自动驾驶怎么避开车辆和行人?看懂原理后,买车别只盯着“智驾”两个字
很多人看自动驾驶演示,最容易被一个画面打动:车自己识别行人、自己跟车、自己避开障碍物。可普通消费者真正该关心的,不是它看起来有多聪明,而是它到底靠什么“看见”世界,又在什么情况下可能看不准。
说白了,车不是人。人开车时能靠经验、余光、预判和常识补全很多信息,但车上的系统面对的是摄像头、雷达、算法和数据。它能帮你减轻一部分驾驶负担,但不能替代驾驶员注意力。看懂这个底层逻辑,再去看各家所谓高阶智驾,就不会那么容易被话术带着走。
 动画演示汽车在斑马线前识别行人并停车。
动画演示汽车在斑马线前识别行人并停车。
车最早的“眼睛”,其实就是摄像头
工程师最初的想法很直接:人靠眼睛开车,那车也装“眼睛”。摄像头能看到车道线、红绿灯、行人、车辆、路牌,这一点和人眼很像。
但难点也在这里。人看到一张模糊画面,能靠生活经验判断那大概是一辆车、一个骑车人,或者一个站在路边的行人。可机器看到的只是大量像素点,它一开始并不知道“四个轮子加一个车身”意味着汽车,也不知道一团移动的阴影是不是危险物体。
所以早期的办法很笨,也很有效:给AI看大量标注好的图片。哪张图里有车,哪张图里有人,哪张图里有车道线,都提前告诉它。它就像刷题一样,见得多了,慢慢学会识别。
这一步解决的是“这是什么”。但开车光知道是什么还不够,还得知道它离我多远、速度如何、会不会进入我的行驶路径。
 多张不同车型图片展示AI通过标注学习识别车辆。
多张不同车型图片展示AI通过标注学习识别车辆。
只看见不够,还得知道远近
开车时,距离判断非常关键。前车离你50米和离你5米,处理方式完全不同;行人站在人行道边和已经踏上斑马线,风险也完全不同。
这时候,激光雷达就派上用场了。它的原理可以理解为向外发射激光束,再根据反射回来的时间计算距离。最终,它能把车辆周围扫描成一张点云图,告诉系统哪里有东西、离车有多远。
 激光雷达工作原理图,展示激光束发射和反射时间计算。
激光雷达工作原理图,展示激光束发射和反射时间计算。
但激光雷达也不是万能的。它擅长测距离,却不擅长理解“那到底是什么”。它可能知道前面有一个物体,但这个物体是车、行人、路锥,还是路边某个反光物,就要依赖摄像头和算法继续判断。
所以很多方案会把摄像头和激光雷达结合起来:摄像头负责看清“是什么”,激光雷达负责判断“有多远”。听起来很稳,但真正麻烦的是,多套传感器给出的信息并不总是一致。
 分屏显示真实道路图像和点云图,说明摄像头与激光雷达融合。
分屏显示真实道路图像和点云图,说明摄像头与激光雷达融合。
系统最怕的,不是看不见,而是看法不一致
如果雷达认为前方有障碍物,摄像头却判断那只是影子,系统该听谁的?
