nuReasoning:面向长尾自动驾驶的推理数据集与 Benchmark
作者 | Zhiyu Huang、Johnson Liu、Rui Song、Zewei Zhou 等
机构 | University of California, Los Angeles;Motional
论文标题 | nuReasoning: A Reasoning-Centric Dataset and Benchmark for Long-Tail Autonomous Driving
项目主页 | https://nureasoning.github.io/
前言
端到端自动驾驶近几年发展很快,统一模型直接从传感器输入映射到未来轨迹,省去了传统模块化方案中大量工程堆叠。但在真实道路上,系统最容易出问题的地方往往不是常规直行、跟车或换道,而是施工区、临停车辆、弱势交通参与者、异常标志、紧急车辆等长尾场景。
这些场景对模型提出的要求,不只是识别目标类别和预测运动轨迹。模型还需要理解空间关系、交通语义、行动因果和潜在风险:哪个目标会影响自车?当前动作为什么合理?如果选择另一个动作,会不会带来碰撞或违规风险?
这正是 nuReasoning 试图解决的问题。论文将长尾自动驾驶场景组织成一个推理中心的数据集和 benchmark,不仅评估 VLM 能否回答驾驶推理问题,还进一步观察推理监督是否能改善 VLA 模型的规划性能。
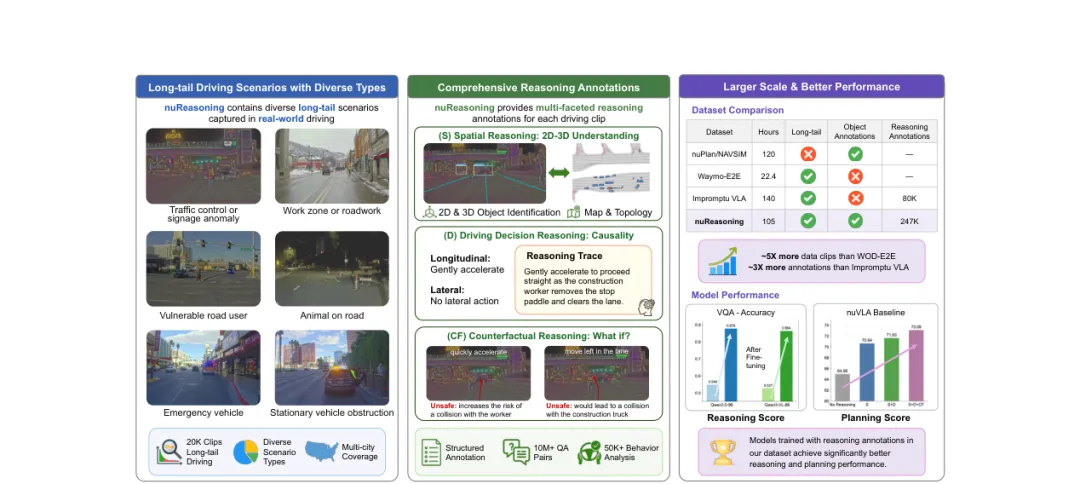
图 1:nuReasoning 是一个大规模真实世界长尾驾驶数据集,包含 20K 个 20 秒驾驶片段,覆盖多种长尾场景类型。数据集提供高质量推理标注,涵盖空间推理、驾驶决策和反事实推理。相比既有数据集,nuReasoning 提供了更大规模的长尾驾驶数据和更丰富的推理标注,使基于该数据集训练的模型能够显著提升推理与规划性能。
研究背景
现有自动驾驶数据集大多围绕感知、预测或规划展开。它们能够告诉模型哪里有车、行人和车道线,未来轨迹应该如何拟合专家驾驶,但对“为什么这样开”以及“如果换一个动作会怎样”提供的监督相对有限。
与此同时,VLM/VLA 开始进入自动驾驶任务。一类方法让 VLM 输出高层意图或驾驶指令,再交给动作模块生成轨迹;另一类方法把 VLM 表征和视觉 backbone 特征融合,再由统一的动作专家解码轨迹。这些方法能够引入语义理解,但如果缺少面向驾驶场景的推理数据,模型仍然很难学到稳定的空间、因果和反事实判断。
nuReasoning 的思路是补上这块数据缺口:不仅构建长尾驾驶片段,还给每个片段配套结构化推理标注,并把 reasoning benchmark 和 planning benchmark 放在同一套数据里。这样,研究者可以同时回答两个问题:VLM 是否真正具备驾驶推理能力?推理监督是否能转化为更好的规划表现?
