🚗 自动驾驶决策,既要“聪明”又要“快”!还在为生成式策略的推理速度发愁?「龙哥读论文」知识星球每日速递前沿算法,让你第一时间掌握像DACER-F这样的“性能加速器”!👇扫码加入,解锁更多AI前沿干货,让你的研究也驶上快车道~

龙哥推荐理由:
这篇论文精准地戳中了当前生成式强化学习策略在自动驾驶等实时决策场景下的核心痛点——推理速度慢。它没有在复杂的扩散模型上继续“卷”采样步数,而是巧妙地转向了流匹配(Flow Matching),并结合朗之万动力学解决了在线学习中的目标分布难题。最终实现了单步推理、性能提升、速度飞跃的三重胜利,思路清晰,实验扎实,对推动生成式策略的实际落地非常有价值。
原论文信息如下:
论文标题:
Real-Time Generative Policy via Langevin-Guided Flow Matching for Autonomous Driving
发表日期:
2026年03月
发表单位:
清华大学
原文链接:
https://arxiv.org/pdf/2603.02613v1.pdf
想象一下,你坐在一辆自动驾驶汽车里。前方有车突然减速,左边车道有空位,但后面有车快速接近。一个完美的AI司机应该在几十毫秒内做出判断:是刹车,还是安全地变道超车?这个决策过程,在AI领域对应的是强化学习(Reinforcement Learning, RL)中的“策略”。近年来,一种叫“生成式策略”的技术火了。它不像传统方法只输出一个“最优”动作,而是能像大师厨师一样,根据当前“食材”(环境状态),构思出多种可能的“菜谱”(动作分布),从而在面对复杂、不确定的路况时更灵活、更安全。但问题来了:这些强大的生成式策略,比如基于扩散模型(Diffusion Model)的,有个致命弱点——“慢”。生成一个动作需要几十甚至上百步的迭代采样,推理延迟(Inference Latency)太高,根本达不到自动驾驶实时控制的要求(通常要求毫秒级)。这就好比你的自动驾驶AI是个米其林大厨,每做一个“转弯”还是“刹车”的决定,都得在厨房里精心雕琢半天,等它想好,车早就撞上了😅。有没有办法让这位“大厨”既保持高超的厨艺(强大的建模能力),又能像快餐厨师一样“出餐”神速呢?来自清华大学的研究团队给出了一个漂亮的答案:DACER-F。