
📍 文 / 老Z
自动驾驶里有一个很烦人的问题,做了很多年了,一直没有很好的解法。
规划模块要生成车辆的行驶轨迹。理想的做法是用强化学习——给RL一个奖励函数,让它自己学怎么在复杂交通里既安全又高效。但实际上RL在这里很难用,原因很具体:轨迹是高维的连续序列(每个时间步都有x、y坐标),RL给的奖励是一个标量,稀疏的标量奖励很难指导高维的轨迹空间。
地平线机器人(Horizon Robotics)联合华中科技大学发了一篇RAD-2,用了一个挺巧妙的解耦思路把这个问题绕过去了。
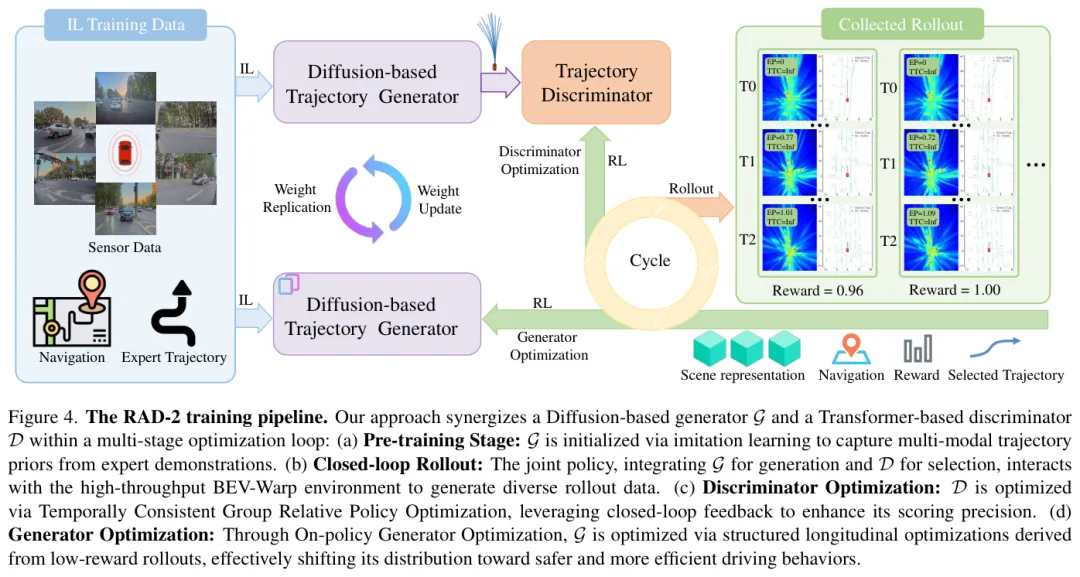
图:RAD-2的核心思路:扩散生成器负责多样性,RL判别器负责质量筛选,两者通过BEV-Warp环境联合优化
为什么这个问题这么难
先说清楚现有方案的困境。
自动驾驶规划大概有三条路:
第一条,回归一条轨迹。给当前场景,直接预测一个确定的轨迹。问题是真实驾驶有很多合理选项(跟车、变道、刹车都行),压缩成一个输出会丢失多模态信息,遇到模糊情况容易出错。
第二条,用扩散模型生成一批轨迹候选,再打分选一个。这条路多模态覆盖好,但训练靠模仿学习(IL),没有负反馈,生成的轨迹里依然会混进危险的选项,模型没法从失败里学。
第三条,直接用RL。理论上RL能从闭环交互里学到"什么是好的驾驶行为",但轨迹空间太高维,RL的梯度信号很难稳定地传回去,训练容易炸。
RAD-2的核心观察是:扩散模型和RL其实可以各干各的。
拆开来做
RAD-2把整个系统分成两个部分:
生成器:扩散模型,每次生成M条轨迹候选。它只负责多样性,覆盖各种可能的驾驶行为。
判别器:一个Transformer,用RL训练,给每条候选轨迹打一个分数(0到1),分数高的就是更安全更高效的轨迹。
这样RL只需要优化判别器——输入一条轨迹,输出一个标量分数。这比直接用RL优化高维的扩散过程容易稳定得多。
两个部件之间的数据流:生成器生成候选→判别器打分→选出最佳轨迹→在仿真里执行→根据结果反馈给判别器(RL更新)和生成器(OGO更新)。