这个问题放到真实道路里,并不轻松。车辆高速行驶时,判断慢了可能来不及;判断过于保守,又可能出现没必要的急减速,也就是大家常说的“幽灵刹车”。
这也是消费者看智驾演示时容易忽略的地方。演示视频往往呈现的是系统成功避让的一刻,但真实驾驶环境里,光线、雨雾、积雪、反光、施工路段、临时障碍物、鬼探头、加塞车辆,都会让判断复杂很多。
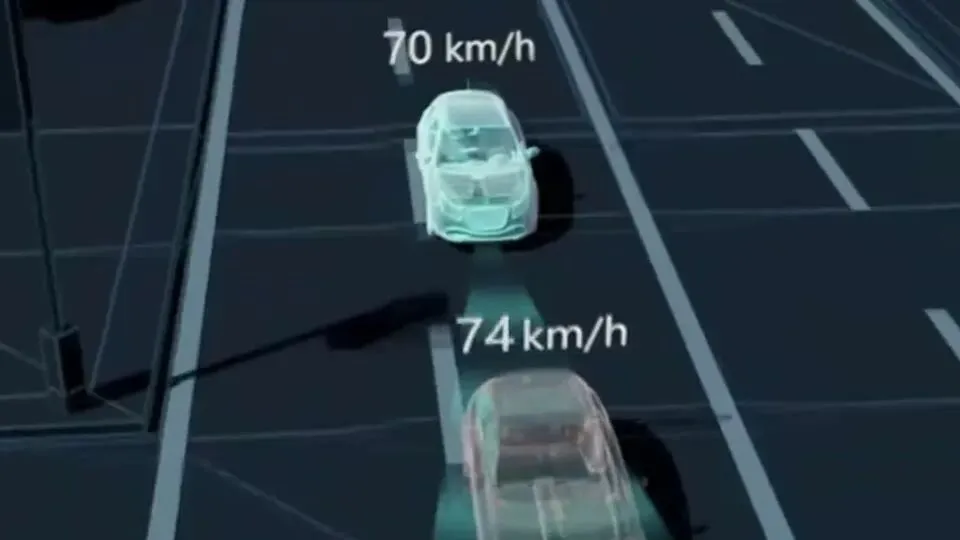 动画演示车辆因雷达和摄像头对障碍物判断不一致而引发幽灵刹车。
动画演示车辆因雷达和摄像头对障碍物判断不一致而引发幽灵刹车。
早期系统还有一个限制:依赖高精地图。高精地图就像提前给车准备了一份详细答案,哪里有车道、哪里有匝道、哪里该变道,都提前写好。它能让系统在熟悉区域表现更稳定,但问题是,一旦离开覆盖范围,能力就容易打折。
这不是说高精地图没有价值,而是它更像辅助工具。普通人买车时要明白,真正决定日常好不好用的,不只是发布会上说支持多少功能,还要看你常跑的道路、城市覆盖情况,以及系统在复杂路况下是否足够稳。
从“背规则”到“理解全局”,智驾才开始变聪明
早期决策系统很像死记硬背。工程师提前写好大量规则:如果前方有车,就减速;如果车道线清晰,就保持车道;如果前车减速,就跟着减速。
这种方式在简单路况下能用,但遇到复杂情况就容易僵。比如有人突然横穿、前车突然加塞、路边车辆开门、施工路段临时改道,靠一条条规则很难覆盖所有可能。
后来,AI模型开始从更大的视角理解道路环境。比如基于transformer发展出的鸟瞰图技术,可以把摄像头、雷达等信息融合成一个类似“上帝视角”的立体沙盘。系统不再只盯着单个画面,而是把周围车辆、车道、行人、障碍物放进同一个空间里理解。
 动画展示车辆将所有信息融合为上帝视角的立体沙盘。
动画展示车辆将所有信息融合为上帝视角的立体沙盘。
再往前一步,是占用网格思路。它不一定非要纠结前方物体到底叫什么,而是先判断某个空间有没有被占用。只要那块空间被占了,车辆就知道不能往那里走。
这个思路对现实道路很有意义。因为路上不只有标准车辆和标准行人,还有倒下的纸箱、施工桶、异形障碍物、动物、临时掉落物。系统未必每次都能准确叫出它的名字,但只要判断那里不能通过,就能降低风险。
动画展示占用网格思路,判断空间格子是否被占用以避让障碍。
端到端大模型听起来高级,但普通人要看使用边界
现在行业里很热的一个方向,是端到端大模型。简单理解,就是不再把每一步都拆成识别、预测、规划、控制,而是让系统学习大量人类驾驶视频,从传感器输入直接生成驾驶动作。
这个方向的吸引力在于,它有机会让系统表现得更自然,不那么像按死规则开车。比如面对加塞、绕行、复杂路口时,理论上可以通过大量数据学到更接近人类的处理方式。
动画演示端到端大模型通过学习人类驾驶视频直接输出驾驶动作。
但消费者不能把“模型更先进”直接理解成“车就能放心自己开”。模型再强,也要看训练数据、传感器能力、算力、系统冗余、道路环境、法规边界和具体车型落地水平。
买车时尤其要警惕一种心理:把智驾功能当成安全兜底。真正正确的理解应该是,辅助驾驶可以在部分场景里减轻驾驶压力,比如长时间跟车、车道保持、拥堵路况辅助,但驾驶员仍然要持续关注道路,随时准备接管。
