一句话讲清楚👉🏻 博世 Research 提出 BLUE :在冻结 VLA backbone 的前提下,只训练一个 0.11M 参数的 gate ,让模型逐帧判断「此刻要不要生成语言」, Bench2Drive 成功率从 67.27% 拉到 76.18%,推理延迟从 1396.6ms 降到 549.5ms ,实现 2.54 倍加速。
论文标题:BLUE: Toward Better Language Use in Efficient Vision-Language-Action Models for Autonomous Driving
论文链接:https://arxiv.org/abs/2606.08684
Github 链接:https://github.com/George-Ling3/BLUE
项目链接:https://blue-website.github.io/
权重与日志:https://huggingface.co/George-Ling/blue_gate
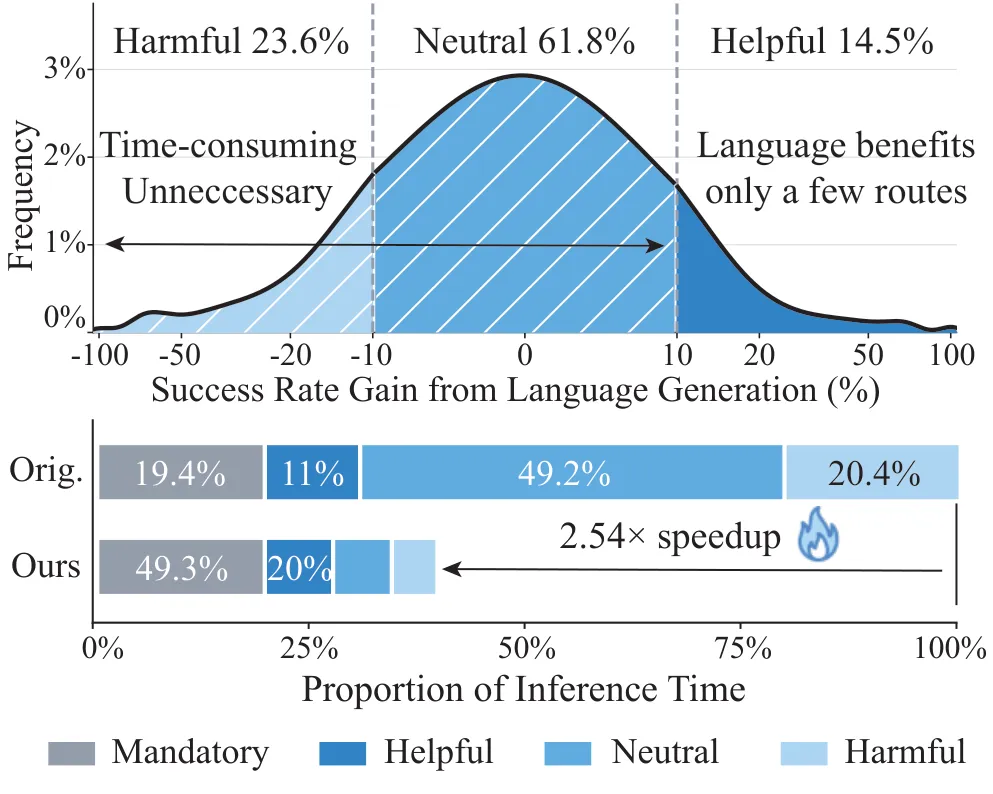
14.5% 的路线靠语言赢, 23.6% 的路线被语言拖垮
自动驾驶 VLA 这几年走了一条很自然的路线:先让模型「说」一段场景推理,再据此输出转向、加速等动作。 SimLingo 、 CriticVLA 、 TakeVLA 等代表性工作,默认每一帧都走这条链路。
博世 Research 团队先问了一个更基础的问题:这些语言,到底在闭环驾驶里帮了多少忙?
