<The Blind Spot of Adaptation: Quantifying and Mitigating Forgetting in Fine-tuned Driving Models>论文:https://arxiv.org/pdf/2604.04857代码:https://github.com/AutoLab-SAI-SJTU/FidelityDrivingBench一、研究方向及背景
这篇论文属于 自动驾驶中的视觉语言模型(VLM)/多模态大模型 研究方向,更具体地说,聚焦于 VLM 驱动自动驾驶模型在微调过程中的灾难性遗忘(catastrophic forgetting)问题。作者关注的核心矛盾是:自动驾驶场景往往需要把通用视觉语言模型进一步微调到驾驶数据上,但这种“适配”过程会破坏模型原有的通用世界知识,导致模型在长尾、罕见、复杂场景中的泛化能力下降,进而影响安全性。
论文的贡献不只是在方法上提出改进,更重要的是把“自动驾驶VLM微调后是否遗忘了原有知识”这个此前缺少系统研究的问题,明确提出并量化评测。作者因此把工作分成两部分:一是 构建面向遗忘评估的基准 Fidelity Driving Bench,二是提出 缓解遗忘的新框架 DEA(Driving Expert Adapter)。
二、主要研究方法或创新点
1. 首次系统提出并量化自动驾驶VLM中的“灾难性遗忘”问题
论文首先指出,当前很多自动驾驶VLM方法只关注任务性能提升,却忽视了微调导致的知识退化。作者在文中展示了一个很直观的例子:基础模型原本还能识别路边石块、路缘等关键风险物,但微调后的驾驶模型反而漏检这些危险目标,导致潜在不安全轨迹(见图2)。这说明,模型虽然“更像驾驶模型了”,却可能“更不懂世界了”。
