地平线开始回答自动驾驶世界模型的解法,CompoSIA方案解析......
- 2026-05-20 16:55:48

点击下方卡片,关注“自动驾驶之心”公众号
作者 | Yifan Zhan等
编辑 | 自动驾驶之心
本文只做学术分享,如有侵权,联系删文
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
自动驾驶的测试有一个老问题一直悬而未决:长尾场景。
nuScenes、Waymo 这些主流数据集,覆盖的基本上是"正常开车"的样子。常见车辆、常见路况、常见行为。而真正让系统出问题的,一般都是那些极少出现的组合 —— 一辆从未见过姿态的卡车突然横穿、前车以异常节奏急刹、对向车道来了一辆特殊的工程车……
这些东西,在真实采集的数据里出现频率极低,但它们又恰恰是安全的边界。
想要解决这个问题,一个常见的思路是用生成模型来"造场景"。但场景生成的难点在于细粒度控制:在保持视觉真实感的同时,又能按你的意图去改变"哪辆车长什么样"、"它走什么轨迹"、"自车怎么运动" —— 现有方法大多做不到同时控制好这三件事。
轨迹、外观、背景和控制信号之前互相干扰,也是自动驾驶场景生成最常见的问题。业内头部的公司也针对闭环仿真做了很多工作,像小鹏的X-World、理想的生成+重建、小米的一系列算法等等。最近,地平线也放出了自己在这个领域最新的研究成果产出,CompoSIA。

论文标题:Composing Driving Worlds through Disentangled Control for Adversarial Scenario Generation 论文链接:https://arxiv.org/abs/2603.12864 项目主页:https://yifever20002.github.io/CompoSIA/
一、自动驾驶视频仿真这几年
在聊 CompoSIA 之前,先把这个方向的发展脉络简单捋一下。
