理想汽车摊牌了:别再只看自动驾驶,这才是未来汽车的终极形态
理想汽车最近在NVIDIA GTC大会上发布了下一代自动驾驶基础模型MindVLA-o1,这事儿听起来可能有点技术化,但它揭示的信号,远比“辅助驾驶又升级了”要重要得多。理想汽车基座模型负责人詹锟的演讲,几乎是在明示,未来汽车竞争的终点,可能不是我们现在想的样子。那么,这个新模型到底意味着什么?它会如何改变我们对智能汽车的认知?汽车学会“脑补”了,这和看懂路况是两码事
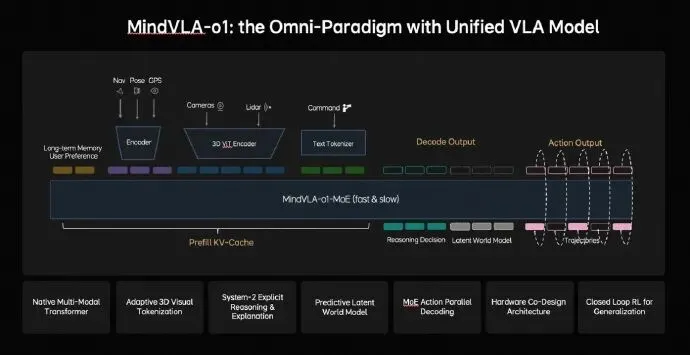
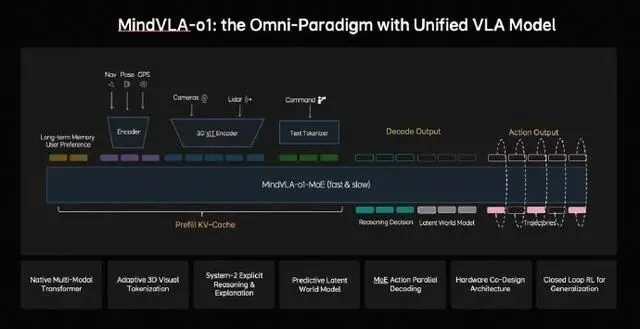
过去我们聊自动驾驶,核心是“感知”,也就是车能不能看清路上的线、识别旁边的车。但这本质上还是在处理平面的、当下的信息。理想的MindVLA-o1第一个颠覆性的地方,就是让车从“看清”进化到了“理解”。它融合了摄像头和激光雷达,通过3D编码器,让车能像人一样感知物体的远近、深浅和动态。说白了,它看到的不再是一张张照片,而是一个立体的、正在运动的真实世界。但问题是——光看懂还不够。真正厉害的是,这个模型学会了“脑补”未来。它内置了一个“隐世界模型”,可以在一个虚拟空间里,提前推演接下来几秒钟可能发生的各种情况。你仔细想想,这和人类老司机开车前的预判一模一样。比如,看到路边一个滚动的球,老司机脑子里会立刻“脑补”出可能会有孩子冲出来。MindVLA-o1做的就是类似的事,它把思考从二维推向了多维,从“当下”延伸到了“未来”。开得丝滑不是重点,能自我进化才是关键
很多人评价一套辅助驾驶好不好用,标准是“开得像不像人”、“丝不丝滑”。理想这次提出的“统一行为生成”架构,确实能让车辆的行驶轨迹更符合物理规律,避免那种突兀的加减速。它通过一个叫VLA-MoE的架构,让“动作专家”一次性生成所有轨迹点,然后像“去噪”一样优化,确保行驶平顺。但很多人其实忽略了一点,比开得好更重要的,是它如何学会开得更好。这就要提到它的“闭环强化学习”能力。理想搞了一个强大的世界模拟器,让这个AI司机不仅能在马路上积累经验,更能在虚拟世界里进行海量、高强度的“魔鬼训练”。(说实话,这一点才是最吓人的地方)这意味着它的进化速度是指数级的,今天处理不了的疑难路况(Corner Case),可能在虚拟世界里模拟几百万次后,明天就轻松解决了。这种进化效率,是单纯靠路测数据喂养的传统模式无法比拟的。真正的价值:它不只想当个司机
聊到这里,你可能觉得理想只是在技术上做了一次大升级。但詹锟的演讲揭示了更深层的野心。他说,当视觉、语言和行动统一到一个模型里时,它就不再只是一个自动驾驶模型,而是在演化为“面向物理世界的通用智能体”。这句话是什么意思?意思是理想汽车MindVLA-o1的目标,根本不只是开车。这套以视觉-语言-动作为核心的VLA模型,是一套通用的“大脑”,理论上可以驱动任何物理世界的机器。今天它装在车里,控制方向盘和电门,明天它就可以装在机器人身上,控制机械臂。自动驾驶,只是这套物理世界AI的第一个应用场景。所以,未来车企的竞争,可能不再是谁的续航更长、谁的零百加速更快,甚至不是谁的辅助驾驶功能更多。竞争的核心,会变成谁能打造出更强大的、能够理解并与物理世界交互的“通用智能体”。软硬件协同,决定了梦想何时照进现实
当然,再强大的模型,如果不能流畅地跑在车端的芯片上,那也只是空中楼阁。理想这次也强调了“软硬件协同设计”的重要性。他们通过研究模型精度和硬件延迟之间的平衡,把架构设计的时间从几个月缩短到了几天。这听起来很技术,但它解决了一个核心的商业问题:如何让顶尖的AI技术,以合理的成本和功耗,真正落地到量产车上。这决定了我们消费者什么时候能真正用上这些听起来很科幻的功能。一个再聪明的“大脑”,如果需要一台超级计算机才能运行,那它对普通人就毫无意义。理想正在做的,就是把这个“大脑”小型化、高效化,让它能装进我们买得起的车里。真正的智能汽车,比的不是功能,而是“智商”的成长性
很多人纠结自动驾驶的级别,其实真正决定未来的不是功能,而是智能的成长性。传统车企造车像是在写一本说明书,功能出厂即固定。而以理想MindVLA-o1为代表的新一代模型,让造车变成养一个孩子,它的能力是不断学习和进化的。这两种模式的差距,在未来几年会越拉越大。如果只是为了一个更丝滑的自动跟车,那市面上很多车型都能做到。但我认为,理想这次展示的,是对未来汽车终极形态的一次预演。它不再是一个冰冷的交通工具,而是一个能够理解世界、预测未来、并不断自我进化的智能伙伴。所以,我的判断是,未来我们买车,看的可能不再是配置表,而是这台车背后的“AI模型版本号”。