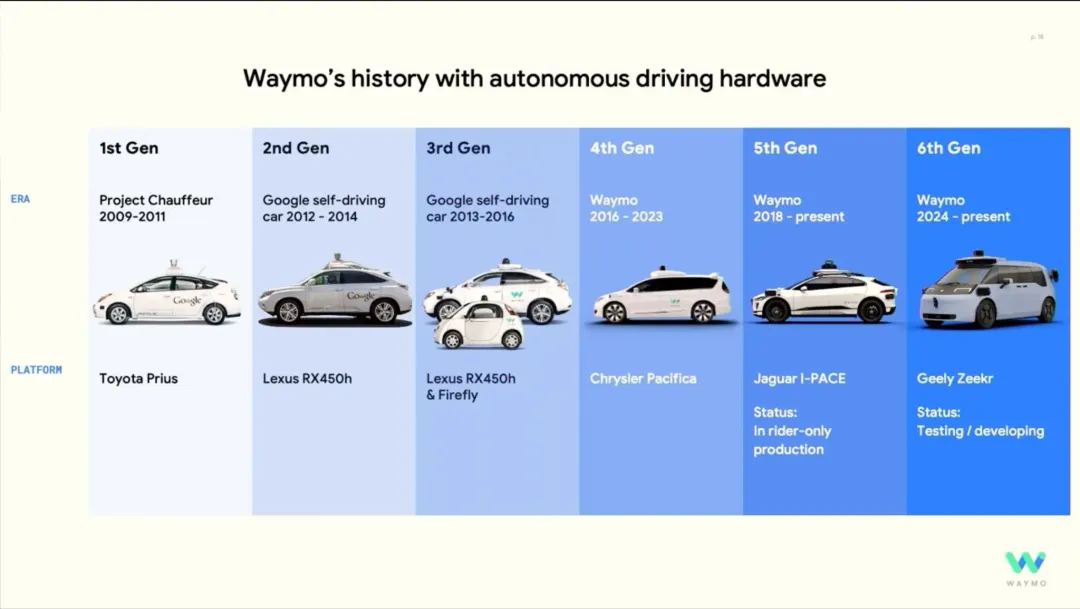
via waymo blog范式转移:从“画像”到“写字”:
- 过去 (CNN/Rasterization): 像给 AI 看卫星地图照片,图片像素点多、冗余大,且远处物体会因为分辨率变低而“模糊”,导致丢失几何精度。
- VectorNet: 像给 AI 看矢量草图。它认为世界由 Polylines(折线) 构成。
- 技术优势: 将路缘、车道线、行人路径简化为点对点的向量序列。数据量减少了 70%-90%,且无论距离多远,位置精度都依然是厘米级的。
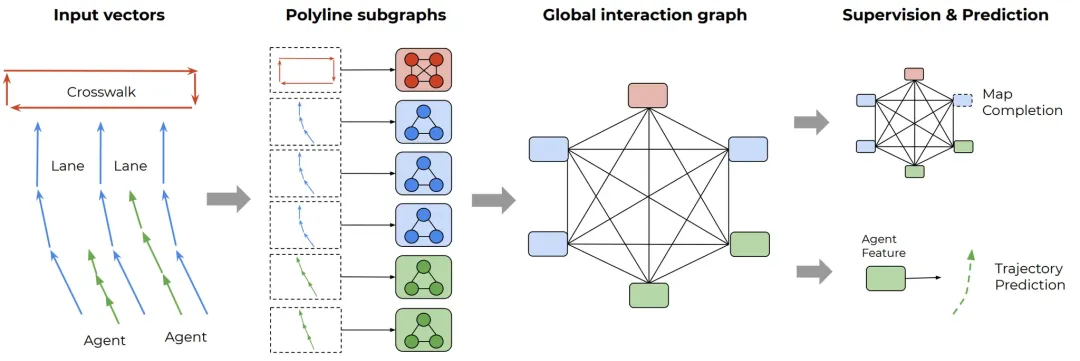 VectorNet 概览
VectorNet 概览核心架构:双层图神经网络 (Hierarchical GNN):
- 局部聚合(Polyline Subgraphs): 将 Agent 轨迹和地图特征表示为向量序列,输入局部图网络,提取每条折线(Polyline)的深层特征。
- 全局交互(Global Graph): 将提取出的折线特征传入全连接图,利用 Attention 机制建模交通参与者与地图元素之间的高阶博弈关系。
- 轨迹预测: 基于节点特征预测 Agent 的未来运动路径。
- 特征补全: 对随机遮蔽(Masked)的节点特征进行预测,强化模型对场景语义的理解。
VectorNet 的核心笔记:
- 表示法: 用矢量线段(Polylines)取代栅格图片,实现输入数据的低损耗、高精度。
- 分层聚合: 先局部提取单条线特征,再全局建模万物之间的空间博弈,大幅降低计算量(FLOPs 减少一个数量级)。
- 本质贡献: 定义了后续 Wayformer 和 WFM 统一处理时空数据的“母语”——即“万物皆可向量化,万物皆可 Transformer”。
Wayformer(2022)
标题:Wayformer: Motion Forecasting via Simple & Efficient Attention Networks
链接:https://arxiv.org/abs/2207.05844
地位:多模态融合底座,实现了从“图神经网络(GNN)”向“通用 Transformer”的架构统一,为后续 Foundation Model 奠定了技术框架。
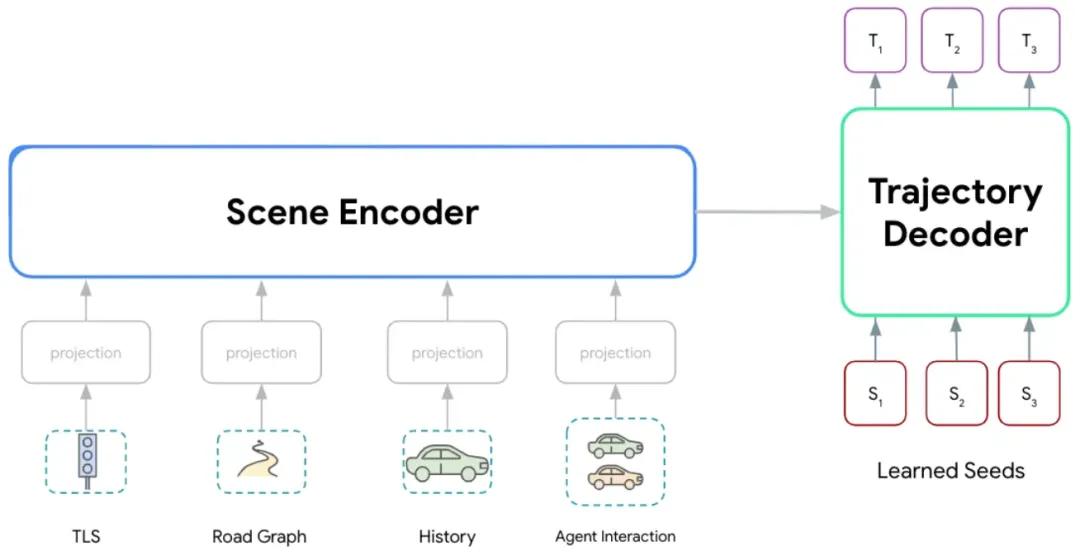 Wayformer 架构,由一对编码器/解码器 Transformer 网络组成。输入多模态场景数据,输出轨迹的多模态分布。
Wayformer 架构,由一对编码器/解码器 Transformer 网络组成。输入多模态场景数据,输出轨迹的多模态分布。- Encoder(场景编码): 负责消化复杂的多模态场景 Token,提取深层的时空特征。
- Decoder(分布预测): 负责输出轨迹(Trajectory)的多模态分布。不只给出一个结果,而是预测多种可能的未来路径及其概率。
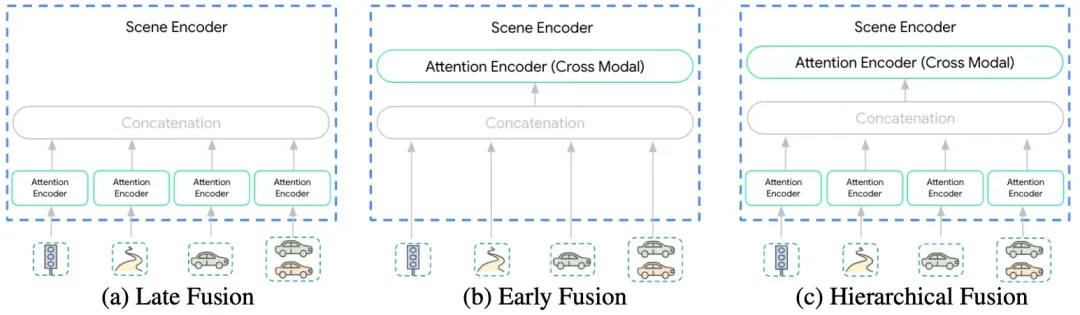 不同阶段融合多模态输入的 Wayformer 场景编码器
