自动驾驶感知系统是智能汽车实现自主决策、安全行驶的核心基础,相当于车辆的“眼睛”和“视觉大脑”。作为专栏的开篇之作,我们聚焦于感知系统最基础、也是最关键的任务之一:目标检测。目标检测作为感知模块的核心任务,主要分为2D目标检测与3D目标检测两大技术体系。(限于篇幅原因,本篇先盘点2D目标检测)我们按技术架构将算法划分为两阶段Anchor-Based算法、单阶段CNN Anchor-Based算法、单阶段Anchor-Free算法、Transformer视觉骨干检测算法四大类,贴合自动驾驶车载RGB图像检测场景。
每个算法我们都尽可能直白讲解原理、指明核心创新,提炼一下共同点(都是同一个大思想下的小改动),顺便也说说车载落地适配性,贴合自动驾驶车辆、行人、交通标识、遮挡小目标检测需求。
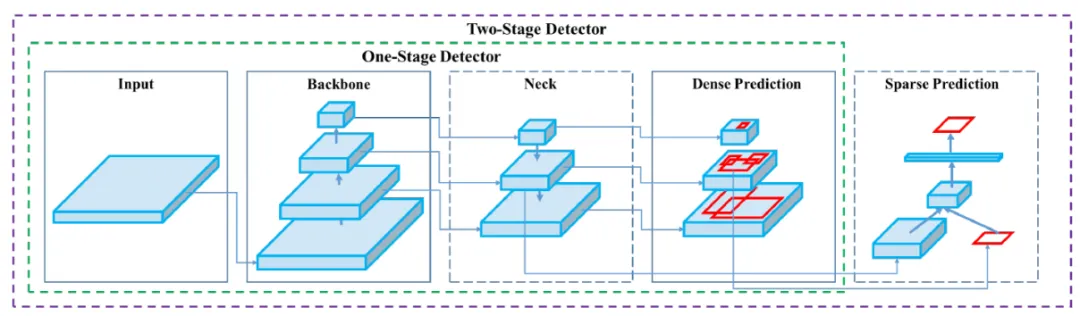
它们的共性是遵循「候选框生成→特征精修分类回归」双流程,先筛前景候选区域,再微调边框、完成分类,误检率低、密集遮挡目标精度高;缺陷是推理链路长、帧率低,车载边缘算力部署压力大,均依托锚框Anchor设计。
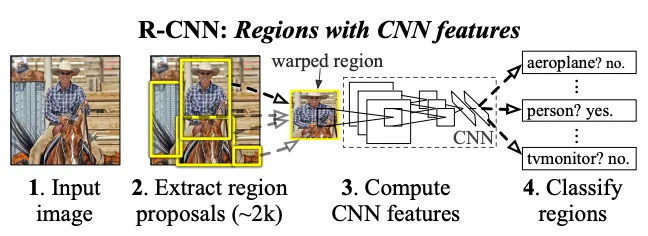
(1)R-CNN
