自动驾驶学术之星 | 清华AIR赵昊团队2025年工作盘点
- 2026-02-19 00:37:22

点击下方卡片,关注“自动驾驶之心”公众号
编辑 | 自动驾驶之心
本文只做学术分享,如有侵权,联系删文
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
写在前面
在自动驾驶这股奔涌的浪潮中,中国研究者正扮演着越来越重要的角色。每所高校、每个实验室都有自己的“独门秘籍”——有的深耕感知,有的擅长端到端,有的专攻仿真。
最近刚好有想要申请硕博的同学联系自动驾驶之心,想要我们帮忙整理介绍一下国内有哪些知名的实验室,以及他们的研究重点是什么。
为了帮大家更清晰地了解国内自动驾驶领域的学术版图,自动驾驶之心特别推出『学界之星』系列,带你走近那些正在悄悄改变行业的高校教授们。无论你是正在择业、规划研究方向,还是考虑申请硕博,希望这些分享能给你一点启发。
今天柱哥要介绍的,是清华大学智能产业研究院(AIR)的赵昊教授。

赵昊老师是地地道道的“清华系”:本科到博士都在清华电子系度过,之后在英特尔中国研究院做过研究,北大联合博士后,最终回到母校AIR,成为一名年轻的助理教授。他身上有种典型的“技术理想主义”——既痴迷于几何与认知层面的场景理解,琢磨机器如何像人一样“看懂”世界;也乐于动手实践,早年创办了清华最大的学生机器人社团“天空工场”,还参与孵化了十多家科技创业公司,把想法一点点变成现实。
他的研究聚焦在如何用AI重建和理解动态世界,比如用神经渲染快速生成逼真的驾驶场景,让自动驾驶算法在虚拟环境中高效“练级”。2025年12月,他作为组委会主席亮相GAIR全球人工智能与机器人大会,并主持世界模型分论坛,分享团队在具身智能认知建模上的新探索。
如果你对“场景重建、生成、仿真、端到端”感兴趣,赵昊教授的工作或许正是一个值得追踪的窗口。
更多研究细节,也欢迎大家访问他的主页:https://sites.google.com/view/fromandto
本篇文章,柱哥将着重介绍2025年(也包含部分2024年底的工作)赵昊教授的一些重要研究成果。整理的时候,柱哥也发现,多数工作也都是和企业合作发表的,可以见得其研究方向并非天马行空,也正是工业界的需求。
[CVPR 2025] UniScene: Unified Occupancy-centric Driving Scene Generation
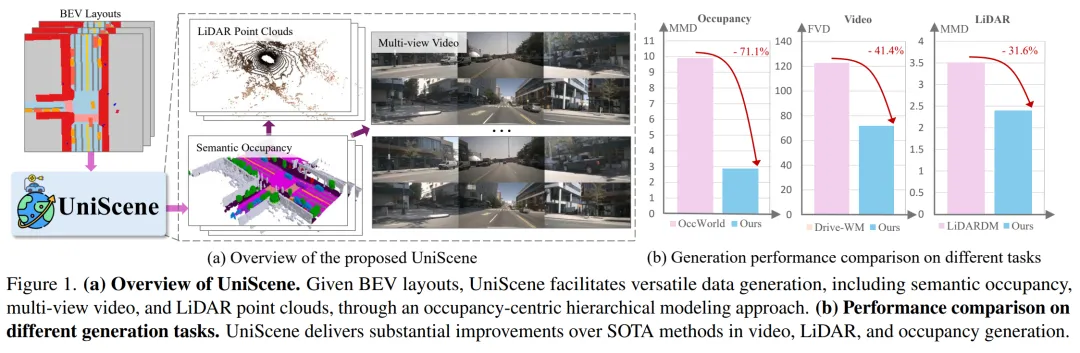
提出时间:2024.12 提出机构:清华大学智能产业研究院(AIR)、上海交通大学等 论文链接:https://arxiv.org/pdf/2412.05435
研究背景:自动驾驶系统依赖大量高质量、多模态标注数据进行训练,但真实数据采集与标注成本高昂。现有生成方法多局限于单一数据类型(如仅生成视频),且直接从粗糙的鸟瞰图(BEV)布局生成数据的效果有限,难以满足多模态感知任务的需求,也无法充分建模真实场景的复杂几何与外观分布。
论文内容:这篇工作提出的 UniScene,是首个统一的、以语义占据(Semantic Occupancy)为中心的驾驶场景生成框架,能够同时生成语义占据、多视角视频和激光雷达点云三种关键数据形式。这篇工作采用分层生成范式:
首先生成语义占据:基于输入的BEV布局序列,通过 Occupancy Diffusion Transformer 生成具有时空一致性的3D语义占据序列。语义占据富含语义与几何信息,作为中间表示为后续生成提供结构化引导。
基于上述占据生成视频与激光雷达:
视频生成:提出高斯联合渲染(Gaussian-based Joint Rendering) ,将占据转换为3D高斯基元,渲染出多视角的语义图与深度图,作为条件输入到视频扩散模型(基于Stable Video Diffusion),显著提升了生成视频的几何准确性与跨视角一致性。