不同阶段融合多模态输入的 Wayformer 场景编码器- 后期融合 (Late Fusion): 各模态先独立编码再汇聚。缺点是模态间的深度交互发生得太晚。
- 前期融合 (Early Fusion) —— Wayformer 首选: 所有模态的 Token 从第一层 Transformer 开始就进行交叉注意(Cross-attention)。
Wayformer 的核心笔记:
- 时空统一: 继承了 VectorNet 的空间矢量化,并通过 Transformer 统一时间序列和静态空间的特征表达。
- 深度融合: 证明了 Early Fusion 在处理自动驾驶复杂场景时优于其他架构,显著提升了预测精度。
- 计算优化: 引入了 Latent Query(潜在查询)等技术,解决了全注意力机制在处理海量地图 Token 时的算力瓶颈。
- 本质贡献: 它证明了 Transformer 可以作为自动驾驶的“通用大脑”,直接开启了从“模块堆砌”向“端到端大模型”进化的道路。
MotionLM(2023/09)
- 标题:MotionLM: Multi-Agent Motion Forecasting as Language Modeling
- 链接:https://arxiv.org/abs/2309.16534
- 地位:标志着 Waymo 方案从“特征工程”全面转向“生成式大模型”。它不再需要复杂的规则来定义博弈,博弈能力直接从海量数据中涌现。
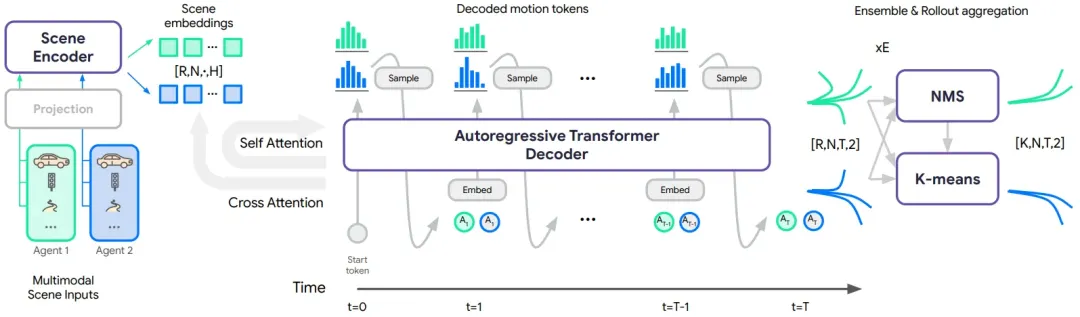 MotionLM 架构
MotionLM 架构- 场景特征编码 (Scene Encoding): 针对每个智能体(个)提取异构场景特征,生成场景嵌入(Scene Embeddings)。通过在批次维度重复 次,支持并行路径采样(Parallel Sampling)。
- 自回归轨迹解码 (Autoregressive Decoding): 解码器以时间因果方式,为多个智能体同步生成 步离散运动 Token。每一时刻的预测均依赖于历史状态及其他智能体已生成的动作。
- 模态聚合 (Mode Aggregation): 对生成的 组路径进行聚类。利用 NMS(非极大值抑制) 初始化的 k-means 算法,从大量随机采样中提取出最具代表性的 种多模态预测轨迹。
明确了 (Rollouts) 的概念。MotionLM 通过并行采样 次,得出不同的“平行宇宙”走向,最后用聚类选出最合理的几条。
MotionLM 的核心笔记:
- 表示法:将连续运动轨迹离散化为 Motion Tokens,利用语言模型框架处理驾驶不确定性。
- 核心机制:自回归(Autoregressive) 生成。通过时间上的序列依赖,完美模拟交通参与者之间的博弈互动。
- 本质贡献:证明了自动驾驶的行为规划可以被彻底转化为一个序列生成任务。它不再需要预设博弈规则,而是通过“续写”交通流,实现了真正的交互式决策。
EMMA (2024/10)