这一观察很有价值,因为它指出了当前自动驾驶大模型研究中的一个盲区:如果只看常规基准,很可能无法发现模型已经失去了对长尾物体、罕见场景和语义细节的感知能力。
2. 构建了新的遗忘评测基准 Fidelity Driving Bench
论文最重要的创新之一,是提出了 Fidelity Driving Bench。按照作者的描述,该基准覆盖 15个数据源、18万 driving scenes、90万 QA 对,并设计了 3类评测任务 与 2类核心遗忘指标,用于专门分析微调后的知识保留问题(见图1)。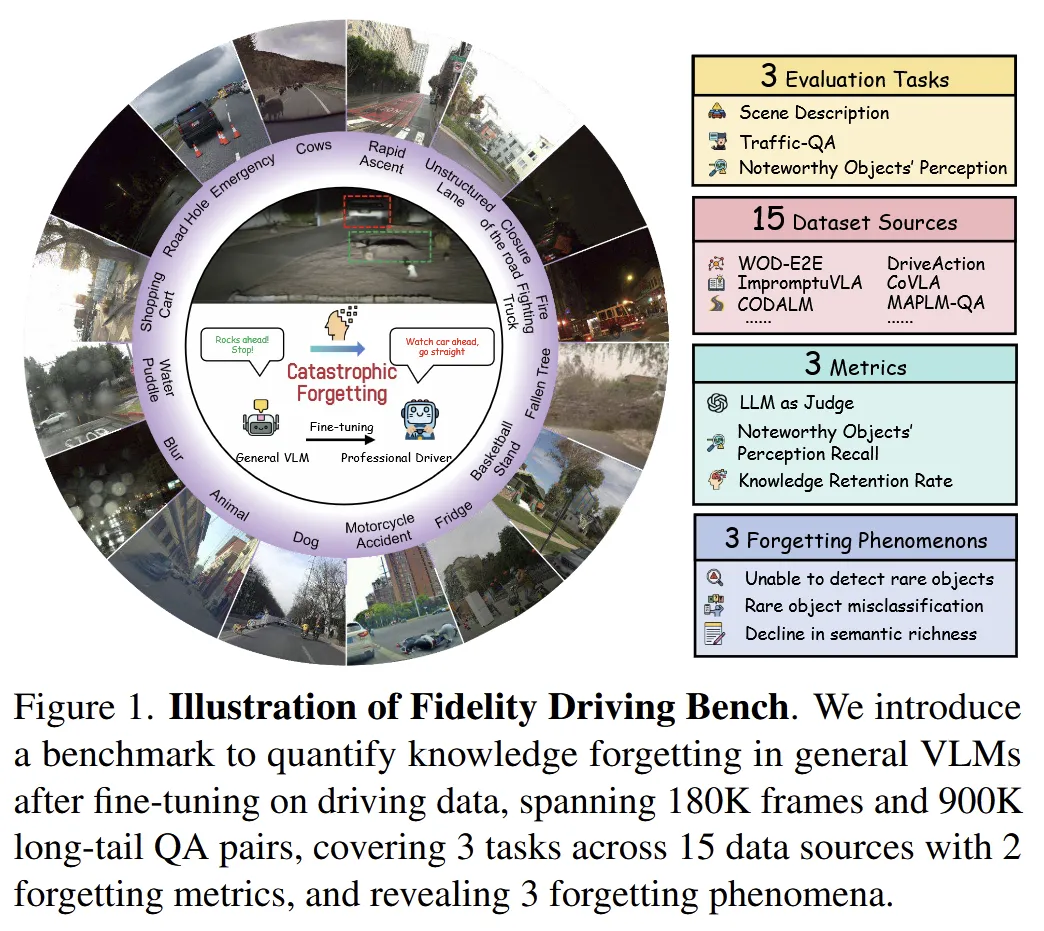
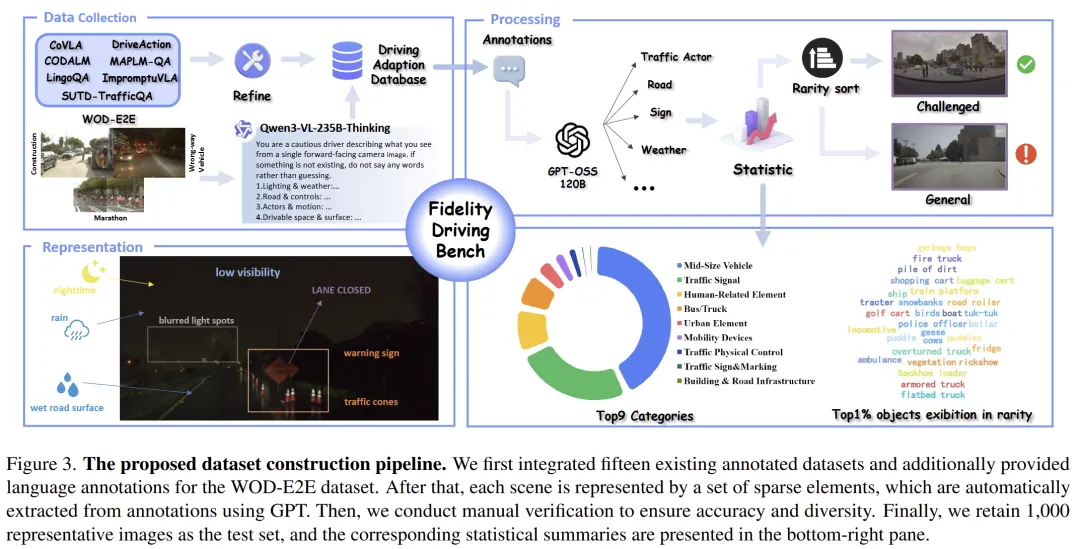
从数据构建上看,作者并不是简单拼接已有自动驾驶数据,而是设计了一条自动化长尾场景挖掘流程。其核心做法包括:
- 将场景表示为若干稀疏元素,如道路条件、交通参与者、天气、标志等;
- 再通过带有长度归一化的打分方法,为整张图像计算“长尾稀有度”;
- 最后结合人工审核,从候选池中筛选出 1000张最具代表性的长尾/遗忘测试图像。这一流程在图3中有完整示意。
同时,作者还把剩余数据整理成高质量训练集,最终形成了一个 180K 场景、15个来源、900K QA 的统一训练语料。论文在表1中将其与 DriveLM、CoVLA、OmniDrive、ImpromptuVLA 等数据集做了比较,可以看到 Fidelity Driving Bench 在场景规模、数据来源多样性上都更强。
3. 提出新的遗忘评测指标:KRR
