26年2月来自上海博世和上海大学的论文“HiST-VLA: A Hierarchical Spatio-Temporal Vision-Language-Action Model for End-to-End Autonomous Driving”。
视觉-语言-动作(VLA)模型通过多模态理解为自动驾驶提供了广阔的应用前景。然而,由于其固有的局限性,例如数值推理不够精确、三维空间感知能力较弱以及对上下文高度敏感,VLA模型在安全关键场景中的应用受到限制。为了应对这些挑战,提出HiST-VLA,一种分层时空VLA模型,旨在生成可靠的轨迹。该框架通过将几何感知与细粒度的驾驶指令和状态历史提示相结合,增强三维空间和时间推理能力。为了确保计算效率,将动态token稀疏化集成到VLA架构中。这种方法融合冗余token而非过滤它们,从而在不牺牲模型性能的前提下有效降低冗余度。此外,采用基于Transformer的分层规划器,将粗粒度的VLA路径点逐步细化为细粒度的轨迹。至关重要的是,该规划器利用动态潜正则化来整合语言指令,从而确保严格的空间定位和时间一致性。
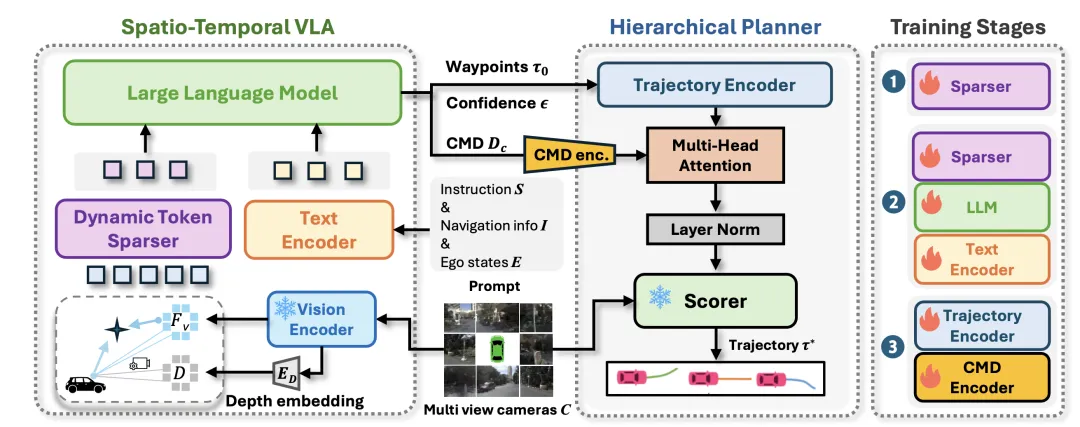
HiST-VLA将感知、语义推理和轨迹规划集成到一个统一的架构中。该框架包括:(1)一个统一的架构,结合三维感知几何表示和语义推理,用于多阶段轨迹细化;(2)一个时空VLA骨干网络,具有多视角三维理解、时间建模、CoT推理和动态token稀疏化等特性,以减少冗余;(3)一个分层规划器,通过语义条件化和多准则评分,从粗略的VLA输出生成连续轨迹。
HiST-VLA框架
如图所示,时空VLA和分层规划器通过多阶段过程实现空间定位、时间建模和精确轨迹细化。时空VLA作为主要策略生成器,负责生成初始驾驶规划和粗略轨迹。给定当前时间步t的多视角相机输入C,时空VLA首先通过视觉编码器处理视觉输入以获得F_v。然后,利用深度估计ED进一步增强该表示,并通过动态token稀疏器处理组合的3D视觉特征,生成空间感知的视觉token。同时,指令 S、过去 k 帧的时间序列导航信息 I = (i_t , i_t−1 , ..., i_t−k ) 以及时间序列自车状态 E = (e_t,e_t−1,...,e_t−k) 由文本编码器进行编码。这些视觉token和文本嵌入随后被输入到大语言模型 (LLM) 中。经过 CoT 推理过程后,该模型基于推理步骤自回归生成三个输出:接下来四秒的细粒度驾驶指令 D_c、置信度为 ε 的候选轨迹 τ_0。
然后,分层规划器优化粗略轨迹 τ_0。它首先使用 VAE 将 τ_0 编码到潜空间,然后将其与细粒度驾驶指令 D_c 进行语义对齐。然后,多准则评分器评估可行性、安全性和舒适性,并通过加性偏移进行优化,生成最优轨迹 τ∗。这种多阶段优化机制构成分层规划策略的核心,实现从粗略轨迹和语义意图到精确运动的逐步优化。
时空 VLA 模型
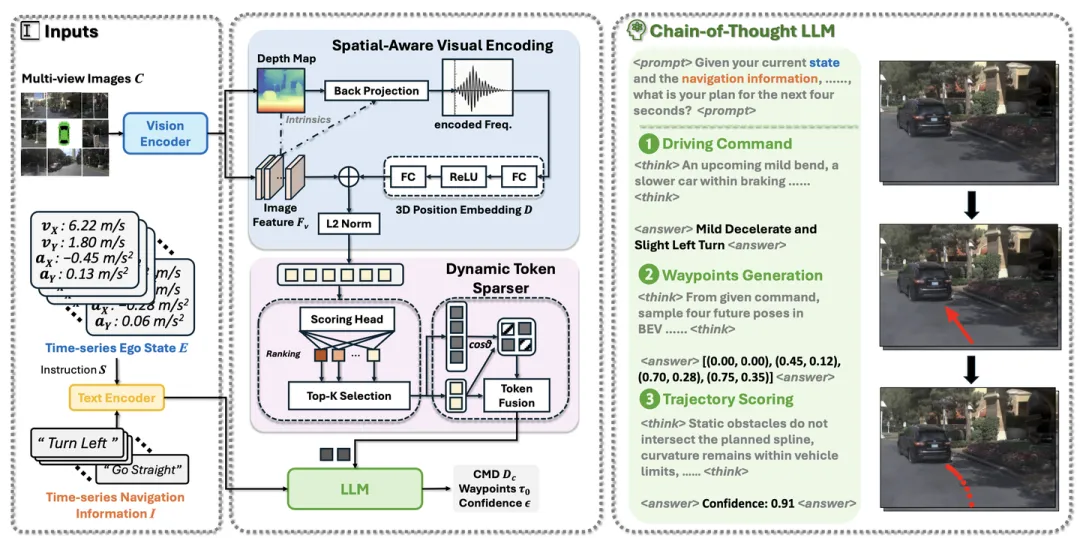
如图展示时空 VLA 模型,该模型整合空间感知视觉输入和时间历史信息,从而实现结构化推理。
1) 空间感知视觉编码:用 CLIP [30] 中的 ViT-L/14 作为视觉编码器,从多视角图像中提取 2D 图像块特征。为了恢复 3D 场景几何结构,用预训练的单目深度估计器 [31] 生成密集深度图。利用相机内参,将每个二维图像块反投影到自车的三维坐标系中。然后,使用多层感知器(MLP)对生成的三维坐标进行编码,并嵌入位置信息,并将编码后的三维信息添加到原始的二维特征中。此过程生成空间增强的视觉token,这些token明确地编码了场景的度量结构。
