26年3月来自中科院自动化所的论文“DynVLA: Learning World Dynamics for Action Reasoning in Autonomous Driving”。
DynVLA是一个驾驶VLA模型,它引入一种CoT范式,称为动力学CoT。DynVLA在动作生成之前预测紧凑的世界动力学,从而实现更明智、更符合物理实际的决策。为了获得紧凑的动态表示,DynVLA引入一个动力学token化器,将未来的演化压缩成少量动态token。考虑到交互-密集型驾驶场景中丰富的环境动力学,DynVLA将以自我为中心的动力学和以环境为中心的动态解耦,从而产生更精确的世界动态建模。然后,通过SFT和RFT训练DynVLA在动作生成之前生成动力学token,在保持低延迟推理的同时提高决策质量。与缺乏细粒度时空理解的文本CoT以及因密集图像预测而引入大量冗余的视觉CoT相比,动力学CoT以紧凑、可解释且高效的形式捕捉世界的演变。在NAVSIM、Bench2Drive以及大规模内部数据集上的大量实验表明,DynVLA始终优于文本CoT和视觉CoT方法,验证动力学 CoT的有效性和实用价值。
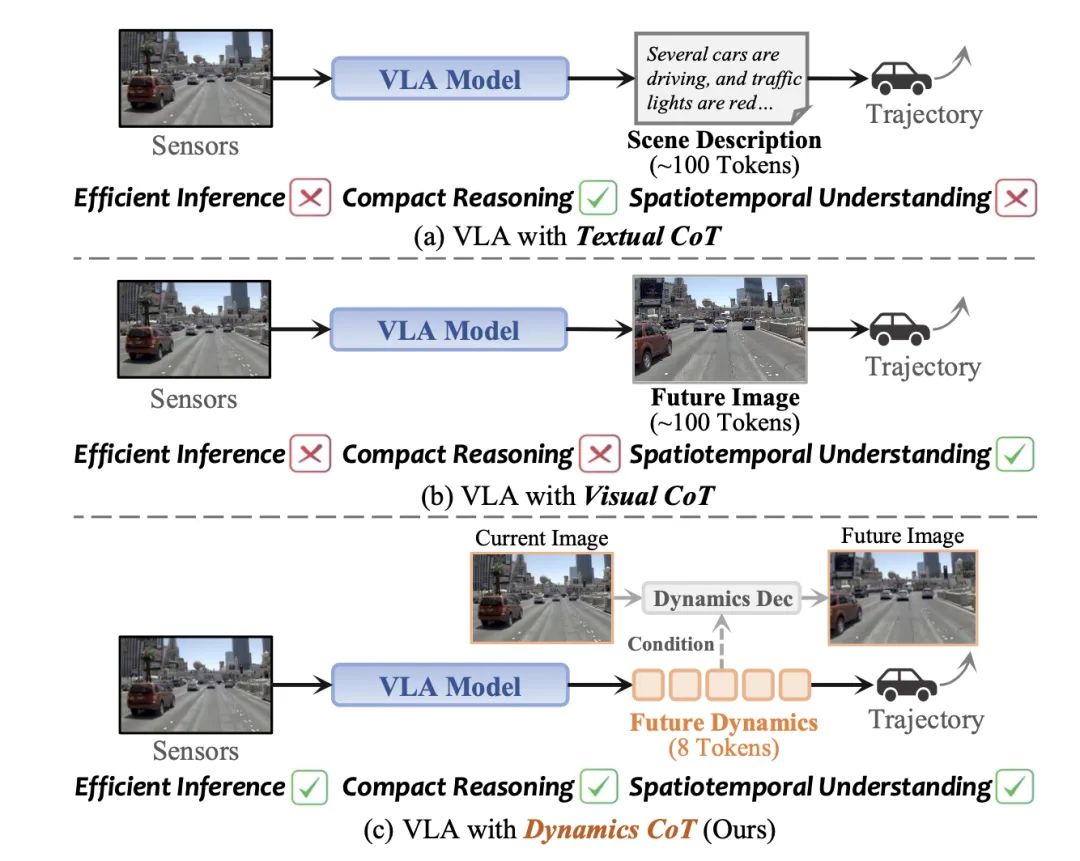
在基于VLA的自动驾驶中,主流的CoT设计是文本认知逻辑(如图a),它在文本空间进行推理并提供高层次的决策逻辑(Hwang et al., 2024; Li et al., 2025b)。然而,驾驶操作依赖于复杂且受物理约束的世界中精细的时空关系,而离散的语言表征难以捕捉这些关系。为了解决这个问题,最近的研究探索视觉认知逻辑(如图b),它预测未来的视觉帧并生成相应的动作,从而在像素空间中进行时空推理(Zeng et al., 2025; Zhao et al., 2025b)。尽管视觉认知逻辑在表示时空关系方面更具表现力,但该模型必须预测与决策无关的背景和纹理细节,这增加了推理的冗余性和学习难度。此外,文本和视觉思维链都需要生成大量的推理token,导致推理延迟显著。
为了克服这些局限性,本文提出DynVLA,它引入一种思维链范式,称为动力学思维链(Dynamics CoT)。如图(c)所示,DynVLA首先将未来的动力学信息压缩成紧凑的token,然后在生成动作之前预测这些动力学token。与文本思维链相比,动力学思维链能够对时空状态的演化进行建模,超越符号文本推理的范畴。与视觉思维链相比,它仅编码场景动态信息,避免冗余推理。此外,这种紧凑的表示方法能够对连续观测之间的状态转换进行建模,因此只需要少量token即可捕捉未来的动态信息。与文本或视觉思维链相比,这显著缩短了推理路径,并将推理延迟降低了一个数量级以上。
