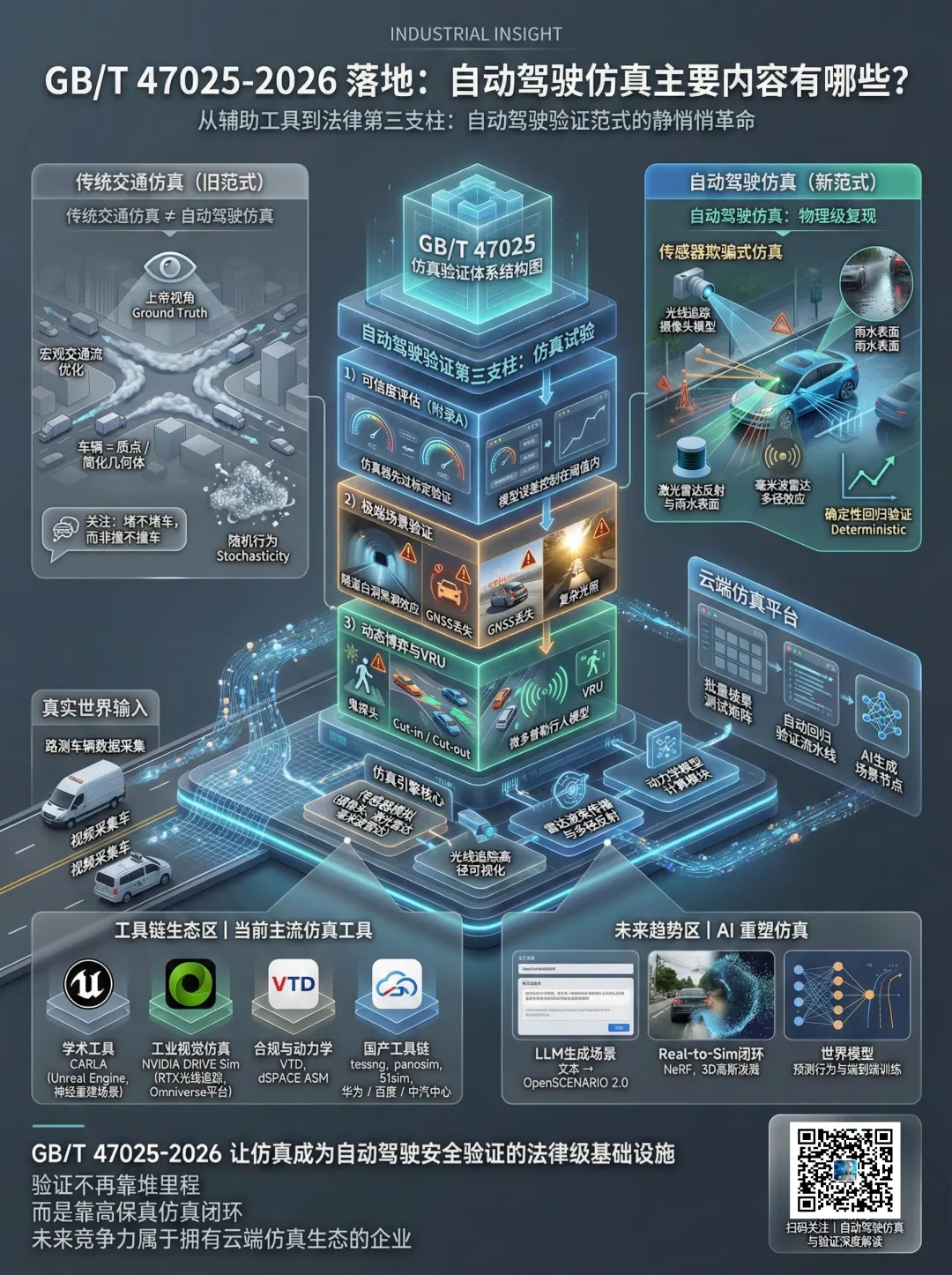
最近,我在仔细研读GB/T47025—2026《智能网联汽车自动驾驶功能仿真试验方法及要求》。读完最大的感受是:自动驾驶的验证逻辑正在发生一场静悄悄但极具颠覆性的范式转移。
过去几年,我们目睹了太多关于自动驾驶的豪言壮语,也看到了随之而来的事故新闻。大家逐渐意识到,车要跑得好,光靠在路上“堆里程”是不够的。面对L3、L4级别所需的数十亿公里验证里程,纯靠物理路测不仅在经济上不可行,在复现那些极端危险场景(Corner Cases)时更面临着巨大的伦理悖论——我们总不能真的让人去撞车来验证系统是否安全。就跟我们传统的车辆或者护栏的防撞性能一样,需要做实际场景的碰撞测试,也需要通过仿真来进行模拟。
此外,2026年发布的这套新国标,实际上是把仿真试验从“辅助工具”正式扶正为具有法律效力的“第三支柱”。这次想参考这个标准,从一个技术观察者的角度,讲一下这次标准落地背后的技术验证、工具进化以及未来的游戏规则。
一、 别再把“交通仿真”当成“自动驾驶仿真”
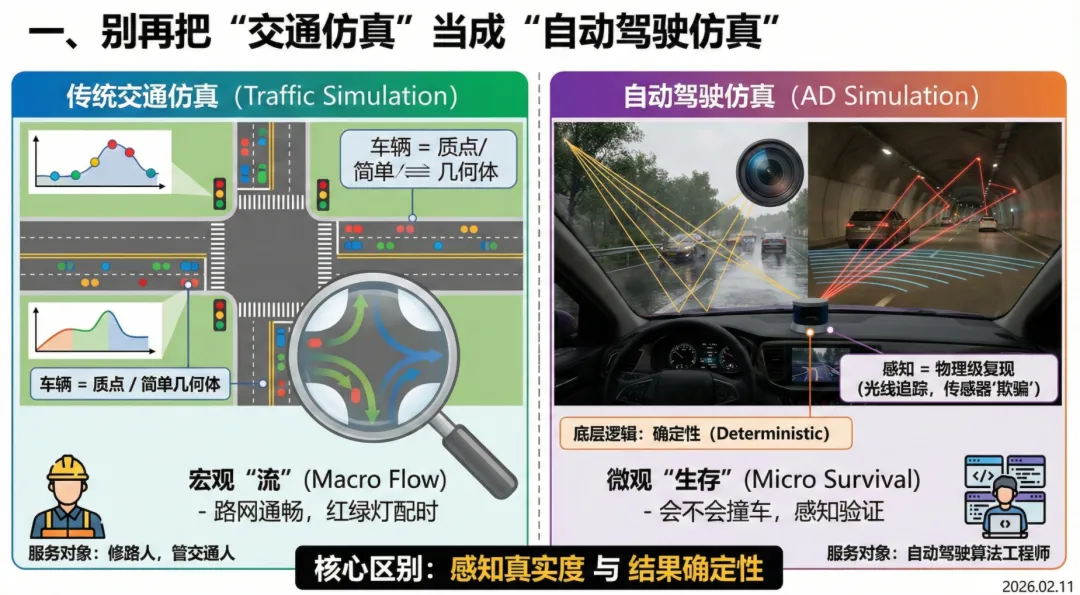
仿真或者说交通仿真很多人但很熟悉,但是也有很多人容易混淆一个概念,就是交通仿真和车辆仿真。其实,传统的交通仿真和现在的自动驾驶仿真,在底层逻辑上完全是两个物种。
