🚗 语义观测层:面向自动驾驶低延迟语义异常检测的量化VLM部署方案
导读
直击自动驾驶语义异常检测的核心痛点:像素级检测器无法理解上下文依赖风险(无法区分路面瘪球与阴影、误判卡车悬挂交通灯),LLM/VLM语义方案延迟过高无法车载部署,主控制回路难以处理长尾语义边缘案例。纽约大学团队提出语义观测层(Semantic Observer Layer),将量化视觉-语言模型(Cosmos-Reason1-7B)作为并行安全监控模块,以–频率独立运行于主控制回路之外,监测语义异常并触发安全接管;通过NVFP4量化+FlashAttention2实现推理延迟(同硬件下较未优化FP16基线加速倍),满足车载观测层时序预算;实验首次发现NF4量化在视频推理中出现灾难性召回崩塌(),并基于ISO 26262完成危险分析与风险评估(HARA),明确车载部署的安全约束与量化选型准则,完整验证了量化VLM作为自动驾驶语义观测层的预部署可行性。
图1:使用Cosmos-Reason1-7B模型[9]在危险感知测试数据集[8]上的定性结果。上排(样本11–12):正确分类的正常帧。下排(样本13–14):一帧正常画面与一处检测到的异常情况,体现了具备上下文感知能力的语义推理。
推荐理由
- 核心价值:首创并行主控制环的语义观测层架构,通过双优化实现50×推理加速,明确静态/视频的量化选型禁忌,首次验证VLM车载语义异常检测的工程可行性;
- 落地意义:基于Cosmos-Reason1-7B优化,500ms延迟满足1-2Hz车载需求,可直接作为自动驾驶安全冗余模块,触发安全接管;
- 学术意义:系统评估量化VLM的精度-延迟-模态适配性,揭示NF4视频召回崩塌的硬约束,为安全关键车载大模型部署提供基准。
1 业务背景与技术背景
1.0 业务背景:自动驾驶语义异常的致命安全风险
L4级自动驾驶在开放道路面临语义异常致命威胁:
- 语义异常是上下文相关危险,像素级检测器无法推理(如路面异物vs阴影、卡车悬挂交通灯、路面破损);
- 主控制系统以感知-规划流水线为主,缺乏高层语义推理能力,易对长尾异常做出错误决策;
- 现有安全冗余多基于规则/定位,无语义理解能力,无法覆盖开放道路长尾语义风险。
1.1 技术背景:现有异常检测方案局限与本文突破
| | |
|---|
| 无语义理解、无时序推理、易受域偏移影响、无 actionable 输出 | |
| | |
| | |
| | |
2 核心概念:关键定义与技术体系
| | |