激光雷达生成:提出先验引导的稀疏建模(Prior-guided Sparse Modeling) 。利用占据提供的几何先验,通过稀疏UNet和基于射线的稀疏采样策略高效生成激光雷达点云,并额外预测反射强度与射线丢弃概率,使生成结果更贴近真实传感器数据。
总结来看,这篇工作的主要创新点在于:
统一多模态生成框架:首次实现从一个框架中联合生成语义占据、视频和激光雷达点云,提供了丰富、可控且标注齐全的合成数据。 占据中心的分层生成策略:将复杂的端到端生成任务分解为“布局→占据→多模态数据”两个层次,降低了学习难度,提升了生成质量与可控性。 两种新颖的表示转换技术:1)高斯联合渲染,将3D占据高效转化为2D几何与语义引导;2)先验引导稀疏建模,利用占据先验实现高效、高保真的激光雷达生成。
作者也通过在NuScenes数据集上的实验表明,UniScene在占据生成、视频生成和激光雷达生成三项任务上均超越现有SOTA。生成的数据能有效提升下游任务的性能。
[ICRA 2025] AVD2: Accident Video Diffusion for Accident Video Description
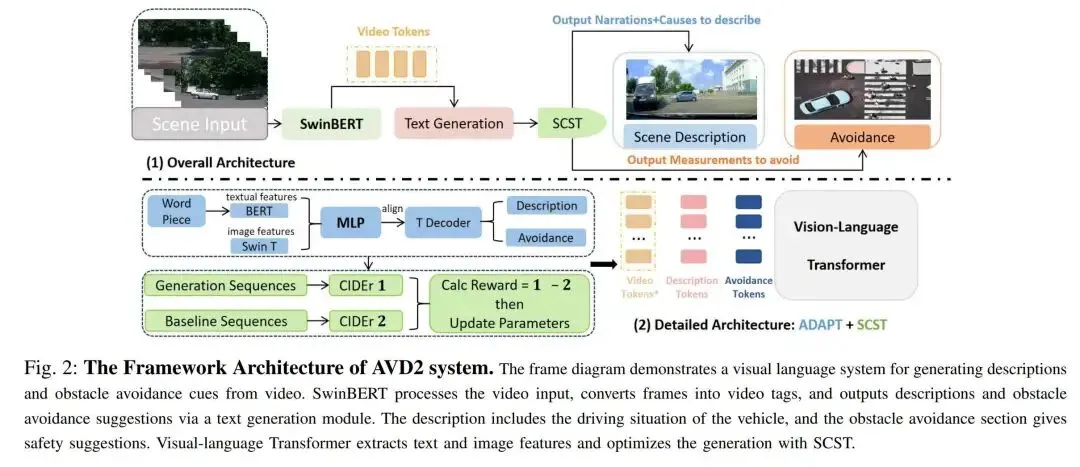
提出时间:2025.02 提出机构:清华大学智能产业研究院(AIR)、港科大、吉林大学等 论文链接:https://arxiv.org/pdf/2503.15208 项目链接:https://an-answer-tree.github.io/
研究背景:自动驾驶系统在事故场景下面临理解与响应挑战,现有方法因缺乏专门的事故训练数据,难以深入分析事故原因并提供有效预防措施。视频问答等方法虽能部分解答事故相关疑问,但在处理复杂多变的真实事故场景时仍显不足,这就需要能生成高质量事故视频并支持深入推理的数据与方法。
论文内容: 为了解决上述痛点,这篇工作提出了 AVD2 框架,主要由两个核心部分组成:
视频生成流水线:基于开源的 Open-Sora 1.2 文本-视频生成模型,使用原始MM-AU数据集的“描述”和“避障”文本进行微调,专门生成高保真度的交通事故视频。同时,采用Real-ESRGAN技术对生成视频进行超分辨率增强,以提升视觉质量。
事故分析系统:以ADAPT模型为视觉语言理解基础,并引入自临界序列训练(SCST) 进行优化。该系统能够对输入的视频自动生成两部分内容:一是对事故过程的描述(D),包括动作与原因;二是具体的避障建议(A)。
主要创新点可以总结为以下三个部分:
首次提出将可控事故视频生成与深度事故分析相结合的统一框架(AVD2),实现了从文本描述生成视频,再从视频反推分析与预防的闭环。 构建了首个基于生成式AI增强的驾驶事故视频理解数据集EMM-AU,为解决事故数据稀缺问题提供了新范式。 将SCST强化学习策略成功应用于驾驶场景描述生成,显著提升了输出文本的准确性、相关性和可操作性,为自动驾驶系统的可解释性与安全性设立了新基准。
作者通过实验证明,使用该框架和数据集训练的模型,在描述事故和提供避障建议的任务上,其性能全面超越了之前最好的专业模型(如ADAPT)和通用大模型(如ChatGPT-4o)。
[ICCV 2025] DiST-4D: Disentangled Spatiotemporal Diffusion with Metric Depth for 4D Driving Scene Generation
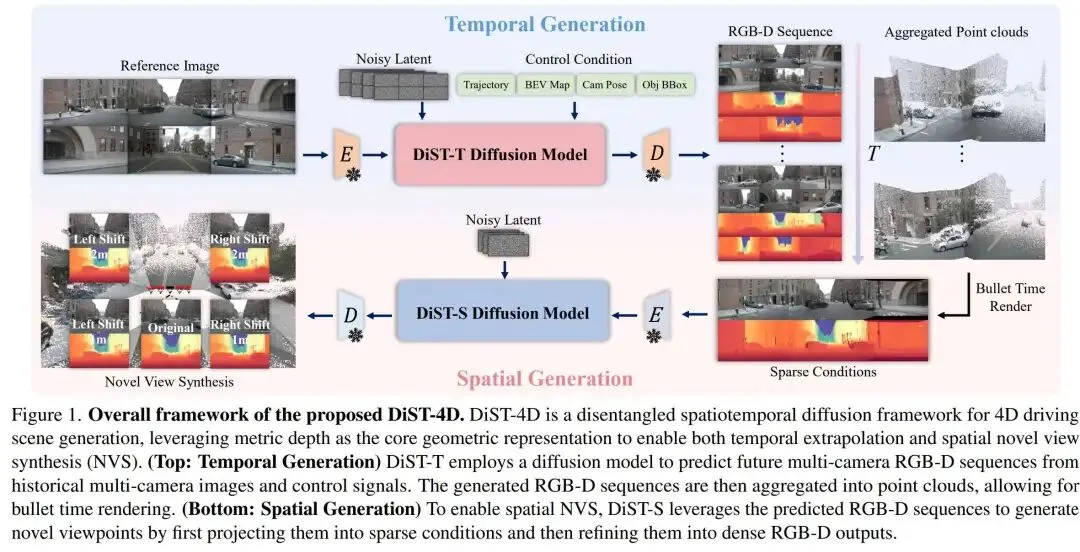
提出时间:2025.03 提出机构:清华大学智能产业研究院(AIR)、旷视等 论文链接:https://arxiv.org/pdf/2503.15208
