欢迎关注,带来最直白清晰的自动驾驶前沿研究!
一颗球突然从路边滚到车前。
普通的自动驾驶系统可能会识别到“球”,然后避让。但真正让人类司机紧张的,往往不是球本身,而是一个更危险的可能:后面会不会跟着一个追球的孩子?
自动驾驶真正难的,不只是看见眼前发生了什么,还要想到下一秒可能发生什么。
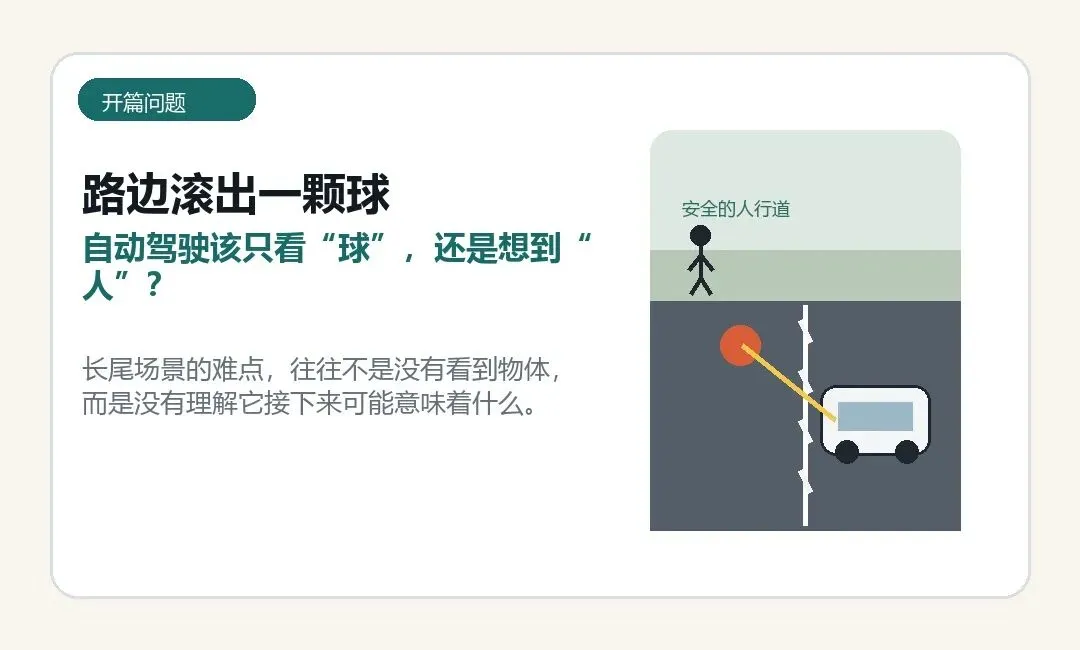
图注:长尾场景的难点,常常不是没有看到物体,而是没有理解它接下来可能意味着什么。
▍问题不是没有看到,而是没有想到下一步
自动驾驶在规则清晰、数据充足的道路上,已经能表现得相当熟练。
可一旦进入开放环境,麻烦就来了。
训练数据里出现过的车道线、车辆和行人,系统可以学得很好;但现实道路总会冒出一些低频、意外、难以穷举的情况。球滚出来、施工区域临时变化、遮挡后突然出现行人,这些都属于自动驾驶最头疼的长尾场景,也常被称为 corner case。
这类问题不能只靠“见过更多图片”来解决。系统还需要把环境线索连起来,判断风险,并在发现原计划不够稳妥时重新规划。
▍CogniDrive 的核心:普通路况快开,复杂场景多想一步
2026 年 4 月,来自北京科技大学和清华大学的研究团队在 Nature Communications 发表论文 Autonomous driving system based on dual process theory and deliberate practice theory,提出了一个名为 CogniDrive 的自动驾驶框架。
它借用了认知科学里的“双系统理论”。
人做决定时,常常有两种状态:一种快、直觉化,适合处理熟悉问题;另一种慢、审慎,适合面对复杂和陌生情况。
CogniDrive 也把驾驶决策拆成了两套模式:
InstinctNav 负责快速、直觉式的轨迹规划。
ReflectPlan 负责在复杂场景中反思、评估并修正计划。
这篇论文最值得记住的,不是“让自动驾驶一直想得更久”。
