自动驾驶领域有两条公认的技术路线:VLA(视觉语言动作模型)负责"看路+决策",世界模型负责"预测未来会发生什么"。
过去,这两条路各走各的,井水不犯河水。
小米昨天把这两条路合二为一了。
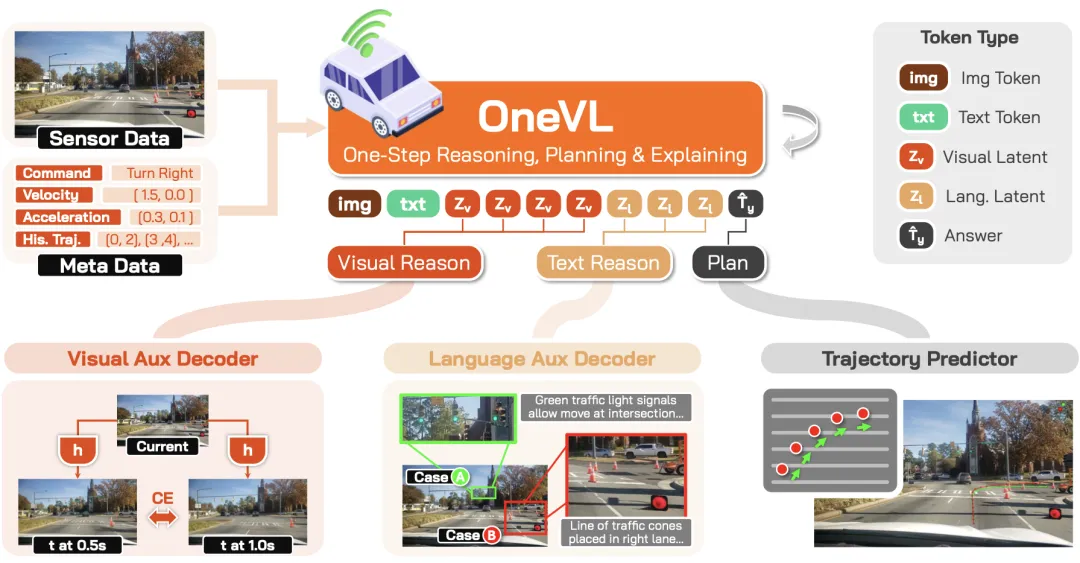
5月13日,小米技术正式发布并开源了 Xiaomi OneVL——业内第一个把VLA、世界模型、潜空间推理统一到同一框架的自动驾驶模型。
而且,全面开源。代码、权重、训练方案,全部放出来。
OneVL 解决了什么问题?
先说背景。
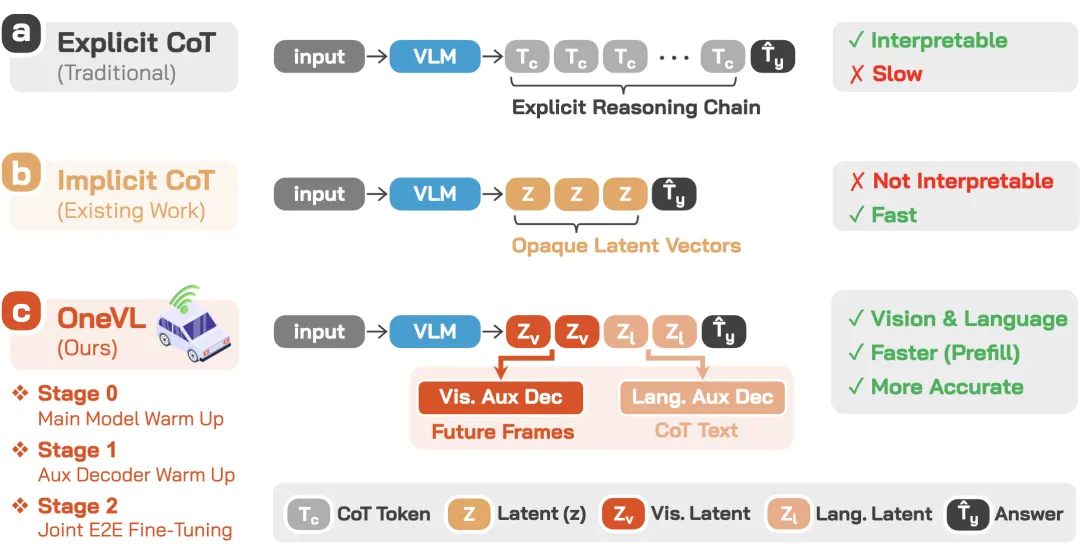
自动驾驶模型要"思考",目前主流方案是 Chain-of-Thought(CoT)——让模型像人一样,一步步推理:"前面有行人→减速→观察行人动向→决定是否绕行"。
这种显式推理效果好,但有个致命问题:太慢了。自回归一步步生成推理链,延迟太高,车开到路口了推理还没跑完。
业界一直在尝试 潜空间 CoT(Latent CoT)——把推理过程压缩到隐藏状态里,不生成文字,直接出结果。快是快了,但精度明显不如显式推理。
为什么?