这个算法的全称是“Diffusion Actor-Critic with Entropy Regulator via Flow Matching”, 名字有点长,但核心思想很明确:用“流匹配”代替“扩散”,实现生成式策略的单步推理。下面,龙哥就带大家拆解一下,这篇论文是如何实现这个“既要又要”的魔法🪄。解决生成式策略的“慢”痛点:从扩散到流匹配
要理解DACER-F的巧思,我们得先看看它要替代的“前辈”——扩散模型策略为啥慢。简单来说,扩散模型生成数据(比如图片,或者这里的“动作”)的过程,就像是把一团毛线(随机噪声)慢慢捋顺,还原成一件毛衣(目标数据)。这个过程是迭代的、多步的,每一步都要计算一下该往哪个方向“捋”。步数越多,还原得越精细,但耗时也越长。而流匹配(Flow Matching)走了另一条路。它学习的不是一个“逐步去噪”的过程,而是一个“速度场”。想象一下,你面前有一条从噪声源(比如一个装满随机点的盒子)到数据目标(比如一个猫猫图片的形状)的直线管道。流匹配模型要学的,就是管道里每个位置、每个时间点,粒子应该以多快的速度、向哪个方向流动。一旦这个“速度场”学好了,生成就变得极其简单:从噪声源扔一个点进去,沿着学到的速度场“嗖”地一下,一步到位就被推到目标位置,变成猫猫图片的一部分。这就是单步推理的奥秘!用论文里的数学语言描述,对于给定的初始噪声 a₀ 和目标动作样本 a₁,它们之间在时间 t 的线性插值是: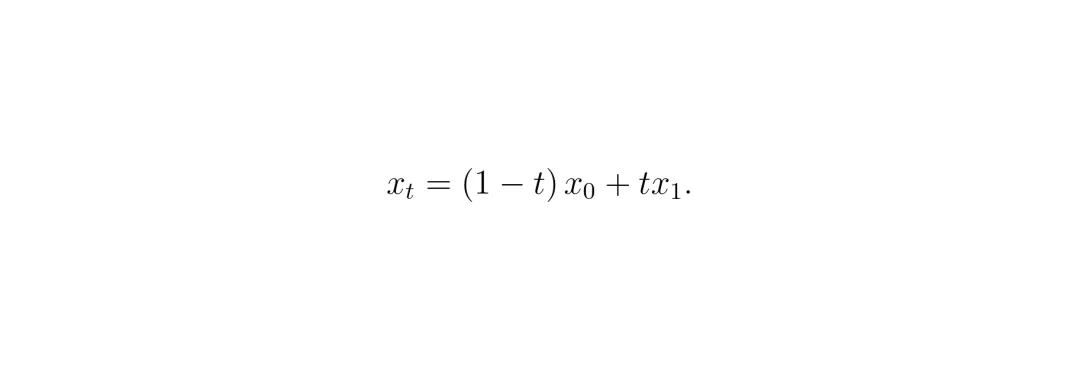
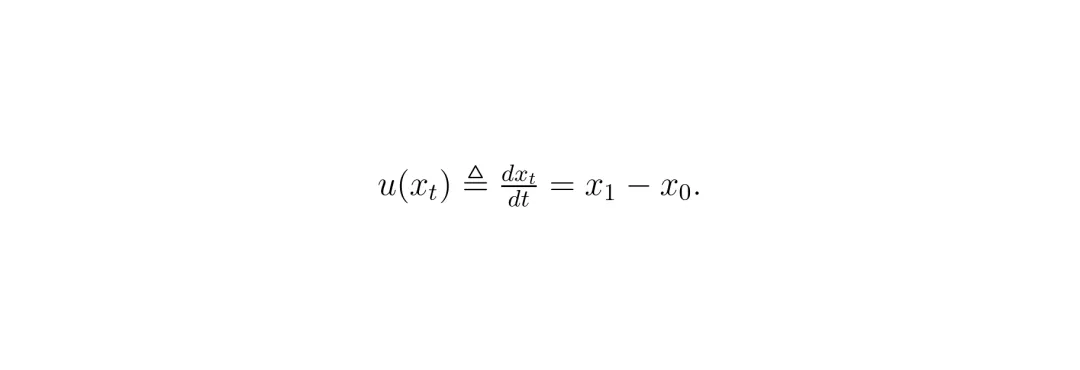 模型要学习一个神经网络
模型要学习一个神经网络 vθ 去拟合这个速度场,损失函数就是简单的均方误差: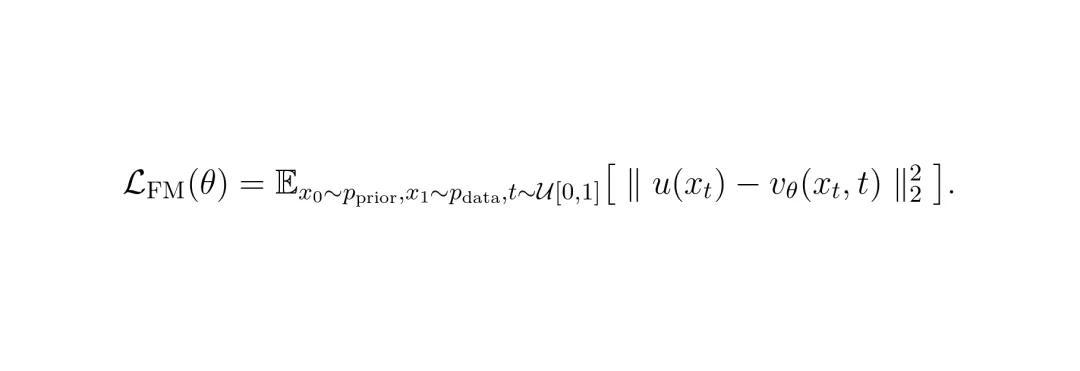 看,训练目标很清晰:让模型预测的速度,等于目标动作和噪声之间的向量差。推理时,只需对学到的速度场进行一次积分(实践中常用欧拉法离散化,近似为一步或几步),就能得到动作:
看,训练目标很清晰:让模型预测的速度,等于目标动作和噪声之间的向量差。推理时,只需对学到的速度场进行一次积分(实践中常用欧拉法离散化,近似为一步或几步),就能得到动作: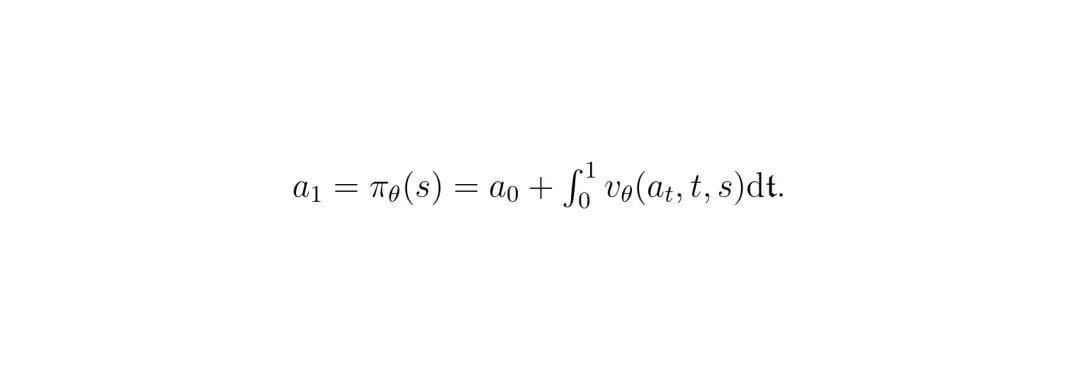 思路很美好,对吧?但这里有一个巨大挑战:训练流匹配模型需要一个明确的目标分布