他们在 Bench2Drive 上跑了约 2000 A100 GPU hours 的系统分析,把 SimLingo 分别放进「语言模式」和「直接动作模式」,对每条路线做重复实验,再用统计检验归类结果。数字很扎眼:
■14.5% 的路线:语言生成显著提升 驾驶成功率■61.8% 的路线:语言没有可测量影响,却照样付出完整生成成本Bench2Drive 路线按语言影响分布(上),以及 BLUE 相对原始 VLA 的推理时间对比(下)。
更扎眼的是,每帧都走语言链路,却把大量算力花在多数时候帮不上忙、有时甚至帮倒忙 的中间步骤上。 autoregressive 语言生成又是驾驶 VLA 的主要延迟来源——SimLingo 平均 0.72 FPS、单帧延迟 1396.6ms,其中语言生成占了大头。
如果能在需要的时候 才打开语言、其余帧直接出动作,理论上可以同时拿到更好的闭环成绩和更快的推理速度。难点在于:怎么判断「这一帧该不该说」?
场景复杂度猜不准, hidden states 里却藏着信号
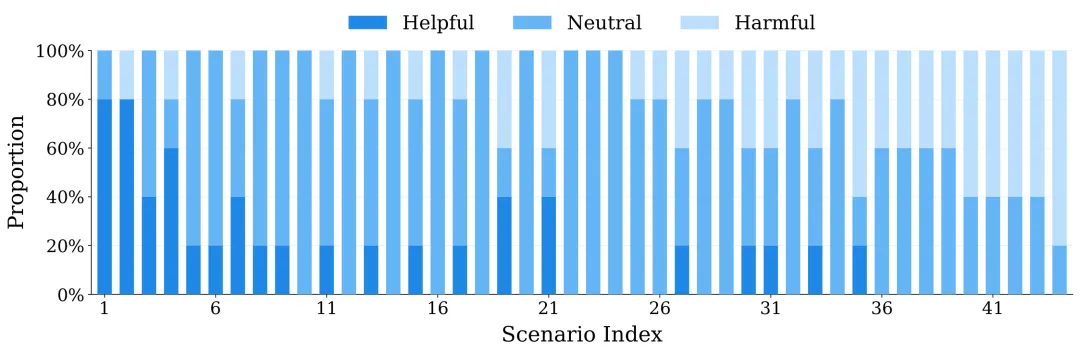
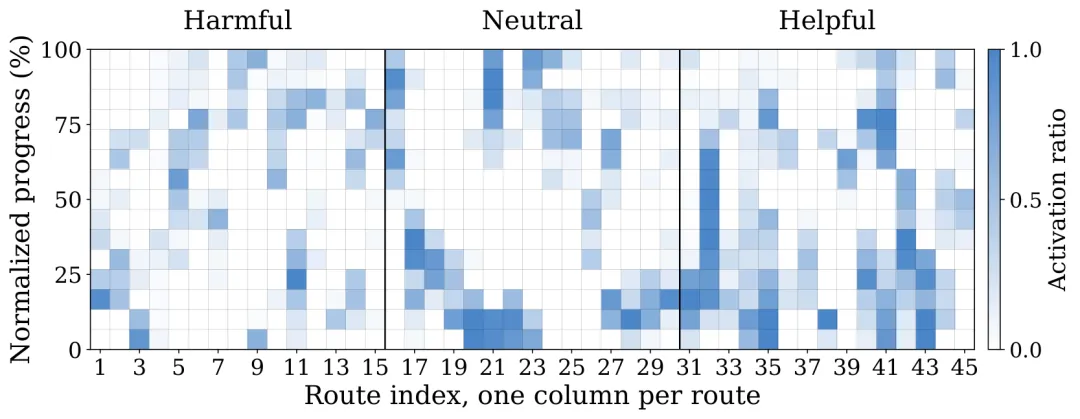
一个直觉猜想是:复杂场景需要语言,简单场景可以跳过。团队把 Bench2Drive 全部 44 类场景 拆开统计,发现语言效应在不同场景间差异极大——有些场景语言帮忙比例高,有些场景反而以「有害」为主,但没有单一复杂度指标能稳定预测语言是否有用。
44 类 Bench2Drive 场景中,语言生成对驾驶成功率的影响分布(有帮助 / 中性 / 有害)。
更有意思的发现来自模型内部:在冻结的 VLA 最后一层 hidden states 上,用简单 logistic regression 就能把「语言有帮助的帧」和「没帮助的帧」分开,不需要 额外引入场景复杂度或车辆运动学特征——效用信号已经编码在表征里了,只是默认每帧全开语言时从未被利用。