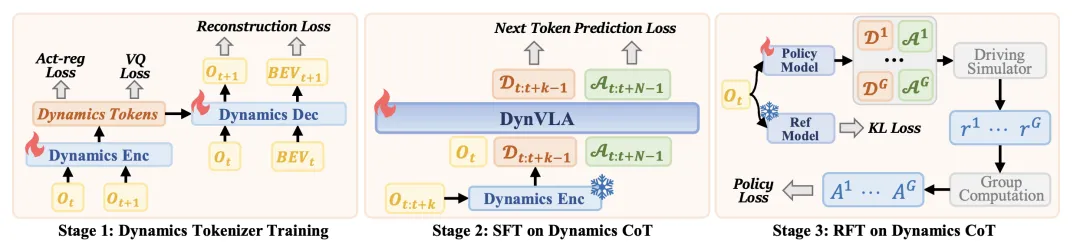
如图所示DynVLA 首先训练一个动力学token化器来提取离散的动力学token。然后,它对动力学 CoT 序列执行监督微调(SFT),并通过强化微调(RFT)进一步改进 VLA 策略。
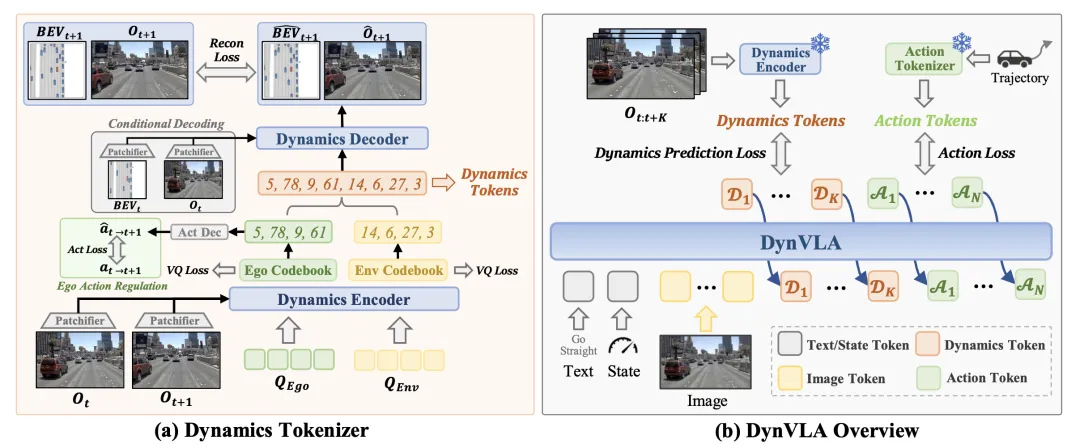
具有解耦动力学的编码器。驾驶场景除了包含自运动外,还包含显著的环境动力学。因此,将动力学表示显式地解耦为以自我为中心的token和以环境为中心的token,如图 a 所示。
基于动作正则化的解码器。在获得编码后的动力学特征后,采用解码器来重构未来的观测数据,从而为动力学token的学习提供监督。在解码过程中,对当前观测数据进行条件化,这使得离散token无需编码静态背景或纹理细节。然而,仅通过重构来学习动力学信息仍然缺乏足够的约束,并可能导致码本崩溃。为了解决这个问题,引入一种基于动作的正则化方法,使以自我为中心的动力学信息与自运动保持一致。
具有跨视图一致性正则化的解码器。理想的环境动力学应该在不同的表示中捕捉相同的底层场景演化。因此,通过要求相同的动力学token来施加跨视图一致性正则化,从而在各自的当前观测条件下,预测未来的图像和未来的BEV图。这强化图像空间和BEV空间之间的语义一致性,从而产生更连贯的以环境为中心的动力学,如图a所示。
动力学token化器训练。动力学token化器通过最小化重建损失、VQ-VAE损失和正则化损失进行训练。图像重建损失L^image^_recon结合了均方误差损失和感知相似性损失(Zhang,2018),以同时捕捉低频结构一致性和高层次语义相似性,而BEV重建损失L^bev^_recon是一种交叉熵损失。
结构化动力学 CoT 序列。为了实现动力学 CoT,对结构化动力学序列执行监督微调 (SFT)(如图 b 所示)。为了明确界定动力学推理序列,引入两个特殊tokens ⟨BOD⟩和⟨EOD⟩,分别标记(mark)动态推理的开始和结束。对于动作生成,我们使用FAST token化器(Pertsch,2025)将连续动作编码为离散动作token序列A_t:t+N −1,其中N表示动作token序列的长度。类似地,引入⟨BOA⟩和⟨EOA⟩来指示动作生成序列的开始和结束。
DynVLA训练流水线示意图如下:
SFT训练。给定目标序列,最大化输出token在观测和指令上下文条件下的似然性来训练模型。具体来说,t时刻的模型输入表示为c_t = {O_t, O_t−1, T_t, S_t},其中O_t是当前图像观测值,O_t−1是前一个图像观测值,T_t是文本指令,S代表自我状态。采用标准的下一token预测损失(Vaswani,2017),并最小化动态推理序列和动作生成序列上的负对数似然。通过此过程,预训练模型明确地学习动态推理和动作生成的因果生成顺序,并将推理出的动态视为决策的中间变量。
尽管动力学CoT SFT能够教会模型在行动前显式地推理未来的动力学,但行动的学习仍然完全基于模仿。然而,模仿学习容易产生类似人类但不安全的轨迹(Shang et al., 2025),并且倾向于产生平均化且次优的运动方案(Li et al., 2025d)。此外,最近的研究表明,将强化学习应用于基于CoT的模型可以提供超越SFT的结果驱动激励(Guo et al., 2025)。因此,为了克服模仿学习的局限性,并遵循推理模型中的常用做法,引入强化微调(RFT)(Shao et al., 2024b; Guo et al., 2025)以进一步提高安全性和决策质量。
奖励设计。对于每条轨迹,采用 PDM 评分 (PDMS)(Dauner,2024)作为轨迹级奖励 r_traj,其值为 [0, 1] 范围内的标量。此外,为了稳定强化学习训练并强制模型输出遵循 CoT 模板,引入格式奖励 r_fmt ∈ {0, 1},如果生成的序列满足所需的token组织,则 r_fmt 为 1,否则为 0。最终奖励计算为轨迹奖励和格式奖励的加权组合:r = r_traj + λ_fmt r_fmt,其中 λ_fmt 为权重系数。
RFT训练。用组相对策略优化(GRPO)(Shao,2024b)来优化策略。对于给定的每个训练样本c_t,生成G个候选序列{o_i}并计算它们对应的奖励{r_i}。通过基于GRPO的RFT,该模型可以在保持动态CoT结构化生成的同时,进一步提高规划安全性和决策质量。
对三个基准测试数据集进行全面的实验:真实世界基准测试数据集 NAVSIM(Dauner,2024)、闭环基准测试数据集 Bench2Drive(Jia,2024)以及包含 70 万帧的大规模内部数据集。
动力学token化器。对于每个驾驶场景,用 8 个动力学tokens,包括 N_ego = 4 个以自我为中心的动力学tokens和 N_env = 4 个以环境为中心的动力学tokens,这些tokens均从前视图像推断得出。自我和环境分支的码本大小均设置为 64,总共产生 128 种不同的离散动力学token类型,VQ 嵌入维度为 32。动力学token化器采用 Transformer 架构实现。隐层维度设置为 1024,动力学编码器包含 L_Enc = 12 层,图像解码器和 BEV 解码器均包含 L_Dec = 8 层。