|---|
| 并行于主自动驾驶回路的VLM监控模块,–运行,检测语义异常并触发安全接管 | |
| | |
| 英伟达机器人专用VLM,基于Qwen2.5-VL,面向具身推理优化 | |
| | |
| 分块内存高效注意力核,避免实例化全注意力矩阵,降低IO | |
| NF4量化在视频时序推理中召回骤降至,安全关键失效 | |
| ISO 26262危险分析与风险评估,映射模型指标至ASIL安全目标 | |
3 核心内容:架构设计与关键技术
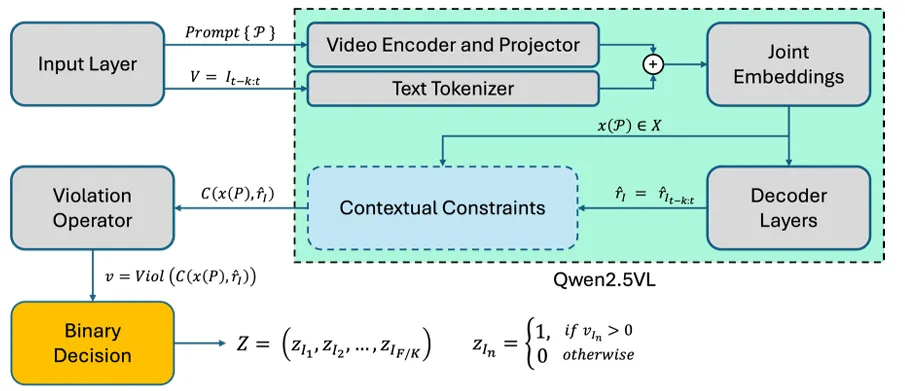
图2:语义观测层架构。视觉大模型观测器以1–2赫兹的频率与自动驾驶车辆主控制环路同步运行,通过结构化提示对RGB帧序列的时间窗口进行处理。当检测到高置信度的语义约束违反时,该观测器将触发安全失效接管机制。来自Cosmos-Reason1-7B的视觉特征标记被投影至语言嵌入空间,并结合上下文相关的语义约束进行评估,最终输出{正常,异常}的二分类判定结果。
3.1 整体技术框架
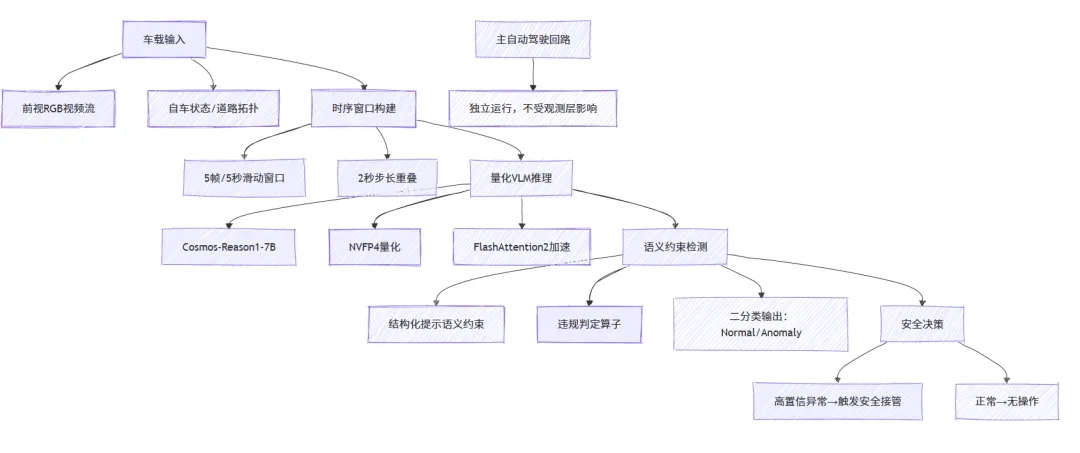
语义观测层采用主系统并行架构,VLM观测器以–独立运行,处理时序视频窗口,执行语义约束检测,异常时触发安全接管,全流程如下:
3.2 核心模块技术细节
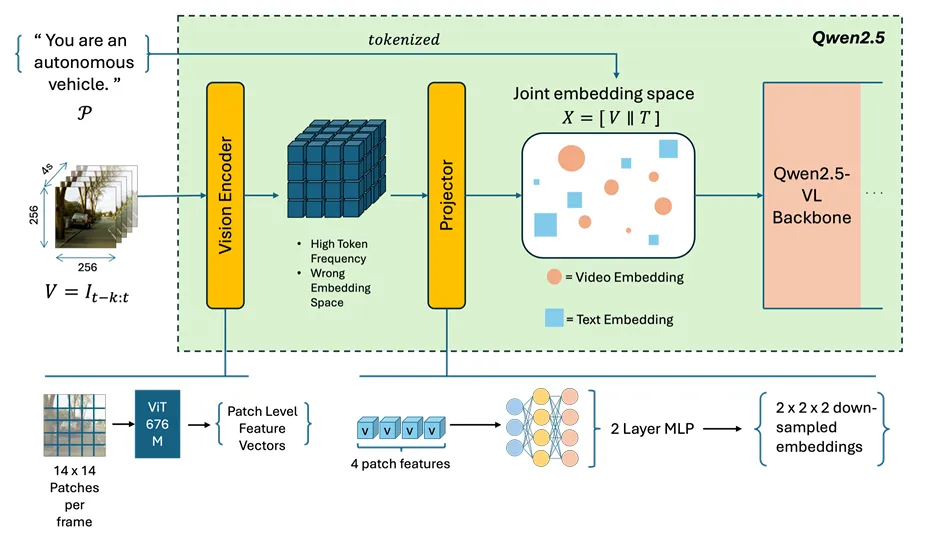
图3:用于异常检测的Cosmos-Reason1-7B模型高层架构。来自视觉编码器的视觉特征被投射至语言嵌入空间,并由纯解码器Transformer主干网络与提示词标记共同处理(模块细节见图4)。
3.2.1 系统形式化定义
将语义异常检测系统形式化为元组:
- :自车状态空间;:RGB观测;:上下文信息;:预测不确定性;:二分类异常输出;:可解释输出;:系统指标。
视频表示为连续帧集合:
其中为第帧图像,每帧对齐自车状态与上下文。
VLM将时序窗口与提示映射为语义表示:
其中为VLM映射函数,为场景语义表征。
语义违规判定与二分类输出:
视频全局输出:
3.2.2 语义观测层架构
- 基座模型:Cosmos-Reason1-7B,继承Qwen2.5-VL架构(ViT视觉编码器+MLP投影+解码器Transformer),面向具身推理微调。
- 多模态编码:帧分块→视觉编码→MLP映射至语言嵌入空间→拼接提示令牌→统一序列输入。
- 时序推理:帧滑动窗口(5秒,),秒步长,利用短时动态提升异常检测可靠性。