研究背景:当前自动驾驶场景生成方法存在明显局限:一些方法能生成未来时序视频但无法合成新视角;另一些虽能进行新视角合成(NVS),但依赖逐场景优化,效率低下;还有部分前馈方法虽快却缺乏时序外推能力。因此,现有方法难以同时实现时序外推与空间新视角合成,限制了其在自动驾驶仿真与数据生成中的规模化应用。
论文内容: 本文提出 DiST-4D,是首个无需逐场景优化、能同时实现时序预测与空间新视角合成的4D驾驶场景生成框架。其核心创新在于使用度量深度作为连接时序与空间的几何表征,并采用解耦的时空扩散建模策略:
提出以每帧度量深度作为统一几何表征,既支持高保真新视角合成,又易于生成模型学习,从而有效连接时空生成任务。设计了一套多视角度量深度标注流水线,融合LiDAR点云、多视角立体视觉(MVS)重建与深度补全网络,生成高质量深度真值,为模型训练提供可靠监督。
提出了双分支解耦扩散模型
DiST-T(时序分支):基于历史多视角图像与控制信号(如轨迹、BEV地图),通过扩散Transformer(STDiT)生成未来多视角RGB视频与深度序列。
DiST-S(空间分支):以DiST-T生成的RGB-D序列为条件,通过投影获取稀疏视角条件,再经扩散模型合成任意新视角的密集RGB-D输出。
自监督循环一致性(SCC):该策略是针对真实轨迹多样性不足的问题,提出来的:随机生成新轨迹,用DiST-S合成对应RGB-D,再投影回原视角构建自监督训练对,显著提升了模型对分布外视角的泛化能力。
作者在nuScenes数据集上,DiST-4D在时序视频生成(FID/FVD指标)和空间新视角合成质量上均达到最优。生成的数据在下游感知与规划任务中表现出接近真实数据的性能。
[NeurIPS 2025] Impromptu VLA: Open Weights and Open Data for Driving Vision-Language-Action Models
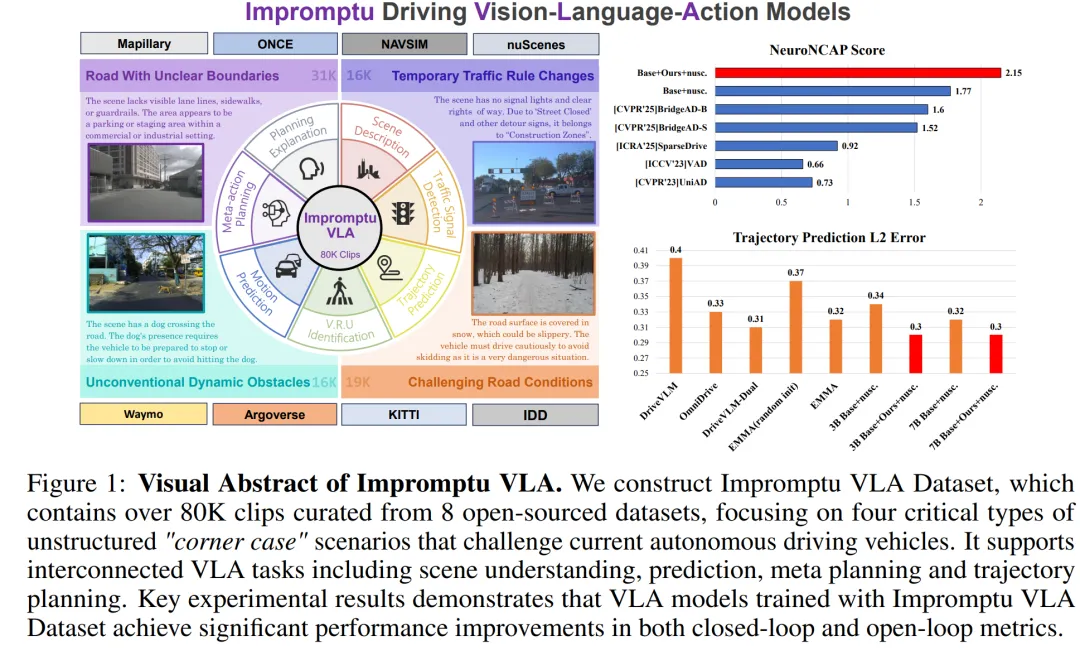
提出时间:2025.05 提出机构:清华大学智能产业研究院(AIR)、Bosch Research 等 论文链接:https://arxiv.org/pdf/2512.03004 项目链接:https://impromptu-vla.c7w.tech/
研究背景:自动驾驶在结构化环境中进展显著,但在非结构化道路(如乡村道路、施工区域、恶劣天气等)中仍面临严峻挑战。现有数据集大多聚焦于常见结构化场景,缺乏针对复杂、非常规驾驶场景的大规模、高质量标注数据,限制了视觉-语言-动作模型在真实复杂环境中的泛化与决策能力。
论文内容: 本文的核心贡献是提出了 Impromptu VLA 数据集,旨在解决自动驾驶在非结构化场景下的数据稀缺问题。其主要创新点包括:
构建了首个专注于非结构化驾驶场景的大规模多任务数据集:从8个开源数据集中精选并标注了约8万个视频片段,覆盖四类挑战性场景(道路边界模糊、临时交通规则变化、非常规动态障碍物、恶劣路况与环境)。
提出了系统化的场景分类体系与自动化标注流程:基于视觉语言模型的思维链推理能力,结合人工校验,实现了对复杂场景的高效、可靠分类与丰富标注(包括场景描述、信号检测、轨迹预测、元动作规划等)。
数据集的格式设计以规划任务为导向:标注以问答对形式组织,紧密关联视觉输入与决策输出,可直接用于训练和评估VLA模型的感知、预测和规划能力。
作者也通过实验证明,使用该数据集训练的模型在闭环安全测试和开环轨迹预测等基准上均取得了显著性能提升,证明了其在增强模型应对复杂现实场景能力方面的有效性和价值。
值得一提的是,该数据集已开源,为之后业界和学术界的 VLA 发展提供了数据支持。
[IASEAI 2026] Challenger: Affordable Adversarial Driving Video Generation