思路很美好,对吧?但这里有一个巨大挑战:训练流匹配模型需要一个明确的目标分布 p_target(a|s),也就是要知道“好的动作”长什么样。这在图像生成里不是问题,因为你有成千上万张猫猫图片作为目标。但在在线强化学习里,智能体是在和环境的交互中不断学习的,根本没有一个现成的、固定的“好动作数据集”给你模仿!这就引出了DACER-F最核心的创新:如何在没有固定目标的情况下,为流匹配模型动态地创造高质量的训练目标?朗之万动力学:在线RL中“无目标”困境的破局者
既然没有现成的“好动作”可以抄,那就自己“烹制”出来!DACER-F的答案是:利用“价值函数”(Q函数)作为指导,通过朗之万动力学(Langevin Dynamics)来“优化”出高质量的备选动作。Q函数(Q-function):在强化学习中,Q(s, a) 代表了在状态 s 下执行动作 a 后,所能获得的长期累积奖励的期望值。你可以把它理解为一个动作的“得分”或“美味程度”。Q值越高,说明这个动作在当前状态下越“好”。
朗之万动力学(Langevin Dynamics):这是一种常用于从复杂概率分布中采样的数学方法。想象一下,你想在一片高低起伏的山地(概率分布,高处概率大)里随机漫步,但同时你又有点“懒”,总想往更高的地方(梯度上升)走。朗之万动力学就是你走一步(梯度方向),然后再加上一点随机的小晃动(噪声)。这样,你既会倾向于走向山峰(高概率/高价值区域),又不会完全失去随机探索的能力。
DACER-F的核心假设是:最优的策略分布,可以看作是一个由Q函数定义的能量模型(Energy-Based Model):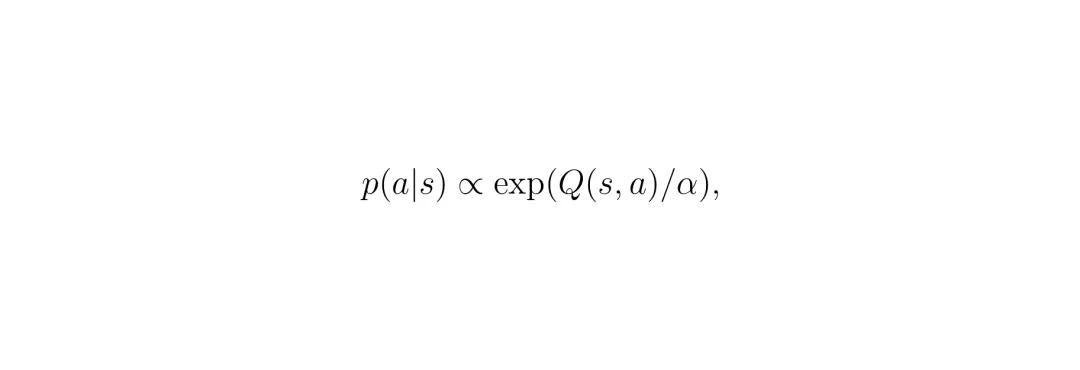 其中 α 是一个温度参数,控制探索的程度。这个公式非常直观:动作的概率与其Q值的指数成正比。Q值越高的动作,被选中的概率就越大。那么,如何从这个分布里得到样本(即“好动作”)呢?最直接的想法是沿着Q函数的梯度方向“爬坡”:
其中 α 是一个温度参数,控制探索的程度。这个公式非常直观:动作的概率与其Q值的指数成正比。Q值越高的动作,被选中的概率就越大。那么,如何从这个分布里得到样本(即“好动作”)呢?最直接的想法是沿着Q函数的梯度方向“爬坡”: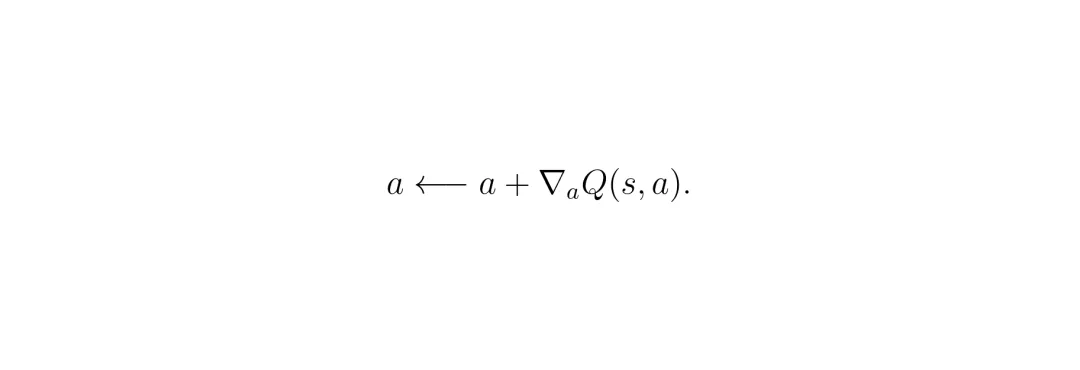 但论文指出,这样做容易让策略变得过于“贪婪”和“确定性”,只找到局部高点,失去了对分布本身多样性的探索。因此,DACER-F采用了更优雅的朗之万动力学采样。它从经验回放缓冲区中取出一个历史动作作为起点,然后迭代地应用以下更新:
但论文指出,这样做容易让策略变得过于“贪婪”和“确定性”,只找到局部高点,失去了对分布本身多样性的探索。因此,DACER-F采用了更优雅的朗之万动力学采样。它从经验回放缓冲区中取出一个历史动作作为起点,然后迭代地应用以下更新: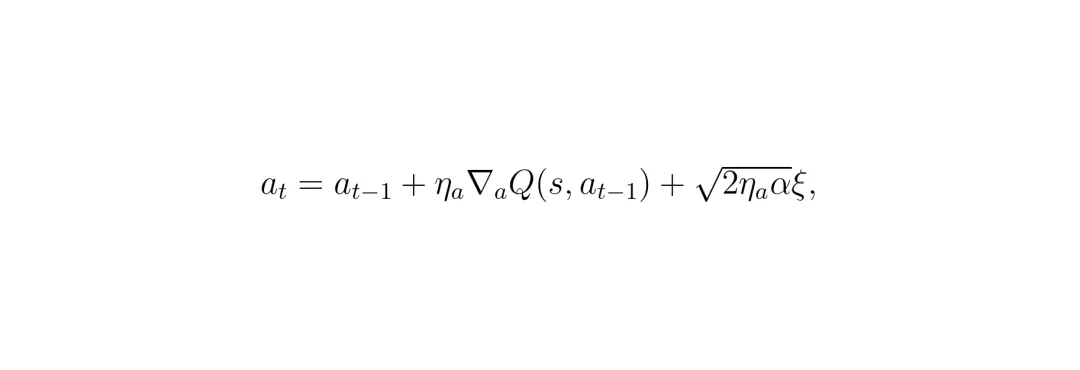 这里的
这里的 η_a 是步长,ξ 是高斯噪声。这个过程就像一位美食家在品鉴一道菜(历史动作),他根据自己对“美味”(Q值)的理解,对菜进行一些“微操”(梯度提升),但同时也会加入一点点“即兴发挥”(噪声)。经过几轮这样的“优化”,最终得到一道色香味(Q值)更佳、且富有新意(探索性)的升级版菜肴,我们称之为 a*。这个 a*,就是流匹配模型梦寐以求的高质量、动态生成的目标动作样本!DACER-F核心算法:如何实现高效单步决策
现在,我们已经有了两个核心武器:①单步生成的流匹配策略模型,②通过朗之万动力学生成的动态目标动作 a*。DACER-F 巧妙地将它们结合起来。整个算法的损失函数设计得非常精妙,是一个混合目标,这个损失函数包含两部分:1. 策略提升项(-Q(s, πθ(s))):这是标准的强化学习目标,目的是直接提升流策略自身输出动作的Q值,鼓励它做出能获得更高回报的决定。
2. 流匹配模仿项(λ_f || vθ(...) - (a* - a₀) ||²):这就是我们前面讲的核心!它训练流策略的速度场,去匹配从噪声 a₀ 到优化后目标动作 a* 的向量。这样一来,流策略就学会了如何“一步到位”地生成像 a* 一样好的动作。
这里的权重 λ_f 也设计得很聪明,它是一个动态的、基于优势(Advantage)的系数:λ_f ∝ ReLU(Q(s, a*) - Q(s, a_B))。其中 a_B 是回放缓冲区中的原始动作。这意味着,只有当朗之万动力学优化出来的动作 a* 确实比原来的动作 a_B 更好(Q值更高)时,模型才会重点去模仿 a*。