标题:EMMA: End-to-End Multimodal Model for Autonomous Driving
链接:https://arxiv.org/abs/2410.23262v1
地位: Waymo“感知-决策-规划”大一统的最终理想。证明了通用 AI(AGI)的技术栈可以直接平移到物理世界的移动任务中。
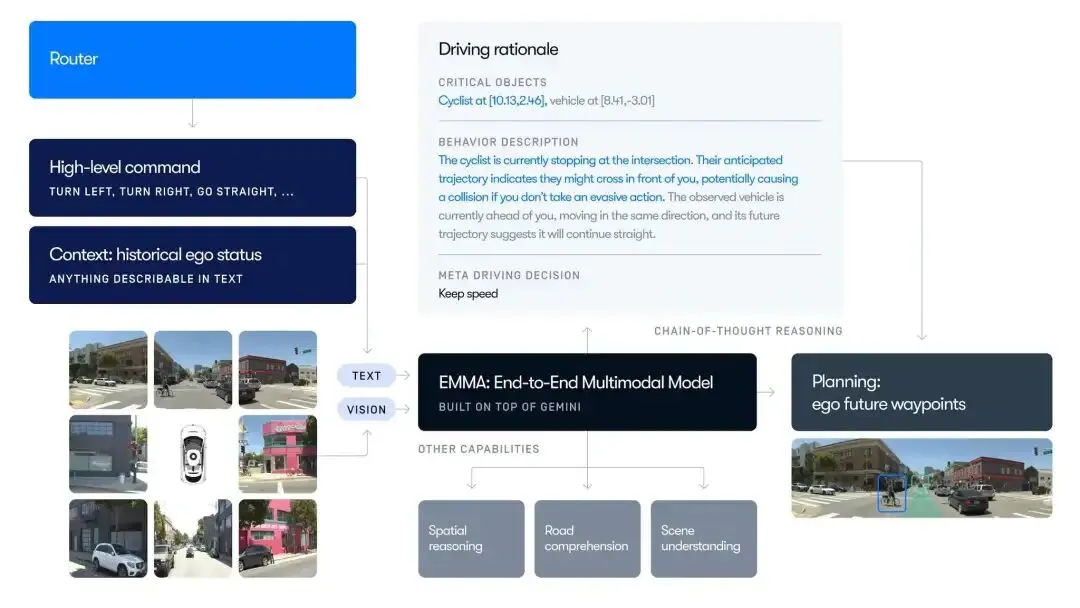
- 多模态输入 (Multimodal Input): 环视摄像头视频 + 导航指令(文本)+ 自车(ego)历史状态。
- 思维链推理 (Chain-of-Thought, CoT): 在生成轨迹前,模型会先输出文本逻辑(如:“前方车辆减速,我需要保持车距”)。这种先“想”后“写”的方式显著提高了决策的可解释性。
- 视觉接地 (Visual Grounding): 模型在推理时会自动关联 3D 空间坐标,确保生成的行为与真实的物理世界(BEV 空间)精准对齐。
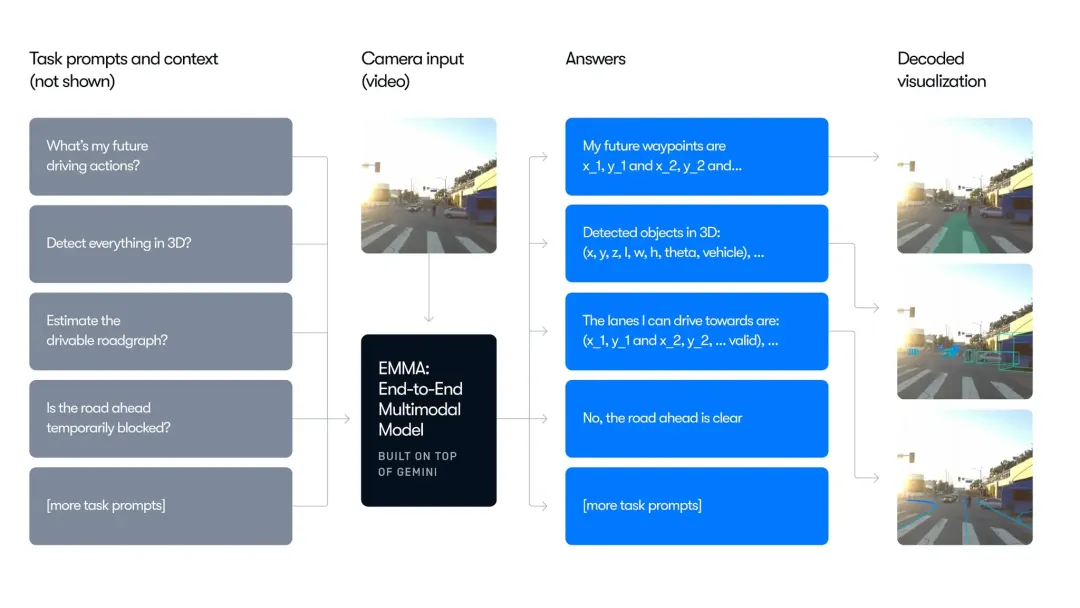
- 全栈能力: 不仅仅是开车。同一个模型可以同时完成:端到端规划、目标检测、道路拓扑估算、场景问答 (QA)。
- 统一输出格式: 所有的任务都被简化为“文本/Token 生成”。例如,检测到一个障碍物,对模型来说只是生成了一串包含特定坐标的“单词”。
证明了自动驾驶可以被建模为一个统一的文本生成任务。无论是检测障碍物坐标,还是规划路线,在它看来都是一种“语言输出”。
EMMA 的核心笔记:
- 表示法: 抛弃矢量化,回归原始图像序列,将自动驾驶建模为纯粹的多模态序列生成任务。
- 深度融合: 借助 Gemini 强大的视觉-语言跨模态能力,让自动驾驶具备了处理极端复杂、模糊场景的“常识”。
- 本质贡献: 定义了自动驾驶的“终局形态”——World Model(世界模型)。证明了感知、预测、规划不需要分步走,一个足够强大的多模态大模型就能完成从像素到控制的全过程。
缺点:EMMA 摆脱了对高精地图和矢量特征的依赖,但其核心挑战在于 VLM 极高的推理计算延迟,纯视觉端到端方案在极暗或恶劣天气下对物理距离的精准感知能力(相比激光雷达)存在不确定性。
小结
| 模型阶段 | 核心范式 | 输入特征 | 处理逻辑 | 解决的核心痛点 |
|---|
| VectorNet | | | | |
| Wayformer | | | | |
| MotionLM | | | | |
| EMMA | | | | |
- 从“硬编码”到“涌现”: 以前是工程师告诉模型什么是车道线(VectorNet),现在是模型自己从像素里悟出什么是路(EMMA)。
- 从“单向感知”到“双向博弈”: 以前是只看别人怎么走,现在是“我考虑了你会考虑我的考虑”(MotionLM 自回归)。
- 从“工具箱”到“大脑”: 以前每个任务一个模型,现在一个 Gemini 底座解决所有问题(EMMA Generalist)。
Waymo Foundation Model
 via waymo blog
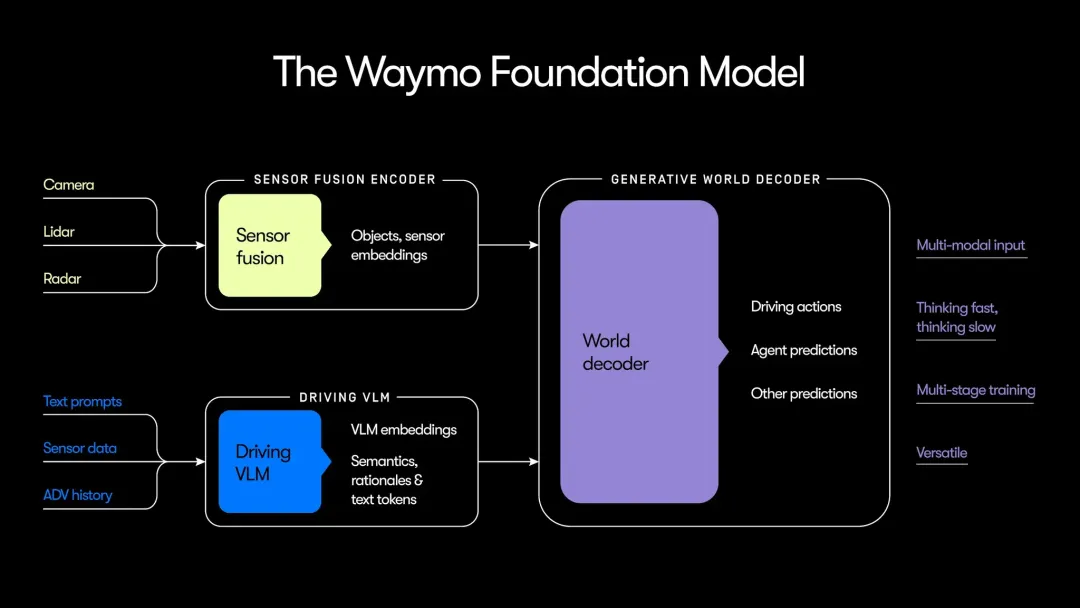
