自动驾驶 | EzReal:让机器人征服百米外的视觉盲区
- 2026-02-23 13:40:54
自动驾驶 | EzReal:让机器人征服百米外的视觉盲区
1. 问题的起点:远距离导航为什么这么难
设想这样一个场景:一台地面机器人站在校园的一端,接到指令"前往远处的图书馆"。图书馆在350米开外,在机器人的相机画面中只占据几个像素点。更麻烦的是,沿途的教学楼、树丛会反复遮挡目标——目标时而可见、时而消失、时而只露出一角。
这个场景浓缩了户外零样本目标导航(Zero-Shot Object Navigation, ZSON)的两大核心困难。第一,远距离目标在图像中的投影极其微小,传统的目标检测方法(如GroundingDINO、YOLO-World)在目标缩小到几个像素时,检测精度会急剧下降,因为它们依赖的特征在如此小的区域内几乎无法提取。第二,目标的可见性是动态变化的——机器人在移动过程中,目标会因为前景遮挡物的存在而反复出现和消失,这意味着机器人不能仅仅依赖"当前帧能不能看到目标"来做导航决策。这两个问题是耦合的:正因为目标只有几个像素,稍有视角变化或前景遮挡就会导致目标完全消失。
现有的室内ZSON方法通常依赖深度传感器构建语义地图,但在户外场景中,目标往往远超深度传感器的有效范围(通常不超过10米),深度信息完全不可用。而基于大语言模型(LLM)推理的方法,每次目标消失都需要暂停进行推理,导致导航不连续,且推理延迟使其难以支持实时部署。EzReal正是为了解决这个耦合难题而设计的。
项目主页:https://tianlezeng.github.io/EzReal/
2. 设计哲学:像人一样"看轮廓"与"记方向"
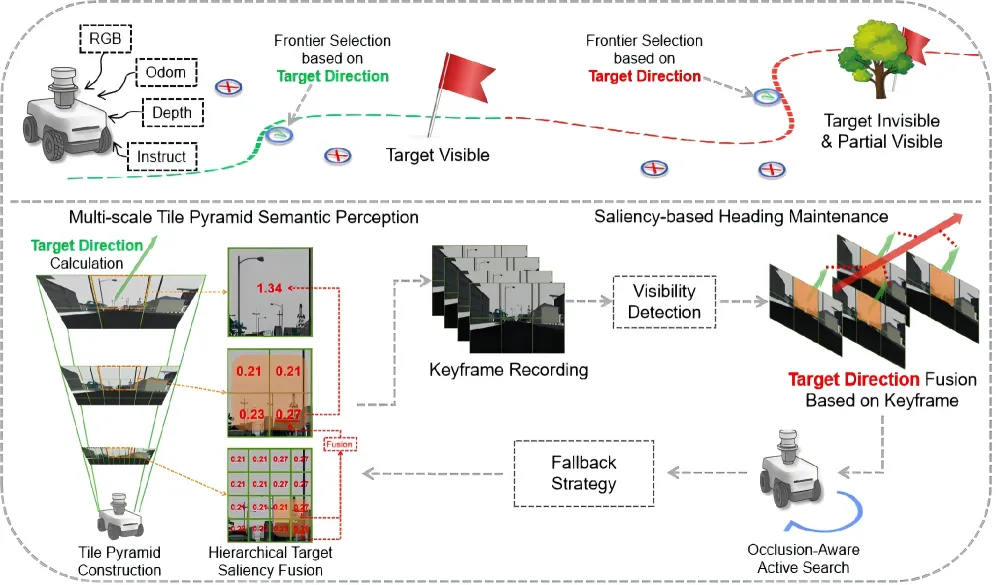
EzReal的设计灵感来源于人类自身的导航行为。当我们在远处寻找一个目标时,我们并不会试图看清它的每一个细节。我们的做法是:先扫视整个视野,通过轮廓和语义特征找到"最像目标"的那个区域,然后朝着它的大致方向前进。随着距离缩短,目标在视野中逐渐变大,我们再进一步确认。
这个过程揭示了一个关键洞察:导航到远距离目标,并不需要一次性的精确定位(grounding),只需要一个模糊但稳定的方向引导信号。 这个信号不是来自对目标本身的精确识别,而是来自目标与周围环境之间的语义对比——在一片绿色植被中,一栋红色建筑即使只有几个像素,也会在语义上"突出"于周围环境。
同样重要的是人类处理遮挡的方式。当目标被建筑暂时遮挡时,我们不会立刻停下来或迷失方向。我们会记住目标的大致方位,继续朝那个方向前进,同时不断"东张西望",试图重新找到目标。如果长时间找不到,我们可能会回到上一次看到目标的位置重新观察。