团队还构造了一个路线级 oracle :对每条路线,直接选「语言模式」和「直接动作模式」里表现更好的那个。即便这种每路线只做一次选择 的粗粒度 oracle ,成功率也能到 78.4%,比默认 SimLingo 的 67.27% 高出超过 10 个百分点。 oracle 还是保守估计——更细粒度的逐帧选择理论上还能更高。路线级 oracle 已把上限抬到 78.4%,说明轻量 gate 不必动 backbone ,就能挖出被浪费的性能空间。
BLUE 方法: 0.11M gate ,冻结 backbone ,标签来自闭环评测
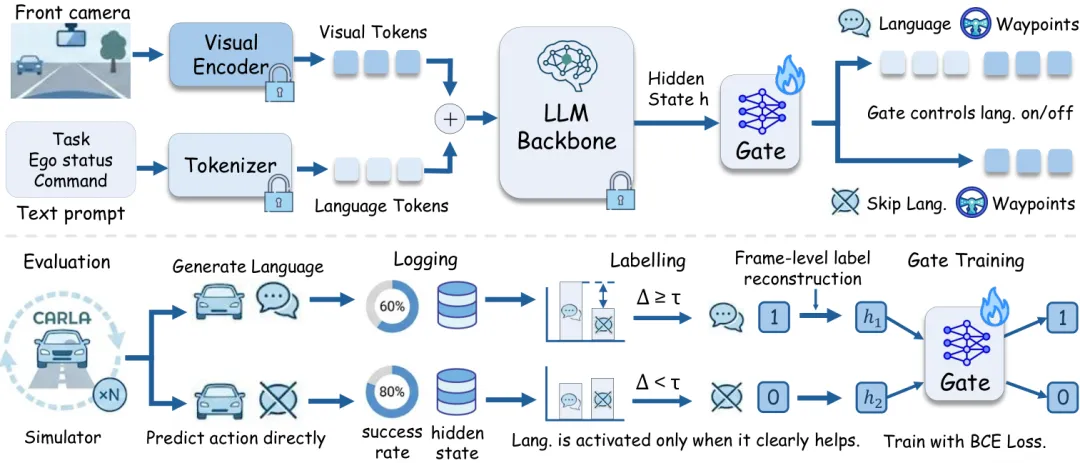
BLUE (B etter L anguage U se in Efficient VLA )的核心设计极其克制:视觉编码器和 LLM backbone 全部冻结,只训练一个单隐藏层 MLP gate ,参数量 0.11M。
BLUE 整体框架: gate 读取冻结 VLA 的 hidden state ,逐帧决定激活语言生成或直接输出 waypoints ;训练标签来自闭环评测结果。
数据收集与标注
训练数据来自 SimLingo 训练集约 400 条路线。对每条路线,分别以「语言模式」和「直接动作模式」跑重复实验,收集每个帧在最终 token 位置的最后一层 hidden state 。这个位置对应语言或 waypoint 生成开始前的表征,两种模式共享,保证特征对齐。
路线级标签根据成功率差距定义:
其中 是随机种子集合, 表示成功率,阈值 。设计逻辑是:默认走更快的直接动作模式,除非语言模式展现出明确优势。