而是让它知道:什么时候应该快速反应,什么时候必须停下来多想一步。
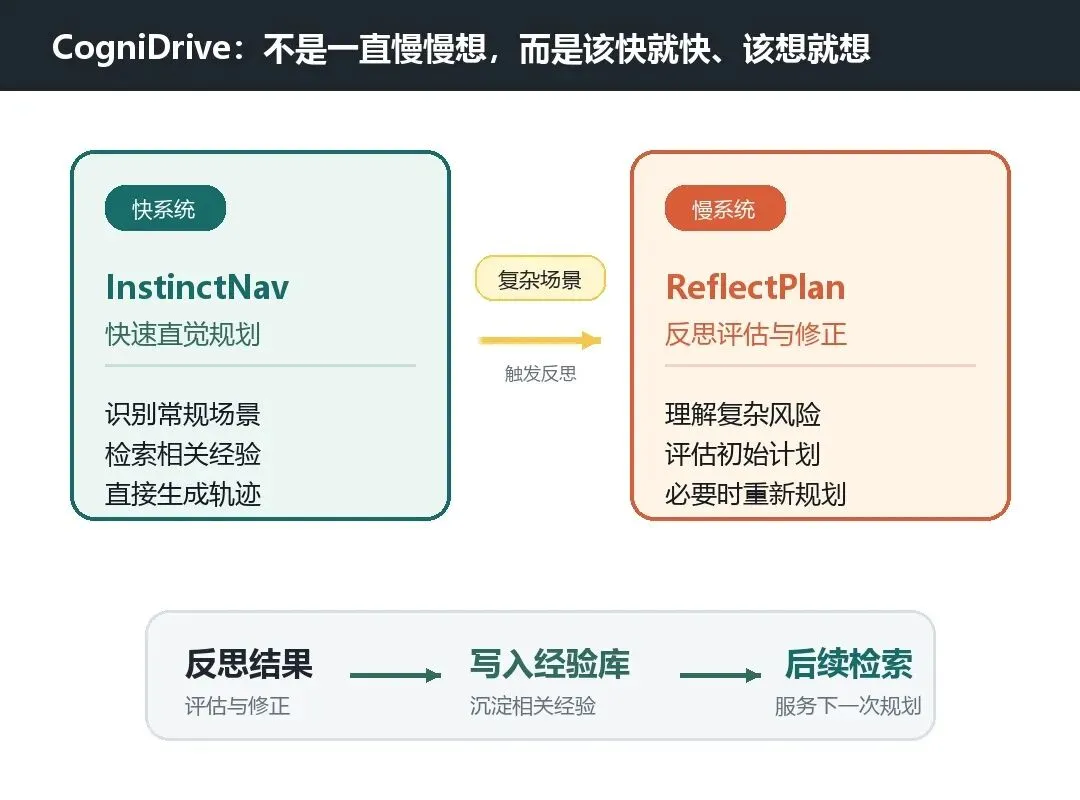
图注:CogniDrive 用 InstinctNav 处理常规规划,用 ReflectPlan 处理需要更深推理的复杂场景,并将反思结果转化为后续可利用的经验。
▍快系统 InstinctNav:先把车开起来
如果每一次驾驶决策都调用复杂推理,系统会变得迟缓,计算成本也会迅速上升。
所以 CogniDrive 的第一层仍然追求快。
InstinctNav 结合行为克隆和检索增强生成,从已有驾驶数据和相关经验中快速给出轨迹。你可以把它理解成一位熟练司机的“肌肉记忆”:熟悉路况不需要逐条分析,先凭经验做出合理动作。
但快系统有天然边界。
当场景超出训练数据分布,或者某个线索背后藏着更复杂的风险时,只靠直觉就可能不够。
▍慢系统 ReflectPlan:发现不对,就重新评估
ReflectPlan 更像一位坐在副驾驶上的审慎检查者。
它会评估 InstinctNav 给出的初始计划,并在需要时重新理解环境、判断潜在危险,再修正轨迹。论文还引入视觉语言模型,帮助系统在复杂场景中把视觉线索和语义风险联系起来。
回到开头那颗球。
快系统看到的是“前方出现障碍物”;慢系统要进一步想到“球后面可能有人”,于是减速、扩大安全余量,或者重新规划。
论文的 Fig. 1 给出了一个更具体的道路场景案例。
左侧是普通场景:InstinctNav 给出初始轨迹后,Critic、Evaluator 和 Replan 都显示为 None,系统没有触发额外反思。
右侧是 CODA 长尾场景:道路右侧出现施工材料和轮椅使用者。初始规划仍然是保持恒定速度向前行驶,但 ReflectPlan 的评估器随后指出右侧需要保留更多驾驶空间,建议车辆向左保持偏移,并重新生成轨迹。

图注:论文 Fig. 1 原图。左侧普通场景没有触发额外评估或重规划;右侧 CODA 长尾场景触发了 ReflectPlan 的评估与轨迹重规划。图像从论文 PDF 的图页中分离,未拆分图内面板、未改绘、未添加标注。
