论文标题:OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
作者团队:Xiaomi Embodied Intelligence Team(Jinghui Lu、Jiayi Guan、Zhijian Huang、Jinlong Li、Guang Li、Lingdong Kong、Yingyan Li、Han Wang、Shaoqing Xu、Yuechen Luo、Fang Li、Chenxu Dang、Junli Wang、Tao Xu、Jing Wu、Jianhua Wu 等)
发布时间:arXiv:2604.18486v1,2026年4月20日
论文地址:https://arxiv.org/abs/2604.18486
项目主页:https://Xiaomi-Embodied-Intelligence.github.io/OneVL
背景与目标
视觉语言模型(VLMs)已成为自动驾驶的核心组件,统一了场景理解、自然语言推理和端到端轨迹规划。当 VLM 扩展到输出动作(如轨迹路点或控制信号)时,被称为视觉语言动作模型(VLA)。
核心问题:链式推理(Chain-of-Thought,CoT)虽然能显著提升轨迹预测质量,但其自回归生成特性带来了极高的推理延迟,难以满足实时自动驾驶的需求。
隐式 CoT 的困境:现有隐式 CoT 方法(如 COCONUT、CODI、SIM-CoT)尝试将推理压缩到连续隐状态以降低延迟,但始终无法达到显式 CoT 的准确率。OneVL 论文指出根本原因:纯语言隐表示压缩的是符号抽象,而非真正支配驾驶的因果动力学。
OneVL 的目标是:找到一种隐式推理方法,既能达到显式 CoT 的准确率,又保持"答案仅预测"的推理速度。
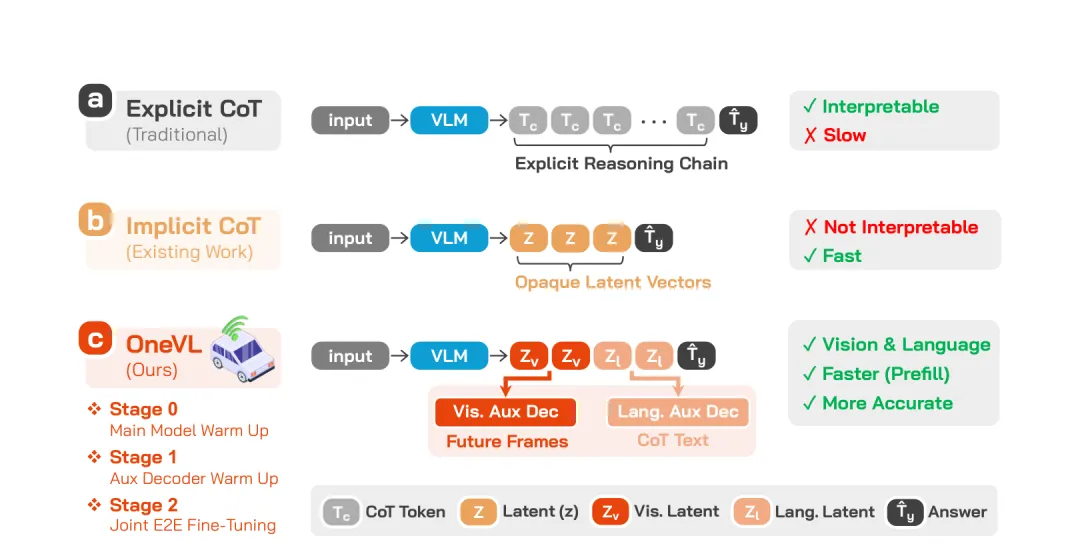
图1:三种CoT范式对比。(a)显式CoT:逐token生成离散推理链,可解释但延迟高;(b)隐式CoT:压缩为连续隐向量,速度快但不可解释;(c)OneVL(本文方法):引入双类型隐token(视觉隐tokenZv和语言隐tokenZl),训练时由视觉辅助解码器(预测未来帧)和语言辅助解码器(预测CoT文本)监督,推理时丢弃解码器实现高速推理(来源:原论文 Figure 2)
方法
三种 CoT 范式的对比
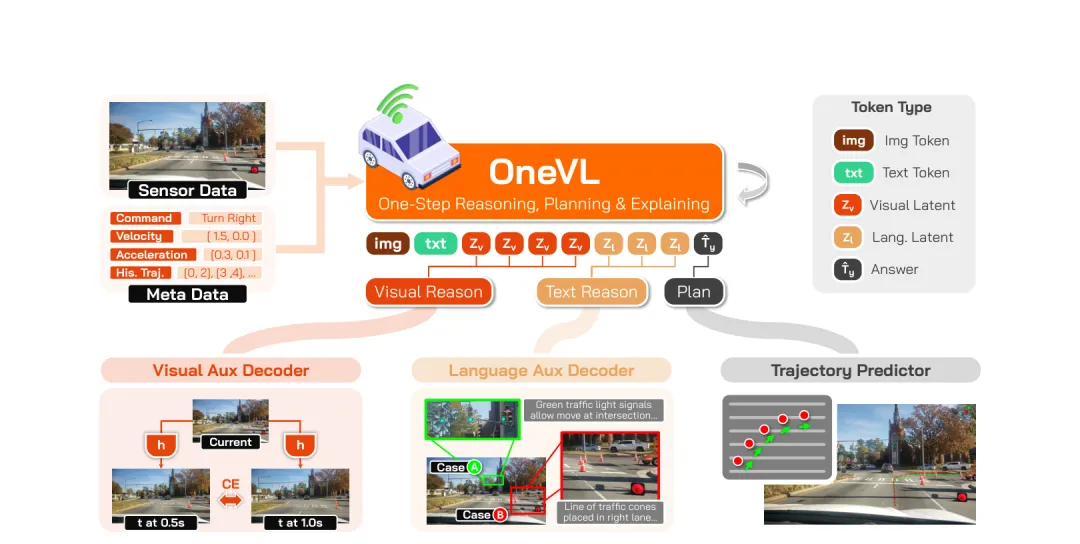
图2:OneVL整体架构。输入图像和结构化元数据(命令、速度、加速度、历史轨迹),经VLM处理输出包含图像token、文本token、视觉隐token(Zv)、语言隐token(Zl)和轨迹答案token。训练时Zl路由到语言辅助解码器预测CoT推理文本,Zv路由到视觉辅助解码器预测0.5s和1.0s的未来帧;推理时两个解码器完全丢弃,隐token直接预填充到上下文实现单次并行前馈(来源:原论文 Figure 3)
论文首先系统对比了三种 CoT 范式:
(a)显式 CoT(传统):模型逐token生成离散推理链(如"前方有行人,应减速"),再输出轨迹。可解释性强,但每个推理token都要逐个自回归生成,延迟高(NAVSIM 上约10.74秒)。
