数据壁垒:自动驾驶的阿喀琉斯之踵
自动驾驶领域积累了机器人学中最丰富的传感器数据,但这些数据被锁在一个个孤岛里。每个数据集都采用不同的模态定义、采样率、同步方案与标注规范,想混合训练三个模型?工程师得先啃下三套格式转换的硬骨头。NLP领域靠共享语料库催生出大语言模型,通用机器人领域也通过LeRobot实现了跨实体统一,自动驾驶却迟迟未能迈出整合这一步。
123D:化零为整的模块化设计
123D开源框架用一套API终结了混乱。它的核心思想十分朴素:把相机、激光雷达、自车状态、交通灯、高精地图等每一种模态都看作独立的事件流,每条记录只带上精确的时间戳,全部存入Apache Arrow IPC文件。数据解析器负责从原始数据集中提取标准化内容,写入器将其序列化为自包含的日志,上层Scene API则提供统一的访问入口。图像和点云既可以直接打包进文件方便移动,也可以只存路径引用节省本地空间,还支持JPEG、Draco等多种压缩方式。
同步表:对不齐的时钟,一次查表解决
相机10Hz、激光雷达20Hz、标注只有2Hz——过去对齐这些频率只能重采样,数据膨胀还丢失精度。123D创造性地引入同步表:存储层预计算一个映射表,记录每个同步时刻各模态最匹配的数据帧索引。访问时一次查表即可获得对齐后的多模态数据,想要更灵活的模式?绕过同步表,按任意时间戳做精确或最近邻查询也一样直接。这种“存储独立、逻辑对齐”的设计,让数据管理体量不变,访问效率却大幅提升。
高精地图与坐标的大一统
地图碎片同样令人头疼。123D定义了覆盖各个数据集的矢量化地图超集,把车道、路口、人行横道等全部打包到一个文件里,并利用R树空间索引实现半径查询,随要随取。另一层统一是对齐坐标系:强制将自车坐标系转为ISO 8855标准,相机转为OpenCV约定,不同传感器的空间偏移通过车辆模型推断的变换矩阵归算到后轴中心,下游的规划与碰撞检测终于有了稳定坐标基座。
创新不是换个格式,而是保留可能
123D不做生硬的类别映射,保留原始标注,只提供到通用类别的延迟映射,避免不可逆的信息丢失。这让后续的开放词汇模型或自动重标注有了原始依据。全模态通用接口、同步表、保留原始标注、灵活的存储模式,这些创新让123D不仅能支撑3D目标检测,也能胜任规划仿真、新视角合成等多类型任务,弥补了以往“任务特化”框架的互操作性缺陷。
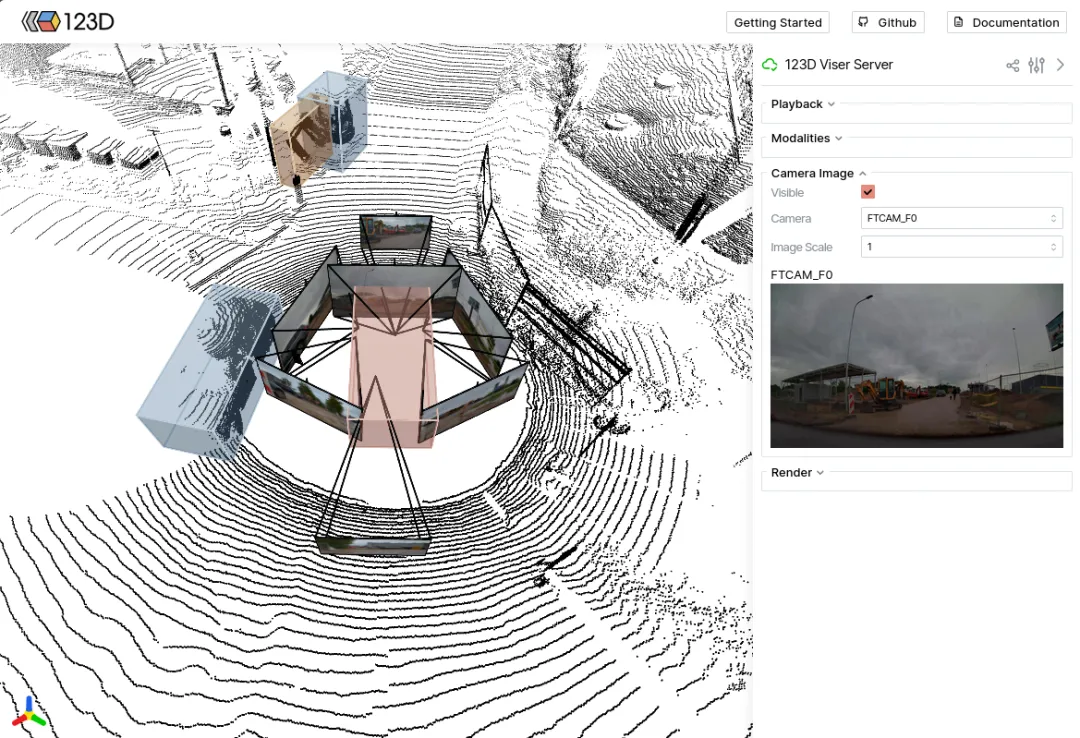
实战初显锋芒
目前123D已完成nuScenes、Waymo Open Dataset和Argoverse 2三大主流数据集的转换,配套的3D Viewer可以交互浏览统一后的数据。实验表明,在固定训练帧数下,直接混用不同数据集的样本进行3D目标检测,模型的泛化性能明显优于单数据集训练,初步验证了数据整合的规模化效益。强化学习规划也在简化场景中成功验证了跨数据集训练的可行性。
铺平通往通用驾驶智能体的道路
123D有望成为自动驾驶的“Hugging Face Datasets”,让研究者把精力从数据工程转向模型探索。未来,框架计划扩展对毫米波雷达、语义点云等更多模态的支持,并融入云端流式数据访问,进一步放大数据多样性的价值。当数据孤岛被桥梁连接,训练出具备城域级泛化能力的驾驶智能体便不再是奢望。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