如果优化没效果,模仿的权重就会降低,避免学坏。这个设计保证了训练的稳定性和效率。此外,为了稳定Q值的估计,论文还采用了双Q网络(Double Q-networks)和目标网络(Target Networks)这些强化学习中的常用技巧。训练时:用朗之万动力学从历史经验中“炼制”出更好的动作样本 a*,然后让流匹配策略去学习模仿这个“升级版样本”,同时也不忘通过Q值直接优化自己。
推理/部署时:流匹配策略模型已经学成,对于任何新的状态,只需要进行一次前向传播,就能瞬间生成高质量的动作。朗之万动力学的优化过程只在训练阶段进行,不增加推理时的任何延迟!妙啊!这就好比在厨师学校(训练阶段),老师(朗之万动力学)手把手教学生(流策略)如何改良一道菜;等学生毕业成了大厨(部署阶段),他就能凭借肌肉记忆(学好的流模型),看一眼食材(状态)就飞快地炒出一盘好菜(动作),再也不需要老师在旁边指导了。实验验证:自动驾驶与通用控制的双重胜利
理论说得天花乱坠,是骡子是马还得拉出来溜溜。论文在两类场景中进行了全面测试:自动驾驶模拟和通用机器人控制基准。作者构建了复杂的多车道高速公路和城市十字路口模拟环境,包含了变道、超车、转弯、避让等复杂交互。奖励函数综合了轨迹跟踪、控制平顺性、乘坐舒适度和安全性(详见论文中的表I)。DSAC (Distributional Soft Actor-Critic):基于分布价值函数的先进算法,但策略是单峰高斯分布,表达能力有限。
DACER (Diffusion Actor-Critic with Entropy Regulator):基于扩散模型的生成式策略,是DACER-F的直接“前身”,在论文中配置了20步采样以达到最佳性能。
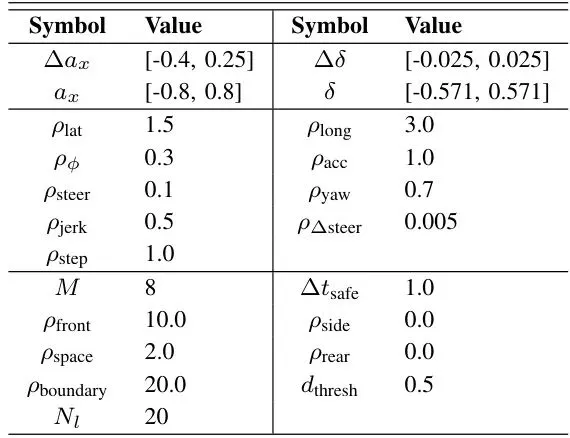
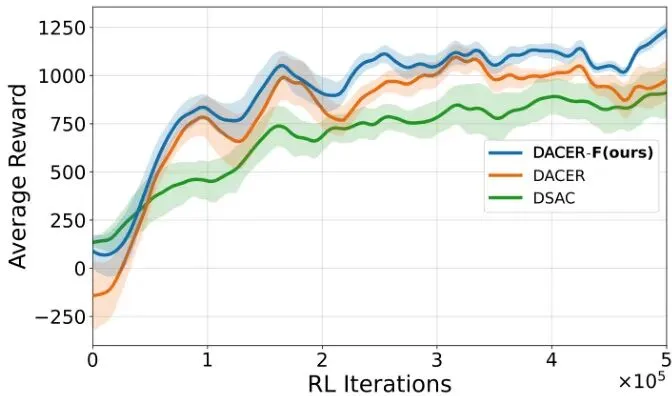
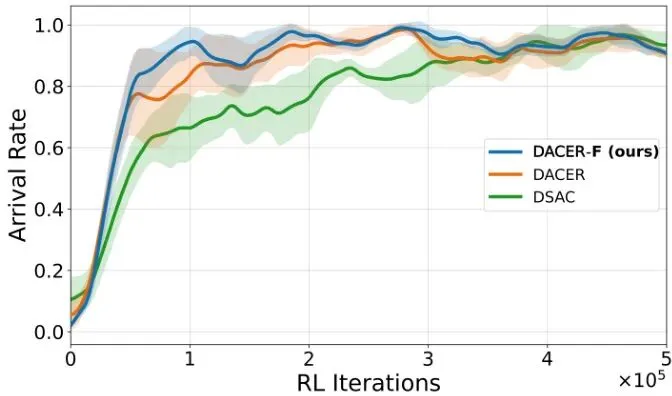
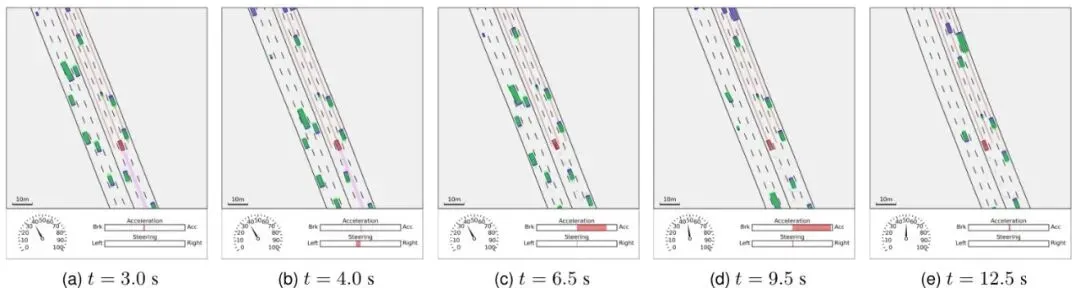
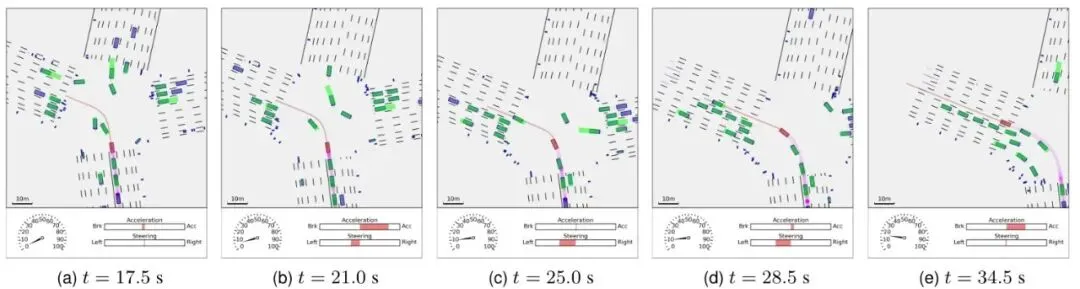
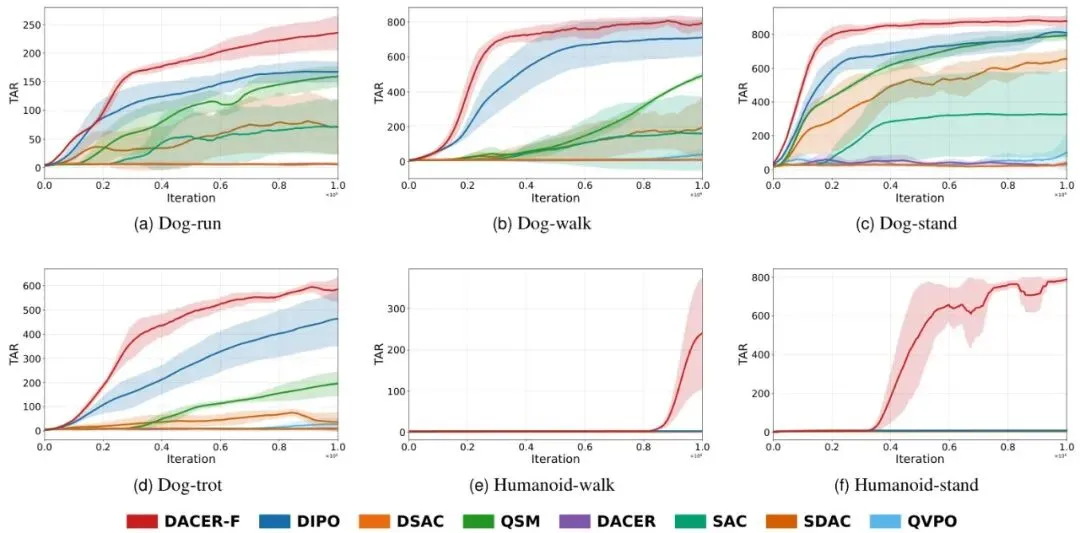
