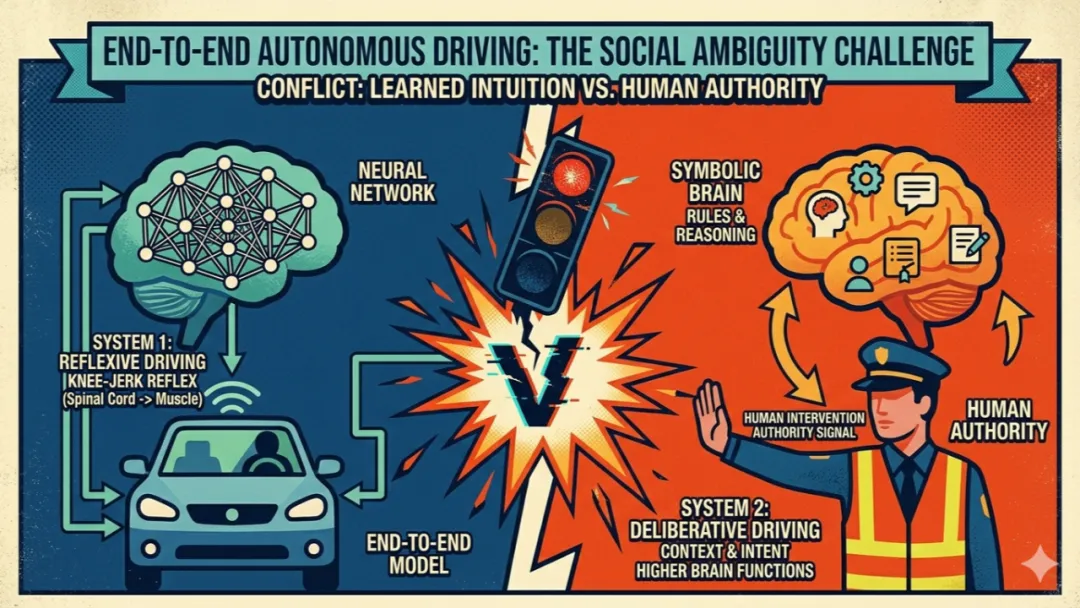
前段时间处理了一个挺有意思的智驾售后案例:客户车在十字路口第一位,交通灯坏了,一直红着不转绿。交警走过去,冲驾驶员摆了向前走的手势。按常理,这时候应该跟着交警走,但智驾还在乖巧地等红灯。后车喇叭按疯了,最后只能自己接管。
客户反馈:“需提升智驾智力水平”。挺扎眼的一句话。系统明明看见了红灯,也看见了交警挥手。问题出在“脑子”里:它不知道该怎么权衡这两个信号。红灯很强,交警也很真,但“交警的优先级高于红灯”这个概念,不在端到端训练出来的直觉里。
膝跳反射
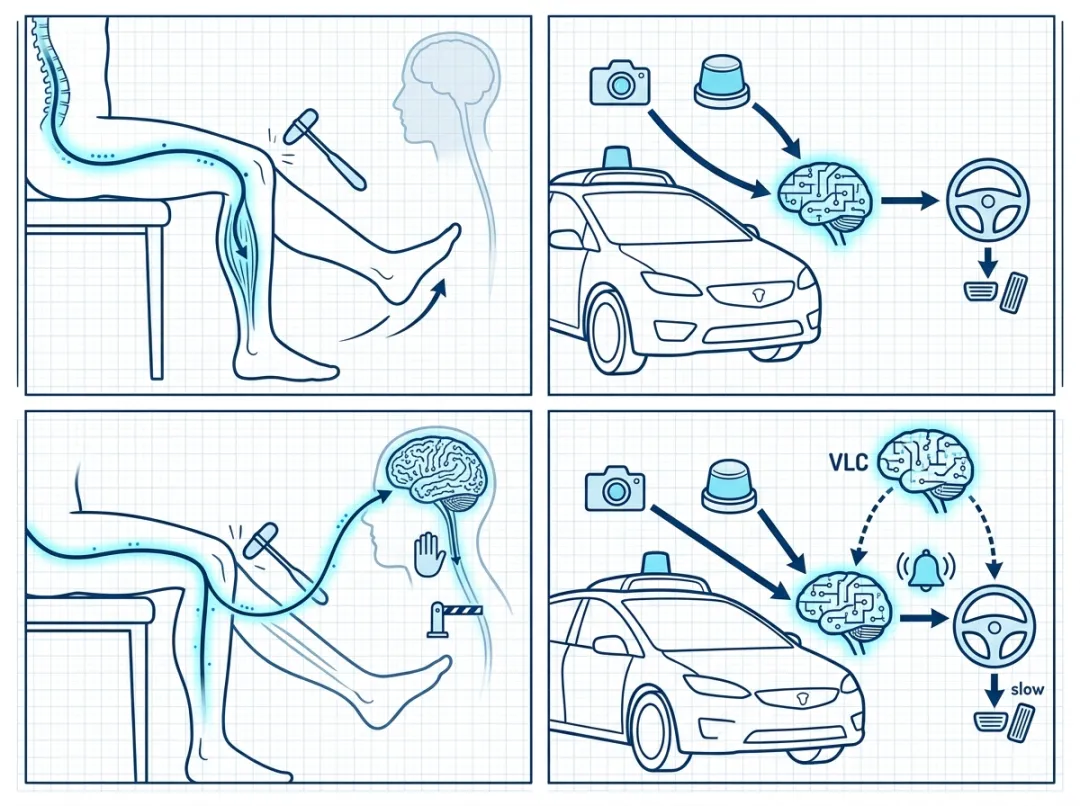
医生拿小锤子敲膝盖,小腿会不自觉地弹起来。这个过程中,信号根本没经过大脑,走的是脊髓反射弧。从感知到动作,极快、极稳、极省脑子。人类日常驾驶里绝大部分操作,其实也是这个级别的:前车慢了,你也慢;车道偏了,手自己回正;红灯亮了,脚自己去找刹车。这些都不需要你在心里默念“第一步、第二步”,它们就是直觉。
现在的端到端算法,干的是类似的事。摄像头、激光雷达等环境信息丢进一个大神经网络,网络直接输出期望轨迹,或更直接的方向盘、油门、刹车指令。中间没什么(或很少,取决于架构)人写的规则,没有曾经的“感知-规划-控制”的模块化流水线。这种设计妙在哪?妙在它让模型自己去学“规律”——什么速度下该打多少方向,跟停刹车要提前多久,旁边车辆加塞时该怎么平滑减速。而且这些知识是隐式的,存在神经网络的权重里,反应速度极快。