(b)隐式 CoT(现有方法):将推理压缩为少量连续隐向量 Z,直接输出轨迹。速度快,但隐向量不可解释,且实验表明所有隐式 CoT 基线在自动驾驶轨迹预测任务上均不如"仅答案"的自回归基线。
(c)OneVL(本文方法):引入双类型隐token,分别由视觉世界模型解码器和语言解码器监督。训练时通过两个辅助解码器验证隐token是否编码了有意义的推理内容;推理时丢弃辅助解码器,将隐token直接预填充到上下文,一次并行前馈完成,延迟与"仅答案"预测相当。
核心设计:双类型隐token
OneVL 引入了两类专门设计的隐token,作为紧凑的隐式推理载体:
语言隐token(⟨|latent|⟩):固定长度为2个token,放在助手回复中轨迹答案之前,位置对应显式 CoT 所在位置。提取这些位置的隐状态后,编码了模型对驾驶场景的语言接地推理。
视觉隐token(⟨|latent-vis|⟩):固定长度(从架构图看有4个),同样放在助手回复中。视觉隐token 编码的是空间-时间视觉推理信息。
双辅助解码器
语言辅助解码器:将语言隐token路由到一个小型解码器Dl,训练目标是通过交叉熵损失重建标准 CoT 推理文本。这确保了语言隐token携带语义丰富、可解码为自然语言的内容。
视觉辅助解码器:将视觉隐token路由到一个视觉解码器Dv,训练目标是在0.5秒和1.0秒的未来时间点预测视觉token。论文认为这是关键创新:未来帧视觉token直接表示驾驶场景在短时间内的样子,预测这些token迫使模型内部化道路几何、智能体运动和环境变化的因果动力学——而这是纯语言 CoT 无法可靠编码的物理因果结构。
视觉解码器作为世界模型(World Model)的辅助:它提供了一个具体的、物理接地的压缩目标(未来视觉观测),无法通过语言级记忆来满足,必须编码真实的场景动态才能最小化重建损失。
三阶段训练
由于联合端到端训练会导致梯度爆炸和任务冲突(直接端到端训练的 PDM-Score 从 88.84 暴跌至 67.13),OneVL 提出了三阶段训练课程:
Stage 0(主模型热身):冻结视觉编码器和 LLM 主干,仅训练隐token嵌入层,让主 VLM 在轨迹预测任务上学会正确放置隐token。
Stage 1(辅助解码器热身):解冻辅助解码器,固定主模型,使隐token能够被有效解码为有意义的未来帧和语言文本,同时保持主模型能力不受影响。
Stage 3(联合端到端微调):所有组件联合优化,整体轨迹预测损失 + 语言解释损失(λl=1.0)+ 视觉解释损失(λv=0.1)。
Prefill 推理
推理时直接丢弃两个辅助解码器。关键效率洞察:隐token在训练时已经见过特定的token身份,因此可以在前馈阶段直接预填充到提示上下文,而不是逐个自回归生成。现代 Transformer 并行处理整个 prefill 序列,增加的隐token几乎不产生额外开销。模型只需自回归生成最终的轨迹token。
实验结果
OneVL 在四个主流基准数据集上进行了评估:NAVSIM、ROADWork、Impromptu 和 APR1。
图3:NAVSIM基准预测可视化(第一种视角)。图像为某停车场出口场景,绿色轨迹为真实路线,红色为模型预测轨迹。(来源:原论文 Figure 4 局部)