从总平均奖励(TAR)来看,DACER-F展现了最快的收敛速度和最高的最终性能。最终,DACER-F的TAR达到1238,分别比DACER(967)和DSAC(924)高出约28.0%和34.0%。在任务完成率(到达率)和安全性(碰撞率)指标上,DACER-F同样表现优异,学习效率高且早期就很稳定。可视化案例更是生动地展示了DACER-F策略的智能。在高速公路场景中,它能平滑、安全地完成变道超车;在十字路口,它能准确判断车流间隙,安全地完成左转。为了证明DACER-F不是个“偏科生”,论文还在著名的DeepMind控制套件(DMC)上进行了测试,包含了人形站立/行走、狗小跑/站立/行走/奔跑等6个高维连续控制任务。结果令人震惊!DACER-F在所有六个任务上均取得了最佳的平均回报,大幅超越了包括SAC、DSAC、DACER在内的七个代表性基线算法。特别是在最具挑战性的“人形站立”任务中,DACER-F取得了775.8的平均分,而DACER和SAC分别只有8.1和6.9,差距接近两个数量级!这个结果表明,DACER-F提出的朗之万引导的流匹配框架具有极强的通用性和可扩展性,不仅能用于自动驾驶,也能解决更广泛的机器人控制问题。极速推理:实时部署的关键指标分析
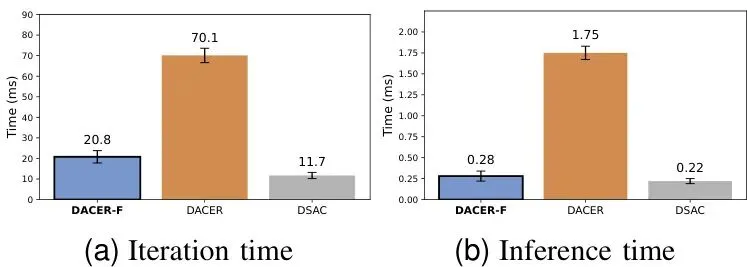
性能好是一方面,但我们最初的目标——“快”,实现得怎么样?论文对训练效率(迭代时间)和部署效率(推理时间)进行了详细分析。训练效率:DACER-F的平均迭代时间为20.8毫秒,比需要20步采样的DACER(70.1毫秒)快了3.37倍。虽然比MLP结构的DSAC(11.7毫秒)慢一些,但作为生成式策略,这个训练速度已经非常高效。
推理效率(核心!):DACER-F的单步推理时间仅需0.28毫秒!这比DACER的1.75毫秒快了6.25倍,时间减少了84%。更重要的是,0.28毫秒的延迟已经和轻量级的MLP策略DSAC(0.22毫秒)处于同一数量级。
这意味着什么?意味着DACER-F成功实现了最初的目标:在保持生成式策略强大建模能力的同时,达到了与传统高效策略相近的推理速度,完全满足自动驾驶等实时控制场景的严苛要求。总结与展望:生成式RL的未来之路