小米团队的核心洞察是:你压缩的对象本身就错了。
纯语言的潜空间只能压缩符号化的抽象概念,无法捕捉驾驶场景中的真实因果关系。就好比你用文字描述一辆车的运动轨迹,再怎么精确,也不如直接看一段视频来得直观。
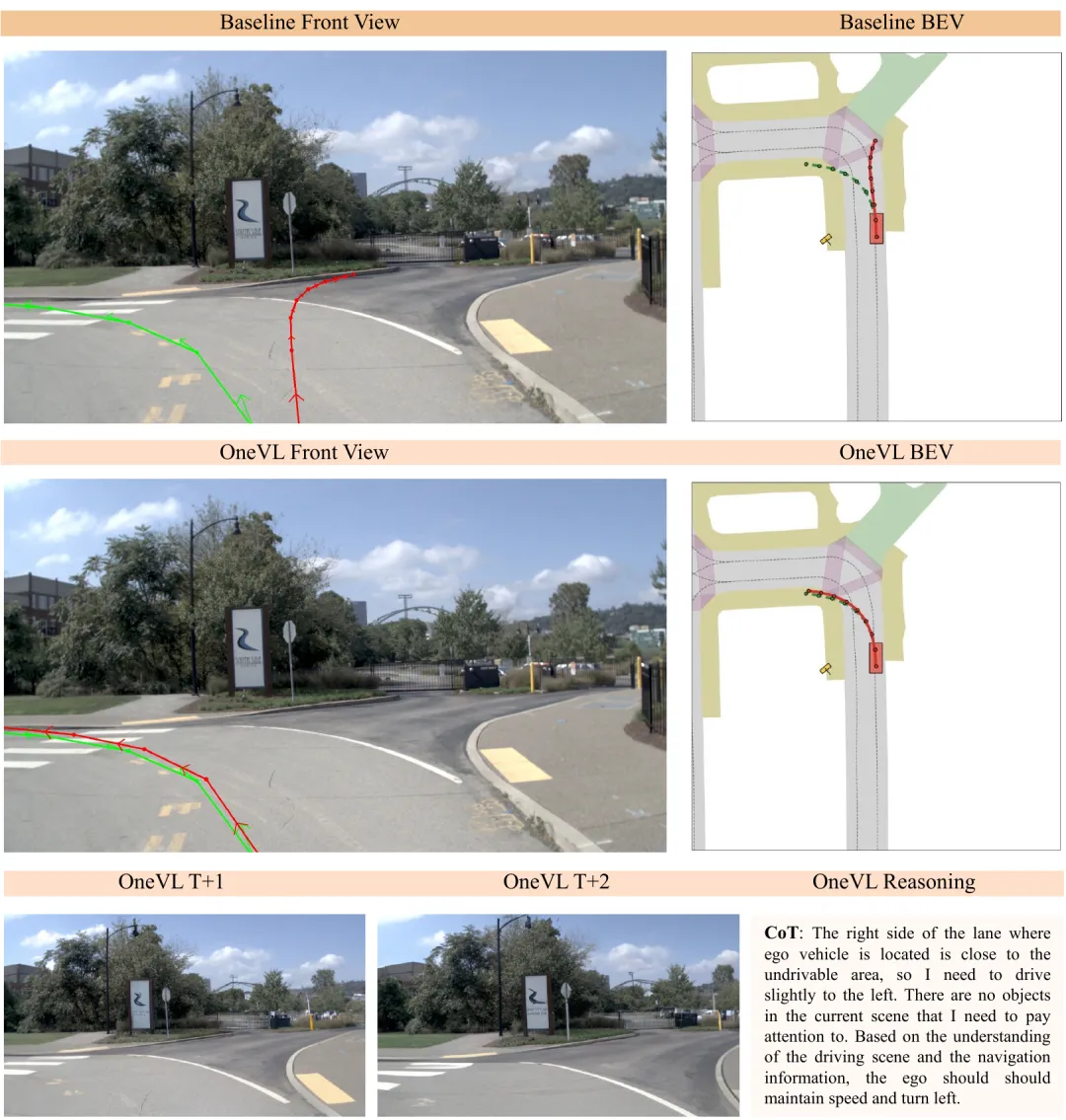
OneVL 的解法:双管齐下
OneVL 的核心设计很巧妙——在潜空间里塞了 两个辅助解码器:
🔹 语言解码器:从潜空间状态中还原出可读的推理链文字——"为什么这么开"
🔹 视觉世界模型解码器:预测未来0.5秒和1秒的画面——"接下来会发生什么"
这两个解码器在训练时一起工作,强迫潜空间同时编码语言语义和物理因果动态。但在实际推理时,两个解码器全部丢掉,只保留压缩后的潜空间做单次前向推理。
结果就是:精度超过了显式CoT,速度对齐了"只给答案"的最快方案。
一句话概括:又快又准,还能解释。
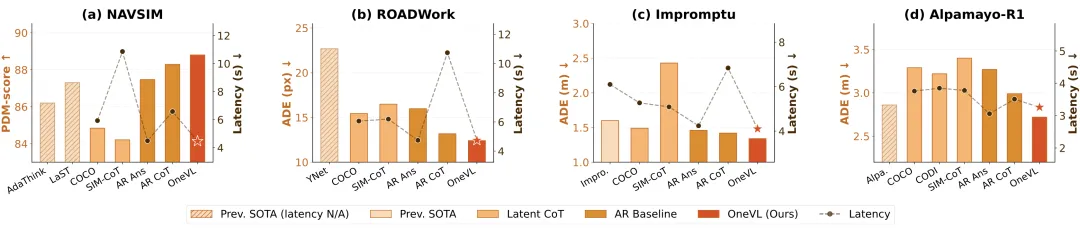
性能有多炸?
在四个主流自动驾驶基准测试上,OneVL 全面刷新了潜空间推理方法的性能上限:
注意看第一行:4B参数的OneVL,性能超过了8B参数的前SOTA。参数量只有一半,精度还更高。
更关键的是延迟数据:
OneVL 的推理速度和"只给答案"几乎一样快,比显式推理快了32%。MLP变体甚至做到了 0.24秒(4.16Hz),完全满足实时部署需求。
小米为什么要开源?
这个问题值得深想。
小米造车已经不是新闻了。YU7 新款即将交付,小米汽车正在从"产品发布"转向"规模化量产"。在自动驾驶技术上,小米一直在闷声干活。
这次开源 OneVL,有几个信号值得关注:
1. 技术自信
敢开源,说明小米不怕别人看。代码、权重、训练方案全放出来,接受学术界和工业界的检验。这在国内车企中不多见。