这并不意味着 CogniDrive 已经保证车辆不会再犯同样的错误。更准确地说,研究者给了自动驾驶一种“先做、再评、必要时重做”的机制。
▍最关键的一点:反思结果要变成下一次的经验
只会当场纠错,还不算真正的“复盘”。
CogniDrive 还借用了“刻意练习”的思路:反思产生的奖励信号会被转成语言 token,并与经验表示结合,供后续检索和规划使用。
它不是简单记住“这次错了”,而是尽量把错误变成一条可复用的经验:什么场景触发了风险,原计划哪里不够好,下次遇到相似情况应该优先注意什么。
这也是标题里“下次别再犯同样的错”的来源。它描述的是框架希望实现的学习方向,而不是对所有真实道路场景的绝对保证。
▍慢系统并不是一直开着
一个很有意思的结果是,ReflectPlan 在普通场景中的激活频率只有 5.32%,而在长尾场景中上升到 36.42%。
这说明研究者没有让复杂推理占据每一次驾驶决策,而是让它更集中地出现在真正困难的场景里。
换句话说,CogniDrive 追求的不是“越想越多越好”,而是“该想的时候再想”。

图注:ReflectPlan 在长尾场景中更常触发,说明复杂推理被选择性地用于更困难的环境。
▍结果数字怎么读?
论文在 nuScenes、Waymo、CODA 和 CARLA 等数据集或仿真环境中进行了开放环和闭环评测。
在开放环评测中,相比此前方法,CogniDrive 在 nuScenes 和 Waymo 上的碰撞率分别取得 21.43% 和 13.33% 的相对改进;轨迹 jerk 分别降低 5.75% 和 4.99%,能耗相关指标分别减少 2824.8 J 和 2943.27 J。
在 CODA 长尾场景评测中,论文报告的最低平均碰撞率为 2.05%。
在 CARLA 闭环测试中,CogniDrive 的路线完成成功率为 27.37%,相较此前方法取得 10.54% 的相对提升。