传统交通仿真(如 Vissim 或 SUMO),服务的对象是修路的人和管交通的人。关注的是“流”——路网通不通畅、红绿灯怎么配时。在这些软件里,车辆被简化成了质点或简单的几何体,它们的行为逻辑是基于概率统计的(Stochasticity)。也就是说,它们模拟的是宏观规律,为了看堵不堵车,而不是看会不会撞车。
但自动驾驶仿真(AD Simulation)要解决的是“这辆车会不会撞”的生存问题。这要求一种极致的“物理级复现”。
最本质的区别在于感知。在传统仿真里,车辆获取周围信息是上帝视角(Ground Truth),它直接“知道”旁边有车。但在自动驾驶仿真中,必须“欺骗”车辆的传感器。这意味着我们要用光线追踪技术去模拟光怎么照进摄像头,要模拟激光雷达的光束打在积水路面上的反射,甚至要模拟毫米波雷达在隧道里的多径效应。如果做不到这一点,就无法验证感知算法在恶劣环境下的表现。
此外,自动驾驶仿真必须是确定性(Deterministic)的。如果我今天测了一个代码版本,明天复测时因为仿真里的路人随机走了一步导致结果不同,那这个测试对于回归验证就是无效的。这一点,是传统交通流仿真软件难以直接胜任的。
二、 工具箱大盘点:现在的“神兵利器”都有哪些?