via waymo blog- System 1 (快思考): 传统 L4 的强项,利用多传感器(LiDAR, Radar, Camera)解决“看得到、反应快”的问题,将场景拆解成多个独立对象。
- System 2 (慢思考): VLM 的核心,使用Gemini训练,利用其常识解决“看得懂、想得深”的问题(如:识别事故车辆、紧急车辆,理解火灾的危险性而非仅仅将其视为障碍物)。
- World Decoder: 相当于“执行官”,把感知到的信息转化为具体的预测轨迹、驾驶指令和地图等。
Waymo Foundation Model 是一套采用“系统 1(即时感知)与系统 2(语义推理)”协作的结构化端到端架构;通过数据驱动实现全链路可导,同时保留了清晰的语义逻辑,平衡了端到端技术的性能上限与安全可解释性(可审计)。
仿真部分
Waymo 认为:“在模拟器中死掉一万次,好过在现实中发生一次碰撞。”
仿真重要性:处理 0.1% 的长尾工况。现实中 100 万英里才能遇到的复杂路口,在模拟器里可以每天运行一亿次。
通过文本指令(天气/时间)与语义约束(交通流和红绿灯),将现实场景(左)对应的底层紧凑结构化世界表示转化为纯生成的、高保真的相机(中)与激光雷达(右)仿真数据。SimNet@Lyft(2021/05)
标题:SimNet: Learning Reactive Self-driving Simulations from Real-world Observations
链接:https://arxiv.org/abs/2105.12332
地位: 闭环仿真(Closed-loop Simulation)的先驱工作,首次证明了可以通过数据驱动的方式,让仿真环境具备与人类一致的“交互反应”。
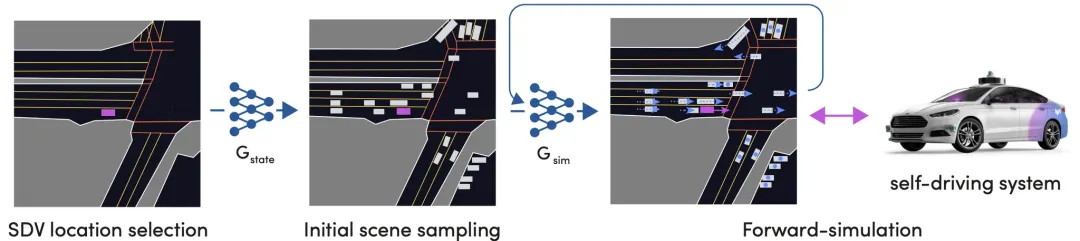 仿真采样过程概览
仿真采样过程概览- 初始采样: 从真实日志中提取历史时刻,作为包含所有交通参与者的“初始快照”。
- NPC: 由 SimNet 神经网络控制,每一步都在观察周围环境。
- 自车 (SDV): 由待测试的自动驾驶算法(Planner)控制。
- 闭环演进: 两者不断交互,共同推进驾驶片段向未来展开,生成“从未发生过”但符合人类逻辑的新场景。
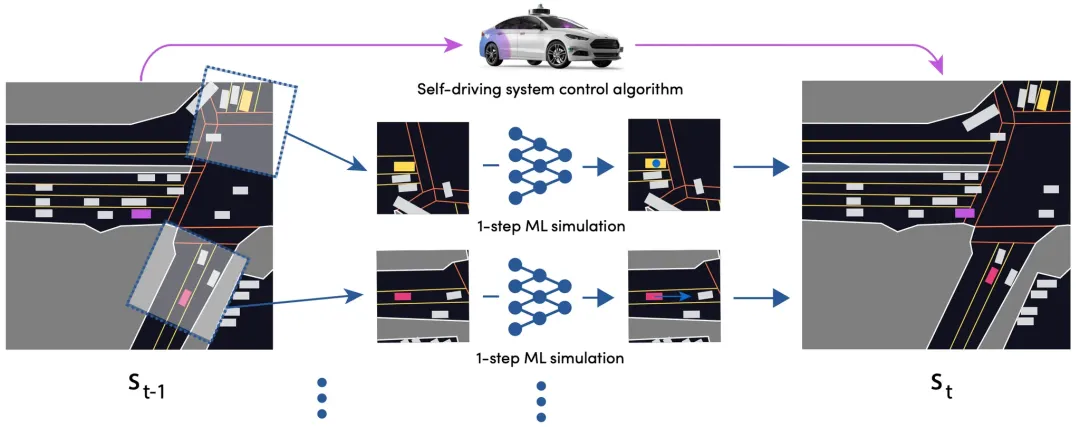
- 马尔可夫建模: 将仿真看作马尔可夫过程。每一帧的状态 仅取决于前一帧 的博弈结果。
- 并行预测(Independent Step Prediction):模型对场景中所有 Agents 独立运行单步轨迹预测。
- 输入: 包含地图、障碍物历史轨迹的 Bird's Eye View (BEV) 表征。
- 输出: 代理在下一时刻的最优位置,并由此更新全局状态 。
- 因果一致性: 解决了“因果混乱”问题。模型能分辨出是“因为前车刹车,我才刹车”,而非盲目跟从历史日志。
SimNet 的核心笔记:
- 真实感 (Realism): 轨迹是否像真人开出来的?
- 反应性 (Reactivity): 别人会不会因为我的动作而做出避让?