帧级标签在路线级基础上进一步细化。对语言有益的路线(),只标记行为分歧最大的关键区域 :
是路线 跨种子的语言优势均值, 是帧 的空间坐标。训练时混合路线级和帧级样本,让 gate 同时学到「哪些路线偏好语言」和「路线内哪些片段需要语言」。
针对时序冗余(比如停车时连续帧特征几乎相同),团队把余弦相似度 的连续帧分组,每组长度 下采样到 个代表样本,避免 gate 过拟合静止片段。
Gate 设计与推理
Gate 是单隐藏层 MLP (隐藏维度 128 ,带 dropout ),用二元交叉熵训练。推理时,每帧先走两种模式共享的前向过程得到 , gate 输出分数 :超过阈值 则继续语言生成,否则直接输出动作。阈值 ,来自语言效应三类划分(有帮助 / 中性 / 有害)对 gate 输出区间 的三等分边界,无需在测试集上调参。
整套流程不需要额外人工标注,标签完全来自常规闭环驾驶评测——这让 BLUE 更像一个「后装插件」,而不是一次昂贵的大修。
闭环成绩:单前视相机拿下双 benchmark SOTA
Bench2Drive 主结果
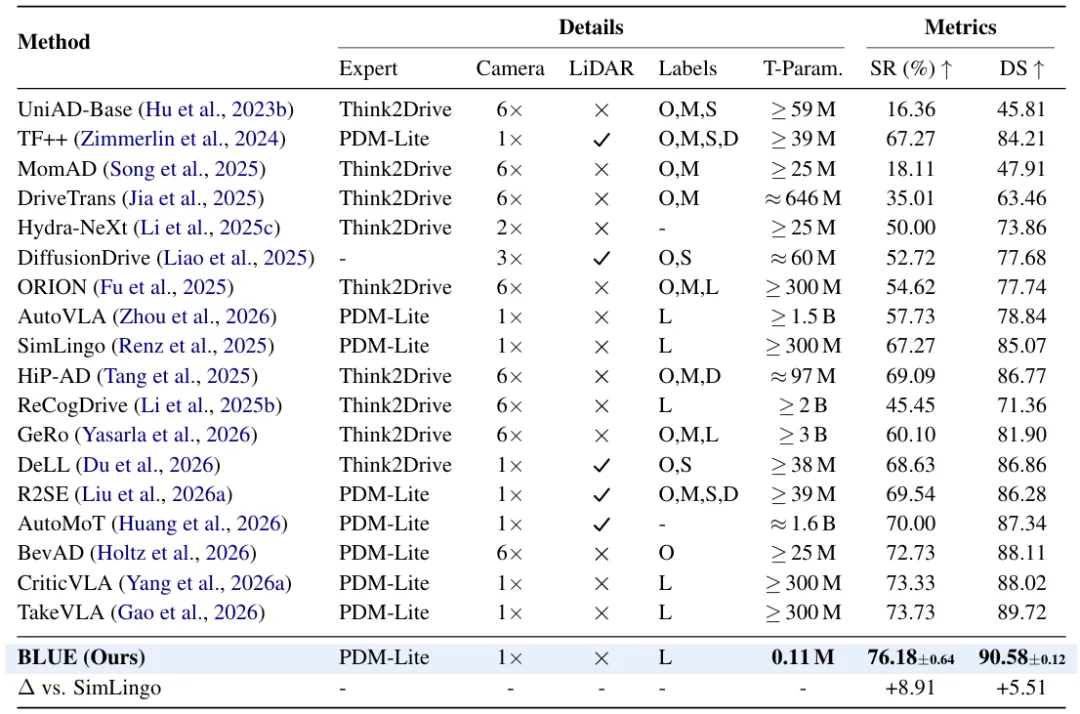
在覆盖 220 条路线、 44 类场景 的 Bench2Drive 上, BLUE 拿到当前 VLA 方法中的最好成绩:
这组数字的分量在于配置极简:只用单前视相机、无 LiDAR、只需语言标注,却超过了多种采用 6 摄像头、 LiDAR 或密集辅助标签( 3D 检测、地图、语义分割、深度等)的闭环方法。 TakeVLA ( 73.73% SR )、 CriticVLA ( 73.33%)、 BevAD ( 72.73%, 6 摄像头)都被甩在身后。