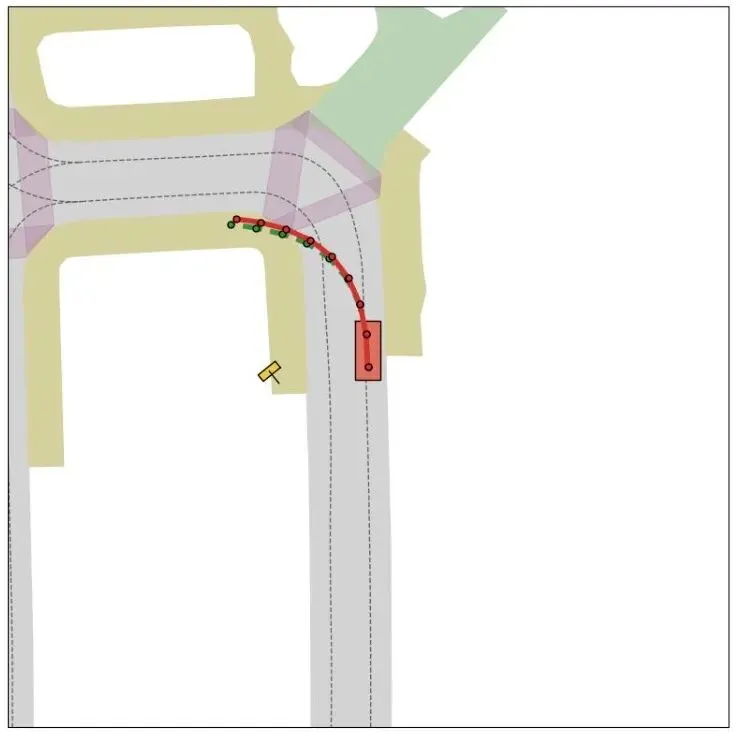
图4:NAVSIM基准预测可视化(俯视BEV地图)。图中可见T字路口的道路结构,灰色为路面,虚线为车道边界,红色车辆为自车,红色实线/绿色虚线为预测/替代轨迹。(来源:原论文 Figure 4 局部)
图5:NAVSIM基准预测可视化(第二种视角,与图3同一场景不同视角)。绿色轨迹为真实路线,红色轨迹为预测路线。(来源:原论文 Figure 4 局部)
NAVSIM 基准(主要结果)
NAVSIM 是最重要的自动驾驶轨迹预测基准。OneVL 以 4B 参数(Qwen3-VL-4B-Instruct 主干)达到 88.84 PDM-Score,显著超越此前最优的 AdaThinkDrive(86.20)和 LaST-VLA(87.30),同时推理延迟仅为 4.46 秒,与 AR Answer 模式(4.49秒)几乎相同,远快于 AR CoT+Answer(10.74秒)。
OneVL 是首个在隐式 CoT 框架下超越显式 CoT 的方法(88.84 vs 88.29)。
ROADWork 基准
ADE(Average Displacement Error)达到 12.49 像素,FDE 为 28.80 像素,大幅超越此前的 SOTA YNet(22.68/80.78),同时也明显优于 AR CoT+Answer(13.18/29.98)和所有隐式 CoT 基线。推理延迟 4.71 秒,与答案仅预测模式(4.74秒)持平。
Impromptu 基准
ADE 为 1.34 米,L2 误差平均 1.01 米,同时延迟仅 4.02 秒。显著超越 Impromptu VLA(1.60/4.28)和 AR CoT+Answer(1.42/3.96,延迟 6.84 秒)。
APR1 基准
ADE 为 2.62 米,FDE 为 7.53 米(略低于 Cosmos-Reason 的 7.42),同时延迟仅 3.23 秒。
消融实验
消融实验揭示了各组件的贡献(NAVSIM PDM-Score):
完整 OneVL 模型达到 88.84。移除视觉解码器后降至 87.97(贡献 +0.87),表明视觉世界模型监督提供了最关键的增益。移除语言解码器后降至 88.53(贡献 +0.31),表明语言解释监督有辅助作用。不使用三阶段训练直接崩溃至 67.13(下降 21.71 分),证实了三阶段训练课程的必要性——没有它,模型无法有效学习。
MLP 实时部署变体
为满足量产车端到端实时需求,OneVL 还提供了一个 MLP 回归头变体:用 MLP 头替代自回归解码轨迹,直接前馈预测路点。该变体达到 86.83 PDM-Score,延迟仅 0.24 秒(约 4.16 Hz),在延迟敏感的量产部署中具有实用价值。
核心洞察与分析
视觉监督为何比语言监督更重要
消融实验显示,视觉辅助解码器贡献了 +0.87 PDM-Score,而语言解码器仅贡献 +0.31。论文认为这种不对称性反映了世界模型的核心作用:自动驾驶轨迹预测本质上是空间预测任务,预测 0.5-1.0 秒后的场景外观,直接提供了与轨迹预测几何特性高度一致的监督信号。视觉未来帧预测本质上是一个世界模型目标:要最小化未见配置的重建损失,视觉隐token必须编码场景的因果动力学,而不仅仅是当前外观。相比之下,语言 CoT 用抽象符号描述推理过程,在精确性上隔了一层。