- 端到端训练: 直接从 1,000 小时的真实驾驶日志中模仿学习(Imitation Learning),无需手动编写任何复杂的物理规则或动力学模型。
- 本质贡献: 论证了“仿真必须是闭环的”。它是后续所有生成式世界模型(如 Drive&Gen)和交互式挑战赛(Waymax)的思想鼻祖。
UniSim@waabi(2023/08)
标题:UniSim: A Neural Video Simulator for Autonomous Driving
链接: https://arxiv.org/abs/2308.01898 (CVPR 2023)
地位: 神经闭环仿真的里程碑工作。首次证明了可以通过“动静分离”重构现实世界,让仿真是可以交互、可以“改剧本”的数字孪生。

- 上图(创建孪生): UniSim 将采集车录制的摄像头和 LiDAR 数据,转化为可自由操控的“数字孪生”场景。
- 下图(闭环验证): 系统为新场景生成时序连贯的传感器数据(图像和LiDAR)。自驾系统(SDV)与环境实时博弈(如变道),并在交互中接收动态反馈。
 方法概览
方法概览- 场景拆解: 将 3D 场景解构为静态背景(灰色)和一组动态代理(红色)。
- 特征提取: 分别查询两者的神经特征场(Neural Feature Fields),通过体渲染(Volume Rendering)生成特征描述符。
- 动态代理: 利用超网络(Hypernetwork)从可学习的隐变量(Latent)生成每个代理的表征。
- 图像渲染: 最后通过卷积网络(CNN)将提取的特征块解码为最终图像。
UniSim 的核心笔记:
- “What-if” 测试能力: 能够模拟从未发生过的危险场景,如“如果前车在 5 米内突然急刹,我的感知和决策能否反应过来?”。
- 动静层分离: “图层式”的场景建模,解决了传统重建中动态物体留下的“鬼影”和“空洞”问题,使背景重构异常干净。
- 本质贡献: 定义了神经视觉仿真器的标准形态,为后续 DrivingGaussian(追求性能)和 Drive&Gen(追求生成多样性)奠定了“场景拆解”的底层逻辑。
UniSim 就像是一个“带神经皮肤的木偶系统”。SimNet 是幕后的牵线人(控制结构化状态),而 UniSim 负责给木偶披上真实的皮肤并渲染灯光(处理高维特征)。
这种“结构化控制 + 高维渲染”的组合,完美解决了传统仿真“不够真”和单纯视频生成“不可控”的双重痛点。
DrivingGaussian@Google Research(2023/12)
标题:DrivingGaussian: Composite Gaussian Splatting for Surrounding Dynamic Autonomous Driving Scenes
链接: https://arxiv.org/abs/2312.14920 (CVPR 2024)
地位: 神经仿真领域的“性能怪兽”,将 3D 高斯喷溅(3DGS)引入自动驾驶,解决了 UniSim 渲染慢、长场景难扩展的工业落地难题。
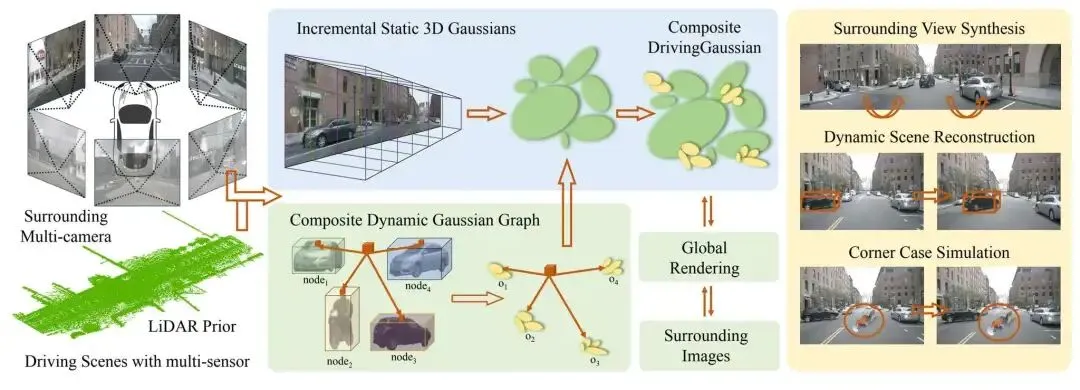 方法总体流程图
方法总体流程图- 输入端(左): 接收多传感器序列数据,包括多路摄像头图像与 LiDAR 点云。LiDAR 提供的精确深度信息是高斯球(Gaussians)初始化的关键先验。
- 核心层(中)—— 复合高斯喷溅(Composite GS):
- 静态背景重构: 采用增量式策略,随着车辆行驶不断扩展背景地图,解决长距离场景的内存溢出问题。
- 动态物体建模: 使用高斯图(Gaussian Graph)为每个 Agent(车/人)创建独立的表征,并根据物体的运动轨迹将其动态、无缝地整合进场景中。