EzReal将这套"看轮廓 - 辨方向 - 记方向 - 寻方向"的人类行为,转化为了三个具体的技术模块:多尺度图块金字塔感知、基于显著性的航向维持、以及可见性感知的主动搜索与回退策略。
3. 系统架构总览
EzReal的整体架构形成了一个感知-决策闭环,由感知模块和导航模块两部分组成。
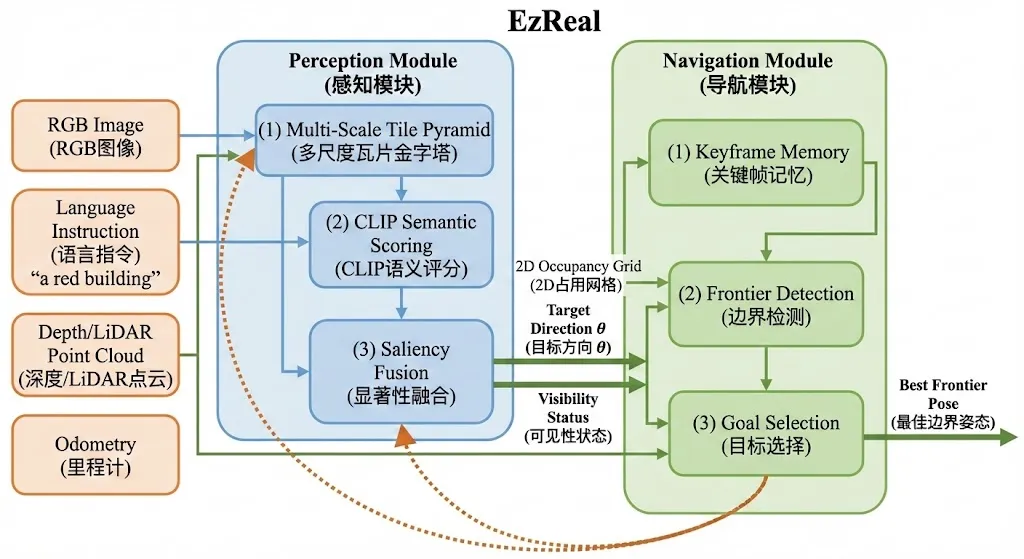
感知模块接收RGB图像,通过多尺度图块金字塔分析图像中每个区域与目标描述的语义相似度,输出两个关键信号:目标方向(target direction)和目标可见性状态(visibility status)。导航模块根据这两个信号调整机器人行为:当目标可见时,方向信号直接引导前沿点选择;当目标被遮挡时,系统利用存储的关键帧维持航向,并触发主动搜索或回退策略。
从代码层面看,这个闭环由三个ROS节点实现:
系统数据流:3D22D.py (占据栅格构建)├── 订阅: /cloud_registered (3D点云), /Odometry (机器人位姿)└── 发布: /map (2D占据栅格地图)tile_node.py (多尺度语义感知)├── 订阅: /image (RGB图像), /camera_info (相机内参),│ /Odometry (位姿), /best_frontier_pose (前沿点反馈)└── 发布: /target_theta (目标方向), /target_visible (可见性)frontier_node.py (前沿点检测与目标选择)├── 订阅: /map, /Odometry, /target_theta, /target_visible└── 发布: /best_frontier_pose (最佳导航目标点)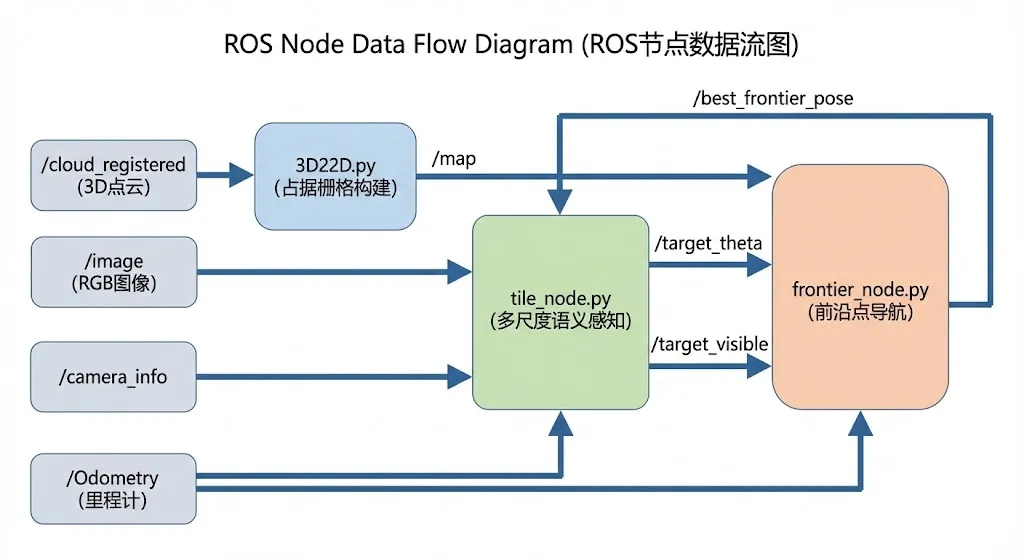
这三个节点通过ROS话题松耦合连接,形成了从感知到决策的完整链路。tile_node.py是感知核心,负责多尺度语义分析和关键帧管理;frontier_node.py是决策核心,负责将语义方向信号转化为具体的导航目标点;3D22D.py则提供环境的几何表示,用于避障和前沿点检测。
4. 核心技术一:多尺度图块金字塔感知
这是EzReal最核心的创新。传统方法处理远距离小目标的思路通常是对图像进行多分辨率缩放(image pyramid),或者使用特征金字塔网络(FPN)在不同尺度上提取特征。这些方法的问题在于:缩放会引入插值伪影,而FPN需要训练,无法做到零样本。