为了真正量化遗忘,作者提出了 Knowledge Retention Rate(KRR)。这个指标的思想很清晰:把模型在“遗忘测试集”上的关键目标感知能力,看作它对预训练知识是否仍然保留的代理指标。具体地,作者先定义 Noteworthy Objects’ Perception Recall(NoPR),再把微调后模型的 NoPR 与原始基础模型的 NoPR 做比值,得到 KRR。
这个设计很有针对性。因为自动驾驶里最危险的遗忘,不一定体现为语言描述变差,而往往体现为 对关键障碍物、动物、施工物、特殊车辆等“值得注意目标”的漏感知。所以相比一般文本指标,KRR 更贴近安全需求。
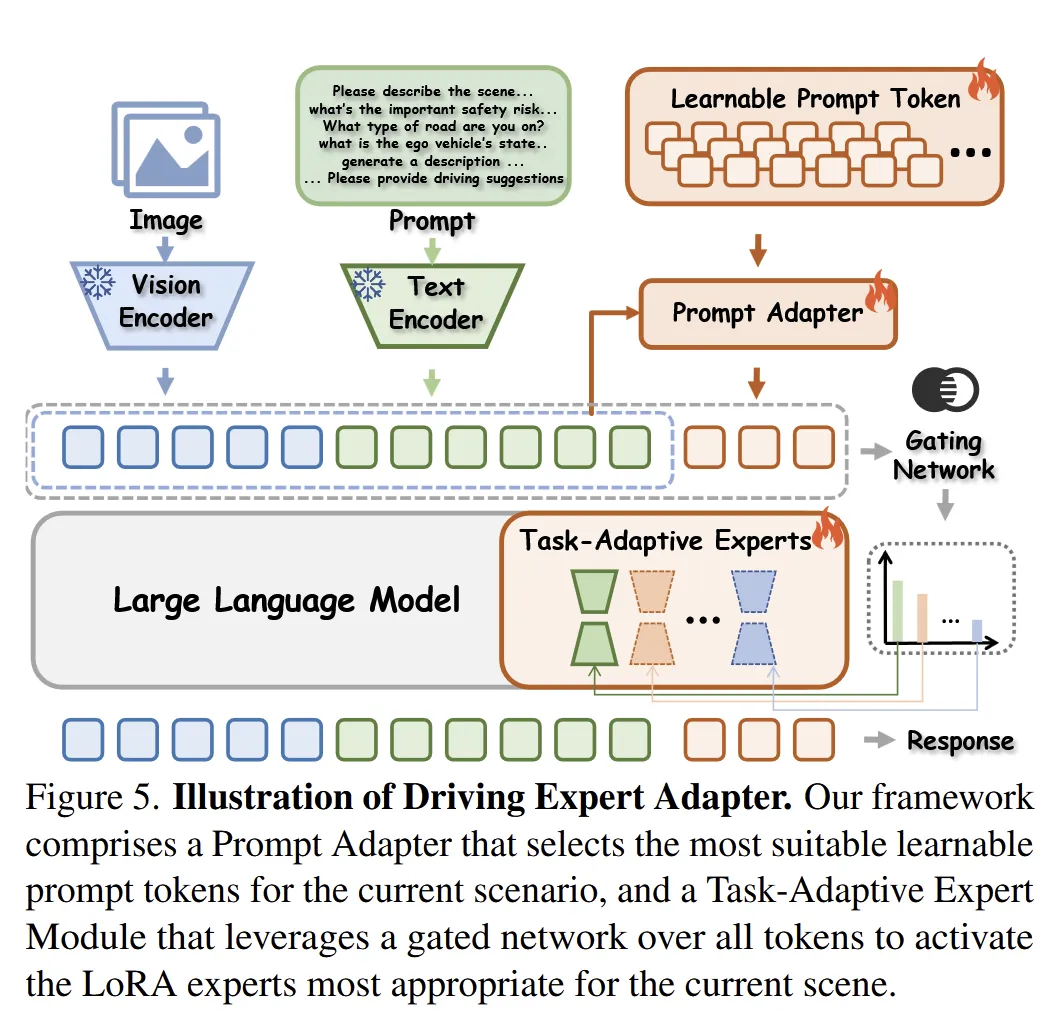
4. 从“权重适配”转向“提示适配”,提出 DEA
针对“适配增强任务性能,但会破坏原知识”的问题,作者提出 Driving Expert Adapter(DEA)。DEA 的核心思想是:尽量不去改动大模型核心参数,而是把驾驶知识注入到 prompt 和外接专家模块中。
DEA 主要由两个部分组成:
(1)Prompt Adapter(PA)
PA 通过一组可学习的 prompt token,把驾驶任务知识编码到提示中。输入问题到来时,模型会先提取语义表示,再检索最相关的 prompt embedding,把它们拼接到原始输入前面。这样做的好处是:
- 更有利于保留原有通用知识。
其整体思路可见图5左半部分。
(2)Task-Adaptive Expert Module(TAEM)