世界模型更是在给这种直觉打底。它让车不仅能“看到”现在,还能“预测”下一秒会发生什么。前车尾灯亮了,世界模型能预判它是不是要刹停;旁边车道的车开始偏过来,世界模型能估计它是不是要变道。这种对物理规律的深度理解,让自动驾驶系统在常规场景下越来越像人了,甚至某些纯机械操作上比人更稳。
绝大多数的常规驾驶任务,应该交给“膝跳反射”来完成。 端到端+世界模型,是自动驾驶的脊柱和肌肉,没有这个基础,后面什么都谈不上。足够的数据、足够大的模型、足够强的算力,这根“脊柱”就能完成这些常规任务。
当然,这些算法即使擅长物理直觉,也并不是完美无缺的。端到端模型在物理直觉任务上的表现,与技术成熟度有关: 它们可以通过更多数据、更好的世界模型逐步收敛。
但剩下的那些非常规任务呢?也可以靠端到端+世界模型基于补充数据训练完成么?我觉得不一定,因为这是架构能力的问题——纯端到端缺乏一种显式处理规则优先级冲突的机制,这不是靠堆数据就能自然涌现的。因为那一部分的来源不是因为“物理”,而是因为“歧义”。
歧义时刻
自动驾驶不会直接落在“全无人未来城市”里。在很长很长一段时间里,智驾车辆要和人类司机、临时路障、交警、施工队混在一起出现在大街上。路上不是只有标准的红绿灯和清晰的车道线,还有被风吹歪的施工告示牌,还有穿着反光背心的大爷冲你挥手,还有警车闪着灯慢慢引导你靠边。
这些场景有个共同特点:物理上一切都可能是合理的,但规则上充满歧义。
前方明明立着“道路封闭”的牌子,但施工大爷走到车头前,招手示意跟着他走。跟,还是不跟?