- 输出端(右): 不仅能生成照片级的视频,还支持深度图生成、LiDAR 点云合成以及感知算法的闭环评估,展现了极强的泛化性能。
DrivingGaussian 的核心笔记:
- 实时交互性: 真正的“所见即所得”。自车或 NPC 的任何动作,画面都会在毫秒级时间内做出响应,支撑大规模端到端模型的训练。
- 高保真长序列: 解决了传统方法在长距离驾驶中显存爆炸的问题,能够重构连贯、稳定的超长动态视频。
- 本质贡献: 将 3DGS 范式 确立为自动驾驶仿真的新底座。证明了:不需要昂贵的体渲染,仅靠点云喷溅就能生成照片级的闭环训练环境。
Drive&Gen@Waymo&DeepMind(2025/10)
标题:Drive&Gen: Blank-Canvas Video Generation for Autonomous Driving
链接: https://arxiv.org/abs/2403.14602 (CVPR 2024)
地位: 自动驾驶“生成式仿真”的里程碑,将扩散模型从单纯的“画图”升级为具备物理约束的“驾驶场景模拟器”。

不需要特定的原始视频,只要给它一张矢量草图(布局),它就能凭空“幻觉”出照片级的环视视频。
实现了条件可控性。通过修改输入指令,可以瞬间将同样的交通流切换为暴雨、深夜或大雾模式,极大地覆盖了自动驾驶的“长尾场景”。
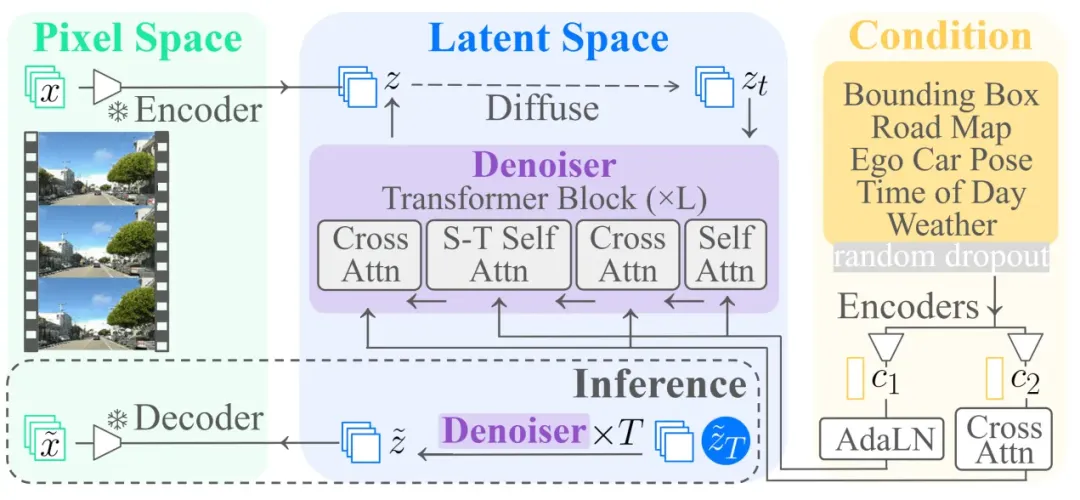 模型架构
模型架构- 模型基于潜在视频扩散模型 W.A.L.T 进行扩展。
- 场景与交通布局:目标边界框(bounding boxes)、道路地图(road map)和自车位姿(ego car pose);
- 运行环境条件:一天中的时间(time-of-day)和天气(weather)。
- 条件信息经过编码后,通过 AdaLN(Adaptive Layer Normalization) 与 交叉注意力(cross attention)机制,与扩散 Transformer 中的中间特征进行交互。
Drive&Gen 的核心笔记:
- 逻辑驱动: 视频中的每一帧都受自车位姿(Ego-motion)和交通布局的严格约束,而非漫无目的的像素堆砌。
- 数据闭环: 首次提出了用端到端规划器(Planner)的反应来评估生成视频的质量,如果 AI 规划器在合成视频里开得跟真的一样,说明仿真成功。
- 本质贡献: 摆脱了对“历史视频”重构的依赖,开启了“布局指令 传感器数据”的直接生成路径,是构建“驾驶世界模型”的关键一步。
结合驾驶(Drive)和生成(Gen),以 E2E 规划器为‘考官’评测生成的真实性,以可控生成模型为‘教练’创造极限场景,实现仿真与规划器的双向进化。
小结
| 技术名称 | 核心范式 | 核心贡献 / 解决的问题 | 关键词 |
|---|
| SimNet | | 利用机器学习取代手写规则,让 NPC 具备博弈能力。 | |
| UniSim | | 首次实现录制视频到数字孪生的转换,支持“编辑”场景。 | |
| DrivingGaussian | | 引入 3D 高斯泼溅,解决 NeRF 渲染慢的问题。 | |
| Drive&Gen | | 基于布局控制(Layout)凭空生成视频,无需原始录像。 | |
数据飞轮
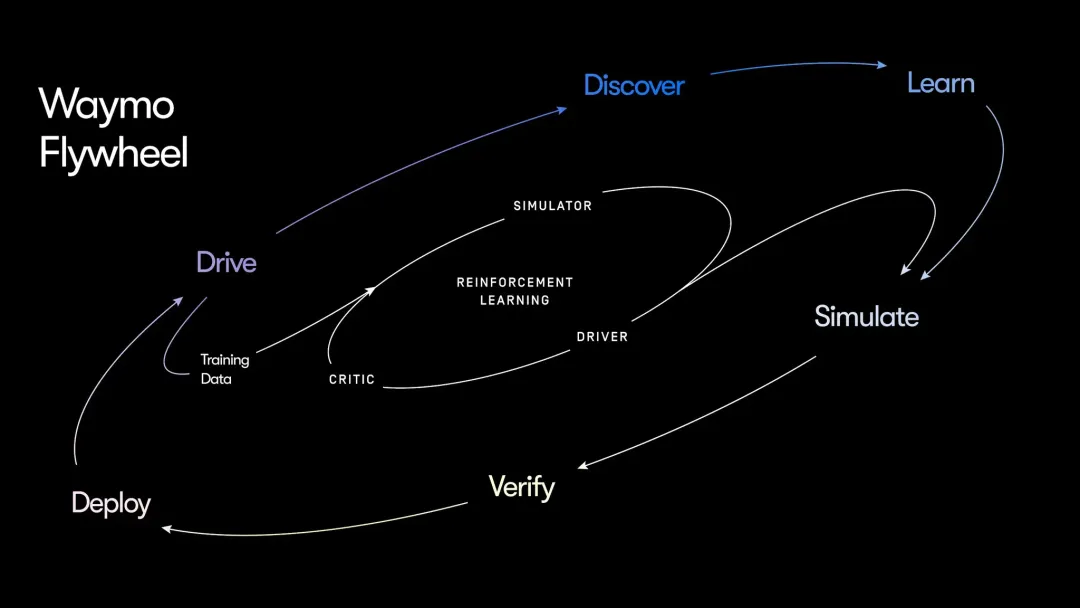 via waymo blog
via waymo blog1. 双环驱动的学习架构
- 内环:仿真强化学习 (Virtual RL Loop)
- 核心: 仿真器 (Simulator) + 评估者 (Critic)。
- 逻辑: 在受控的虚拟环境中,系统通过强化学习进行自我博弈,根据行为反馈(奖励/惩罚)快速积累驾驶经验。