DACER-F这篇工作,为生成式强化学习策略的实际部署打开了一扇新的大门。它没有在“如何加速扩散模型”这个艰难问题上死磕,而是巧妙地更换了“赛道”,选择了天生具有快速推理潜力的流匹配模型。其最关键的创新在于,用朗之万动力学解决了在线RL中流匹配缺乏目标分布的“鸡生蛋”问题,创造性地将价值函数指导、动态目标采样和高效单步生成结合在了一起。实验结果无可辩驳地证明,这套方法是有效的:性能显著超越基线,推理速度实现数量级提升,且具备优秀的泛化能力。未来,基于流匹配的生成式RL可能会有更多探索,例如:如何设计更高效的朗之万采样过程?能否将这种方法与基于模型的RL结合?在多智能体协作场景中表现如何?DACER-F无疑为这些方向奠定了一个坚实且充满希望的起点。龙迷三问
这篇论文解决的核心问题是什么?解决生成式强化学习策略(特别是基于扩散模型的)在实时决策场景(如自动驾驶)中推理速度过慢的问题。目标是让策略在保持强大表达能力(能处理复杂、多模态动作分布)的同时,实现毫秒级的快速单步决策。
流匹配(Flow Matching)和扩散模型(Diffusion Model)的根本区别是什么?核心区别在于数据生成的路径和方式。扩散模型学习一个“逐步去噪”的随机过程,需要多步迭代,慢但精细。流匹配学习一个确定性的“速度场”,数据点沿着这个场从噪声源“流”到目标位置,通常可以一步或很少几步完成生成,速度快但需要明确的目标分布。
朗之万动力学在这里具体起到了什么作用?它扮演了“目标动作炼制师”的角色。在在线RL没有固定好动作数据集的情况下,它利用当前的Q函数作为“美味标准”,对经验回放中的历史动作进行“优化”。通过“梯度提升(往高Q值方向走)+ 随机噪声(保持探索)”的迭代,产生出质量更高且兼具探索性的动作样本 a*,为流匹配模型提供了动态的训练目标。这个优化过程只在训练阶段进行,不影响推理速度。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆
将流匹配引入在线RL并巧妙地用朗之万动力学解决目标分布问题,思路清晰且有突破性,不是简单的模块堆砌。实验合理度:★★★★★
实验设计非常扎实,覆盖了专用领域(自动驾驶模拟)和通用基准(DMC),对比了当前主流的SOTA方法,指标全面(性能、安全、速度),结果呈现清晰且有统计意义。学术研究价值:★★★★★
为生成式RL的策略部署提供了新的范式,证明了流匹配在该领域的巨大潜力,很可能启发后续一系列围绕流匹配+RL的研究工作,具有很高的引领价值。稳定性:★★★★☆