高速上,警车从后面追上来,闪着灯、鸣着笛,用车身姿态和喇叭声示意你驶入应急车道停车。让,还是不让?
前方出了事故,前方司机走过来,站在路中央比划着手势指挥你倒车让行。听,还是不听?
这些时刻不涉及“会不会撞车”的物理安全问题。施工大爷没有恶意,警车不会突然变道,事故司机也不会故意误导。真正的挑战是:听谁的? 静态规则失效了,必须凭对社会惯例、权威层级、现场意图的理解,临时做出一个“对”的决策。
其实,通过添加输入消除歧义这件事,智驾已经有了一些实践 - "导航地图"。十字路口前,如果没有导航输入,系统不知道用户的目标是哪里。地图会明确告诉它:走最右侧车道,右转。这本质上就是一个巨大的语义化约束,消除了几何歧义,让系统能按用户期望执行。问题是,导航只能解决“预先规划好的歧义”。当遇到交警临时指挥、施工队改道时,就需要一个更通用的语义层来实时生成类似的约束指令。
纯靠数据训练出来的“膝跳反射”,在这里会卡壳。因为它缺少的不是感知能力,而是处理歧义的那根神经。
大脑与脊髓
缺少的“神经”是什么?
心理学家丹尼尔·卡尼曼在《思考,快与慢》里提出的System 1(快思考)和System 2(慢思考),描述的是一种双层结构。System 1负责本能反应,System 2负责复杂推理。人类驾驶完美符合这个模型:绝大多数驾驶场景是System 1在开车,只有少数的歧义时刻System 2才会被唤醒。
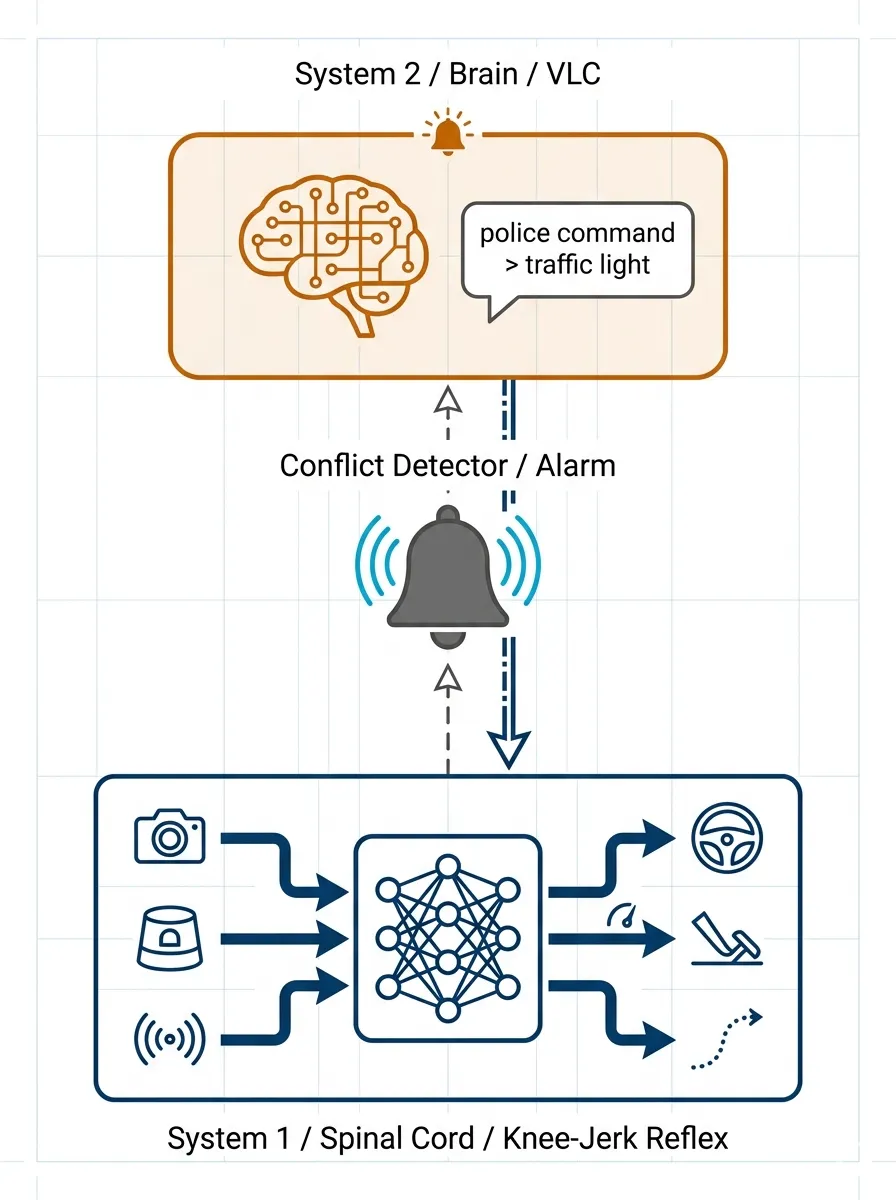
顺着这个思路,最近几年提出的VLA(Vision-Language-Action)模型,就是在试图构建自动驾驶的System 2。但这里的VLA与我的构想有些不同:我构想中的上层系统,不应再叫VLA——因为它并不直接输出Action(油门、刹车、方向盘)。它更像是一个VLC(Vision-Language-Constraint)系统,或者说是一个语义约束层。它的目标是处理歧义场景,输出的是高层约束条件:可通行区域怎么变、谁的路权优先、当前应该遵守什么社会惯例。真正的Action,仍然由System 1(端到端直觉系统)来生成。
总的来说:
下层是“脊髓”——端到端世界模型,负责那绝大多数的常规驾驶任务。它不需要思考,只负责快速、流畅地执行。红灯停、绿灯行、前车慢了就跟着减速,这些全是“膝跳反射”。
上层是“大脑”——一个视觉-语言-约束(VLC)系统,只在歧义场景中被唤醒。它向下层输出一个高层意图或约束条件。比如在交警挥手的场景里,VLC的输出不是“左转10度、油门20%”,而是“当前路口的交警指令优先级高于红灯,车辆应在确保安全的前提下低速通过路口”。下层的世界模型接到这个指令后,像平时一样调用自己的物理直觉,去计算具体的轨迹和车速。