- 外环:现实世界进化 (Real-world Evolution Loop)
- 自动标注: “评估者”自动识别全无人驾驶过程中的次优行为。
- 策略优化: 针对问题生成“替代行为”作为训练数据,在仿真中严苛测试。
- 安全验证: 验证修复后,经安全框架评估无误,再回传部署至现实车队。
2. 范式转移:从“模仿人”到“自我超越”
- 数据脱钩: 摆脱对高质量人工驾驶数据的依赖。目前 Waymo 的全无人驾驶里程已远超人工采集量。
- 独特优势: 仿真和人工驾驶无法完全复现系统在“独立掌控车辆”时的极端状况。直接利用无人驾驶经验学习,是系统实现指数级增长的关键。
规模化:2026 关键年
扩张
Waymo 正在从“硅谷的昂贵玩具”变成“普适的公共设施”。
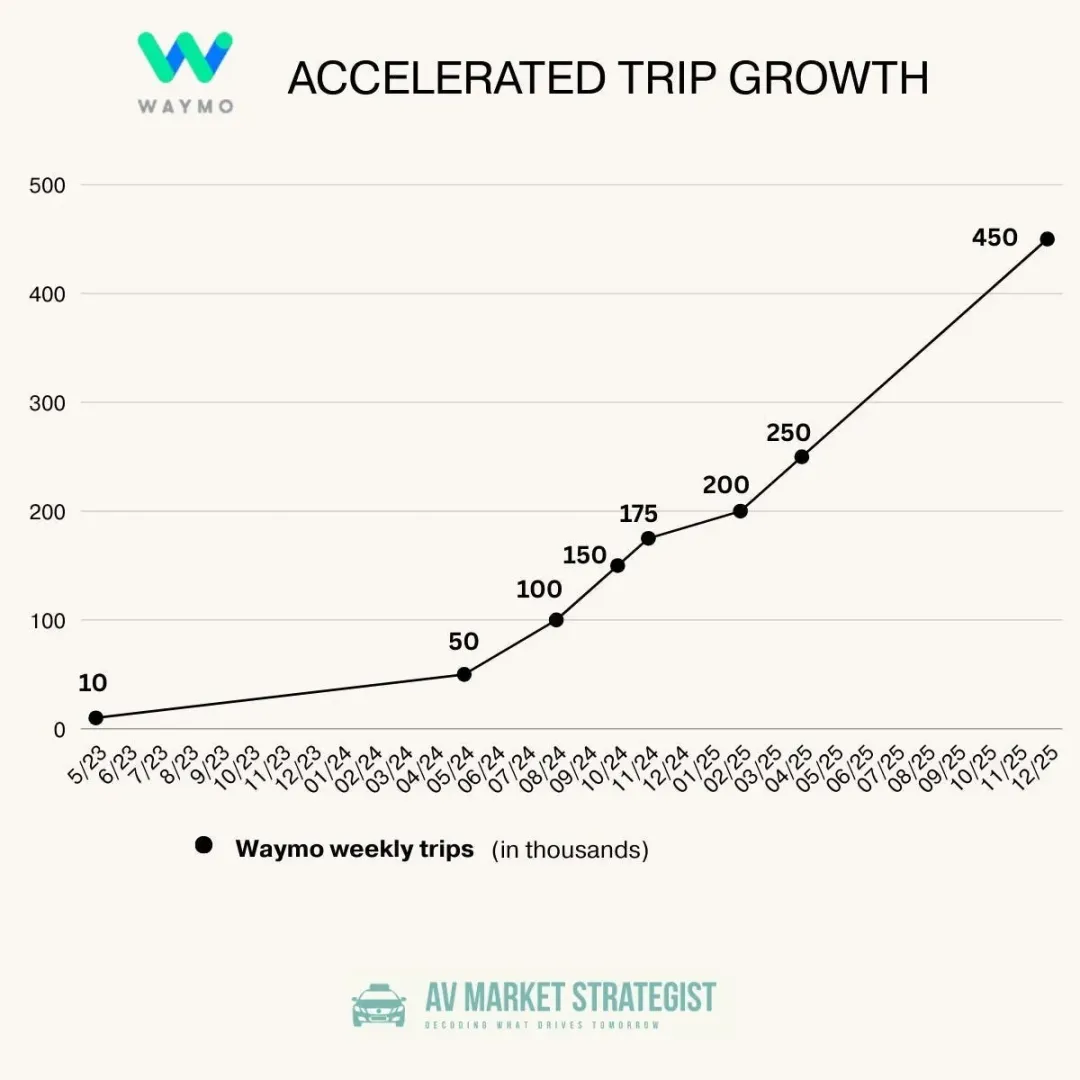
订单量实现指数级跨越:
- 2026 目标: 随着运营效率提升,预计每周订单量将冲刺 100 万次。
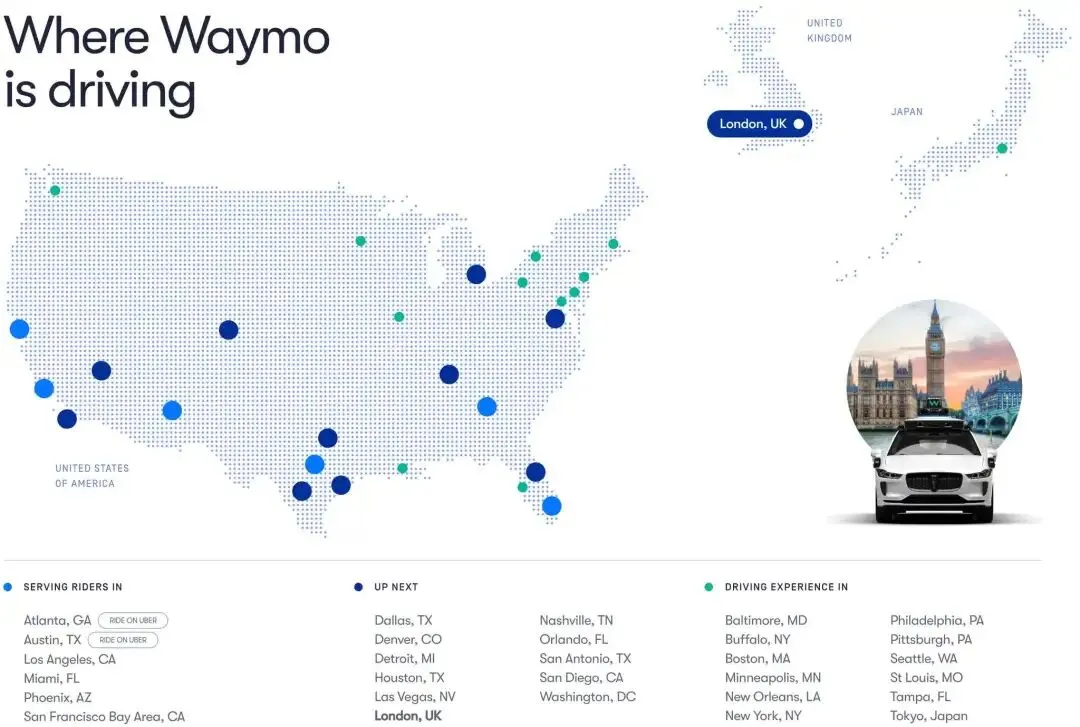
- 深耕核心存量市场: 在旧金山、洛杉矶和菲尼克斯,Waymo 已深度融入城市脉络,接近 1/6 的当地乘客依赖Waymo通勤。
- Waymo 将在 2026 年把全无人商业化版图扩张至全美至少 12 座核心城市。
- 核心竞争力: 依托 WFM(基础模型) 的强大泛化能力,Waymo 实现了“零样本/少样本”快速开城,新城市从地图部署到无人商业化上线的周期大幅缩短。
- 全球化战略启航:针对英国(右舵驾驶、狭窄街道)及日本(高密度交互、复杂标志)的特殊环境进行针对性适配训练。
- 场景解锁: 重点攻克机场接驳与高速航段,打通城市出行的“最后一块拼图”。
- Waymo for Business:2025 年 9 月发布,全面对接企业差旅、酒店接送等需求,转向 B/C 端双轮驱动。
安全第一
安全是规模化的前提。
社会对无人驾驶的容错率远低于人类司机,因此必须建立比人类更稳健的防御性驾驶习惯。
真正的护城河在于如何处理那些发生概率极低但危险程度极高的极端情况。
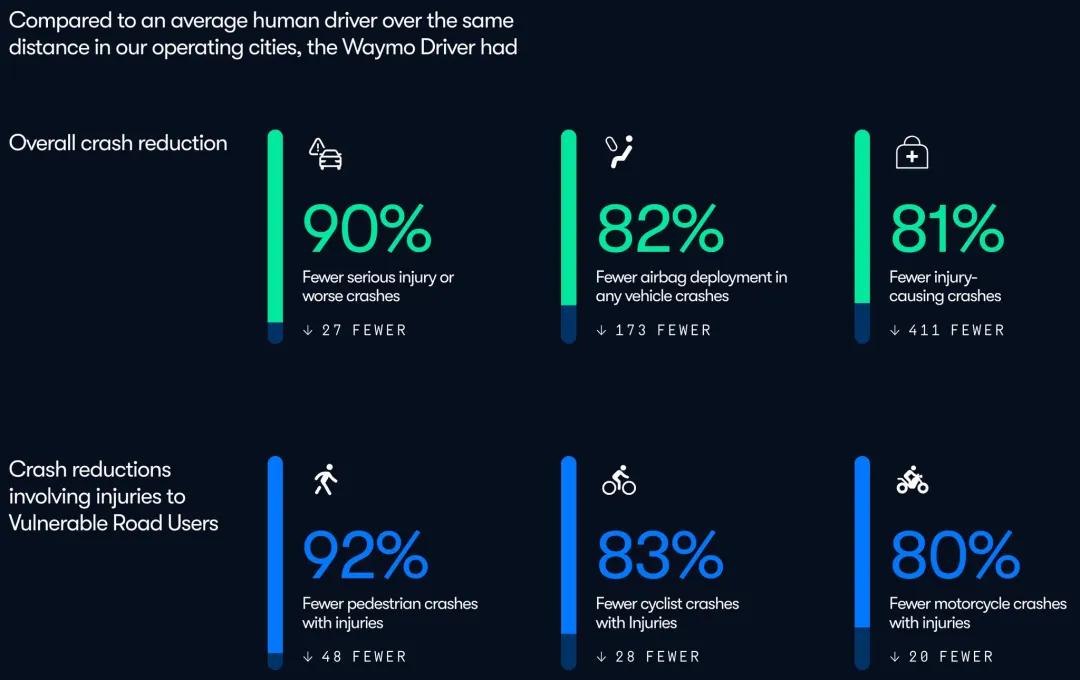
- “超人级”安全数据: 截至 2026 年初,Waymo 全无人驾驶里程已超 1 亿英里。数据显示,其**重伤事故率比人类驾驶员低约 90%**,财产损失赔付率降低 76%。这种显著优于人类驾驶员的安全性,是其获得监管信任与公众信誉的基石。
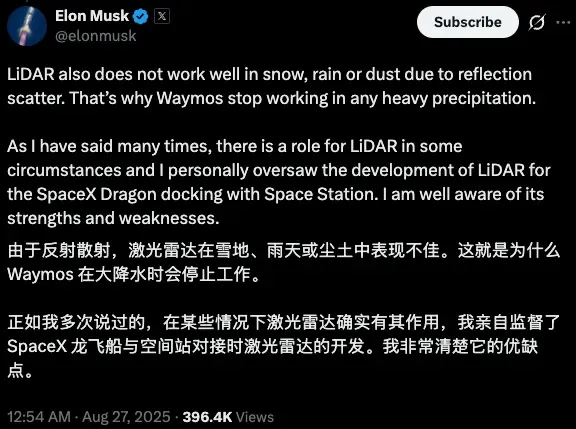
- 多感知冗余的物理护城河: 坚持激光雷达(LiDAR)+ 毫米波雷达 + 摄像头 + 地图 + 远程辅助的融合方案。这种冗余机制能有效消除 AI 在纯视觉方案下可能产生的“幻觉”——当摄像头受光照或语义干扰失效时,主动传感器能提供确定性的物理反馈。
- 结构化端到端 AI 架构: 与黑盒式端到端不同,Waymo 坚持保留 3D 障碍物列表和地图语义等中间层表征。这种架构确保了系统的可解释性与可修复性:一旦发生长尾异常,工程师能精确定位失效模块并进行定向修复,而非重新训练整个模型。
- 全天候硬件加固(中东的高温/沙尘以及北美的冰雪气候):
- 自清洁系统: 每个传感器都配有自动清洁机制(喷淋、风干等),防止泥土、昆虫或霜冻遮挡视线。
- 可互换组件: 可以根据不同城市的特定环境(如寒冷地区加装加热组件)快速调整硬件配置。
降本逻辑
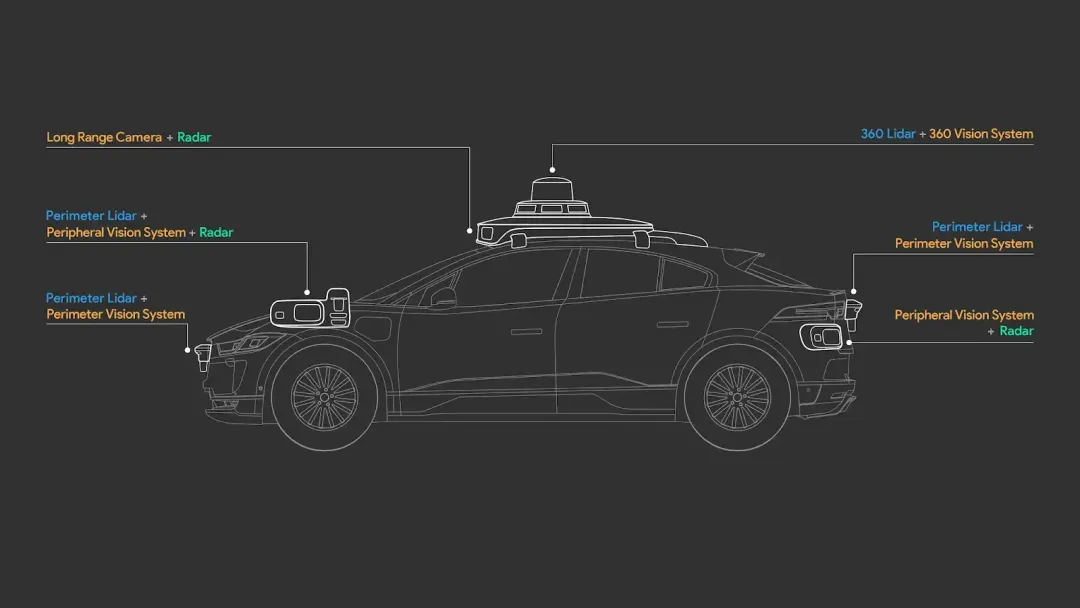
- 硬件降本与第六代系统(6th-gen): 第六代 Waymo Driver 系统通过硬件架构深度优化,在提升感知范围与分辨率的同时,大幅削减了传感器总成本。系统采用精简化的传感器布局(如减少高成本激光雷达数量),并依托中国吉利极氪(Zeekr)等供应链合作伙伴实现量产级成本控制,解决了以往单车成本过高的瓶颈。