少样本结果也很值得注意:在平均碰撞率上,CogniDrive 仅使用 10% 训练数据就超过了使用 100% 数据的基线;在 L2 轨迹误差上,只使用 5% 训练样本就超过了基线。
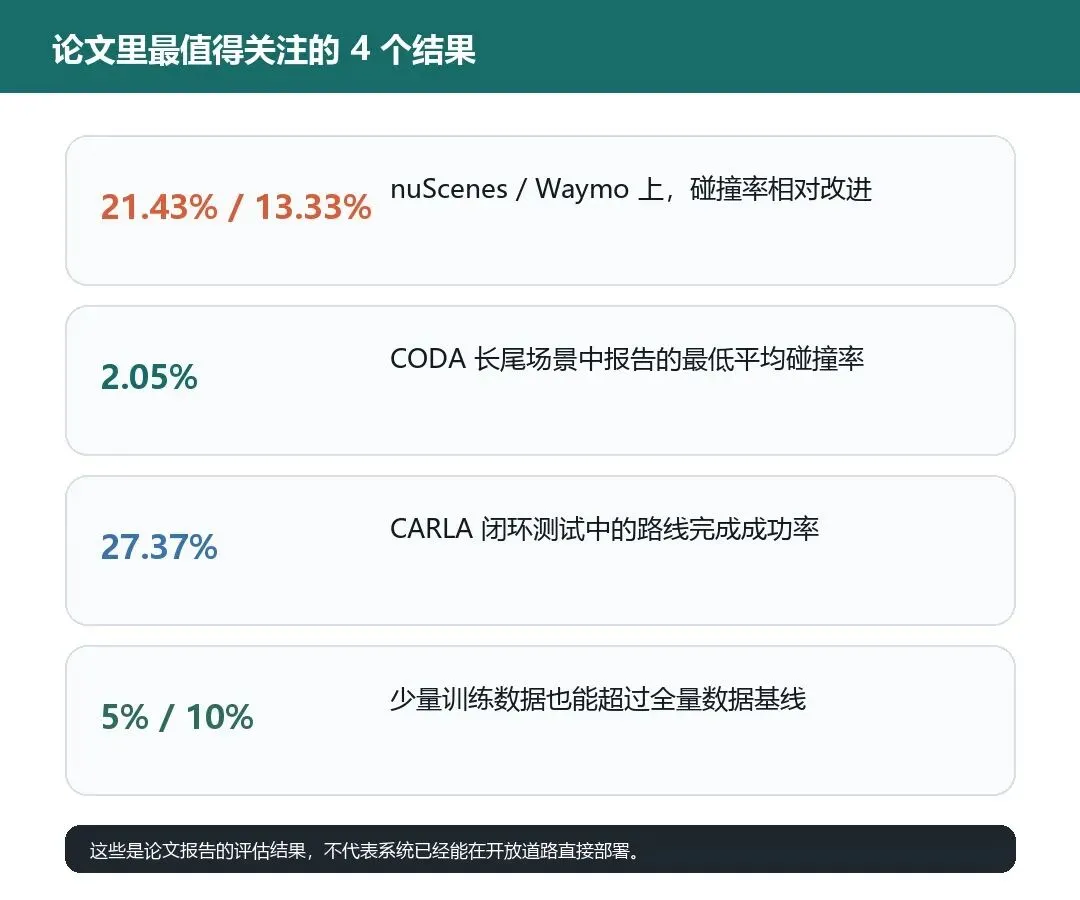
图注:这些数字来自论文报告的评测结果。它们说明框架在既定数据集和仿真环境中表现更好,但不等于系统已经可以直接在开放道路部署。
论文的 Fig. 3 展示了少样本泛化的原始结果。图 a 对应平均碰撞率,图 b 对应 L2 轨迹误差,虚线是使用 100% 训练样本的 ST-P3 基线;图 c 则显示随着训练样本增加,无效输出数量快速下降。
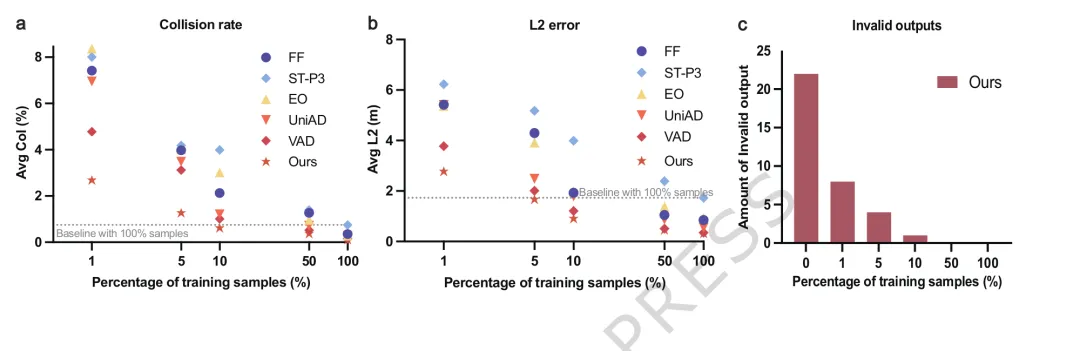
图注:论文 Fig. 3 原图。CogniDrive 在平均碰撞率上使用 10% 训练数据超过全量数据基线,在 L2 误差上使用 5% 训练样本超过基线。图像从论文 PDF 的图页中分离,未拆分图内面板、未改绘、未添加标注。
▍为什么“经验越多越好”是个陷阱
复盘系统还有一个容易被忽略的问题:经验库不是越大越好。
论文的消融实验显示,检索 1 条相关经验时,平均碰撞率最低,为 0.11%。当提示词里塞入更多低相关经验,模型的困惑度上升,不确定性也会增加,推理准确性反而可能下降。
这很像人类做题。
真正有帮助的,不是把所有笔记都摊在桌上,而是快速找到最接近当前问题的那一次经验。

图注:论文提示,经验检索的关键是相关性,而不是数量。该结论来自论文中的特定消融设置。
▍这篇论文真正值得看的地方
过去很多自动驾驶评测,重点集中在轨迹误差和碰撞率。
CogniDrive 进一步把舒适性和能耗纳入评估。因为一条“没有撞车”的轨迹,也可能急刹、急转、让乘客不舒服,或者消耗更多能量。
更重要的是,这篇论文把一个常被拆开的矛盾放到了一起:
自动驾驶既要反应快,又要在危险时刻想得深;既要利用过去经验,又不能被无关经验干扰;既要追求安全,也要考虑舒适和能耗。