在这个过渡期,市场上的工具链呈现出一种“各显神通”但又“殊途同归”的态势。我也检索了一些资料,目前主流的工具可以分为几类:
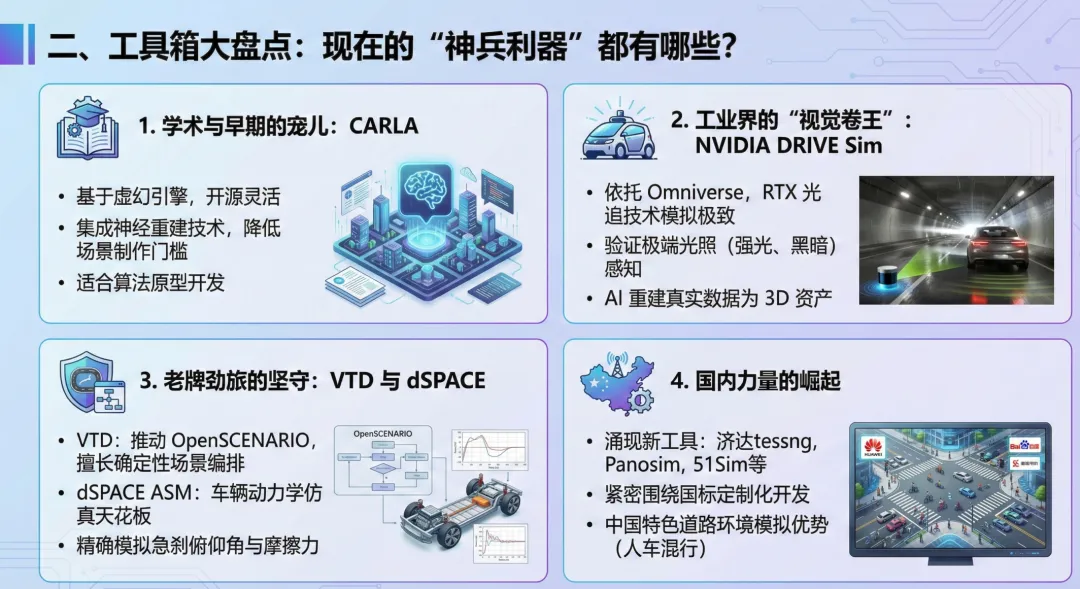
1. 学术与早期的宠儿:CARLA。如果搞学术研究或者早期算法验证的,CARLA 依然是绕不开的名字。它基于虚幻引擎(Unreal Engine),开源且灵活。现在的CARLA更是集成了神经重建技术,大大降低了场景制作的门槛,非常适合做算法的原型开发。
2. 工业界的“视觉卷王”:NVIDIA DRIVE Sim。如果主要目的是过车规、做量产验证,NVIDIA 依托 Omniverse 平台构建的 DRIVE Sim 是目前的视觉标杆。它用 RTX 光线追踪技术把传感器的物理传播模拟到了极致。这对于验证 L4 级感知系统在强光、黑暗等极端光照下的表现至关重要,它还能通过 AI 将真实采集的数据重建为 3D 资产。
3. 老牌劲旅的坚守:VTD 与 dSPACEVTD (Virtual Test Drive) 是 OpenSCENARIO 标准的主要推动者,擅长确定性的场景编排,是合规测试的老手。dSPACE ASM 则是车辆动力学仿真的天花板。在做 GB/T 47025 附录 G 要求的紧急避险测试时,必须精确知道车在急刹那一瞬间的俯仰角和轮胎摩擦力,这时候 dSPACE 这种深厚的汽车工业底蕴就显现出来了。
4. 国内力量的崛起。这个国内也经历了快速发展报告,出现了很多新的仿真工具,包括济达的tessng,panosim,51sim等等,此外,我们也可以在 GB/T 47025 的起草单位中,看到华为、百度、赛目科技、中汽中心等国内企业的身影。这意味着国内的工具链正在紧密围绕这套国标进行定制化开发,特别是在中国特色的道路环境(如人车混行、复杂路口)模拟上,国产工具有着天然的本土化优势。
三、 对照新国标:我们到底要测什么?