nuReasoning 数据集:从长尾挖掘到推理标注
nuReasoning 包含 20K 个真实驾驶片段,每个片段约 20 秒,总计约 105 小时,来自 Las Vegas、Pittsburgh、Los Angeles、Boston 等多个城市。每个片段围绕一个决策关键帧组织,包含同步多模态输入、目标标注和局部地图信息。
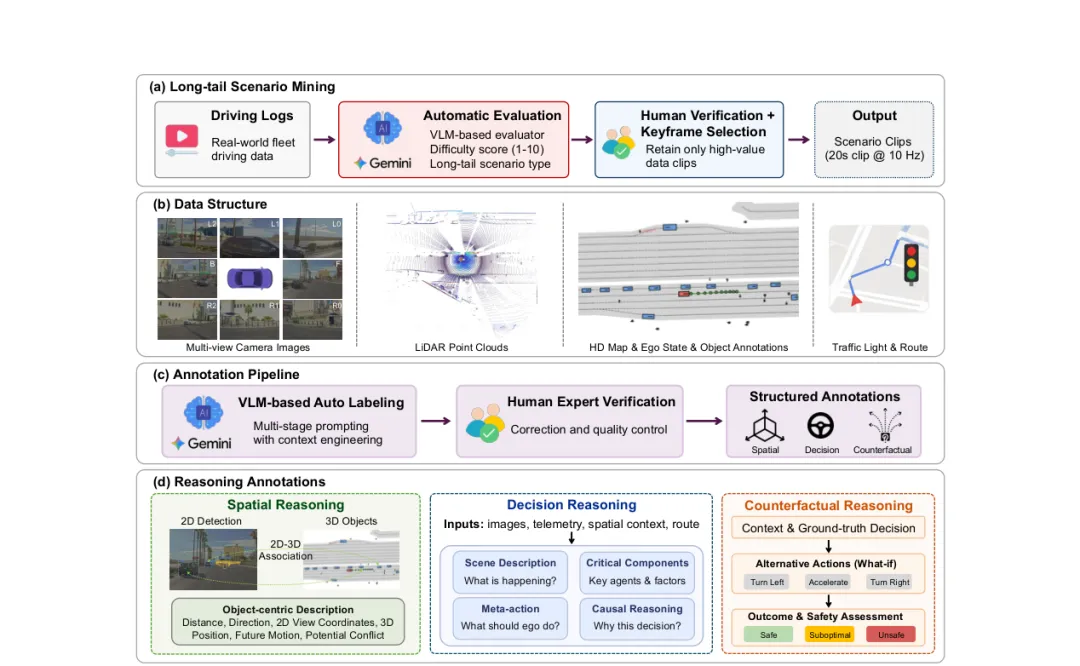
数据构建并不是简单从日志中随机抽样。论文先使用基于 VLM 的评估器对内部车队日志进行场景类型和难度评分,筛选出更有价值的长尾片段,再经过人工验证和关键帧选择。这样做的目的,是让数据集中更多样本落在“需要推理才能处理”的区域,而不是被大量普通驾驶片段稀释。
图 2:长尾数据挖掘与标注流程概览。(a)内部车队驾驶日志先被切分,并由基于 VLM 的评估器对场景类型和难度进行评分,随后经过人工验证和关键帧选择。(b)每个选中的 20 秒片段(10Hz)包含多视角相机图像、LiDAR 点云、高清地图、自车状态、目标标注、交通灯和路线信息。(c)标注流程结合 VLM 自动标注与人工验证/修正,以保证质量。(d)推理标注覆盖空间、决策和反事实维度,支持多类下游任务与推理能力评估。
论文将推理标注拆成三类。
第一类是 Spatial Reasoning,关注目标的 2D/3D 对应关系、车道拓扑、相对位置、运动状态以及潜在交互冲突。它回答的是“场景里有什么、它们在哪里、和自车是什么关系”。
第二类是 Decision Reasoning,关注驾驶决策的因果解释。它不仅标注自车应该采取什么 meta-action,还要求给出为什么需要这样做,例如当前是否应当轻微加速、保持车道、让行或避让。
第三类是 Counterfactual Reasoning,关注替代动作的后果分析。也就是说,数据不仅标注安全动作,还分析如果选择快速加速、向左移动或其他替代动作,会带来什么风险。这类标注对于长尾场景尤其重要,因为真实事故往往发生在“看似也能做,但其实不安全”的动作选择上。
从规模看,在 19K 个带标注片段中,nuReasoning 提供了 247K 个以 1Hz 采样的空间推理帧,以及 57K 个以 0.2Hz 采样的决策/反事实推理帧。论文还通过多类问题格式构建了超过 10M 个 QA 对,并抽样 167K 个用于训练,以平衡覆盖范围和训练效率。