EzReal的做法完全不同——它不缩放图像,而是在单一分辨率的图像上进行固定的区域划分,构建一个三层的图块金字塔:
图块金字塔结构:层级3(粗糙层): 2 x 3 = 6 个图块 ← 最终决策层层级2(中间层): 4 x 6 = 24 个图块 ← 中间聚合层层级1(精细层): 8 x 12 = 96 个图块 ← 底层感知层对齐关系:- 层级3的每个图块 = 层级2的 2x2 个图块- 层级2的每个图块 = 层级1的 2x2 个图块- 层级3的每个图块 = 层级1的 4x4 个图块(16个)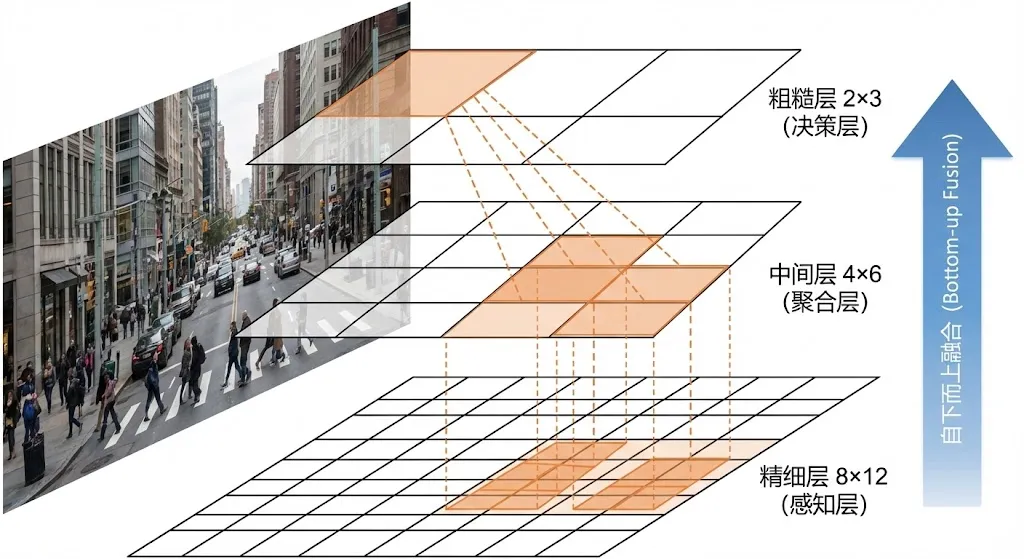
这种对齐的层级结构是整个方法的基石。它保证了信息从精细层到粗糙层的传递路径是唯一且确定的——每个粗糙图块都精确对应一组固定的精细图块,不存在歧义。
4.1 CLIP语义评分
对于每一层的每个图块,系统将其送入CLIP视觉编码器,计算该图块与目标文本描述之间的语义相似度。以下是开源代码中的实际实现:
# embedding_utils.py — CLIP编码与语义评分def compute_tile_embeddings(tiles, model, preprocess, device): """将每个图块resize到224x224后送入CLIP视觉编码器""" processed = torch.stack([ preprocess(Image.fromarray(tile).resize((224, 224))) for tile in tiles ]).to(device) with torch.no_grad(): image_features = model.encode_image(processed) image_features /= image_features.norm(dim=-1, keepdim=True) return image_features.cpu().numpy()def compute_prompt_scores(tile_embeddings, model, device, text_prompts, image_embedding=None): """计算每个图块与目标描述的余弦相似度""" if image_embedding is not None: return np.dot(tile_embeddings, image_embedding.T).flatten() else: text_tokens = clip.tokenize(text_prompts).to(device) with