简介:选择性搜索提取2000个图像候选框,逐个裁剪送入CNN提特征,搭配SVM完成分类、边框微调。
亮点:首次将卷积深度学习引入自动驾驶2D检测,替代传统HOG人工特征,检测精度跨越式提升。
局限:但是候选框重复卷积、速度极慢,无法车载实时部署。
(2)Fast R-CNN
简介:对整张图像仅卷积提取一次全局特征,通过RoI池化层截取候选框特征,分类、边框回归联合训练。
亮点:共享图像卷积特征、取消重复计算,合并训练流程,相较R-CNN提速多倍;解决模型分段训练、特征冗余痛点。
局限:保留选择性搜索候选框,无网络自主生成候选区,速度大幅优化但未摆脱传统区域搜索。
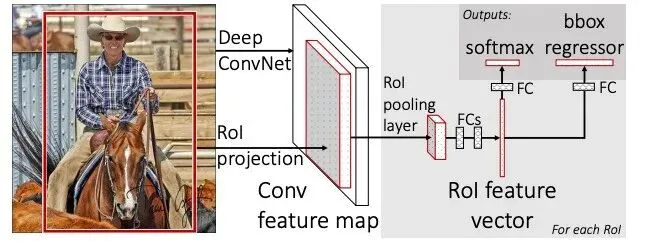
(3)Faster R-CNN
简介:原理是骨干网络提特征,新增RPN区域建议网络自主生成Anchor锚框与候选区,RoI池化后完成检测,完整端到端卷积架构。
亮点:用神经网络RPN替代选择性搜索,实现首个全深度学习两阶段检测器,成为自动驾驶高精度检测基线。
是同系列精度最优、推理最快,是R-CNN、Fast R-CNN终极优化版本,量产高精度感知基线模型。