Benchmark:同时考推理和规划
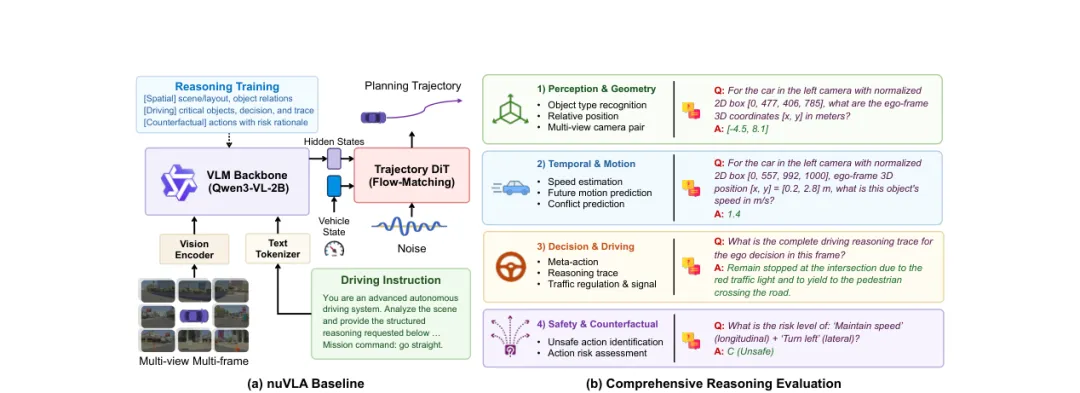
nuReasoning 的关键不只是数据集,而是 benchmark 设计。它把推理能力拆成 Geometry、Motion、Driving、Counterfactual 四类能力,对应几何理解、未来运动估计、驾驶决策和反事实风险评估。
这种设计比普通驾驶 VQA 更贴近自动驾驶系统。因为在真实规划中,模型不仅要知道图像中有什么,还要理解目标在 3D 空间中的位置、未来可能如何运动、当前动作是否合理,以及替代动作是否安全。
图 4:nuVLA 基线与推理评估 benchmark 概览。(a)nuVLA 以多视角、多帧相机图像和驾驶指令作为输入,编码后的隐藏状态输入轨迹 DiT,用于生成未来规划轨迹;VLM backbone 使用不同类型的推理监督进行训练。(b)在推理评估中,benchmark 覆盖 3D 几何理解、未来目标运动估计、决策制定和反事实推理等能力。
论文同时构建了 nuVLA 基线。nuVLA 使用多视角、多帧相机图像和驾驶指令作为输入,VLM backbone 负责学习场景语义和推理监督,轨迹 DiT 则负责生成未来规划轨迹。更重要的是,论文可以控制不同类型推理监督是否参与训练,从而观察空间、决策、反事实推理分别对规划性能的影响。
推理结果:通用 VLM 还不够懂驾驶
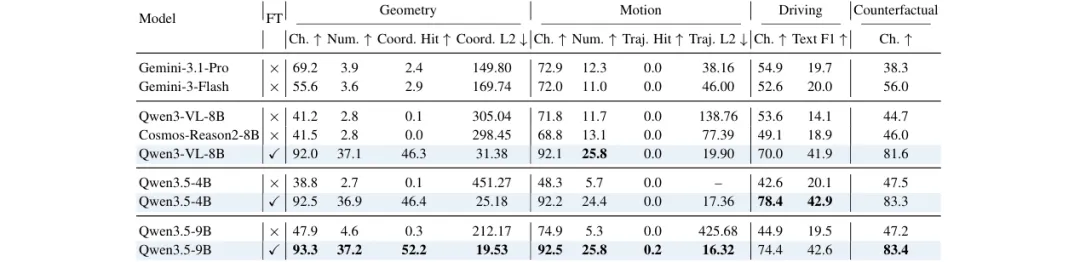
Table 2 的结果说明,通用 VLM 和驾驶专用推理之间仍然存在明显差距。Gemini 系列在部分选择题指标上表现较好,但在结构化 grounding 上仍然较弱:基础模型的几何坐标命中率低于 3%,轨迹命中率几乎为 0。这说明通用预训练能捕捉粗粒度语义,却很难可靠学习多视角驾驶场景中的几何关系和未来运动。