- 约束解码:限制输出令牌数,仅输出/,稳定延迟并保证输出确定性。
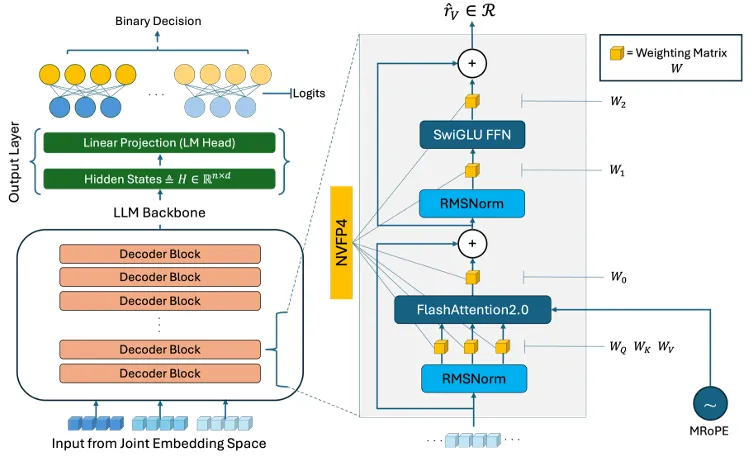
图4:Cosmos-Reason1-7B所采用的架构。由Qwen2.5-VL视觉编码器提取的视觉标记,通过两层多层感知器融合器投影至语言嵌入空间,并与提示标记进行拼接。主干权重矩阵采用NVFP4量化,FlashAttention2可加速注意力计算。Cosmos-Reason1-7B保留了Qwen2.5-VL架构,并在机器人技术与具身推理数据上进一步微调,以适配物理人工智能任务。
3.2.3 低延迟优化(核心创新)
- 权重内存从 bits(FP16)降至 bits,理论压缩。
FlashAttention2加速注意力计算:
分块计算注意力,无需实例化全注意力矩阵,片上SRAM流式计算,GPU SM占用从提升至。
- NVFP4+FlashAttention2:/帧;
3.2.4 提示工程与令牌约束
- 结构化提示:紧凑语义约束+严格输出格式,禁用开放式解释;
- 提示范式对比:极简提示F1归零,精简提示F1骤降,结构化verbose提示最优;
- 令牌预算:限制生成令牌,消除延迟波动,保证车载确定性。
3.2.5 安全风险分析(HARA)
基于ISO 26262完成危险分析,映射模型指标至安全目标:
- NF4视频召回崩塌:ASIL-D,禁止在视频场景使用NF4。
3.3 关键技术创新点
- 并行语义观测架构:非侵入式安全冗余,不影响主控制回路实时性,填补语义安全监控空白。
- VLM车载低延迟方案:NVFP4+FlashAttention2实现7B级VLM 50倍加速,首次满足车载时序预算。
- 量化安全约束发现:实证NF4视频召回崩塌,给出安全关键系统量化选型硬规则。
- 安全-指标映射体系:HARA关联模型精度/召回/延迟与ASIL等级,支撑车载合规部署。
- 零样本语义异常检测:无需专属微调,通用VLM直接适配路面破损、异物等多类异常。
4 实验验证
4.1 实验设置
- 模型:Cosmos-Reason1-7B;硬件:RTX 5090;
- 数据集:RDD2022(路面损伤)、Cityscapes(正常路面)、Hazard Perception Test(驾驶危险);
- 评估指标:精确率、召回率、F1、延迟、ASIL合规性;
- 对比变量:量化方式(BF16/INT8/NF4/NVFP4)、提示格式、时序/静态输入。