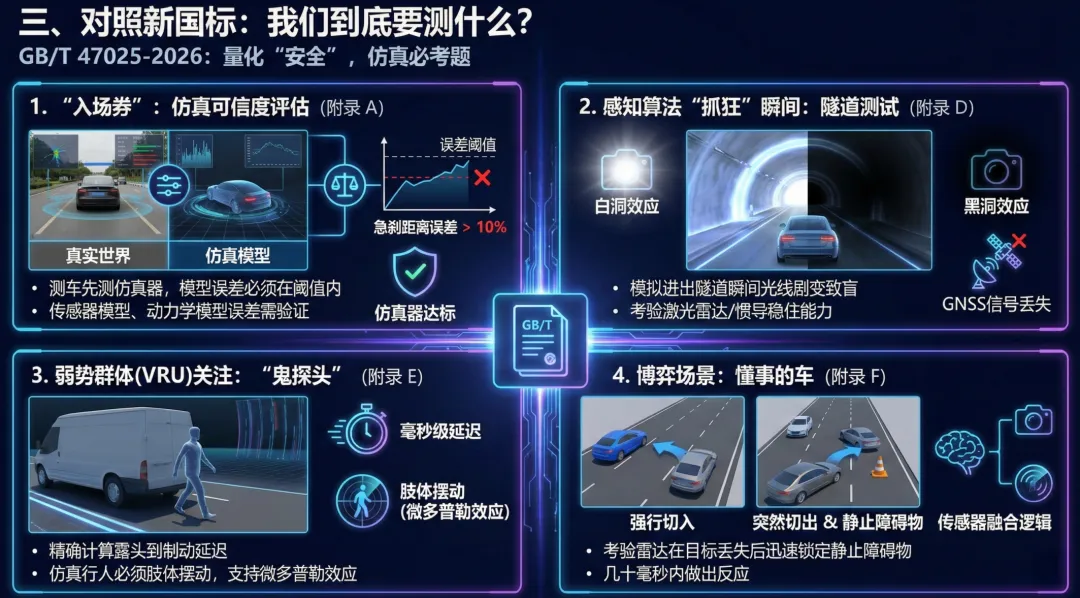
GB/T 47025-2026 的厉害之处,在于它把模糊的“安全”二字,拆解成了数百个具体的、可量化的场景。如果不通过这些“考试”,车是不能上路的。
首先是“入场券”——仿真可信度评估(附录 A)。这是我非常认同的一点:在测车之前,先得测“仿真器”本身准不准。需要证明自动驾驶的传感器模型、动力学模型与真实世界的误差在阈值之内。如果模拟的急刹车距离比现实短了 10%,那所有的安全验证都是空中楼阁。
其次是那些让感知算法“抓狂”的瞬间。比如隧道测试(附录 D)。标准要求的不仅仅是跑通隧道,而是要模拟进出隧道口时那瞬间的“白洞/黑洞效应”导致摄像头致盲,以及 GNSS 信号丢失。这时候车能不能靠激光雷达或惯导稳住,是必考题。
再比如对弱势群体(VRU)的关注(附录 E)。最典型的就是“鬼探头”——行人从遮挡物后突然出现。在现实中测这个太危险,但在仿真里,我们可以精确计算从行人露头到系统触发制动的毫秒级延迟。标准甚至要求仿真器支持行人的肢体摆动,因为现在的雷达算法是靠微多普勒效应来识别行人的,如果仿真里的人是僵硬滑行的,那就测不出真东西。
还有博弈场景(附录 F)。现在的车不仅要看路,还要“懂事”。比如旁边的车强行切入(Cut-in),或者前车突然切出(Cut-out)暴露出前方的静止障碍物。这考验的是传感器融合的逻辑——雷达能不能在丢失前车目标后的几十毫秒内迅速锁定那个静止的交通锥。