最早一批工作的目标很朴素:让生成的驾驶视频"看起来真实"。BEV 条件下的扩散模型、多视角一致性生成,这一代工作解决的核心问题是感知数据的扩充,代表工作有 Vista、WoVogen 和 MagicDrive-V2 等。它们能生成视觉质量不错的场景,但可控性有限 —— 可以指定大致布局,但细粒度的"这辆车换成另一辆、自车走另一条线"做不到。
另一条线,场景编辑方向开始发力。DriveEditor 等工作开始尝试对视频中的特定对象做身份替换,但要求输入姿态对齐的参考序列,操作复杂,难以推广到任意目标。
整体看下来,自驾视频仿真工作要么只控制了场景的一个维度,要么几个维度虽然都做了但彼此之间互相干扰。没有一个方法认真问过:结构、身份、自车动作,这三件事能不能同时控好、互不影响?
CompoSIA 就是在这个背景下出现的。
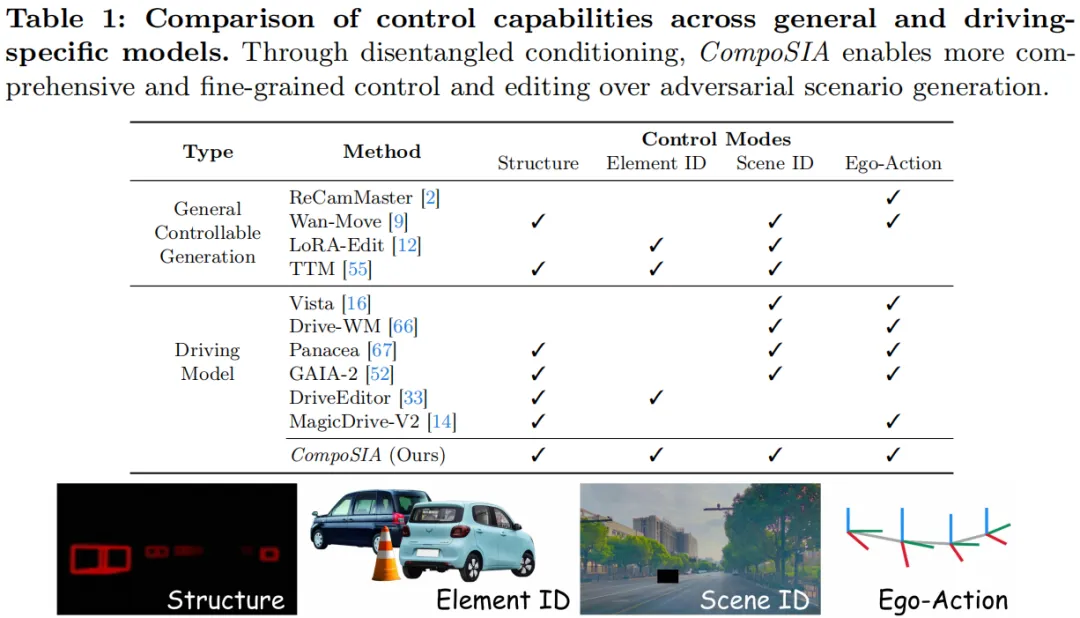
二、问题出在哪
现有的可控驾驶视频生成方法,有一个共性的困境:控制信号之间不够解耦。
场景的构成,直觉上可以分成几个相对独立的维度:场景里有哪些物体、它们在哪儿、长什么样、自车是怎么运动的。但在现有方法里,这几个维度往往是混在一起建模的。
比如,当你用 3D bounding box 去做结构控制时,box 的位置序列其实隐含了自车的运动信息——你以为自己只改了结构,但自车行为其实已经被结构信号"泄露"了。再比如,做 identity 控制时,如果直接用 attention 机制把参考图贴进去,模型往往对参考图的姿态很敏感,换个角度效果就变差了。
这些问题不解决,生成出来的场景要么不够可控,要么几个维度改一个、别的维度就跟着乱。
CompoSIA 的核心创新思路,就是把这三个维度显式分离,各自用针对性的方式注入,再在 Flow Matching-based DiT 骨干上统一组合。
三、核心模块解析
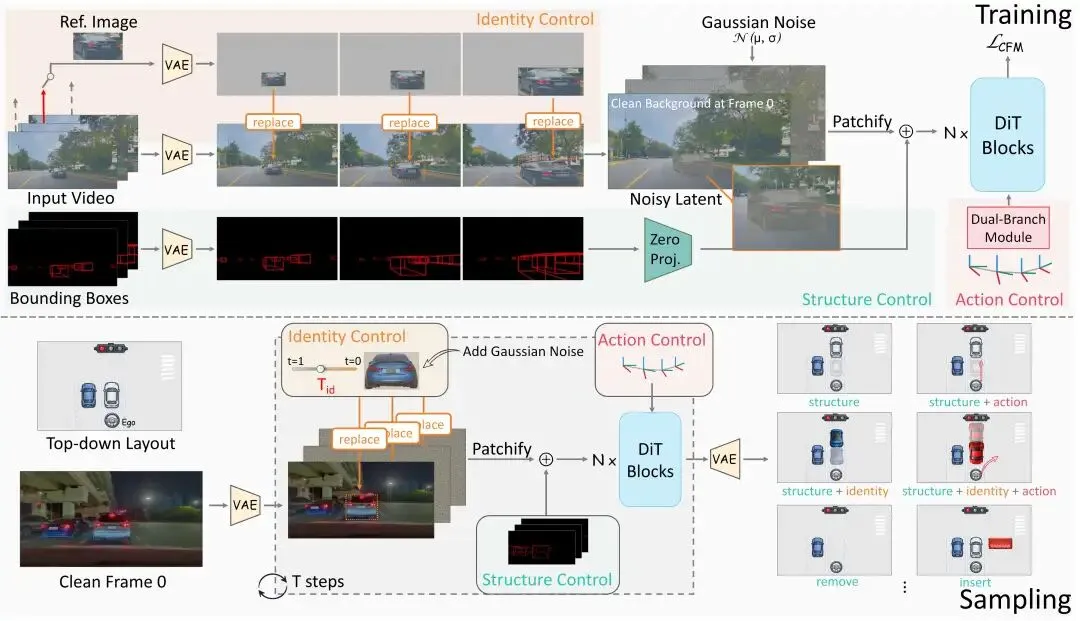
CompoSIA 的生成骨干基于 Continuous Flow Matching。中间状态 由噪声和干净样本插值得到,模型学习的是速度场 ,训练目标为:
在这个骨干之上,三个控制模块各自以不同的方式注入条件信号。