torch.no_grad(): text_features = model.encode_text(text_tokens) text_features /= text_features.norm(dim=-1, keepdim=True) return np.dot(tile_embeddings, text_features.cpu().numpy().T).flatten()这段代码的关键在于:每个图块无论大小,都被resize到224x224后送入CLIP。这意味着即使一个精细层图块只包含目标的几个像素,CLIP也能在224x224的尺度上对其进行语义编码。当然,单个精细图块的CLIP得分可能很微弱——这正是需要多尺度融合的原因。
4.2 层级显著性融合:从微弱信号到稳定方向
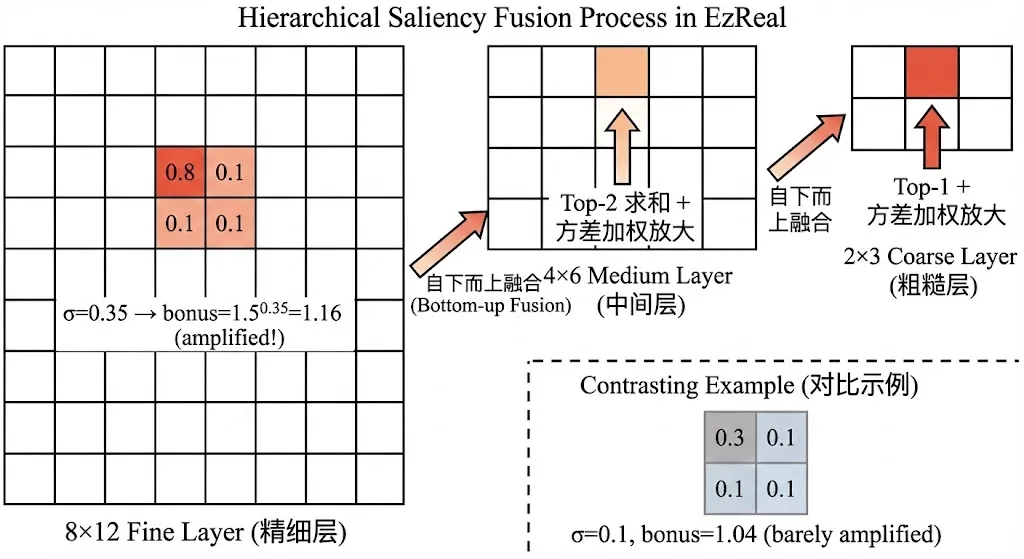
层级融合是EzReal将微弱的底层信号逐层放大为稳定方向估计的核心机制。其基本思想是:如果一个粗糙图块对应的精细子图块中,存在某个子图块的语义得分明显高于其兄弟图块(即局部方差大),那么这个粗糙图块就应该获得额外的"显著性加成"。反之,如果所有子图块的得分都差不多(方差小),说明这个区域没有目标,不应该被放大。
数学上,这个过程通过方差加权的指数放大来实现。对于每组2x2的子图块,计算其标准差sigma,然后用 base^sigma 作为放大系数(base默认为1.5)。sigma越大,放大越强;sigma接近0时,放大系数接近1(几乎不放大)。
以下是开源代码中 tile_node.py 的实际融合实现:
# tile_node.py — 多尺度显著性融合(核心算法)def _compute_multiscale_scores(self, image): """ 三层金字塔:8x12(精细) -> 4x6(中间) -> 2x3(粗糙) 自下而上融合,逐层放大局部语义对比 """ # 第一层:粗糙 2x3 tiles_2x3 = split_image_into_tiles_grid(image, (2, 3)) embeddings_2x3 = compute_tile_embeddings(tiles_2x3, ...) s2 = compute_prompt_scores(embeddings_2x3, ...).reshape((2, 3)) # 第二层:中间 4x6 tiles_4x6 = split_image_into_tiles_grid(image, (4, 6)) s4 = compute_prompt_scores(...).reshape((4, 