纯视觉和多传感器融合,争的不是谁更酷
现在行业里大致有两条路线。
一种是纯视觉方案,核心思路是尽量像人一样,主要依靠摄像头和算法理解世界。它的优势是硬件成本相对可控,结构也更简洁。问题是,摄像头天然依赖光线和能见度,遇到强逆光、暴雨、大雾、雪地反光等情况,感知压力会更大。
多视角摄像头画面,展示纯视觉方案如何感知周围环境。
另一种是多传感器融合,摄像头、毫米波雷达、激光雷达等一起工作。它的好处是信息来源更多,某一种传感器受到影响时,其他传感器还有机会补上。代价也很直接:硬件成本、系统复杂度和后期维修成本都可能更高。
所以这个问题不是“纯视觉一定不行”或者“激光雷达一定更好”。真正要看的是系统整体能力,以及车企有没有把硬件、算法和实际场景调得足够稳定。
动画演示车辆通过雷达波检测障碍物,展示多传感器融合方案。
买车时看智驾,别只看宣传页上的功能名
普通消费者选车时,最容易被功能列表带走。高速辅助、城市辅助、自动泊车、智能变道、避障能力,看起来每一项都很诱人。
但真正要问的是:你每天用得上吗?你常跑高速还是市区?你所在城市道路复杂不复杂?你停车位规整吗?你能不能接受系统偶尔判断保守?你愿不愿意学习一套新的车机逻辑?这些问题比功能名字更重要。
如果你买车主要是城市通勤,智驾再强,也不能替你解决所有拥堵、加塞和非机动车混行问题。
如果你经常跑高速,稳定的车道保持、跟车体验、接管提醒和人机交互,反而比炫技功能更关键。
如果你是新手司机,辅助驾驶可以帮忙,但不能让你跳过基本驾驶能力。
这里有一个真实分歧:有的人愿意为更强硬件和更先进算法多花钱,觉得这是未来几年都能用上的价值;有的人更在意机械素质、空间、舒适性和售后,认为智驾不是当前最优先的需求。这两种选择都不丢人,关键是别把别人的兴奋点当成自己的刚需。
真正该保留意见的地方,是“能用”和“好用”之间的距离
自动驾驶技术确实在进步。从摄像头识别,到激光雷达测距;从高精地图,到鸟瞰图和占用网格;从规则系统,到端到端模型,车越来越会理解环境。
但对买车人来说,技术路线不是最终答案。最终答案是:它在你的生活里能不能稳定、自然、低压力地工作。
这也是当下智驾最该谨慎看的地方。发布会展示的是能力上限,日常用车考验的是稳定下限。一个功能偶尔很惊艳,不等于每天都省心;一次成功避让很漂亮,不等于所有复杂路况都能放心交给系统。
所以,自动驾驶相关配置不是不能为它花钱,而是要把边界想清楚。它更适合经常长途通勤、愿意学习系统逻辑、对智能化接受度高、且能理性看待接管责任的人。
如果你只是想买一台省心家用车,智驾可以加分,但别让它盖过空间、舒适性、补能或用车成本这些高频问题。
如果你对新技术很感兴趣,可以重点体验它在高速、拥堵、泊车和复杂路口里的表现。
如果你对系统稳定性特别敏感,就别只看宣传视频,最好亲自试用,并关注它的接管提示、识别稳定性、误刹倾向和人机交互是否清楚。
现在买带高阶辅助驾驶的车,不是不能买,而是要带着边界感买。它能帮你,但不能替你负责。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