多能力细分上, BLUE 在五项驾驶技能(并线、超车、紧急制动、让行、交通标志)的均值成功率 73.89%,排名第二,仅次于用 6 摄像头的 BevAD ( 74.68%)。超车成功率 80.00%(+12.59 )、紧急制动 93.27%(+11.60 )提升尤其明显——这些恰恰是语言「该出手时出手」最能发挥价值的场景。
Longest6 v2 长程驾驶
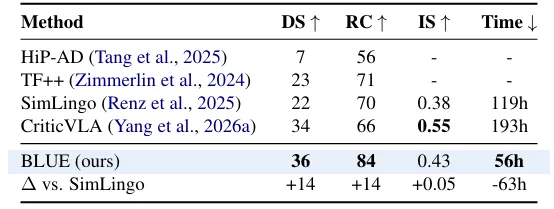
Longest6 v2 考察长程闭环中的驾驶质量维持能力。 BLUE 在这里同样登顶:
路线完成率 +14 个百分点,说明减少无效或有害语言,能在长闭环中抑制误差累积——那些本可直出的帧如果硬走语言链路,错误会一路滚到终点。
推理效率
效率收益和性能收益同步到来:
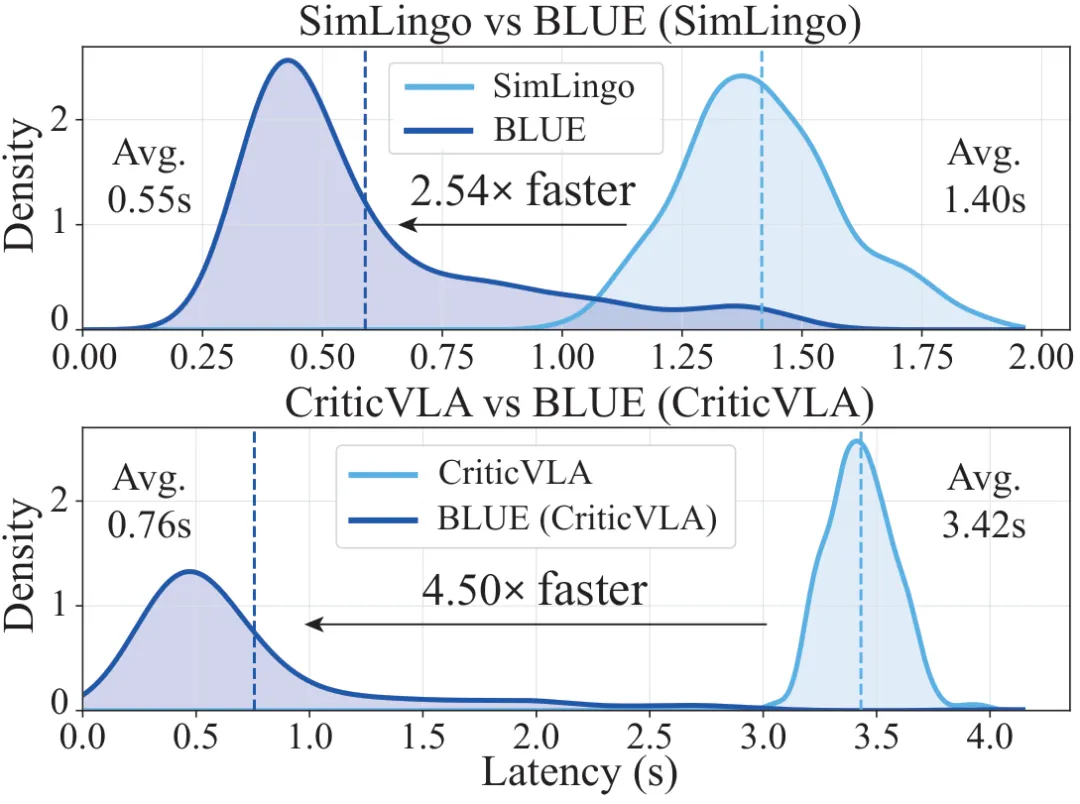
Bench2Drive 评测路线上,各方法逐帧平均延迟分布。 BLUE 将 SimLingo 和 CriticVLA 的延迟整体左移。
Gate 本身几乎不增加开销——它只是一个作用于已算好的 hidden state 上的 MLP 。 BLUE 在约 21.44% 的帧上激活语言生成,其余帧跳过 autoregressive 解码,延迟从 1.40s 降到 0.55s 。换到 CriticVLA backbone 上,加速幅度更夸张:4.50×,平均延迟从 3424.7ms 降到 760ms 量级。
消融实验: gate 学到了什么,又不是什么
激活模式:稀疏且连续
Gate 学到的语言激活模式:多数帧跳过语言,激活点形成连续片段而非孤立噪点。
可视化显示, gate 在大多数帧上跳过语言,激活点形成连续片段——比如进入复杂路口前的一段、需要判断行人意图的窗口——而不是帧级随机闪烁。这说明 hidden states 捕获了时序连贯的决策模式,而不是在噪声上做投机。
规则 gate 全面落败