为什么必须这样分工?因为这两层解决的是完全不同的问题。
世界模型的专长是物理:预测轨迹、估计摩擦系数、判断碰撞概率。它的训练数据是海量的道路驾驶数据(或基于世界模型生成的仿真数据),它的目标是让车辆在几何空间里安全地移动。
VLC的专长是社会语义:交警和保安的区别是什么、施工手势和路人挥手的权重怎么排、“让行救护车”在什么情况下可以压实线。它的训练基础是人类社会的语言、规则和文化共识。
如果把这两层混在一起,或者让V-L直接控车(也就是VLA),会出现一个危险的目标耦合问题。想象一个场景:警车开道,需要对向车道的车辆紧急避让。如果大脑直接输出“向左变道”这个抽象目标,但下层模型没有能力在当前车流密度下安全执行,那系统就会卡死或者硬闯。反之,如果VLC只负责重新定义“可通行区域的边界”——比如“当前允许临时借用对向车道,但需保持30km/h以下”——那么下层模型依然需要调用自己的全部物理能力去求解具体路径。VLC定规则,世界模型定执行,才是稳定的分层。
这种快慢分层的思路,在产业界也不是孤例。华为之前提出的WeVA架构,就是让轻量化的快系统处理常规帧,复杂场景再唤醒更重的模型。还有像DriveVLM这样的探索,让VLM做场景理解、端到端做轨迹执行,本质上已经可以被视为 VLC 教师的一种雏形。这些方案和本文的方向在理念上同构,但边界划分不同:DriveVLM更偏向“并联双系统”,而本文主张的是“按需唤醒”——VLC只在直觉系统检测到不可调和的冲突时才被叫醒,而不是每一帧都并行运行。
那“大脑”什么时候该被叫醒?不是简单的“没见过的东西”。一只鸵鸟跑上高速,视觉特征足够怪异,现有的检测器就能发现。真正的麻烦是那些见过、但此刻含义变了的东西——比如穿着制服的交警站在红灯路口挥手。这属于分布内但语义反常的场景。
更合理的触发机制,应该是多模态冲突检测。具体来说,直觉模型在输出轨迹的同时,还带有一个轻量级的“场景语义摘要”:当前交通灯状态是什么、路边有哪些关键参与者、它们各自的角色估计。当这些语义标签和实际要执行的行为出现逻辑冲突时——比如“红灯=停”和“向红灯方向移动”同时成立——系统就应该判定这里出现了不可调和的歧义,唤醒VLC来做二次确认。
这类似于Sutton在强化学习中提出的Options框架,本质上就是“高层策略调用低层子策略”——高层决定“做什么”(What),低层决定“怎么做”(How)。VLC与直觉系统的分工,正是这种思想在自动驾驶里的映射:VLC负责输出约束场(重新定义可行域),直觉系统负责在物理空间里把它执行出来。