3.1 结构控制:时空布局驱动场景几何
结构控制负责回答"场景里的物体在哪、怎么动"。
CompoSIA 把 3D bounding box 序列通过相机内外参投影到 2D 图像空间,得到逐帧的空间布局:
其中 是 3D box 的顶点, 和 分别是相机内参和外参矩阵。得到的 2D 布局通过一个零初始化的投影模块注入到 DiT 的 latent 里:
这个设计不破坏原有的生成路径,同时把场景的几何结构锁住。
但这里有一个需要特别处理的地方:3D box 的位置序列天然包含自车运动信息,直接用会让结构信号把 ego action 的信息"带进来",导致两个控制维度混淆。所以结构控制必须和动作控制配合使用,才能真正把二者解开。
3.2 身份控制:噪声级注入,解决姿态依赖
身份控制是CompoSIA的第二大亮点。以往自驾视频编辑工作如DriveEditor需要姿态对齐的ID序列来进行身份控制,而这种控制方式太过复杂而难以scaling到任意ID。因此CompoSIA期待从单张参考图就能换掉场景中某个目标的外观。
过去的做法通常依赖 attention 机制,把参考图特征和生成特征做融合,但这类方法对参考图的视角很敏感,换个角度效果就变差了。CompoSIA 换了一个思路:直接在噪声空间里注入参考图。
具体做法是:先对参考图做与目标帧相同的加噪处理:
然后通过一个带阈值的掩码,在高噪声阶段把参考 latent 直接替换到目标区域:
其中 是参考图对应的空间掩码, 是阈值。当 (高噪声阶段),参考 latent 被强制写入目标区域——此时 latent 还很"模糊",模型会把替换进来的参考信号当作强约束,学到"这个区域要长成参考图的样子";而到了 (低噪声阶段),掩码关闭,模型可以自由补全姿态细节。这种 hard binding 不走 attention,彻底绕开了姿态敏感的问题。
训练时,以视频中某一帧为参考,构造"带参考注入的噪声 → 去噪目标帧"的训练对,参考图通过 2D bounding box 做空间对齐,覆盖到目标区域。这样模型学到的,是"从任意视角的参考图恢复目标外观",而不是"复制参考图的姿态"。