提出时间:2025.05 提出机构:清华大学智能产业研究院(AIR)、吉利、上交等 论文链接:https://arxiv.org/pdf/2505.15880
研究背景:在自动驾驶领域,评估系统的鲁棒性和安全性是至关重要的。然而,现有的大规模自动驾驶数据集,如nuScenes、OpenScene等,主要包含自然交通流,缺乏刻意设计的具有挑战性的交互场景。这些数据集难以系统地评估自动驾驶系统在罕见但高风险事件下的表现。为了解决这一问题,先前工作已提出多种对抗性场景生成方法,但这些方法大多基于抽象的轨迹或鸟瞰图(BEV)表示,无法提供逼真的传感器数据来真正测试端到端自动驾驶系统(end-to-end autonomous driving system)的极限。另有部分方法(如NeuroNCAP等)需要大量人力手动设计对抗性场景,或需要大量计算资源,难以实现复杂多样对抗性测试场景的批量生成。因此,如何自动、低开销地生成多样化、物理合理且逼真的对抗性驾驶视频,成为自动驾驶评估领域的一个重要空白。
论文内容: 这篇工作提出的Challenger框架能够生成物理合理且逼真的对抗性驾驶视频。该框架通过结合基于扩散模型的轨迹生成器、物理感知规划模拟器和多视图神经渲染器,实现了基于真实驾驶场景自主生成对抗性驾驶场景。
该项工作的核心贡献包括:
提出对抗性驾驶视频生成任务:为提升自动驾驶系统的安全性和可靠性评估效率,作者首次提出对抗性驾驶视频生成任务,并开发了统一框架Challenger。该框架通过多轮物理感知轨迹优化和渲染兼容的对抗性评分,实现了低成本的对抗性视频生成。 在nuScenes数据集上验证有效性:在nuScenes数据集上,Challenger成功生成了涵盖加塞、尾随、阻挡等多种对抗性驾驶行为的多样化且逼真的视频。这些视频覆盖了包括十字路口、环形交叉路口以及停车场等在内的多种动态交通场景。 显著降低先进自动驾驶模型性能并揭示可转移的失败模式:Challenger生成的视频使当前最先进的自动驾驶模型(如UniAD、VAD、SparseDrive和DiffusionDrive)的性能显著下降,并揭示了这些模型之间可转移的失败模式,为研究人员提供了深入了解模型脆弱性的机会。
Challenger实现了多视角、高保真对抗驾驶视频的自动化生成,在其生成的高挑战性数据集上验证显示,主流端到端模型碰撞率最高提升26.1倍!
[IROS 2025] PosePilot: Steering Camera Pose for Generative World Models with Self-supervised Depth
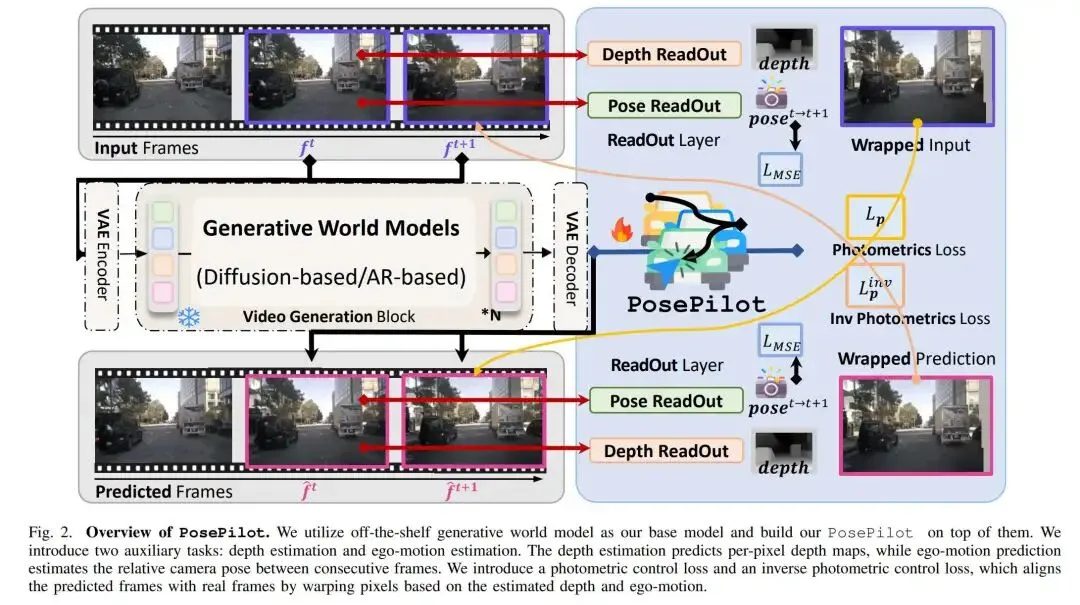
提出时间:2025.05 提出机构:清华大学智能产业研究院(AIR)、港科大、理想汽车等 论文链接:https://arxiv.org/pdf/2505.01729
研究背景:生成式世界模型在自动驾驶中展现出仿真与预测潜力,但现有方法对相机位姿的控制仍显不足,尤其是在理解场景结构与运动之间的几何关系方面。多数方法通过可学习的注意力机制引入位姿控制,缺乏对相机运动与场景演化之间内在联系的深入建模,导致位姿控制的精度与一致性受限。
论文内容: 这篇工作提出的 PosePilot,是一种轻量级、即插即用的相机位姿控制增强模块,可无缝集成到各类生成式世界模型(如扩散模型、自回归模型)中,显著提升模型对相机位姿的精确控制能力。其核心思想是利用自监督深度估计与运动恢复结构原理,建立相机位姿与视频生成之间的几何一致性约束。
使用了自监督几何监督机制:提出深度读出模块与自我运动读出模块,分别从视频序列中估计逐像素深度图与相邻帧之间的相对相机位姿。基于估计的深度与位姿,通过前向与逆向光度扭曲,将源帧扭曲至目标视角,并构建光度控制损失,强制生成视频与指定相机轨迹保持几何一致。
创新地提出了双向一致性约束与位姿回归监督