需要再次强调的是,这些歧义场景大多不是“会不会撞车”的纯安全问题。施工大爷、交警、事故司机通常都不会主动制造物理危险。它们是“听谁的”的问题,是社会规则的重叠与冲突。 没有VLC这层“大脑”,车辆就会像一个眼睛明亮但常识匮乏的新手,在需要灵活应变的时刻呆立原地。
新手到老手
有了双层架构,接下来的问题是:这套系统该怎么训练?这还是一个尚未解决的开放问题。
人类学开车的过程其实给了一个很好的参考答案。新手司机第一次上路,脑子里全是步骤:看到红灯,先想“红灯要停”;再找停止线;再判断刹车力度;最后才踩下去。这就是一个带语义链条的长程思考过程,本质上和VLC的工作方式一模一样。
但开了十年车的老司机不一样。同样是红灯,身体已经完成了“膝跳反射”,脚自动去踩刹车,中间的语言化步骤被压缩掉了。那些曾经需要默念“红灯→停→找线→刹车”的复杂链条,经过无数次重复,变成了神经网络里的一条直接通路。
自动驾驶的训练也可以走这条“先语言、后压缩”的路径。
这一点似乎正中《The Bitter Lesson》批评的靶心——总以为模仿人类的认知方式是更优的AI路径。但需要澄清的是,借鉴人类认知,不等于盲目复制人类大脑。“利用人类手工设计的特征最终会输给利用算力的通用方法”,这一点完全认同。但我想指出的是另一个维度:当数据获取成本极高、分布外泛化是硬性要求时,语言作为一种“结构化先验”,可以像CNN借鉴视觉皮层的局部连接一样,被用来提升样本效率。我们不是在让AI像人类一样“默念步骤”,而是在利用语言的结构化能力,先教会模型规则约束下的因果链条,再通过蒸馏把这些知识高效地迁移给直觉系统。
具体怎么做?训练初期,对于那些复杂或歧义场景,不要直接给模型一堆“视频-动作”配对让它自己去猜。而是先引入一个VLC教师,让它在这些场景下显式地写出思考步骤。比如:
- VLC输出2:根据交通规则,现场交警指令优先级高于信号灯
- VLC输出3:在确保无行人横穿的前提下,低速驶离停止线
这些训练数据可以来自人类的语言标注(V-人类L-C,Vision-HumanLanguage-Constraint),也可以来自机器生成的更高密度语言(V-机器L-C,Vision-MachineLanguage-Constraint),甚至可以把人类口语化的思考步骤精简成机器更高效的隐式语义表征。核心目标只有一个:让模型先“懂事”——知道在这个社会里该怎么开车——然后再把这份“懂事”练成肌肉记忆。
这种“压缩”不是一蹴而就的。一个能力是否被成功内化到直觉系统里,需要经过严格的验证。可以用物理因果不变性测试来判定:在世界模型或高保真仿真中,固定语义构型但系统性地改变底层物理参数(光照、天气、路面摩擦、相对速度)。如果直觉模型在所有变体下都能保持符合物理规律的稳定输出,并且结合对抗性样本(如保安挥手、路人挥手)做并行验证,确保压缩没有丢失安全关键的上下文,这个能力才算真正被压缩成功。否则,它就应该继续留在VLC的管辖范围内,而不是盲目下放到黑盒直觉里。