微调后的提升非常明显。以 Qwen3-VL-8B 为例,经过 nuReasoning 微调后,Geometry choice accuracy 从 41.2% 提升到 92.0%,Geometry numerical accuracy 从 2.8% 提升到 37.1%,Driving choice accuracy 从 53.6% 提升到 70.0%,Counterfactual choice accuracy 从 44.7% 提升到 81.6%。Qwen3.5-4B 和 Qwen3.5-9B 也呈现类似趋势,说明这种提升并不只依赖单一模型规模。
但论文也指出,未来运动推理仍然是主要难点。微调可以显著降低 trajectory L2 error,但严格的 trajectory hit 仍然接近 0。相比之下,坐标 grounding 的改善更明显。这意味着当前监督已经能帮助模型学习静态或瞬时空间关系,但对精确未来运动预测仍然不足。
表 2:四类主要能力下的推理结果。指标遵循原始答案格式,列按高层能力类别分组;默认使用多帧视觉输入。FT 表示微调,Ch. 为选择准确率,Num. 为容差内数值准确率,Coord. Hit 和 Traj. Hit 分别为坐标与轨迹命中率,Text F1 为 token 级 F1;所有数值均为百分比。Coord. L2 与 Traj. L2 为任务特定坐标单位下的平均 L2 误差,“—”表示缺失或无法解析的轨迹输出。
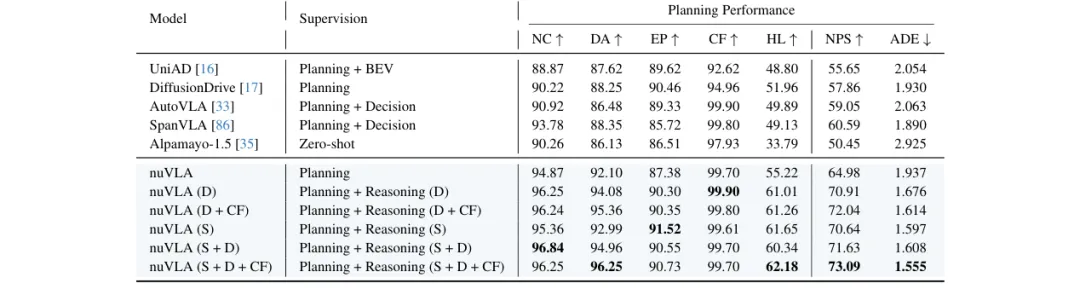
规划结果:推理监督确实影响轨迹规划
更值得关注的是 Table 3。论文不只证明 VLM 微调后更会回答问题,还进一步证明推理监督能够改善 VLA 的规划性能。这个结论比单纯提升 VQA 指标更重要,因为它说明语言推理有可能改变规划模型学到的中间表示。
在 nuReasoning 测试集上,最强的既有 baseline NPS 为 60.59,而只使用 planning supervision 的 nuVLA 可以达到 64.98。加入推理监督后,规划表现进一步提升。Decision reasoning 将 NPS 从 64.98 提升到 70.91,ADE 从 1.937 降到 1.676;Spatial reasoning 将 NPS 提升到 70.64,ADE 降到 1.597;Decision + Counterfactual 进一步将 NPS 提升到 72.04。