2. 抢占标准
VLA和世界模型统一框架,这是一个新的技术范式。小米率先开源,就是在争取让自己的方案成为事实标准。就像Meta开源LLaMA改变了大模型生态一样。
3. 人才吸引
开源是最好的招聘广告。顶级研究者看到高质量的开源项目,自然会对小米的自动驾驶团队产生兴趣。
4. 生态布局
自动驾驶不是一家公司能搞定的事。开源可以吸引更多开发者基于OneVL做二次开发,形成围绕小米技术栈的生态。
对行业意味着什么?
OneVL 的出现,可能会改变自动驾驶技术路线的竞争格局。
过去,VLA和世界模型是两个阵营,各有拥趸。OneVL 证明了两者可以统一,而且统一后的效果比任何一条单独路线都好。
这对其他玩家——华为、蔚来、小鹏、百度Apollo——都是一个压力。如果OneVL的开源方案被广泛验证有效,跟进统一框架可能成为行业趋势。
当然,学术基准和真实路况之间还有巨大的鸿沟。OneVL在四个基准上表现优异,但真正的考验是上路——城市拥堵、极端天气、突发状况,这些场景的复杂度远超任何benchmark。
写在最后
小米这次开源OneVL,技术含量确实够硬。4B干翻8B、潜空间推理首次超越显式CoT、双解码器统一VLA和世界模型——每一项拿出来都是顶会论文级别的工作。
更让人意外的是,这些工作来自小米。在很多人的印象里,小米是"性价比手机"和"智能家居"的代名词。但OneVL的发布说明,小米在AI和自动驾驶领域的技术深度,可能被严重低估了。
接下来就看两件事:一是学术界对OneVL的复现和验证,二是小米汽车什么时候把这项技术真正装上车。
你怎么看小米开源OneVL?自动驾驶技术路线会因此改变吗?评论区聊聊 👇


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
