论文标题:C-TRAIL:基于常识世界框架的自动驾驶轨迹规划
作者:Zhihong Cui, Haoran Tang, Tianyi Li, Yushuai Li, Peiyuan Guan, Amir Taherkordi, Tor Skeie
链接:https://arxiv.org/abs/2603.29908
研究背景
轨迹规划是自动驾驶的核心技术,要求车辆在动态环境中根据周围感知信息实时预测和规划行驶路径。近年来,大型语言模型(LLM)在常识推理和知识检索方面展现出强大能力,为自动驾驶轨迹规划带来了新的可能性。然而,LLM输出本质上具有不可靠性,在安全关键的自动驾驶场景中可能产生严重后果——模型可能生成看似合理但实际不安全的轨迹,或在复杂交互场景中做出错误判断。现有方法将LLM作为外部知识源或直接生成轨迹,但缺乏对LLM知识可靠性的评估机制,也难以在未知环境中实现泛化。
⚠️ 核心挑战
自动驾驶轨迹规划面临两大核心挑战:(1)LLM推理不可靠问题:LLM对未见场景的理解主要基于概率模式匹配而非真正的逻辑推理,召回的常识可能与实际环境不一致,导致不安全或次优决策;(2)规划泛化能力不足:现有世界模型需要大量相似数据才能拟合新场景,难以应对动态交通中不可预测的未知环境。
技术方法
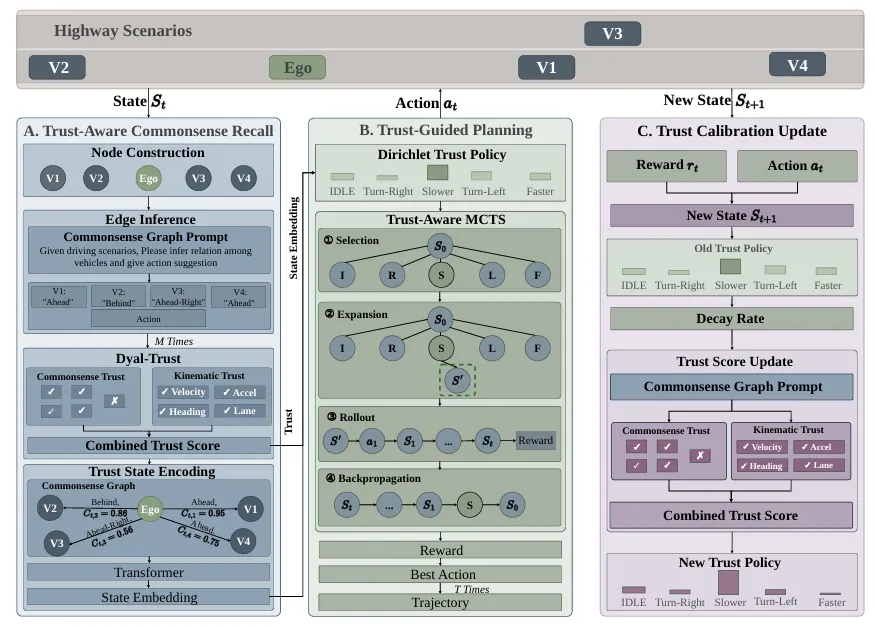
🔹 常识世界范式
C-TRAIL提出一种全新的轨迹规划范式:构建一个概念性的常识世界(Commonsense World),通过Recall(召回)、Plan(规划)、Update(更新)三阶段闭环流程,使自动驾驶车辆能够像人类一样利用常识知识进行轨迹规划,而非依赖大量数据拟合。
🔹 Recall模块——双信任机制
Recall模块向LLM查询语义关系,并通过双信任机制量化召回知识的可靠性。该机制能够识别LLM在特定场景下可能产生的常识偏差,在将知识注入规划前进行可靠性评估,避免不安全决策。
🔹 Plan模块——MCTS融合
Plan模块通过Dirichlet信任策略将信任加权的常识知识注入蒙特卡洛树搜索(MCTS),在保持探索多样性的同时引导搜索向安全轨迹收敛,实现LLM常识推理与经典规划算法的优势互补。
🔹 Update模块——自适应 refinement
Update模块从环境反馈中自适应 refinement 信任分数和策略参数,形成闭环优化。该机制使系统能够从实际驾驶经验中持续学习,不断提升在特定场景下的规划能力。
实验结果
📊 Highway-env仿真实验:在Highway-env仿真环境中的四个场景进行验证,C-TRAIL在所有场景中均优于基线方法,ADE降低40.2%,FDE降低51.7%,SR提升16.9个百分点,展现出在复杂动态交通场景中的卓越规划能力。
📊 真实世界数据集验证:在highD和rounD两个真实世界高速公路数据集上进行验证,C-TRAIL始终优于现有最优方法,证明其在真实交通流数据上的有效性和泛化能力。
📊 消融实验:消融实验验证了三阶段闭环流程每个模块的必要性。双信任机制有效识别了不可靠的LLM常识输出,Dirichlet信任策略显著提升了MCTS的规划效率,Update模块的自适应 refinement 进一步巩固了整体性能。
✅ 核心结论
本文提出C-TRAIL,一种基于常识世界框架的自动驾驶轨迹规划方法。通过Recall-Plan-Update三阶段闭环范式,将LLM的常识推理能力与MCTS的规划搜索能力有机结合,配合双信任机制评估和过滤LLM知识输出,在仿真和真实世界数据集上均取得了显著的性能提升。C-TRAIL为自动驾驶轨迹规划提供了一条不依赖大规模数据拟合的新思路。
总结与展望
本文提出C-TRAIL,一种基于常识世界框架的自动驾驶轨迹规划方法。通过Recall-Plan-Update三阶段闭环范式,将LLM的常识推理能力与MCTS的规划搜索能力有机结合,配合双信任机制评估和过滤LLM知识输出,在仿真和真实世界数据集上均取得了显著的性能提升。C-TRAIL为自动驾驶轨迹规划提供了一条不依赖大规模数据拟合的新思路。