压缩驱动泛化
论文将 OneVL 的成功归结为一个核心假设:压缩驱动泛化。信息瓶颈原理预测:紧凑的隐token迫使模型在最相关的推理上提炼,过滤掉无关或冗余内容,获得比冗长自由形式 CoT 链更好的泛化能力——后者可能引入与轨迹预测无关的推理噪音。
为何先前隐式 CoT 方法失败了
先前方法(COCONUT、CODI、SIM-CoT)压缩的是语言描述,而非场景动力学本身。语言已经是物理世界的抽象,编码语义标签和关系,而非决定未来结果的时空因果动力学。这些方法满足了压缩原理的效率条件,但没有满足智能条件。此外,这些基线没有使用三阶段训练课程,因此隐token流与轨迹及多模态监督的对齐可能很差。
总结
OneVL 提出了一个自动驾驶轨迹预测的统一 VLA + 世界模型框架,其核心洞察是:先前隐式 CoT 方法失败的原因在于压缩目标错误——压缩语言而非场景动力学。通过引入视觉世界模型辅助解码器,预测未来帧视觉 token,提供了一个具体的、物理接地的压缩目标,使隐表示能够内部化真实的因果场景动态。
在推理阶段,两个辅助解码器被完全丢弃,所有隐token在前馈阶段并行预填充,以与"答案仅预测"相当的延迟输出轨迹。在四个基准数据集上,OneVL 成为首个超越显式 CoT 的隐式 CoT 方法,同时提供视觉和语言双重可解释性。
主要参考文献
1. Chen L, Sinavski O, Hünermann J, et al. Driving with LLMs: Fusing Object-Level Vector Modality for Explainable Autonomous Driving. IEEE ICRA, 2024. (VLA自动驾驶基础工作)
2. Mao W, Lin X, Wei Q, et al. TriAttention: Efficient Long Reasoning with Trigonometric KV Compression. arXiv:2604.04921, 2026. (隐式CoT推理优化)
3. Chi H, Gao H, Liu Z, et al. Impromptu VLA: Open Weights and Open Data for Driving Vision-Language-Action Models. NeurIPS, 2025. (Impromptu VLA基准)
4. Feng T, Wang Y, Yang Y. A Survey of World Models for Autonomous Driving. arXiv:2501.11260, 2025. (自动驾驶世界模型综述)
5. Geng J, Du D, Zhang Y, et al. DICC: Driving in Corner Cases. arXiv:2512.16055, 2025. (自动驾驶极端场景benchmark)


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