团队试了速度、加速度、转向角三类运动学规则 gate ,以及基于场景复杂度的规则 gate ,还有随机 gate 。结果一致:全部远低于 BLUE。
运动学特征只反映车辆当前运动状态,无法判断「语言会不会改善驾驶」;场景复杂度是粗粒度路线标签,抓不住帧级动态。 VLA hidden states 联合编码了感知和上下文,才是更强的预测信号。
跨模型泛化:每个 backbone 需要自己的 gate
BLUE 同样适用于 CriticVLA : Bench2Drive SR 从 73.33% 提到 76.04%, Longest6 v2 DS 从 34 提到 36.2 、 RC 从 66 提到 80.6 。但把 SimLingo 上训练的 gate 直接搬到 CriticVLA ,效果会掉一截( 73.11% vs 76.04%)。语言效用信号与模型内部表征绑定,不同 VLA 需要各自训练 gate——好在 gate 只有 0.11M , backbone 完全冻结,适配成本远低于重训大模型。
阈值与数据量
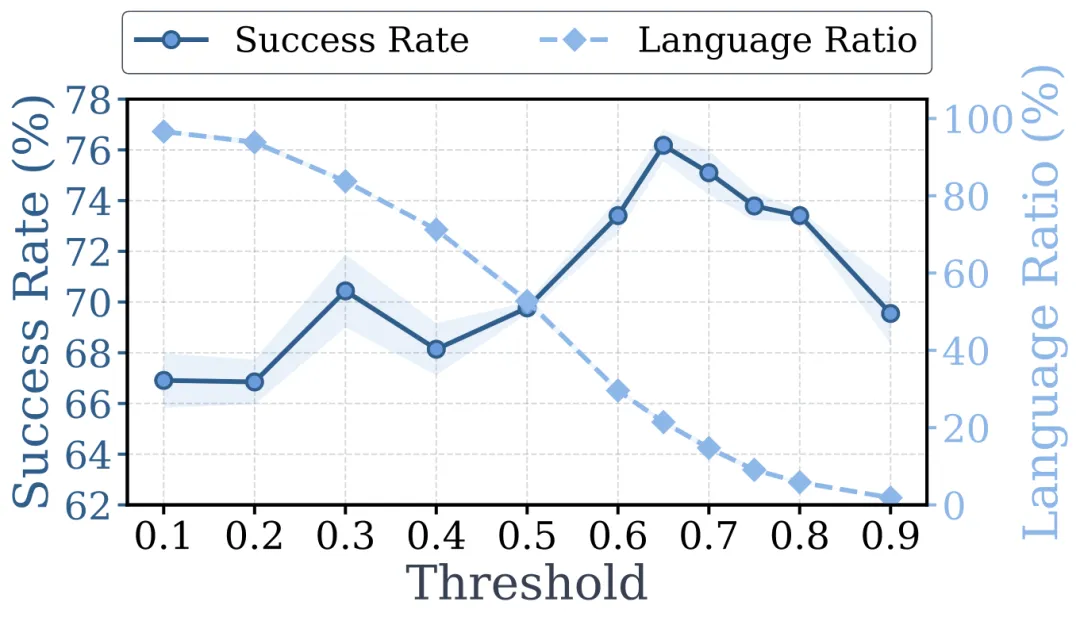
阈值 对语言激活率和成功率的影响。 区间都表现稳健。
过低(几乎每帧都生成语言)时 SR 降到 66.91%; 过高(每帧都跳过语言)时 SR 为 69.55%。 的 76.18% 远超两端极端设置,验证了按需启用的必要性。
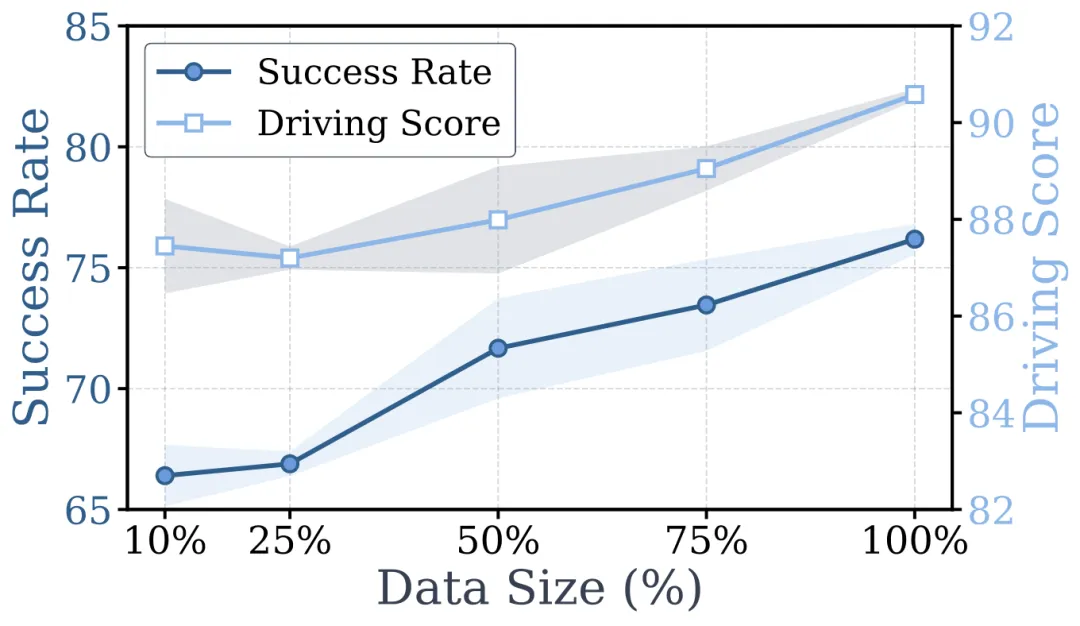
训练数据量对 gate 性能的影响:用一半路线(约 200 条)就已明显超过 SimLingo backbone 。
训练路线从 10% 增到 100%, SR 和 DS 稳步上升。只用一半数据(约 200 条路线), gate 就已超过 SimLingo backbone ,说明 hidden states 里的语言效用信号用中等数据量就能学到。