仅靠 prompt 还不够,因为简单 LoRA 虽保留了一些知识,但对复杂长尾场景的能力提升有限。为此,作者加入 任务自适应专家模块 TAEM。它本质上是一个面向驾驶场景的动态专家系统,不同专家分别适合不同驾驶状态,如拥挤路口、并线、高速、低能见度天气等;再由一个 gating network 根据场景线索和 prompt 语义选择合适专家。这个设计使模型不必用一个统一小模块去应对所有复杂情况,而能做到“按场景调专家”。这一结构在图5中有清晰示意。
5. 给出三条经验结论
论文在分析部分总结了三条很重要的经验规律:
- Guideline-1:训练数据的场景多样性越高,越有助于减轻遗忘。
- Guideline-2:全参数微调虽然能提高域内任务性能,但会显著加剧灾难性遗忘。
- Guideline-3:简单 LoRA 虽然比全参微调更“保守”,但它本身不足以提升模型在真正长尾场景下的能力。
这些结论主要来自表2、表3、表4以及图4的实验分析。
三、实验结果
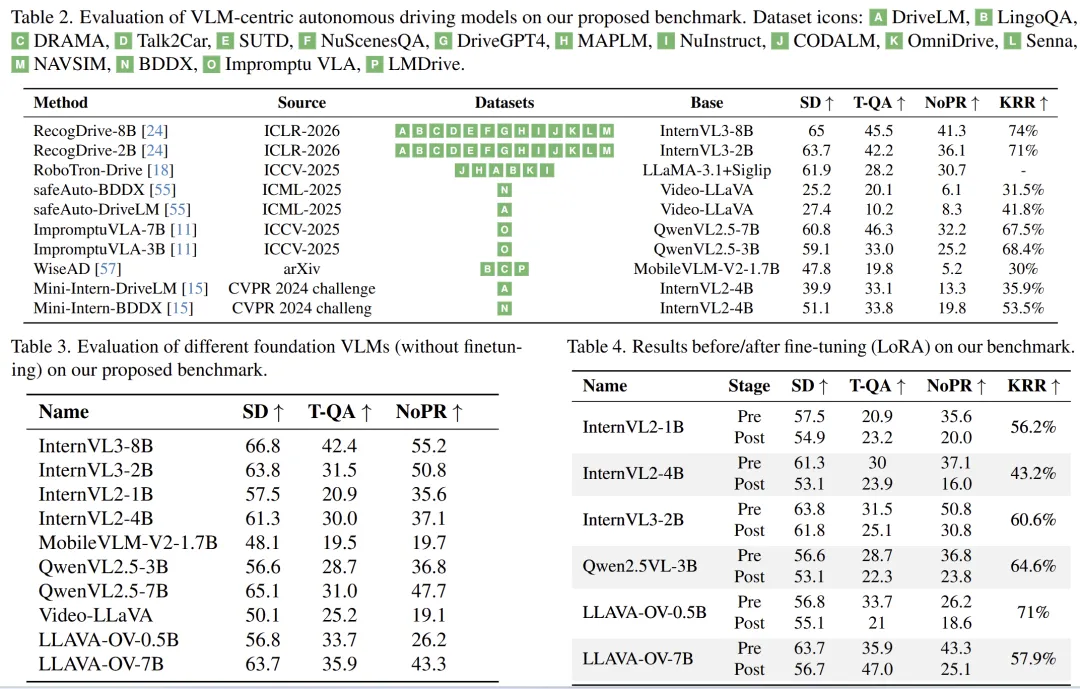
1. 现有驾驶VLM普遍存在明显遗忘
论文在 表2 中评测了多个已有自动驾驶VLM模型,如 RecogDrive、ImpromptuVLA、safeAuto、WiseAD 等。整体结果表明,这些模型虽然在场景描述(SD)和交通问答(T-QA)上取得一定成绩,但在 NoPR 和 KRR 上普遍不理想,说明微调后不同程度地损失了原有感知知识。
例如,RecogDrive-8B 的 KRR 为 74%,ImpromptuVLA-3B 为 68.4%,一些基于单一数据源的方法甚至更低。这表明遗忘并非个别现象,而是普遍问题。
2. 基础VLM原始感知能力往往比微调后更强