共同特点是舍弃独立候选框分支,整张图像单次前向推理,同步输出类别+边框,推理速度远快于两阶段模型;依托预设Anchor,车载帧率高、轻量化易部署,但是小目标、正负样本失衡为通用短板。
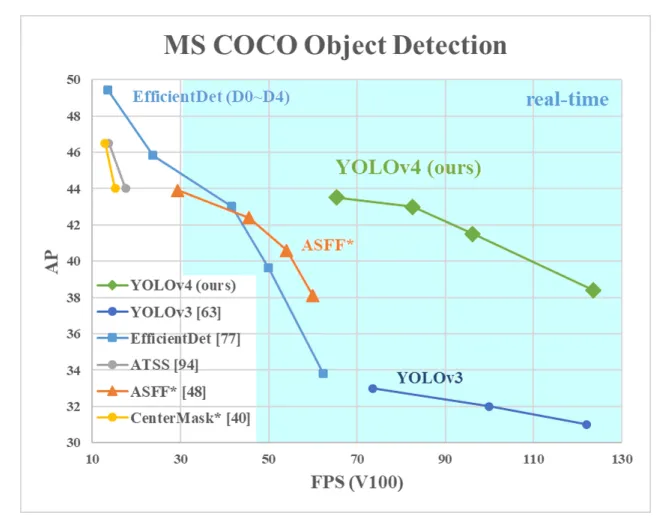
包含SSD、RetinaNet、EfficientDet、YOLOv3/v4/v5/v7/v8/v9全系列。
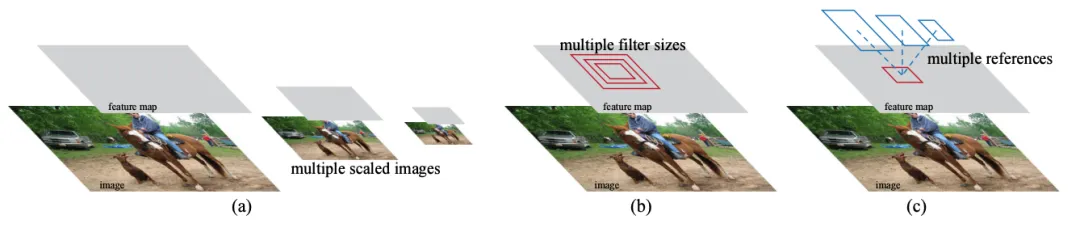
(1)SSD
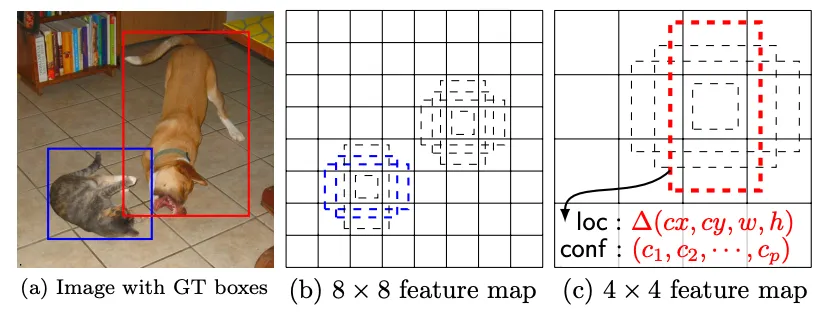
简介:是多尺度特征金字塔分层检测,浅层特征查远距离交通小目标,深层特征查近处车辆,多尺寸Anchor匹配目标。
核心创新:首创单阶段多尺度检测架构,兼顾YOLO速度与Faster R-CNN定位精度,适配车载大小交通目标。
异同:比初代YOLO小目标精度更强,无复杂骨干、部署简单,正负样本不均衡缺陷未解决。
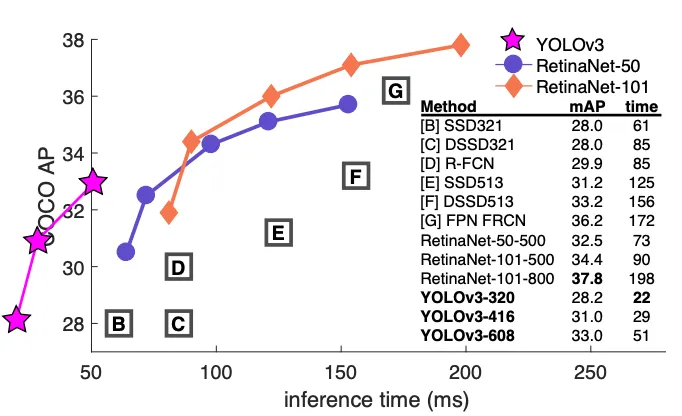
(2)RetinaNet
出自何恺明团队的经典算法
简介:沿用FPN特征金字塔+SSD锚框架构,更换损失函数优化模型训练。
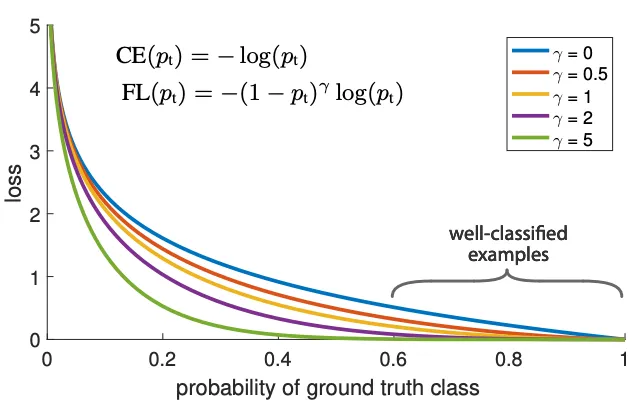