2)动态token稀疏器:与传统方法(即应用 MLP 对所有图像token进行等比例变换而不进行显式选择 [2]、[32])不同,本文方法利用图像token的固有自注意得分进行自适应token稀疏化。该模块基于块内联合token剪枝和压缩(eTPS)[33] 构建。通过保留具有高自注意激活的token并合并不太显著的token,实现更高效且特征感知的视觉token缩减。保留信息量最大的前 k 个token,其余token则通过一个可学习的基于 Transformer 的融合模块自适应地合并到保留的token中。这种自相似性引导的合并机制在保留结构关键区域的同时,减少了计算序列的长度。最终得到的压缩视觉token被投影到 LLM 的嵌入空间,以实现高效的多模态交互。
3) 时间状态建模:此外,为了增强生成的驾驶指令和轨迹的流畅性和舒适性,将时间建模融入到文本提示中。具体来说,前 k 帧的长期导航信息 I(离散机动标签:左转、直行、右转 [11])和自车状态 E(纵向/横向速度:v_x、v_y、a_x、a_y)被用作当前步骤 t 提示的一部分。上述文本连同用户指令(预计未来四秒的驾驶意图和航点是什么?)一起插入到提示框中。这种提示条件将模型从反应函数 π(a_t|s_t) 转换为更具信息量的函数 π(a_t|s_t, s_t−1, ..., s_t−k),其中 s_t = (i_t, e_t),从而提高时间一致性,减少指令的突变,并产生更连续、更人性化的轨迹规划,更好地符合用户的舒适度预期。
4) 细粒度元动作和置信度-觉察的轨迹推理增强型CoT:CoT执行结构化推理以生成合理的驾驶动作。基于融合的多模态输入,LLM首先分析自我状态和感知到的场景上下文,解释语言指令(例如,“左转”)所传达的高级语义意图,并提出接下来四秒的细粒度驾驶指令。以往的元动作规划工作通常难以捕捉语言指令中蕴含的细微意图,依赖于简单的类别动作[1]、[2]、[34](例如,横向:左转、直行、右转;纵向:加速、保持、减速),这些动作缺乏对车辆控制细微差别的表达能力。这种粗略的离散化无法捕捉关键的行为变化,导致在复杂场景下性能欠佳。
为了克服这一问题并进一步增强VLA的空间感知能力,引入一种精细的元动作模式,该模式直接基于真实世界轨迹的几何和运动学特征设计而成。其方法并非依赖于基本的方向和速度标签,而是从未来轨迹的真实形状和轮廓中提取动作差异。对于横向控制,提出一系列多样化的基本动作,包括:急左转、缓左转、左侧变道、急右转、缓右转、右侧变道、直线行驶和车道微调。这反映曲率和横向位移的实际差异,使模型能够区分诸如“左转”之类的单一语言指令的细微变化。
对于纵向控制,基于运动学模式定义一系列加速曲线:完全停止、蠕行(creeping)、紧急减速、轻柔减速、受控减速、匀速宽松、匀速严格、轻柔加速和猛烈加速,涵盖了从精确保持速度到安全临界减速的整个过程。这种精细化程度使得模型能够精确执行涉及速度调整的复杂指令。
所提出的精细化驾驶指令推理方法,将语义意图转化为精确的动作,显著提高了决策的判别能力,并生成了更流畅、更接近人类驾驶的行为。基于该指令,模型生成一条粗略轨迹 τ_0,该轨迹在几何上体现预期的机动动作。最后,模型估计所提出的轨迹的置信度得分 ε。该得分源自token置信度。对于每个token,VLA 的最后一个 Transformer 层通过 softmax 函数生成一个概率分布,token的置信度即为该分布中的最大概率。然后,将整体轨迹置信度 ε 计算为各个token置信度的几何平均值。这种多步骤推理方法不仅将决策过程分解为人类可理解的阶段,而且有助于提高运动规划的可信度。
基于 Transformer 的分层规划器