最佳结果来自 Spatial + Decision + Counterfactual 的组合,完整 nuVLA 达到 73.09 NPS 和 1.555 ADE,并在多数安全性和行驶进度指标上取得最好或接近最好的表现。这个结果说明三类推理监督是互补的:空间推理强化场景理解,决策推理改善动作选择,反事实推理帮助模型区分安全动作和不安全/次优动作。
更关键的一点是,测试时显式推理文本被关闭。也就是说,模型并不是靠推理阶段输出一段解释来提高分数,而是在训练阶段通过推理标注学到了更好的规划表示。
表 3:nuReasoning 测试集上的规划模型对比。Planning 表示轨迹规划监督;nuVLA 使用不同组成的推理监督:S 为空间推理,D 为决策推理,CF 为反事实推理。
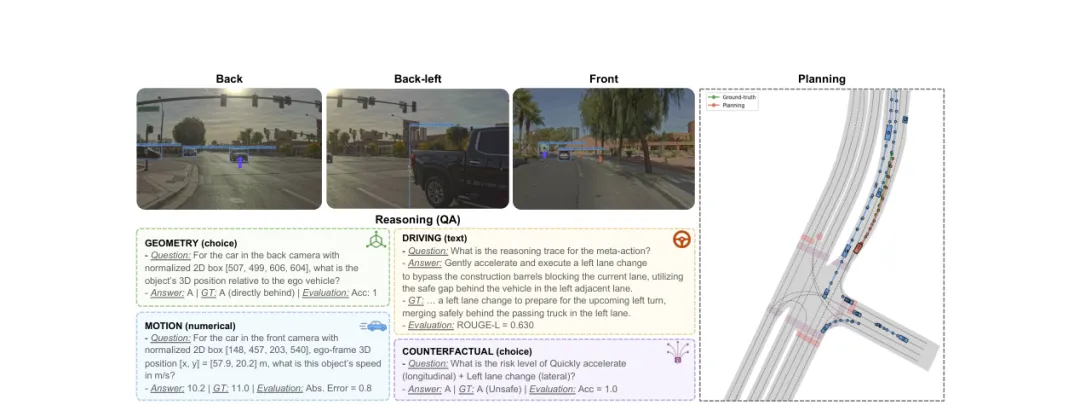
图 5:nuReasoning 测试集上的推理与规划结果示例。推理评估使用微调后的 Qwen3.5-9B 模型,规划评估使用接受全部推理监督类型(S+D+CF)训练的 nuVLA 模型。
结论:自动驾驶数据集的竞争点正在变化
nuReasoning 的贡献可以概括为三点。
第一,它把长尾驾驶场景、结构化推理标注和规划评估放在同一套真实世界数据中。相比只做 VQA 的驾驶语言数据集,这更接近自动驾驶系统真正要解决的问题。
第二,它把推理拆成空间、决策和反事实三类,使“推理能力”不再是笼统概念,而是可以分别训练、评估和消融的监督信号。
第三,实验说明推理监督不只提升问答指标,也能改善规划模型的轨迹表现。尤其是在显式推理输出关闭的情况下,规划性能仍然提升,说明推理标注可能正在改变模型内部表示,而不只是提供可解释性展示。
当然,论文也留下了两个需要继续验证的问题。其一,nuReasoning 来自有限城市和驾驶条件,是否覆盖真实世界所有高风险长尾场景仍有待观察。其二,benchmark 主要是 open-loop evaluation,不能完全代表闭环驾驶中的行为稳定性。
总体来看,nuReasoning 的意义不在于“又多了一个自动驾驶数据集”,而在于它把自动驾驶数据集的竞争点从规模、传感器配置和轨迹标签,推进到风险、因果和决策逻辑的结构化标注。对于 VLM/VLA 进入自动驾驶规划这条路线来说,这是一个值得持续跟踪的方向。