核心创新:提出Focal Loss焦点损失,压制背景负样本权重、解决单阶段正负样本失衡痛点,单阶段精度追平两阶段算法。
效果:架构贴合SSD,核心革新损失函数,拥堵车流、复杂背景自动驾驶检测效果大幅提升。
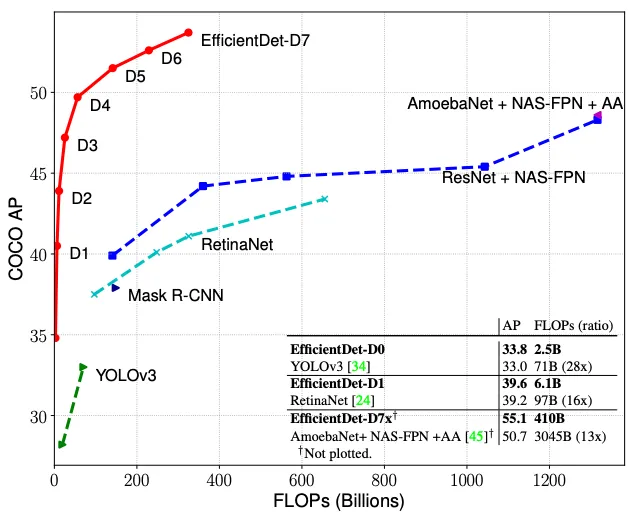
(3)EfficientDet
来自Google Brain团队,EfficientDet是一系列可扩展的高效的目标检测器的统称。
简介:复合缩放统一优化骨干网络、特征金字塔、检测头维度,双向加权FPN融合多尺度特征。
亮点:提出模型复合缩放策略、BiFPN双向特征融合模块,参数更少、多尺度目标泛化性更强,雨雪天气图像特征融合效果优异。
异同:相较SSD、RetinaNet特征融合更高效,模型轻量化、泛化性拉满,车载算力适配性更强。
(4)YOLOv3
初代均衡型YOLO,弥补v1/v2小目标漏检缺陷,算力开销适中。
(5)YOLOv4
简介:优化骨干激活函数、Mosaic车载图像增强、CIoU边框损失。
核心创新:新增自动驾驶路况专属数据增强、优化损失函数,逆光、夜间路况鲁棒性提升。
异同:纯工程trick优化,网络骨架不变,恶劣路况适应性优于v3。
(6)YOLOv5
参数量远低于v4,推理帧率更高,低成本量产车型首选。