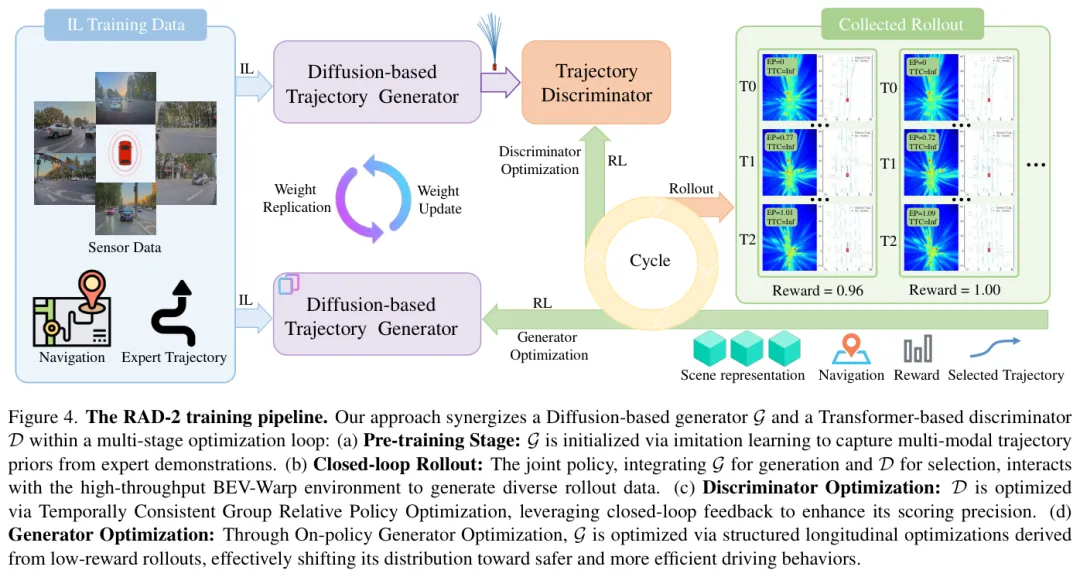
图:三阶段训练:先IL预训练生成器,再闭环RL训练判别器,同步OGO优化生成器分布
两个让训练稳定的设计
TC-GRPO(时间一致性群体相对策略优化)
GRPO本来是用来训练语言模型的——同一个prompt生成一组回答,在组内比较好坏。RAD-2把这个思路搬到驾驶上,但驾驶轨迹有时间相关性,不能像token那样独立处理。
他们引入了"轨迹锁定"策略:选出一条轨迹后,连续执行H步(H=8),而不是每步都重新规划。这样一段时间内的行为是连续的,结果好不好能明确归因到这条轨迹,RL的信号就稳定了。
OGO(在策生成器优化)
当判别器发现某条轨迹有碰撞风险,OGO把这个反馈转化为一个结构化的纵向调整信号:减速还是加速,调整多少。用这个调整信号来更新生成器的轨迹分布,让生成器逐渐往高回报区域移动。
这样避免了直接用稀疏奖励更新高维扩散模型,训练稳定很多。
BEV-Warp仿真
训练RL需要大量仿真交互。用CARLA这种游戏引擎,sim-to-real gap大;用3DGS精确重建,每个场景要重建很久。
BEV-Warp的思路是:不渲染图像,直接对BEV特征做空间变换(warp),模拟车辆移动后的感知结果。BEV特征是感知系统输出的中间结果,一旦存下来,模拟不同位置只需要做矩阵乘法级别的空间变换,速度快很多。
实验数字
闭环评估(BEV-Warp仿真,安全场景,512个测试片段):
碰撞率从0.533降到0.234,降了56%。At-Fault碰撞率(责任在自车的事故)从0.264降到0.092,降了65%。
在3DGS真实渲染场景的评估上,碰撞率0.250,Safety@1达到0.723,同样是所有方法里最好的。
开环评估(Senna-2 benchmark):CR降到0.142%,FDE 0.553m,ADE 0.208m,全面最低。