训练也不可能一劳永逸。白天行驶时,VLC通过高层意图对直觉系统进行个案抑制和临时指导,确保当前场景安全。晚上,那些触发过VLC的典型案例被加密回传到B端,经过聚类和因果分析后,识别出哪些是“可以压缩的直觉缺陷”,哪些是必须保留的“语义歧义”。对于可压缩的部分,通过轻量级的参数更新修正直觉模型的权重,验证后统一OTA。这有点像人类睡眠中的记忆巩固——白天的慢思考经验,在夜间被选择性地整合进低级反射网络里。
理解了这套训练逻辑,也就自然理解了L3和L4之间真正的分水岭。
L3的核心诉求是“安全地把人从A点送到B点”。高速巡航、结构化道路、跟车变道——这些几乎都是物理直觉能覆盖的范畴。歧义场景极少,驾驶员随时准备接管。所以,一个足够强大的端到端世界模型,确实有可能支撑L3的落地。
但L4不一样。L4意味着车辆要在真实的城市肌理里自主穿行,而真实城市里充满了新旧科技的混合:智慧路口还没全覆盖,人类交警还在指挥,施工队随时会封掉半条路。这些临时性歧义不是bug,而是常态。一个没有VLC语义层的纯端到端系统,可以在大部分时间里开得流畅自如,但会在那少数的歧义路口前茫然停住,把交通堵得水泄不通。
所以结论很清晰:纯粹的“膝跳反射”可以抵达L3,但进不了L4的城市核心。想从L3跨到L4,必须多长一层“大脑”。
歧义才是常态
那个售后工单上的红灯与交警,并不是某个偏远角落的偶发故障。它是一面镜子,照出了自动驾驶未来很多年都要面对的真实路况。
自动驾驶的落地,不会是一夜切换进“未来城市”。在很长一段时间里(甚至永远),自动驾驶都要跑在一个因人类社会运转而产生的无法被提前编码的临时调度的世界里。
想想这些场景:
学校门口早高峰,明明立着“禁止停车”的牌子,但几位家长临时靠边放下孩子,把双向车道硬生生挤成了单行道。智驾系统“看到”的是违停车辆占用了合法车道,但本地老司机都知道这时候需要借对向车道低速绕行。跟,还是不跟?
暴雨夜,一个十字路口的红绿灯还在正常工作,但积水已经漫过了斑马线。交警站在没过脚踝的水里,用手势打断信号灯周期,优先放行车流较小的方向。系统“看到”的是绿灯,但“听懂”的应该是手势。停,还是走?
乡间公路上,一队婚车打着双闪,以远低于限速的速度占用对向车道缓缓前行。没有施工标志,没有交警,只有车窗里探出的半个身体和挥动的手臂。让,还是超?
深夜的高速出口,临时设了一个防疫检查点。没有红绿灯,只有几个反光锥和一个举着指挥棒的工作人员,在黑暗中示意车辆驶入一条用雪糕筒临时围出来的蛇形通道。跟,还是不跟?