双向光度扭曲损失:不仅进行前向扭曲(从当前帧到下一帧),还引入逆向扭曲损失,将生成帧映射回原始视角,减少遮挡与动态区域带来的扭曲伪影,增强时空一致性。 位姿回归监督:对估计的相机位姿施加均方误差损失,直接约束其与真实位姿的对齐,进一步提升位姿估计的精度与稳定性。 即插即用与轻量化设计:PosePilot不改变原有世界模型的结构,仅增加约180M参数,在保持高效训练与推理的同时,显著提升位姿控制能力。
作者在 nuScene 和 RealEstate10 上验证了PosePilot的有效性。实验表明,该模块可显著降低平移误差(TransErr)与旋转误差(RotErr),提升生成视频的几何一致性与视觉质量。可以说,该工作为生成式世界模型提供了一种几何驱动、结构感知的相机控制新范式,无需复杂模态输入或结构重构,即可实现精准、一致的视角合成。
[IROS 2025] SparseMeXt: Unlocking the Potential of Sparse Representations for HD Map Construction
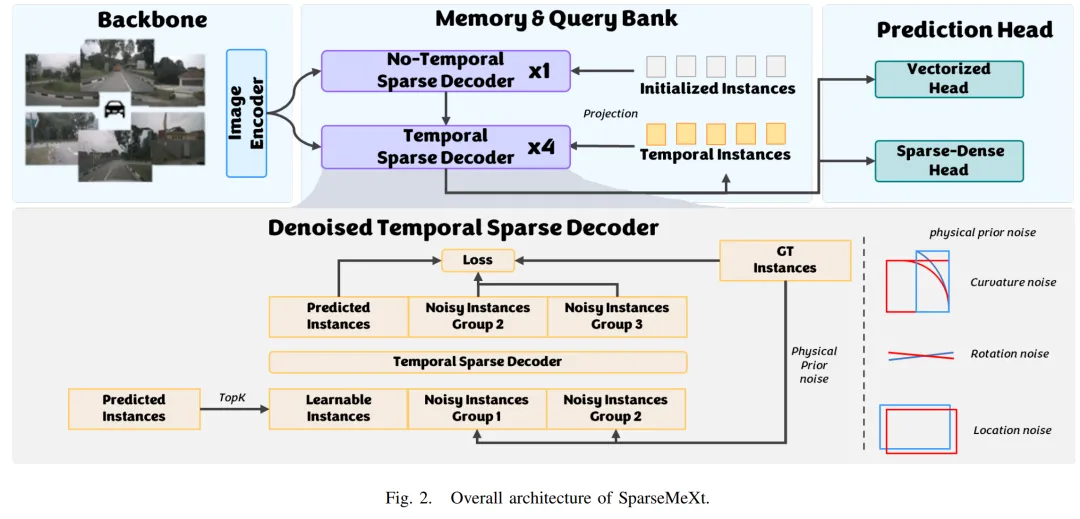
提出时间:2025.05 提出机构:清华大学智能产业研究院(AIR)、博世等 论文链接:https://arxiv.org/pdf/2505.08808
研究背景:在线高精地图(HD Map)构建对自动驾驶至关重要。现有主流方法依赖密集的鸟瞰图表示,计算开销巨大,限制了其在资源受限设备上的部署。虽然稀疏表示作为一种高效替代方案被提出,但现有稀疏方法(如SparseDrive)直接沿用为3D目标检测设计的架构,缺少针对地图构建任务的专门优化,导致其性能显著落后于密集方法,难以满足高精度与高效率的双重需求。
论文内容: 本文提出了 SparseMeXt,一个专为稀疏表示范式优化的在线高精地图构建框架,首次实现了稀疏方法在精度上全面超越密集方法:
针对地图任务优化的网络架构:重新设计图像编码器颈:摒弃了为多尺度目标检测设计的MiMo(多进多出)特征金字塔网络,采用单进多出(SiMo) 结构。该结构仅使用最高层特征,更适配地图要素在图像中通常占据大区域的特点,带来了显著的精度提升。优化解码器阶段配比:针对地图要素类别少、几何位置时不变性强的特性,调整了时序与非时序解码器的阶段数量,避免了参数冗余与过拟合。任务解耦的特征聚合:提出解耦可变形特征聚合模块,为分类和回归任务分别构建独立的特征采样点,从特征空间层面解决了两者冲突,提升了检测精度。
稀疏-密集辅助分割监督:为弥补稀疏架构缺乏显式BEV特征网格、从而丢失全局上下文信息的缺陷,提出一种查询中心的辅助分割任务。该方法将稀疏的实例特征转换为密集的BEV分割图进行监督,使网络能更好地利用语义和几何信息,且在推理阶段可完全移除,不增加额外计算开销。
基于物理先验的查询去噪:针对地图要素(如车道线)的曲线数据结构,传统为边界框设计的加噪策略效果不佳。提出物理先验查询去噪策略,设计了四种符合地图要素几何特性的噪声模式:旋转、平移、缩放和曲率噪声。通过约束噪声符合物理规律,显著提升了去噪训练的效果和模型收敛稳定性。
这篇工作首次证明了稀疏范式在高精地图构建任务上可以全面超越密集范式,为在边缘计算平台部署高性能在线地图构建系统提供了新的、高效的解决方案,重新定义了该领域的效率-性能权衡。
[NeurIPS 2025] Unifying Appearance Codes and Bilateral Grids for Driving Scene Gaussian Splatting
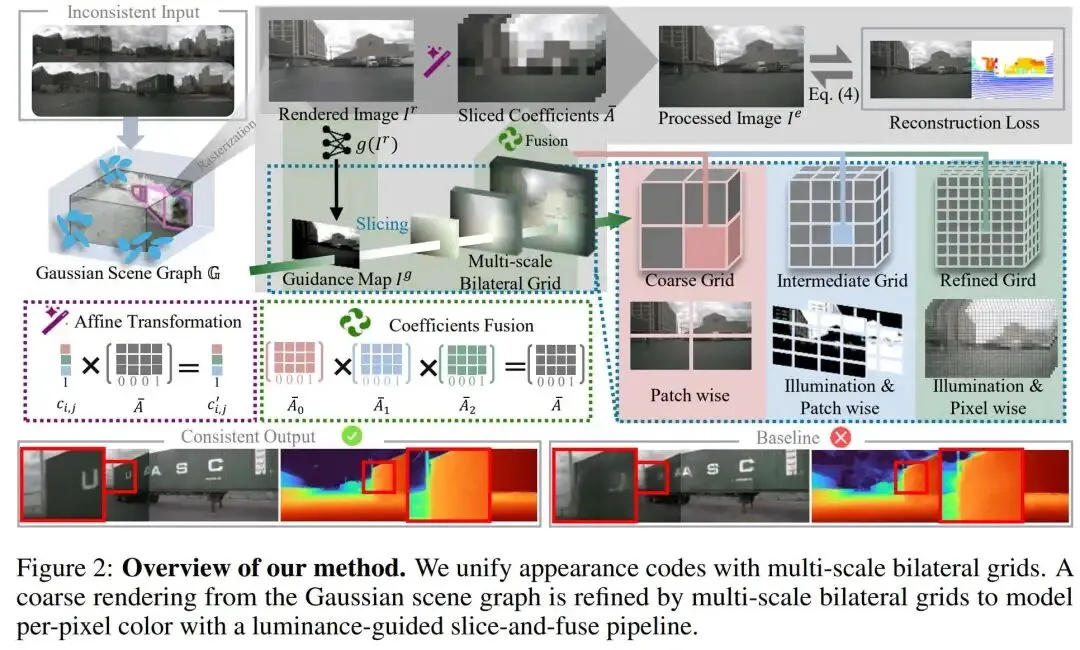
提出时间:2025.06 提出机构:北京智源人工智能研究院、清华大学智能产业研究院(AIR)、上海交通大学等 论文链接:https://arxiv.org/pdf/2506.05280