有一个细节挺有意思:推理时调整候选数量M(Table 10),M=32时碰撞率最低(0.234),M=64时导航效率EP@1.0最高(0.816)。不用重新训练,只需要在推理时多生成几条候选,判别器就能筛出更好的轨迹——这是判别器架构天然带来的inference-time scaling特性。
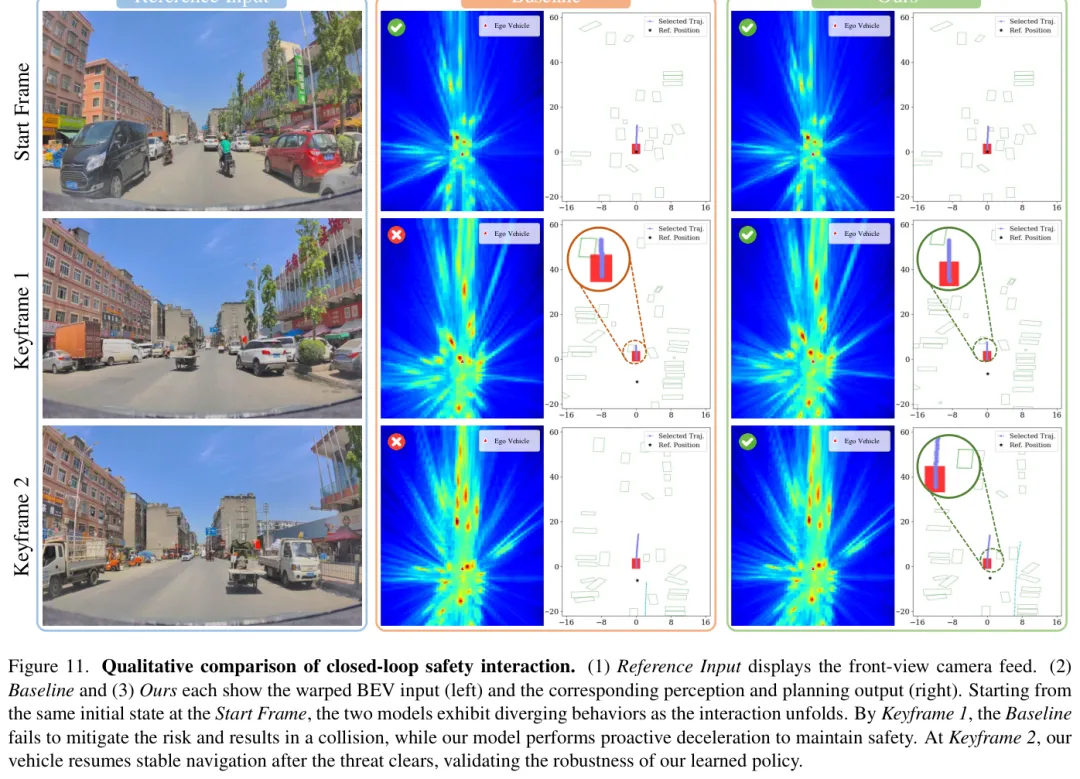
图:同一个场景下,基线在关键帧1发生碰撞,RAD-2通过预判性减速绕过了风险
消融实验说明了什么
训练pipeline的消融(Table 4)挺能说明问题。
只做IL预训练:Safety@1=0.418(ResAD级别)。加上OGO微调生成器:Safety@1升到0.682。再加上判别器RL:Safety@1到0.730。三步都要,缺哪步效果都打折扣。
判别器的初始化方式也很关键:从规划头权重初始化,Safety@1=0.615;随机初始化Safety@1=0.512。差了一截。理由是规划头已经学会了场景的结构表示,判别器从这里起步,开始就有合理的场景理解能力。
我的看法
这个工作聪明的地方是把一个难优化的问题拆开了。直接用RL优化高维扩散轨迹很难,但用RL训练一个判别器来挑轨迹就容易多了。分工之后两边都能稳定训练。
有什么疑问:推理时生成M条轨迹然后挑一条,计算量是baseline的M倍。M=32意味着扩散模型要运行32遍,在车上实时跑的时候这个延迟怎么控制,论文里没有详细讨论。
BEV-Warp的局限也值得注意:这套仿真依赖BEV特征的空间等变性,如果换成没有结构化BEV的视觉模型(比如端到端的视觉token方案),这套pipeline就得重新设计。
自动驾驶的仿真瓶颈一直没有很好的解法,RAD-2的BEV-Warp算一个实用的工程妥协——不是最精确的,但够快,能支撑大规模RL训练,这个取舍在当前阶段可能是对的。
arxiv: https://arxiv.org/abs/2604.15308
GitHub: https://github.com/hustvl/RAD
✍️ 老Z ·
欢迎转发,谢绝洗稿
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