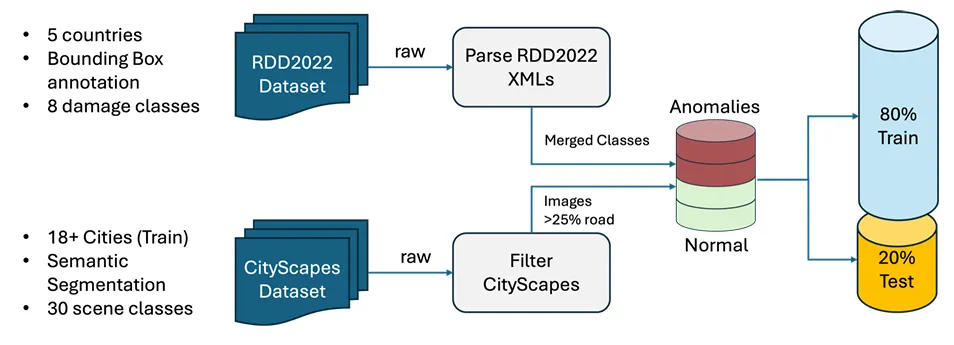
图5:用于FCDD训练的数据集编排。将RDD2022[17]图像(合并所有损伤类型)作为异常类别,而筛选出道路覆盖率大于25%的Cityscapes[18]图像作为正常类别。采用80/20的训练集-测试集划分方式,得到31386个训练样本(2598个正常样本、28788个异常样本)和7643个测试样本(447个正常样本、7196个异常样本)。
图7:FCDD全局热力图。红色区域表示异常分数较高。(a) 完好路面的分数整体偏低且分布均匀。(b) 破损路段会触发显著的激活响应。
4.2 核心实验结果
4.2.1 范式对比:像素级 vs 语义检测
- FCDD(像素级):ROC-AUC,但仅输出异常热图,无语义标签;
- Cosmos(语义):零样本F1=,精确率,输出可解释语义标签。
4.2.2 静态图像:量化+提示消融
最优配置:NVFP4+Verbose提示,F1=,精确率,延迟;极简提示F1=,语义约束不可或缺。
4.2.3 视频时序推理:关键发现
- 结论:视频场景禁止使用NF4量化,BF16/INT8为安全选择。
4.2.4 安全目标匹配
4.3 消融实验
- 无FlashAttention2:延迟提升以上,无法车载部署;
5 挑战与未来方向
5.1 核心挑战
- 召回率缺口:当前召回,未达ASIL-D 安全要求;
- 异常类别有限:仅验证路面损伤,未覆盖异物、异常交通设施等全类别;
- 实车验证缺失:仅在数据集与仿真验证,未完成实车车载部署测试;
- NF4视频失效:4位量化在视频场景存在固有缺陷,限制极致轻量化。
5.2 未来方向
- 召回提升:Rank-16/32 LoRA微调、多帧logit聚合、置信度阈值校准;
- 全类别异常:扩展至DoTA、DADA-2000数据集,覆盖全语义异常;
- 实车集成:在NYU自动驾驶平台完成车载部署与闭环验证;
- 观测层-MRM联动:与MRM最小风险maneuver层结合,实现异常-接管-避险全闭环;
- 混合量化方案:静态用NVFP4,视频用BF16/INT8,兼顾效率与安全。
6❓ 核心QA(基于论文内容)
Q1:语义观测层与自动驾驶主栈的关系是什么?为何延迟要求宽松?
A1:语义观测层并行独立运行,不处于主控制关键路径;语义异常(路面破损、异常障碍物)以秒级演化,而非毫秒级控制,因此500ms推理延迟完全满足安全监测需求,核心约束是高精度减少误触发。
Q2:为何NF4量化在静态有效、视频却召回崩塌?