表3 评估了未经驾驶微调的基础VLM。可以看到,一些通用模型在 NoPR 上反而相当强,比如 InternVL3-8B 的 NoPR 达到 55.2。这说明基础模型其实拥有不错的通用视觉认知和长尾目标识别能力。
但一旦经过驾驶微调,这些能力会下降。论文在表4里展示了多个基础模型 LoRA 微调前后的对比,几乎都出现 NoPR 下滑。例如:
- InternVL3-2B:NoPR 从 50.8 降到 30.8
- InternVL2-4B:从 37.1 降到 16.0
- Qwen2.5VL-3B:从 36.8 降到 23.8
这组结果非常有说服力,直接证明了“微调导致遗忘”的客观存在。
3. DEA 在性能与知识保留之间取得更好平衡
最关键的结果在 表5。作者基于 Qwen2.5VL-3B 做对比实验,结果显示:
- Base+Full
- Base+LoRA
- Base+TAEM
- Base+TAEM+PA(DEA)
同时,DEA 在任务性能上也有提升:
- NoPR 达到 29.0,优于全微调和 LoRA 版本。
这说明 DEA 并不是单纯“保守地少学一点”,而是在保持原知识的同时,真正增强了驾驶任务适配能力。
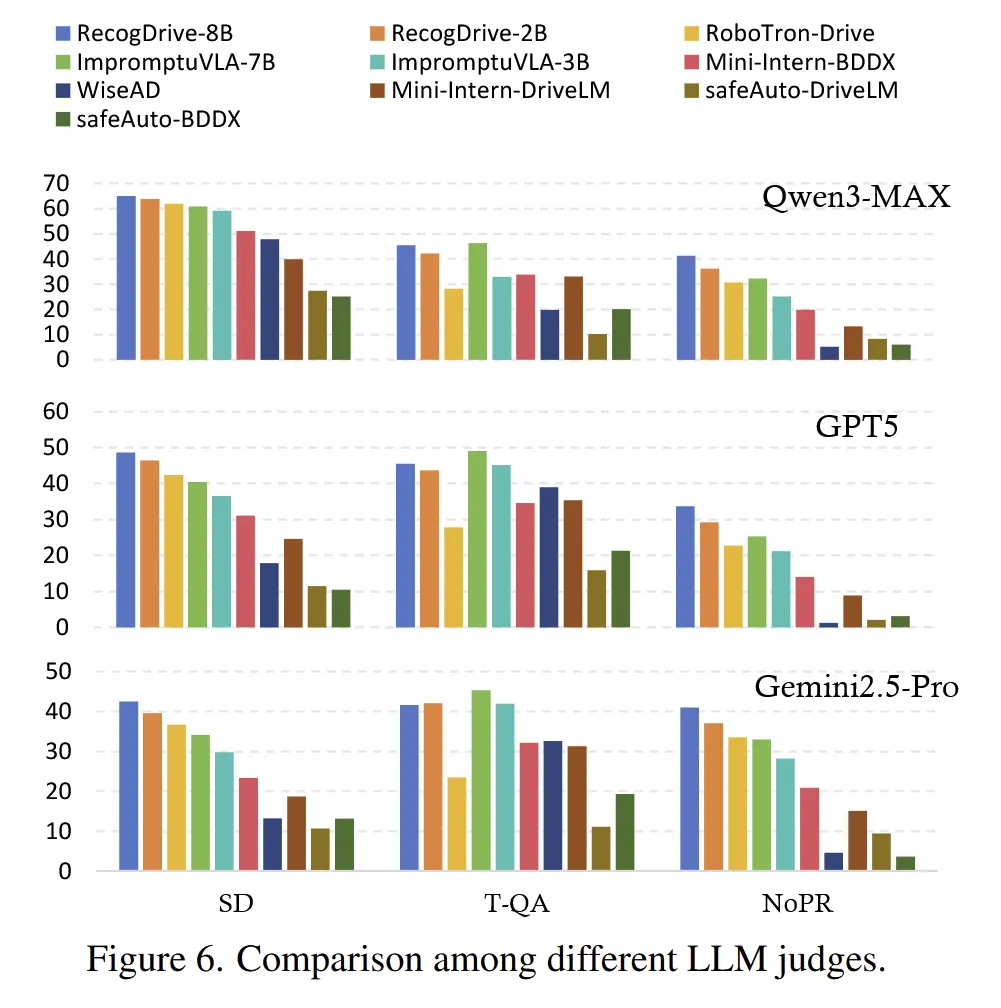
4. 评估结果对不同 LLM Judge 具有鲁棒性
作者还在图6中比较了不同大模型裁判(Qwen3-Max、GPT-5、Gemini-2.5-Pro)的评估结果。不同 judge 下各方法的排序基本一致,说明这个评测框架的结论不是偶然由某个裁判模型偏好造成的,而是比较稳健。
5. 定性结果显示 DEA 对长尾风险识别更细致