编码器以经过图像块处理的观测值 (x_t, x_t+1) 以及学习的查询 (Q_ego, Q_env) 作为输入。将这四个输入序列连接起来,形成一个单一的token序列,并将其输入到 Transformer 层中。用于动作正则化的自我动作,对应于两帧之间的相对自我运动。对于BEV监督,用数据集提供的正面BEV图。训练过程中,图像重建损失由MSE损失和LPIPS损失组成,二者权重均为1.0。VQ损失权重设置为1.0,动作正则化损失权重设置为1.0,BEV重建损失权重设置为0.1。用余弦学习率调度算法,在8个NVIDIA L20 GPU上训练动力学token化器 20万步,并设置1000步预热和最大学习率为1 × 10⁻⁴。批大小设置为32,并使用AdamW优化器,β1 = 0.9,β2 = 0.95。
动力学 CoT SFT。采用 EMU3(Wang,2024)作为预训练基础模型,并遵循与 DriveVLA-W0(Li,2025a)相同的预训练协议。动力学token化器使用包含 128 个离散动力学token类型的码本,而 FAST token化器(Pertsch,2025)使用包含 2048 个离散动作token类型的码本。将token词汇表中的最后 2048 + 128 个tokens分别替换为动作 tokens和动力学tokens。对于动态 CoT 监督,提取未来 2 秒范围内的动力学信息(K = 2),得到一个包含 16 个动力学tokens的序列,作为 SFT 期间的 CoT 内容。作为传感器输入,仅使用当前前视图像以及 1 秒前的前视图像。在训练过程中,动力学 CoT 损失和动作预测损失的权重相同,系数均设置为 1.0。用余弦学习率调度,在 8 个 NVIDIA L20 GPU 上对预训练模型进行 4k 步的微调,预热步数为 100,最大学习率为 1 × 10⁻⁴。批大小设置为 6,并使用 AdamW 优化器,β1 = 0.9,β2 = 0.95。
动力学 CoT 强化微调 (RFT)。在 SFT 训练的模型基础上进行强化微调 (RFT)。轨迹奖励 r_traj 和格式奖励 r_fmt 的权重系数均设置为 1.0。RFT 在 6 个 NVIDIA H800 GPU 上进行 6k 步,使用余弦学习率调度,预热步数为 500,最大学习率为 2 × 10⁻⁶。批次大小设置为 6,梯度累积步长也设置为 6。KL 系数为 1 × 10−3,使用 AdamW 优化器,其中 β1 = 0.9,β2 = 0.95。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