从实验曲线看,训练过程稳定,碰撞率等安全指标没有剧烈波动。混合损失函数中的动态权重设计也增强了稳定性。但朗之万采样的超参数(步长、步数、温度)可能需要针对新任务进行微调。适应性以及泛化能力:★★★★☆
在DMC上的卓越表现证明了其强大的跨领域泛化能力。方法本身不依赖于特定环境结构,理论上适用于任何连续动作空间的RL问题。硬件需求及成本:★★★★☆
推理成本极低(单步前向传播),与简单MLP策略相当,适合边缘部署。训练成本由于需要运行朗之万采样和训练流网络,比非生成式方法略高,但仍远低于多步扩散模型训练。复现难度:★★★☆☆
算法描述清晰,关键步骤有伪代码。但实现涉及流匹配、朗之万动力学、双Q学习等多个组件,集成有一定复杂度。论文未提及代码是否开源。产品化成熟度:★★★★☆
在模拟环境中已展现出可直接产品化的潜力:高性能、高安全、低延迟。下一步需要进入真车实测阶段,验证其对真实传感器噪声、复杂博弈场景的鲁棒性。可能的问题:论文实验充分,方法扎实,暂无明显硬伤。一个可能的延伸思考是:朗之万采样过程本身的计算开销,在训练非常复杂的策略时是否会成为瓶颈?以及对于高维动作空间,如何保证采样的效率和覆盖度。
[1] Tianze Zhu, Yinuo Wang, Wenjun Zou, et al. Real-Time Generative Policy via Langevin-Guided Flow Matching for Autonomous Driving. arXiv preprint arXiv:2603.02613, 2026.[2] GOPS Software. 用于大规模强化学习算法训练的开源平台。[3] DeepMind Control Suite. 一个用于连续控制研究的基准测试环境。*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

想和更多自动驾驶、机器人领域的大佬们一起探讨“快车道”上的新算法吗?
欢迎加入龙哥读论文粉丝群,扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 自动驾驶+北京+清华+龙哥),根据格式备注,可更快被通过且邀请进群。