结果是:单张参考图就能驱动目标以任意姿态出现,FVD 相较 DriveEditor 提升了 17%。

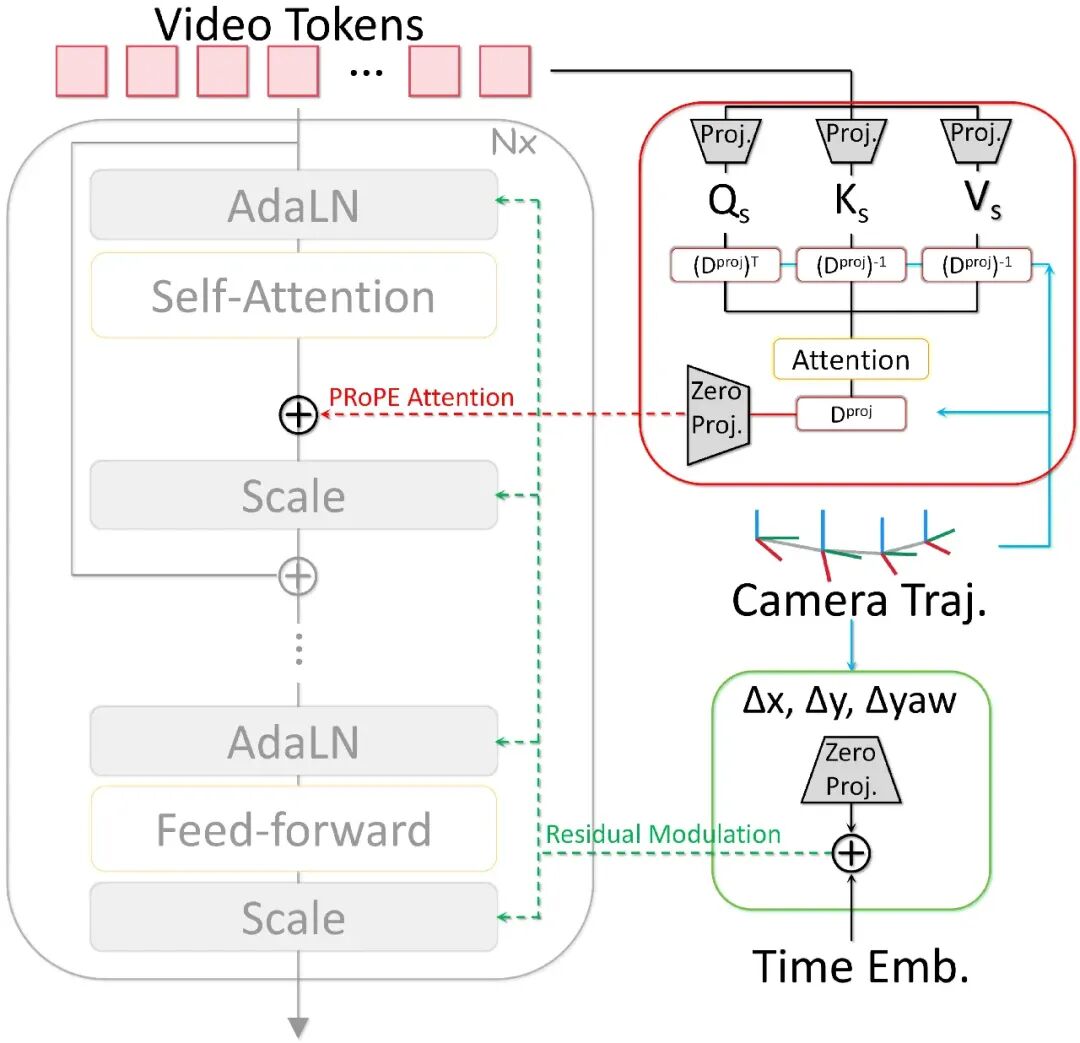
3.3 动作控制:双分支层级机制,管住自车行为
动作控制负责回答"自车怎么开",这也是整个系统里最容易和结构信号耦合的部分。
CompoSIA 设计了一个层级双分支结构:
局部残差调制(Local Residual Modulation):从相邻帧的位姿变换中提取局部运动信号:
这个信号通过 adaptive layer normalization 注入 DiT block,负责捕捉短程的运动变化,让模型在早期训练中快速收敛。
全局 PRoPE 嵌入(Global Projective Positional Encoding):把相机的内外参信息编码进 positional embedding,通过投影矩阵 构建相机感知的注意力:
这种设计让注意力机制直接感知相机运动,处理长程的轨迹一致性。为了控制计算开销,系统把 token 投影到低维子空间做运算,在保持精度的同时降低计算量。
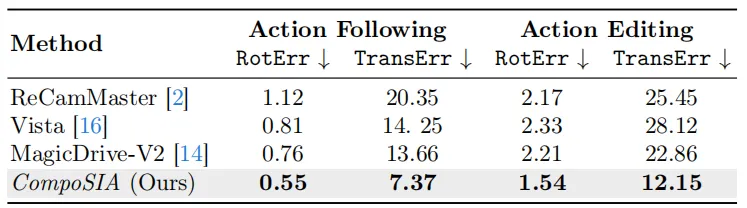
两个分支互补:局部分支管短程精度,全局分支管长程稳定。消融实验里,单独用 PRoPE 的 RotErr 为 0.62,两者合用降到 0.55;与最强 baseline MagicDrive-V2 相比,TransErr 从 13.66 降到 7.37(降低 46%),RotErr 从 0.76 降到 0.55(降低 28%)。
四、效果:压力测试让碰撞率涨了 173%
CompoSIA 的最终目标不是生成好看的视频,而是生成能让规划器出错的场景。
定量指标上:
Identity 控制:FVD 较 DriveEditor 提升 17% Action 控制:旋转误差降低 30%,平移误差降低 47% 跨视角和时序一致性:优于 MagicDrive-V2