语言内容也在变
闭环驾驶中生成语言的 N-gram 词云:左为 SimLingo 每帧生成,右为 BLUE 按需生成。
词云对比显示, BLUE 激活语言时生成的短语更聚焦、更少冗余——gate 筛掉了大量「说了也白说」的帧,留下的语言更集中在真正需要推理的片段。
小结
博世 Research 的 BLUE 用约 2000 GPU hours 的闭环分析,先把「语言在驾驶里到底帮不帮」这件事量清楚了,再基于 hidden states 训练 0.11M gate 做逐帧决策。闭环结果汇总如下:
■Bench2Drive :76.18% Success Rate 、90.58 Driving Score (+8.91 / +5.51 )■Longest6 v2 :36 Driving Score 、84 Route Completion (各 +14 )■推理:2.54× 加速,延迟 1396.6ms → 549.5ms■配置:单前视相机、冻结 backbone 、无额外人工标注BLUE 最值得关注的,不只是它把分数刷高了,而是它重新定义了自动驾驶 VLA 里语言的角色。
语言不是免费的解释文本,而是一段会真实改变动作分布和推理时延的中间计算。既然如此,真正有效的方向就不该只是“让模型生成更多语言”,而应该是“只在语言能改善驾驶时生成语言”。
从这个角度看,BLUE 的贡献可以概括成一句话:它证明了自动驾驶 VLA 的语言能力,不是靠更长的 reasoning chain 获得的,而是靠更好的启用时机获得的。
这也是它能够同时拿到 更高闭环成绩 和 更快推理速度 的根本原因。
⭐️关注我,实时跟进 AI 最新进展⭐️

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