它没有把答案简单归结为“模型再大一点”,而是尝试让系统学会分配自己的推理精力。
▍还需要谨慎看待什么
第一,这篇论文目前是 Nature Communications 的 Article in Press 未编辑版本,正式出版前仍可能出现文字或数据呈现上的修订。
第二,论文结果主要来自数据集和 CARLA 仿真评测,不是公开道路上的大规模真实部署证明。
第三,LLM的前向推理延迟仍是现实限制。安全关键系统不能只追求“想得更深”,还必须在足够短的时间内给出可靠决策。
第四,论文也指出,LLM可能继承预训练数据中的偏差,安全关键决策的可靠性、解释性和公平风险分配仍然需要继续研究。
所以最准确的说法是:
CogniDrive 展示了一条有吸引力的路线,让自动驾驶在复杂场景中学会反思和利用经验,但距离开放道路上的可靠部署仍有很长的验证路要走。

▍文末互动
你更信任哪一种自动驾驶?
是“反应很快”的自动驾驶,还是知道什么时候应该慢下来复盘的自动驾驶?
欢迎在评论区聊聊。
论文来源:Zhang, X., Hu, T., Lyu, J. et al. Autonomous driving system based on dual process theory and deliberate practice theory. Nature Communications, 2026.
DOI:https://doi.org/10.1038/s41467-026-72030-6
论文链接:https://www.nature.com/articles/s41467-026-72030-6
代码链接:https://github.com/2351672564/CogniDrive
说明:本文为论文内容的中文转写与科普解读。论文采用 CC BY-NC-ND 4.0 许可。除完整转载的论文 Fig. 1 和 Fig. 3 外,其余正文配图均为基于论文信息制作的中文解释图;两张论文原图均未拆分图内面板、未改绘、未添加标注。封面车辆照片仅作自动驾驶实景示意,不是论文硬件。