研究背景:神经渲染技术(如NeRF与高斯溅射)依赖光度一致性实现高质量三维重建,但在真实驾驶场景中,因光照、视角与相机设置的动态变化,难以保证图像间的一致性。现有方法如全局外观代码建模能力有限,而像素级双边网格又面临优化困难,导致几何重建精度下降,影响自动驾驶的障碍物感知与路径规划。
论文内容: 为了解决上述问题。这篇工作:
提出统一的多尺度双边网格框架:创新性地将全局外观代码与像素级双边网格融合,构建了一个三层(粗、中、细)的层次化架构。粗网格类似一个“增强版外观编码”,负责捕捉全局光照基调;细网格则继承双边网格的优势,在局部进行像素级微调;中等网格作为桥梁,处理区域级变化。这种“从粗到细”的层次结构,使模型能够自适应地学习从全局到局部的全方位光度校正。该框架能根据场景需求,自适应地在全局校正与局部精细调整之间切换,从根本上解决了单一方法建模能力有限或优化困难的问题。
通过高级外观建模显著提升几何精度:首次明确并验证了复杂光度不一致性是导致动态驾驶场景重建中产生几何伪影(如“漂浮物”)的关键原因。所提方法通过精确的光度校正,有效消除了纹理-几何歧义,从而实现了更干净、更精确的三维几何重建。
在多个权威数据集上实现全面超越:在Waymo、NuScenes、Argoverse和PandaSet四个主流自动驾驶数据集上进行了广泛验证,证明了方法的泛化能力和优越性。
通俗来说,这样的三层架构,就是为了层层递进的修图,不仅让生成的图片更逼真,也可以让模型摆脱光影干扰,摸清了物体的真实三维轮廓,从而构建出更真实的场景。
[ICCV 2025] GS-Occ3D: Scaling Vision-only Occupancy Reconstruction for Autonomous Driving with Gaussian Splatting
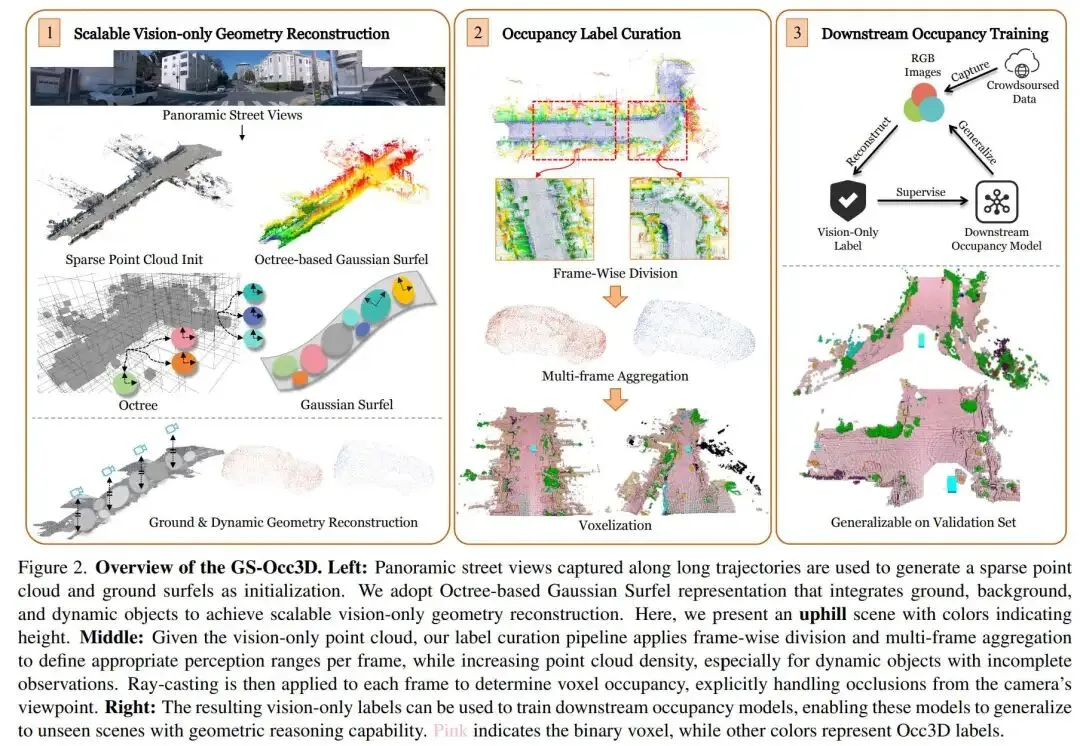
提出时间:2025.07 提出机构:清华大学智能产业研究院(AIR)等 论文链接:https://arxiv.org/pdf/2507.19451
研究背景:现有自动驾驶中的三维占据重建方法主要依赖激光雷达标注,成本高、扩展性差。纯视觉方法虽可利用海量众包数据,但因视角稀疏、动态物体、严重遮挡和长距离运动等问题,重建质量受限。现有视觉方法多基于网格表示,存在几何不完整、后处理复杂等问题,难以支持大规模自动标注。因此,需要一种高效、可扩展的纯视觉占据重建方法。
论文内容: 这篇工作提出了GS-Occ3D,一个为了解决纯视觉、可扩展三维占据重建核心挑战的创新框架。其核心目标是摆脱对昂贵激光雷达标注的依赖,仅利用消费级车辆采集的众包视觉数据,高效生成高质量的三维占据标签,为下游感知模型提供训练基础:
面向几何重建的八叉树高斯面元表示: 针对稀疏视角下几何先验不足的问题,GS-Occ3D 摒弃了传统以渲染为中心的网格或高斯表示,提出一种面向几何重建的八叉树层次化高斯面元表示。该结构以运动恢复结构(SfM)生成的稀疏点云为骨架,通过自适应划分的八叉树在不同尺度上管理高斯面元。
场景分解与针对性建模策略: 论文创新性地将复杂的驾驶场景解耦为三个几何特性迥异的组件进行分而治之:
静态背景: 使用上述八叉树高斯面元进行建模,确保整体场景的结构完整性。 地面: 将其作为主导结构进行显式建模。通过将相机位姿投影并辅以高度偏移与平面正则化,初始化专门的“地面高斯面元”。这一策略显著改善了在弱纹理区域(如大面积路面)的重建质量,解决了现有方法在此处的平滑或空洞问题,极大提升了大范围场景的一致性。 动态物体(车辆): 利用基于视觉的3D目标跟踪获取初始包围框和运动轨迹,并为其分配独立的高斯面元集,同时引入可学习的位姿修正。这种分离建模方式能更精准地捕获运动物体的几何与占据模式,并有效减少了因物体运动造成的遮挡伪影。 从重建到标签的完整流水线: 基于高质量几何重建,GS-Occ3D设计了一套完整的纯视觉占据标签生成流水线。首先,通过帧间划分将连续重建的场景转换为以每帧为中心的感知范围点云。其次,针对动态物体点云稀疏的问题,采用多帧聚合技术,在物体坐标系内融合跨帧点云以增加密度。最后,通过射线投射技术,从相机视角判别每个体素是“被占据”、“空闲”还是“未被观测”,显式地处理了遮挡问题,从而生成了精确可靠的二值占据标签。