A2:静态单帧特征稳定,NF4可保持语义特征;视频依赖多帧时序关联,4-bit量化破坏时序特征的连续性与对齐性,导致异常漏检,召回暴跌至10.6%,成为视频部署的硬禁忌。
Q3:双优化(NVFP4+FlashAttention2)的加速原理是什么?
A3:NVFP4降低Transformer权重内存与计算量,FlashAttention2解决注意力机制的显存IO瓶颈,两者协同破解VLM车载延迟壁垒,将单帧推理从25s压缩至500ms,实现50倍加速。
Q4:车载部署的核心安全约束有哪些?
A4:1. 视频场景严禁使用NF4量化;2. 必须使用Verbose结构化Prompt;3. 需时序防抖(连续多帧检测再触发接管);4. 不可作为唯一安全层,需配合MRM安全验证模块。
7 总结
核心价值
- 范式革新:提出非侵入式语义观测层,为自动驾驶提供语义级安全冗余,不影响主系统实时性;
- 工程突破:实现7B级VLM车载低延迟部署(),倍加速突破实时性瓶颈;
- 安全准则:首次揭示NF4视频量化召回崩塌,建立车载VLM量化安全硬约束;
- 合规可行:基于ISO 26262完成风险评估,验证预部署可行性,提供量产落地路径。
总结金句
👉 “语义观测层以并行非侵入架构为骨架、量化VLM低延迟推理为核心、安全约束合规为准则,首次将大模型语义理解能力转化为车载可部署的安全冗余模块,用实证结论明确量化选型红线,为自动驾驶应对长尾语义异常提供了安全、可行、可落地的全新技术方案。”
8 原论文信息
- 论文题目:A Semantic Observer Layer for Autonomous Vehicles: Pre-Deployment Feasibility Study of VLMs for Low-Latency Anomaly Detection
- 作者团队:Kunal Runwal、Swaraj Gajare、Daniel Adejumo、Omkar Ankalkope、Siddhant Baroth、Aliasghar Arab(纽约大学、纽约市立大学)
- 发表状态:arXiv preprint(cs.RO领域),2026年3月30日,arXiv编号:2603.28888v1
- 核心创新:语义观测层架构、NVFP4+FlashAttention2 倍加速、NF4视频召回崩塌发现、ISO 26262安全分析
- 关键性能:推理延迟(加速),静态精确率,视频BF16召回,ASIL-B精度达标