物理上一切都可能发生,规则上一切都是临时的。 它们不涉及“前面有车,我要不要刹车”这种可以用物理直觉解决的生存问题,而是涉及“在这个具体时刻、这个具体地点,人类社会的临时约定是什么”的认知问题。
纯端到端系统面对这些场景时最痛苦的地方在于:它们不是 OOD(训练分布外)的视觉怪物。婚车、交警、反光锥、积水,每一个元素单独看都在训练数据里出现过无数次。但真正让人头疼的是这些元素以临时组合的方式出现,并构成了一个需要被重新解读的局。
想用数据把它们全部穷举出来?不可能。因为人类社会的临时调度是活的——今天是暴雨疏导,明天是马拉松封路,后天可能是演唱会散场后的临时单行。这个世界不是在按照一套固定的代码运行,而是在不断地打补丁、做例外、灵活协商。
所以,自动驾驶的终局战场之一,在于如何为这些比例不高却决定系统能否落地的常态歧义,长出一根能够处理社会临时规则的神经。 没有这根神经,车辆就会像一个视力极佳但不懂人情世故的新手,在需要灵活应变的时刻一次次地僵在原地。
终局
自动驾驶的终局,不是在等待一座提前建好的全无人未来城市。在那个假想城市里,红绿灯永远不坏,施工永远提前报备,交警永远不需要冲到路中央打手势。那样的城市不存在。真实的情况是,自动驾驶和人类社会的临时规则混在一起跑:这是一个新科技和老习惯混行的过渡期,而过渡期最不缺的就是歧义。 所以,真正的问题不是“要不要端到端”。端到端世界模型提供的是日常驾驶中常规任务的物理直觉,是自动驾驶必不可少的基础。问题是,仅有这一层够不够?
答案取决于目标。如果只需要在结构化道路上安全地把人送到目的地,L3可能可以光靠这根“脊髓”实现。但如果目标是让车辆真正自主地在城市肌理里穿行,面对那些无法被数据穷举的社会临时调度,那它就必须再长一层“大脑”——一个能在歧义时刻被唤醒、理解人类社会规则并给出步骤指导的语义层。
关于训练路径。好的司机不是天生的。新手需要在复杂场景里默念规则,老司机把规则内化成了肌肉记忆。自动驾驶也可以走这条路:先用显式的语义链条让模型“懂事”,再把那些经过严格验证的理解,一点一滴压缩成直觉系统的权重。这是一个渐进的过程,不是一蹴而就的技术奇袭。
从更底层的安全验证角度看,纯端到端+世界模型还有一个常被忽视的障碍:可追责性。如果一个黑盒神经网络在特定路口犯了错,工程师很难知道它为什么错,以及如何保证它下次不再犯。VLC层的存在至少让那些少数的歧义决策有了一个可追溯的语义依据,用VLC+压缩信息的模式去训练端到端模型,至少能让一部分直觉行为具备可回溯性——这在L4的法规准入中,可能与性能指标同等重要。
完成自动驾驶任务,不需要成为全知全能的超人。它只需要像一个好司机一样:平时靠本能开得又快又稳,路子变了、规矩乱了的时候,脑子能转得过来。
组委会联系人|Lilian
微信号|18217555248
邮箱|lilian.wu@artisan-event.com
关注【ArtiAuto 匠歆汽车】,获取最新行业趋势与深度技术洞察。
加入【AutoCS】智能汽车信息安全社群,共同探讨漏洞分析、入侵防护与实战案例,共建端到端协同防御体系。
加入【AutoSEMI】智能汽车半导体社群,与芯片设计、EDA、整车伙伴共同探讨。直面从RISC-V、测试、认证到流片、上车的全链路挑战,协同推动国产芯片落地。
加入【AutoPEPS】智能汽车无钥匙进入社群,与同仁共研共创。攻坚无钥匙进入与数字钥匙融合的硬核挑战,定义下一代智能进入,加速技术量产落地。
来源:(3) 端到端自动驾驶的社会化歧义挑战:习得直觉与人类权威的冲突 | LinkedIn
著作权归原作者所有。部分图文来源网络,如有侵权请联系lilian.wu@artisan-event.com删除。





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