作者首次使用纯视觉方法完成了整个 Waymo 数据集的重建与标签生成。实验表明,GS-Occ3D在几何重建质量上达到了SOTA,甚至在某些方面(如高楼、细杆)优于激光雷达参考。更重要的是,使用其生成的标签训练的下游占据预测模型(如CVT-Occ),在Occ3D-Waymo上取得了与基于激光雷达标签训练模型相当或略优的性能,并在Occ3D-nuScenes上展现了更优异的零样本泛化能力。
[IROS 2025] Delving into Mapping Uncertainty for Mapless Trajectory Prediction
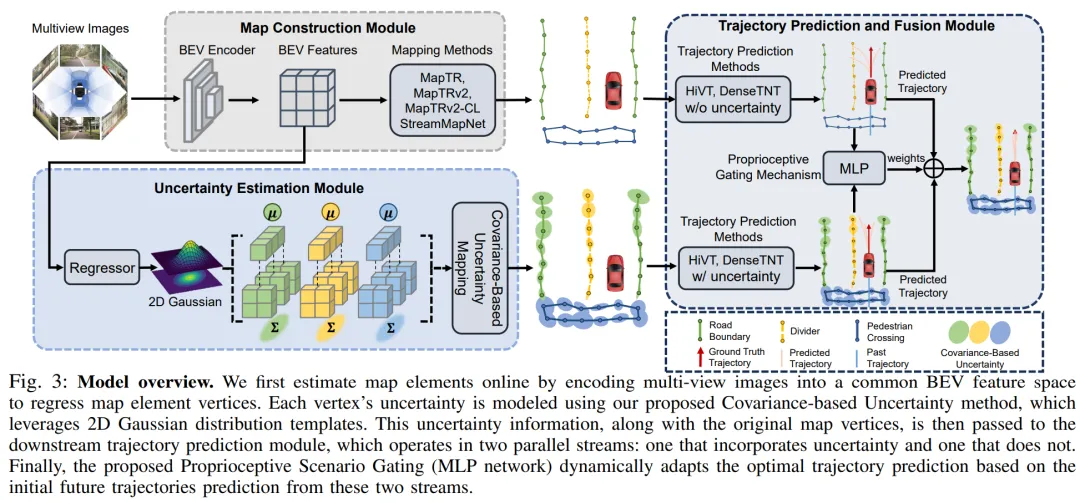
提出时间:2025.07 提出机构:清华大学智能产业研究院(AIR)、博世等 论文链接:https://arxiv.org/pdf/2507.18498 项目链接:https://github.com/Ethan-Zheng136/Map-Uncertainty-for-Trajectory-Prediction
研究背景:自动驾驶正从依赖高精地图转向在线地图生成,但由此产生的地图不确定性直接影响下游轨迹预测的可靠性。现有方法虽然尝试引入不确定性以提升预测性能,但未能深入分析不确定性在哪些驾驶场景中真正有益,也未考虑其与车辆运动状态的关联,导致性能提升有限且缺乏可解释性。
论文内容:这篇工作系统地研究了在线地图不确定性对无地图轨迹预测的影响,并提出了一个自适应整合不确定性的新框架。研究发现,地图不确定性对轨迹预测的正面作用高度依赖于车辆的动力学状态:在车辆运动状态发生剧烈变化时(如从直行转入弯道),不确定性信息能显著提升预测精度;而在运动状态稳定的场景中,引入不确定性反而可能导致性能下降。
基于这一发现,论文提出了两大核心创新:
基于协方差的地图不确定性建模:针对现有方法使用独立单变量分布建模不确定性的不足,本文提出使用二维高斯分布建模地图顶点的位置不确定性,并引入协方差矩阵来捕捉 x 和 y 方向的相关性。这种方法能更准确地描述地图元素的几何特征(如道路曲率),为下游预测任务提供更丰富、更符合几何结构的先验信息。
本体感觉场景门控机制:这是一个轻量级、自监督的即插即用模块。它通过一个双流并行结构,同时生成包含不确定性和不包含不确定性的初始轨迹预测,然后通过一个多层感知机(MLP)动态学习权重,自适应地融合两条轨迹。该门控机制仅基于车辆自身的历史和预测轨迹(即“本体感觉”信息),无需额外环境感知输入,实现了高效、实时的场景自适应决策。
作者在nuScenes数据集上的实验表明,该方法在多种地图生成模型与轨迹预测模型的组合上均取得显著提升,最高使轨迹预测误差降低23.6%,且推理速度远超基于外部感知的替代方案。
DGGT: Feedforward 4D Reconstruction of Dynamic Driving Scenes using Unposed Images
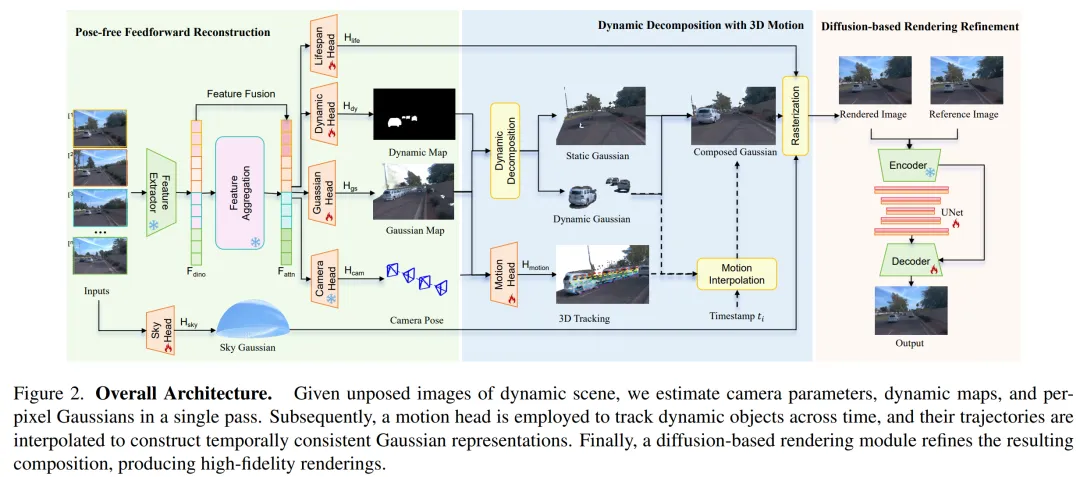
提出时间:2025.12 提出机构:清华大学智能产业研究院(AIR)、小米汽车、香港大学、北京智源人工智能研究院 论文链接:https://arxiv.org/pdf/2512.03004 项目链接:https://github.com/xiaomi-research/dggt