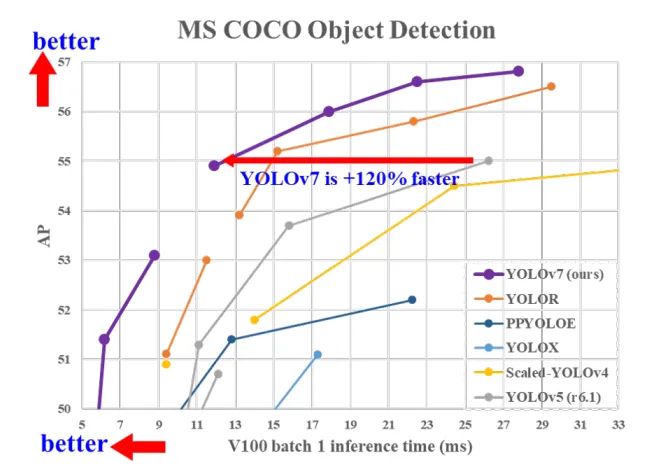
(7)YOLOv7
速度、精度双向超越v5,中高算力车载平台主流选型。
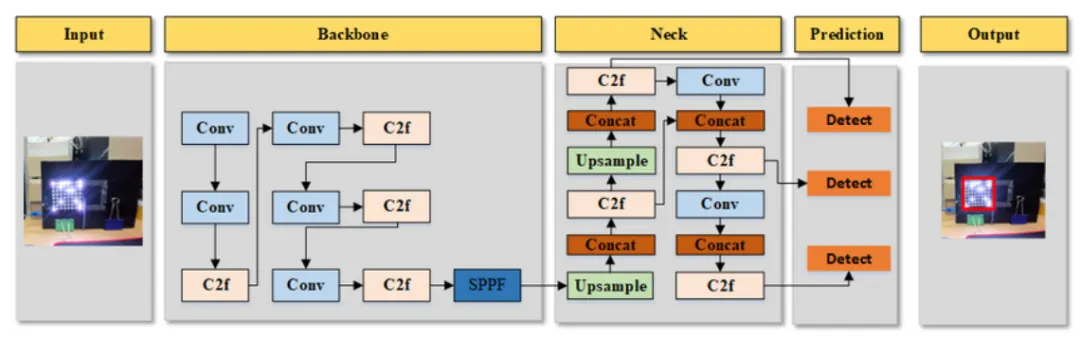
(8)YOLOv8
新增分割分支,密集车流场景优于v7,算法功能多元化。
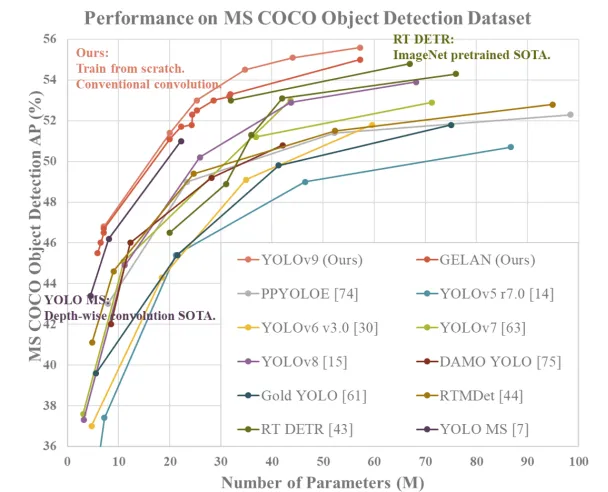
(9)YOLOv9
ps:因为我们是讨论经典算法,所以v10/v11...版本等待时间证明。
单阶段Anchor-Free算法(无锚框、低参数量、轻量化)
摒弃人工预设Anchor锚框,消除锚框超参调试成本、边框冗余计算,结构极简、训练更简单;分为中心点预测、角点预测两类,自动驾驶形变目标适配性更强。包含CenterNet、CornerNet。
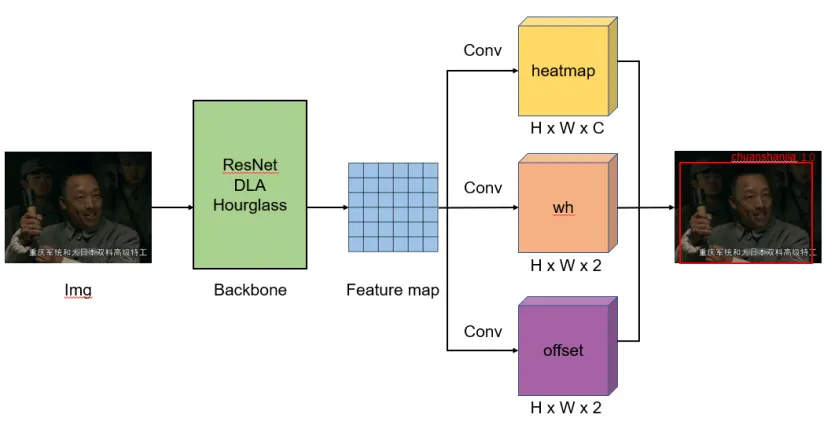
(1)CenterNet
(2)CornerNet
这一类算法依托自注意力机制建模图像全局像素依赖,摆脱CNN局部卷积视野局限,车流重叠、遮挡、远距离目标精度拉满;分为纯视觉Transformer骨干、DETR检测架构两类,高阶自动驾驶视觉基线。