四、 未来的风向:AI 正在重塑仿真
写到最后,我想谈谈未来的趋势。虽然现在的工具已经很强,但建模成本依然高得吓人。不过,AI 技术的爆发正在改变这一切。
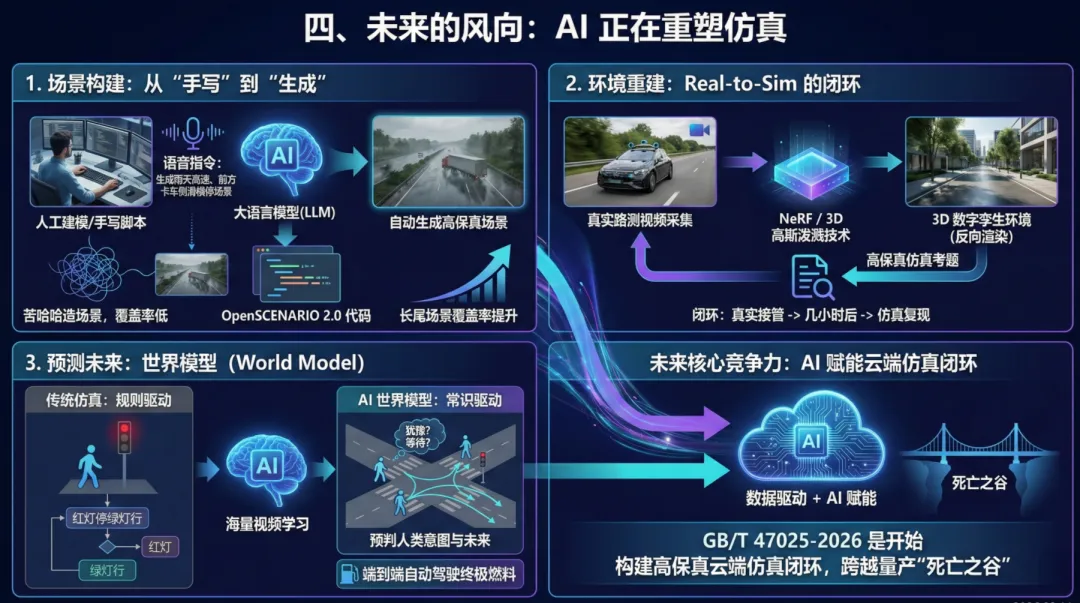
1. 场景构建:从“手写”到“生成”以前工程师要苦哈哈地写脚本造场景,未来结合大语言模型(LLM),我们可能只需要说一句“生成一个雨天高速、前方卡车侧滑横停的场景”,AI 就能自动写出符合 OpenSCENARIO 2.0 的代码,极大提升了对长尾场景的覆盖能力。
2. 环境重建:Real-to-Sim 的闭环NeRF(神经辐射场)和 3D 高斯泼溅技术的出现,意味着我们可以把路测车拍回来的视频,直接“反向渲染”成 3D 数字孪生环境。每一次真实路测中的接管事件,几小时后就能变成仿真里的高保真考题,实现了真正的闭环。
3. 预测未来:世界模型(World Model)传统的仿真里,行人的行为是规则写的(红灯停绿灯行)。但未来的世界模型是让 AI 通过学习海量视频,拥有“常识”。它能预判这个路人在路口是在犹豫还是在等待,这种对未来的预测能力,才是端到端自动驾驶训练的终极燃料。
总而言之,GB/T 47025-2026 的发布只是一个开始。对于车企和供应商来说,未来的核心竞争力不再仅仅是车上的那个算法,而是谁能构建起一套由数据驱动、AI 赋能的高保真云端仿真闭环。这不仅是为了过审,更是为了跨越量产前那道最凶险的“死亡之谷”。