研究背景:自动驾驶的训练与测试离不开能够快速、批量生成的逼真虚拟场景(4D动态重建)。然而,现有主流技术严重依赖精确的相机标定数据,并且需要对每一个新场景进行长达数小时的单独计算优化。这种“手工作坊”式的流程效率极低,无法满足大规模数据驱动的研发需求。
论文内容: 这篇文章为了解决上述问题,提出了一种名为 “Driving Gaussian Grounded Transformer”(DGGT) 的框架。核心目标是:仅输入一段无需任何相机参数的行车视频片段,就能在不到一秒内自动生成一个完整的、可任意编辑的4D数字场景:
免相机姿态输入:DGGT将相机参数从“必需的输入”转变为“可预测的输出”。模型能自动估计每帧图像的拍摄位置,从而能直接处理任何来源的、未标定的视频数据,通用性极强。换句话说, 你随便拿一段行车记录仪的视频(不用知道摄像头怎么装的),扔给这个系统。它能自己反推出摄像头的拍摄角度和位置。
前馈式一次重建:采用一个统一的Transformer网络,单次前向传播即可并行预测出场景的3D结构(高斯表征)、动态物体分割、物体3D运动轨迹以及相机参数,彻底摒弃了耗时的逐场景优化。
高保真动态建模与编辑:通过创新的“生命周期”参数和动态分解技术,能精准分离静态背景与运动物体,并实现流畅的时序插值。最后,一个单步扩散模型对渲染结果进行细化,修复瑕疵,生成极为逼真的画面。这使得重建出的场景支持直观的实例级编辑,如实时删除、添加或移动车辆。换句话说,该框架生成的不是死板的视频,而是一个“数字积木世界”。你可以随时删除一辆车、把一个行人“粘贴”到另一个位置,或者从别的场景“借”一辆车放进来。
实验表明,DGGT 在 Waymo 等权威数据集上,仅用0.39秒即可完成重建,质量与速度均显著超越现有方法,且具备强大的跨数据集泛化能力。这项工作为自动驾驶的大规模仿真提供了高效的“场景生产线”。未来,我们随意快速地构建一些我们想要场景,真的不是梦。
写在最后
以上只是对赵昊教授实验室2025年部分工作的简要梳理,实际上团队在多个前沿方向持续深耕,还有许多精彩研究值得关注。此外,2026年也已有多项工作蓄势待发,即将陆续发表,以下为部分预告截图,可谓亮点纷呈、未来可期。
若想了解更多动态与成果,欢迎持续关注实验室主页: https://sites.google.com/view/fromandto

整体来看,赵昊教授实验室的研究布局既有聚焦也有拓展:业务主线以自动驾驶为核心,同时延伸至具身智能等新兴领域;从技术脉络出发,以场景重建、仿真与编辑为主线,覆盖数据生成、轨迹预测、端到端系统等多个层面,形成贯通感知、决策与生成的完整技术栈。
期待上述方向能为相关领域的学习者、科研爱好者,乃至正在考虑考研或攻读博士的同学,提供有价值的参考与启发。实验室持续开放、活跃的研究氛围,相信赵教授也始终欢迎有志于智能系统研究的同行与学子加入探索。
自动驾驶之心



求点赞

求分享

求喜欢

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 老司机超喜爱的4款燃油SUV,款款配置高,综合表现不错
- 新晋潮趣SUV就该这么选!四驱+三把锁,一项黑科技让车子变客厅
- 年轻人的“华为SUV”来了:价格、配置、黑科技一次看明白
- 一口气带你看完十款全球最大SUV:到底谁才是“路上巨无霸”天花板?
- 起亚新狮铂拓界 全球都市SUV开拓者
- 特斯拉大6座豪华SUV来了:Model YL到底是“加长真香”,还是“换壳套路”?
- 奔驰GLC,豪华SUV里的常青树
- 20万级SUV!1.5T四缸增程!东风日产NX8增程版官图发布!有望二季度上市!
- 2026年将上市的6款硬派SUV,哪台才是你的“梦中情车”?
- 吉利银河M7全球首秀,解锁电混SUV设计的黄金法则