时空 VLA 生成的粗略轨迹 τ_0 作为分层规划器的语义和结构先验。在第一阶段细化中,引入一个置信度-觉察VAE 模块,该模块根据 τ_0 的置信度得分 s 对其进行动态扰动和正则化。轨迹的潜特征从 N(μ, σ²) 中采样,其中方差 σ² = α(1 − s),α 为缩放因子。这种自适应噪声注入将细化集中在高不确定性区域,从而提高效率和目标定位精度。编码后的轨迹特征随后通过多头交叉注意机制与细粒度的驾驶指令嵌入融合,从而实现潜驾驶模式表示与精确控制目标的动态对齐。先前工作[3]中引入的轻量级预训练评分器模块(该模块已在NAVSIM v2[11]上训练)通过预测扩展预测驾驶模型评分(EPDMS)来选择得分最高的候选轨迹τ*。该评分基于安全性、效率和舒适性标准评估轨迹,从而实现无需模拟器的评估。
基于Transformer的轨迹头利用几何约束和潜分布正则化来优化候选轨迹。具体而言,细化损失 L_refine 是几何对齐的 L1 回归项和来自置信度感知 VAE 的 KL 散度约束 D_KL的加权组合。
利用置信度感知正则化、语义引导优化和多准则评分,多阶段规划器逐步将 τ_0 细化为动态可行且上下文合适的轨迹。分层架构确保高层次的可解释性和低层次的控制精度:时空 VLA 生成语义建议和粗略轨迹,而后续的细化阶段则处理几何优化。
训练策略
训练过程包含三个顺序阶段:首先,预训练动态token稀疏器。其次,联合优化稀疏器、LLM 和文本编码器,以实现对细粒度驾驶指令、粗略轨迹和置信度评分的推理。最后,通过最小化 L_refine 来训练指令编码器和基于 Transformer 的分层轨迹头。这些阶段中使用的视觉问答 (VQA) 数据由真实轨迹生成。
实验使用两个 NAVSIM v2 基准测试集:用于通用开环规划的 Navtest 数据集,以及更具挑战性的 Navhard 数据集,后者旨在通过合成扰动评估系统在伪闭环条件下的鲁棒性。用 EPDMS 对性能进行严格评估,EPDMS 是一个综合评分系统,它汇总九个关键子指标:无责任碰撞 (NC)、可行驶区域合规性 (DAC)、行驶方向合规性 (DDC)、交通信号灯合规性 (TLC)、自进度 (EP)、碰撞时间 (TTC)、车道保持 (LK)、历史舒适性 (HC) 和扩展舒适性 (EC)。EPDMS 评分全面衡量自动驾驶系统的安全性、效率和舒适性。
实现基于 LLaVA-v1.5-7B [32] 作为基础视觉-语言模型 (VLM),该模型包含 70 亿个参数,并集成了 CLIP 中的 ViT-L/14 作为视觉编码器、用于视觉语言适配器的多层感知器 (MLP) 以及 Vicuna-7B 作为大语言模型 (LLM)。通过引入深度感知空间编码并替换标准适配器来增强此架构。
首先,用 8 个 NVIDIA H20 GPU,在 NAVSIM trainval 数据集上进行 1 个 epoch 的预训练,批大小为 32,学习率为 1×10⁻³。随后,在相同的硬件配置下,在 trainval 数据集上进行 1 个 epoch 的第一阶段训练,批大小为 8,学习率为 1×10⁻⁵。最后,用 8 个 NVIDIA A800 GPU,在 navtrain 数据集上进行 30 个 epoch 的第二阶段训练,批大小为 2,学习率为 1×10⁻⁵。
评估提出模型的两个变型:HiST-E2E 使用 ResNet-34 [41] 骨干网络提取视觉特征,HiST-VLA 仅生成细粒度的驾驶指令,然后将这些特征输入到外部运动规划器(DiffusionDrive [37])以生成最终轨迹;以及 HiST-VLA,全集成的“纯”VLA 模型,它直接生成轨迹,不依赖任何外部 E2E 模块,作为一个统一的系统运行。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