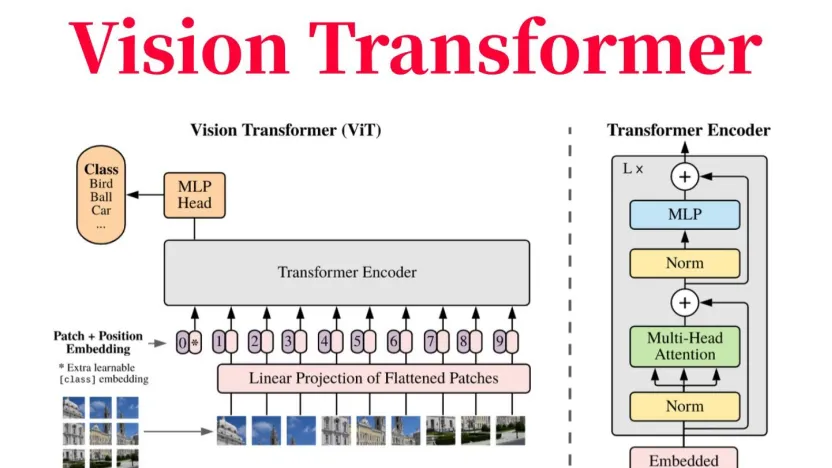
(1)ViT
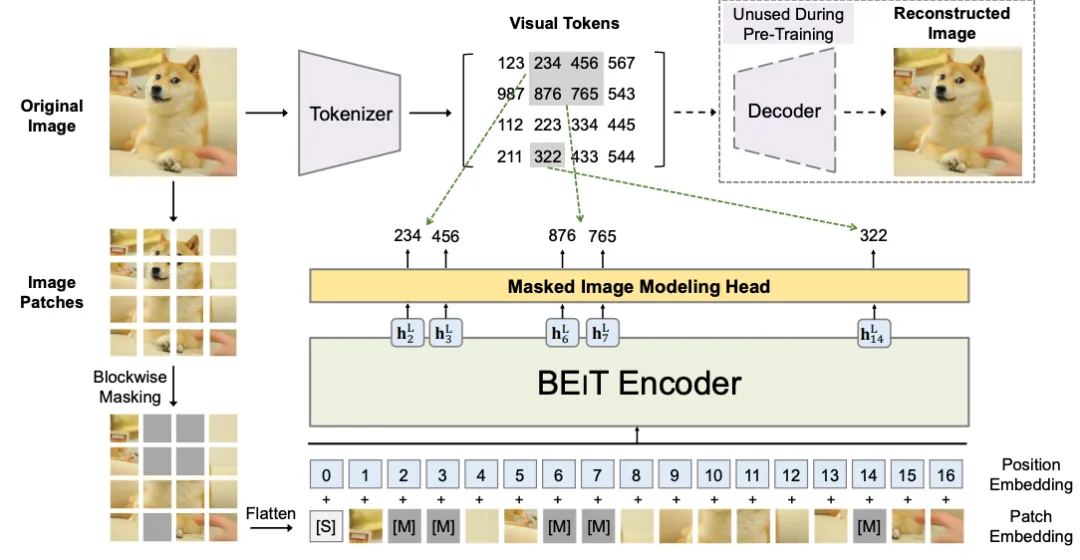
(2)BEiT
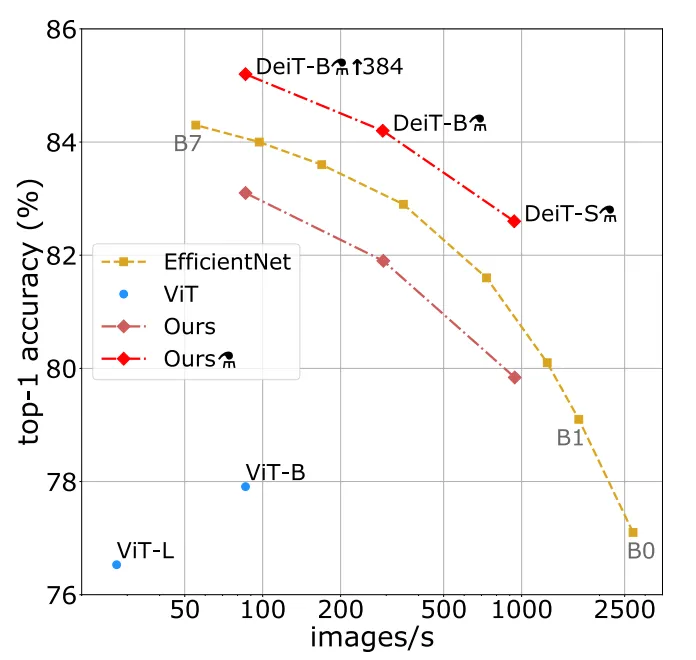
(3)DeiT
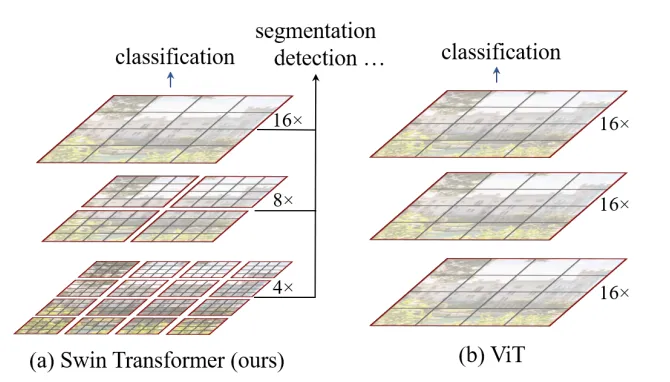
(4)Swin Transformer
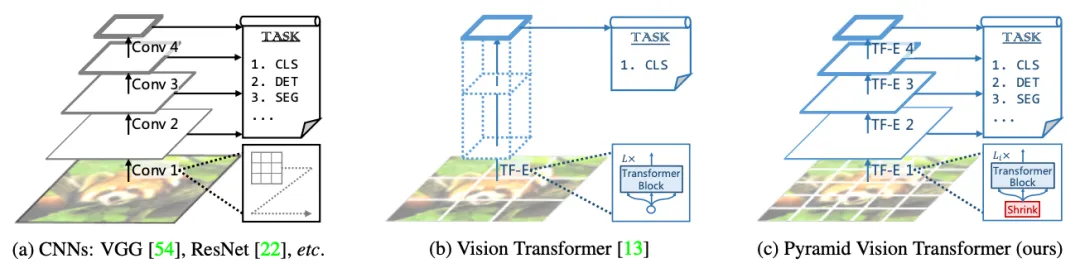
(5)PVT
简介:是金字塔分层Transformer、渐进式下采样,轻量化多级语义特征。
核心创新:纯Transformer轻量化金字塔结构,替代CNN-FPN,参数量低于Swin。
亮点:比Swin更轻量化、车载帧率更高,精度小幅下降,低成本视觉模型优选。
(6)DETR
简介:Transformer编码器+解码器,端到端直接输出检测结果,舍弃Anchor、NMS后处理。
亮点:属于首个Transformer端到端2D检测器,简化检测流水线,重叠目标误检率大幅降低。
局限:CNN检测器后处理全部取消,重叠车流检测效果比较好,但收敛慢、小目标精度差。
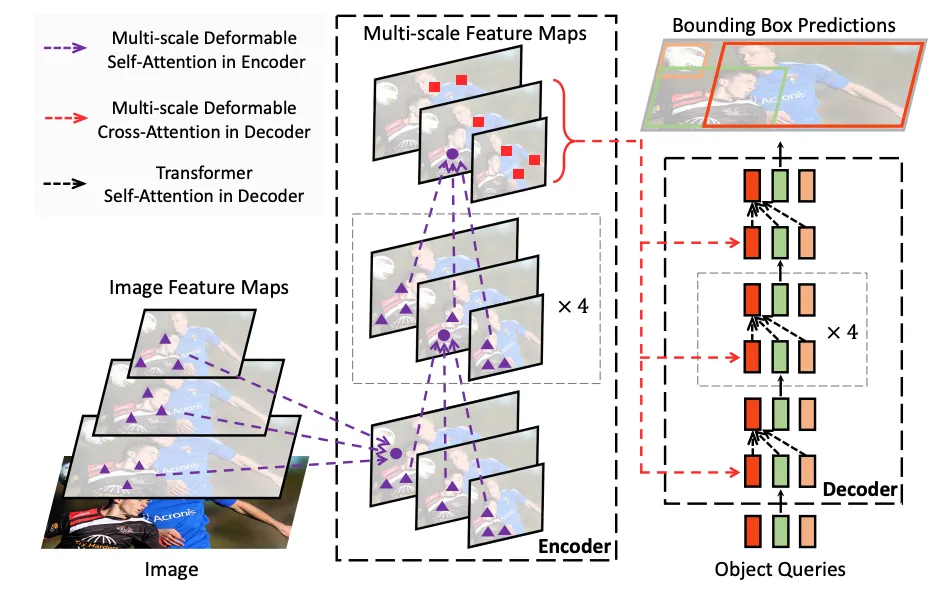