- “City N+1” 规模效应: 随着行驶数据的指数级积累,进入新城市的工作量呈指数级下降,旧城市的长尾经验可快速迁移至新区域(如从洛杉矶到奥斯汀),使得 2026 年实现“极速开城”成为可能。
- 远程协助比率(RA Ratio)持续下降: 车队响应专家(Fleet Response)仅提供逻辑指令(如路径引导),不直接操控车辆,单人可管理的车辆规模大幅提升。
- 场站自动化(Depot Automation): 引入自动化清洁、充电与AI 预测性维护流程,降低车辆在非营运期间的人工运维开支及非营运停机时间。
- 高速航段(Freeway)解锁: 全面开放的高速权限使单次行程时间缩短高达 50%,显著提升了车辆的周转率与每日单量上限。
- 混合模式探索: 测试“高峰载人、低谷配送”模式,利用非通勤时段的闲置运力进行商业配送,确保车辆全天候产生收益。
- 全天候运行能力: 依托第六代传感器的自清洁系统和加固硬件,Waymo 实现了在暴雨、浓雾甚至轻微雪天下的持续运营,消除了因恶劣天气导致的“停工损失”。
- 动态拼车算法: 行驶路径的实时匹配,显著提升了客座率(Occupancy),同时降低了乘客的拼车成本。
- 全局路径最优: 依托车队级实时路况共享,可实现秒级避障与路径重规划,而非滞后反应,确保全城车队以最优周转率运行。
- 理赔数据成为核心财务竞争力: 极低的事故率直接转化为极低的商业保险成本,成为降本增效的隐形利器。
2026 年的 Waymo 正在完成一次“惊险的跳跃”:通过规模与效率摊薄成本。如果说过去十年是自动驾驶的“资格赛”,2026 年则是“决赛圈”。
社会契约
 Uber 和 Lyft 司机抗议@旧金山加州公共事业委员会总部 2026/01/09
Uber 和 Lyft 司机抗议@旧金山加州公共事业委员会总部 2026/01/09在 2026 年的扩张进程中,Waymo 不仅在输出技术,更在通过建立一种全新的“社会契约”来化解 AI 落地过程中的结构性矛盾。
- 应对失业与劳动力转型: 面对“机器人抢饭碗”的社会敏感点,采取“增量补位”策略,化解失业敏感性。
- 岗位创造: 随着规模化,Waymo 在场站运维、远程协助(RA)、传感器标定等领域创造了数以万计的新岗位。
- 技能转型: 与社区学院合作推动传统汽修工向 AI 运维转型。
- 运力补盲: 强调 Robotaxi 优先覆盖凌晨、极端天气及公共交通荒漠等人类司机出车意愿低的“疲劳时段”,实现与传统运力的错位竞争。
- 监管透明化: 与当地警方、消防部门共享安全数据和应急接管协议。
- 本地化沟通: 在进入每个新社区前,通过大量线下体验日和反馈机制,让当地居民参与定义车辆的行驶偏好(如避开特定学校区域)。
- 解锁“银发族”的社交自由: 自动驾驶对社会最大的贡献在于恢复了弱势群体的行动力。数据表明,65 岁以上老人在体验无人驾驶后,其出门社交意愿增加了 60%,极大缓解了老龄化社会的孤独感与心理健康问题。
- 差异化体验的溢价: 提供人类司机无法提供的“绝对隐私”与“零压力空间”。
- 极致安全感: 杜绝了酒驾、疲劳驾驶或不当行为,尤其受到女性和深夜出行者的青睐。
- 公平驾驶: 无偏见的算法确保了所有乘客(无论种族、性别或残障情况)都能获得一致的高标准服务。
结语
Robotaxi 目前仍在发展初期,未来成长空间较大。
Waymo首席科学家 Vincent 认为自动驾驶已经经历了五代技术演进,目前已经处于“正确的时代”,现有的基础模型和世界模型技术足以支撑其走向大规模应用。
2026 年将成为 Waymo 商业版图的“质变点”,是走向全球和全地形(包括雪地和左侧驾驶城市)的关键一年。