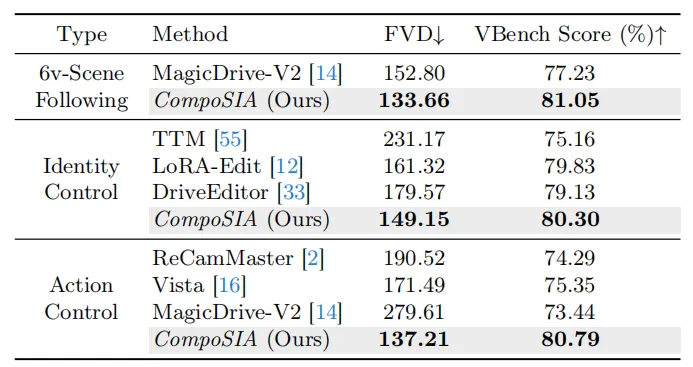



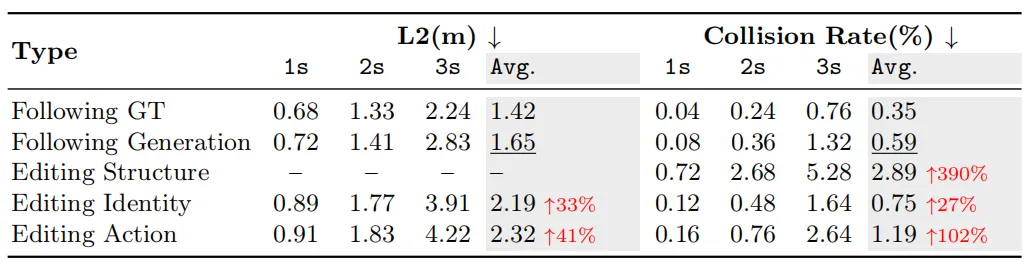
实验里,作者把 CompoSIA 生成的对抗场景接入下游规划器 Epona 做压力测试。结果:跨所有编辑模式,平均碰撞率提升了 **173%**。其中结构编辑单项就能让碰撞率提升 390%——换句话说,仅仅改变场景里物体的位置和轨迹,就足以让规划器大量失效。
这说明 CompoSIA 生成的不只是"看起来危险"的场景,而是真正能暴露规划器漏洞的有效测试样本。
五、结语
整体看下来,CompoSIA 在回答一个问题:
★驾驶场景的各个维度,真的可以独立控制吗?
答案是可以,但需要针对每个维度的特性去设计对应的解耦方式——结构的几何映射、身份的噪声级复原、动作的层级双分支——不能用一套通用机制把三件事一锅端。
生成式视频模型在感知数据增强上已经有很多工作,但如何让生成的场景真正服务于安全测试,还有很大的探索空间。CompoSIA 走的是"可控 + 对抗"这条路,把生成模型和规划器的压力测试真正连起来。
后续怎么走,还值得继续看。
自动驾驶之心





随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 纯电SUV只看这四款,其它都可以左划送走
- 别克E5掀起合资纯电SUV新战局
- 别克E5掀起合资纯电SUV新战局
- KONI车型案例分享:轿车系列 高尔夫7 R
- 世界,尽在于心|梅赛德斯-奔驰S级轿车东莞鹏龙私享品鉴会火热招募中
- 智能、安全、动力、舒适,豪华中级轿车老对手硬碰硬
- 泪目!奥迪RS6轿车版复活,阔别15年硬刚宝马M5!
- 云南镇雄一小轿车被公交车顶着撞上大树,车身严重损毁,公交公司:小上一名大人和一名孩子均被送医检查,身体无大碍,孩子仅受惊
- 云南镇雄一小轿车被公交车顶着撞上大树,车身严重损毁,公交公司:小上一名大人和一名孩子均被送医检查,身体无大碍,孩子仅受惊
- 【新车上市】敢为此刻,金标大众全新旗舰SUV与众08正式上市