(7)Deformable DETR
简介:采用可变形稀疏注意力,仅聚焦目标像素做注意力计算。依靠稀疏注意力提速、优化小目标特征,修复DETR收敛慢、远距离路标漏检缺DETR量产优化版本,适配自动驾驶远距离、小尺寸交通标识检测,车规Transformer检测基线。
自动驾驶2D目标检测从CNN卷积两阶段、单阶段经典架构,迭代至Transformer端到端检测体系,YOLO、Faster R-CNN、DETR 三大系列支撑了近十年辅助驾驶的量产落地。
相较于复杂多模态3D感知,优化后的新一代2D检测算法成本优势显著,仍是L2级量产自动驾驶的核心感知方案。
但当前2D目标检测在车载落地中仍面临多重挑战:精度与实时性矛盾突出,Transformer高精度模型算力开销大;恶劣天气、隧道明暗切换等场景图像失真,检测精度断崖式下跌;长尾未知障碍物识别能力弱;跨场景域偏移导致标注成本高昂。
未来结合视觉预训练大模型、端到端、轻量化注意力机制等,可进一步解决恶劣天气、长尾目标、跨场景适配难题,推动低成本自动驾驶规模化商用。
前时间账号迁移,很多老粉表示咋刷不到我们文章了,的确全靠运气。既有缘相遇此文,不妨把我们星标收藏,慢慢聊车、无人机、机器人、聊技术。