在图7中,作者给出夜间路口样例。DEA 能识别施工区域、交通风险和多个关键物体,而 ImpromptuVLA 漏掉了这些要素,甚至错误认为前方没有障碍。这种差异很能说明问题:DEA 不仅指标更好,而且在安全关键场景下,感知更细粒度、更可靠。
四、总结
这篇论文的价值主要体现在三个层面。
第一,它抓住了当前自动驾驶VLM研究中的一个真正痛点:微调并不总是“越调越好”,反而可能毁掉模型原本最宝贵的长尾泛化能力。这一点对自动驾驶尤其重要,因为安全问题往往正出现在罕见场景里。
第二,作者没有停留在问题指出上,而是系统构建了 Fidelity Driving Bench,把“遗忘”从一种经验印象,变成了可以被基准和指标量化的研究对象。特别是 NoPR + KRR 这套设计,针对自动驾驶安全需求非常贴切。
第三,在方法上,DEA 提供了一个很有启发性的思路:少改权重,多做知识路由与提示层注入。相比直接全参数微调,它更符合“在保留通用世界知识的前提下适配行业任务”的方向,也可能对机器人、医疗、遥感等其他垂直多模态场景有借鉴意义。
当然,这篇工作目前仍以单图前视相机场景和特定基础模型实验为主,后续如果能进一步验证在更大规模模型、多帧时序输入、闭环决策场景中的效果,影响力会更强。总体来看,这是一篇 问题意识很强、 benchmark 价值突出、方法设计有针对性 的论文。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~本文仅做学术分享,如有侵权、笔误等,请联系修改、删文.



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