6)) # 第三层:精细 8x12 tiles_8x12 = split_image_into_tiles_grid(image, (8, 12)) s8 = compute_prompt_scores(...).reshape((8, 12)) # === 融合步骤1:精细(8x12) → 中间(4x6) === s4_fused = np.copy(s4) for i in range(4): for j in range(6): # 取出对应的 2x2 精细子图块 patch = s8[i*2:(i+1)*2, j*2:(j+1)*2].flatten() top2 = np.sort(patch)[-2:] # 取Top-2得分 std = np.clip(np.std(patch), 0, 1) # 局部标准差 bonus = (1.5 ** std) # 指数放大系数 s4_fused[i, j] += bonus * np.sum(top2) # === 融合步骤2:中间(4x6) → 粗糙(2x3) === s2_fused = np.copy(s2) for i in range(2): for j in range(3): patch = s4_fused[i*2:(i+1)*2, j*2:(j+1)*2].flatten() top1 = np.max(patch) # 取Top-1得分 std = np.clip(np.std(patch), 0, 1) bonus = (1.5 ** std) s2_fused[i, j] += bonus * top1 return s2_fused.flatten(), embeddings_2x3这段代码有几个值得注意的设计细节:
为什么精细到中间用Top-2,中间到粗糙用Top-1? 在精细层(8x12),一个远距离小目标可能跨越相邻的两个图块,因此取Top-2可以保留跨图块目标的信号。到了中间层(4x6),每个图块已经覆盖了较大的区域,目标通常落在单个图块内,因此Top-1更具判别力。
指数放大的直觉是什么? 考虑两种情况:(1)一个2x2子图块组的得分为[0.3, 0.1, 0.1, 0.1],标准差约0.1,放大系数为1.5^0.1 = 1.04,几乎不放大;(2)得分为[0.8, 0.1, 0.1, 0.1],标准差约0.35,放大系数为1.5^0.35 = 1.16,显著放大。这意味着只有当某个子图块"明显突出"于其兄弟时,信号才会被放大传递到上层。
4.3 从图块到全局方向:方向计算与可见性判断
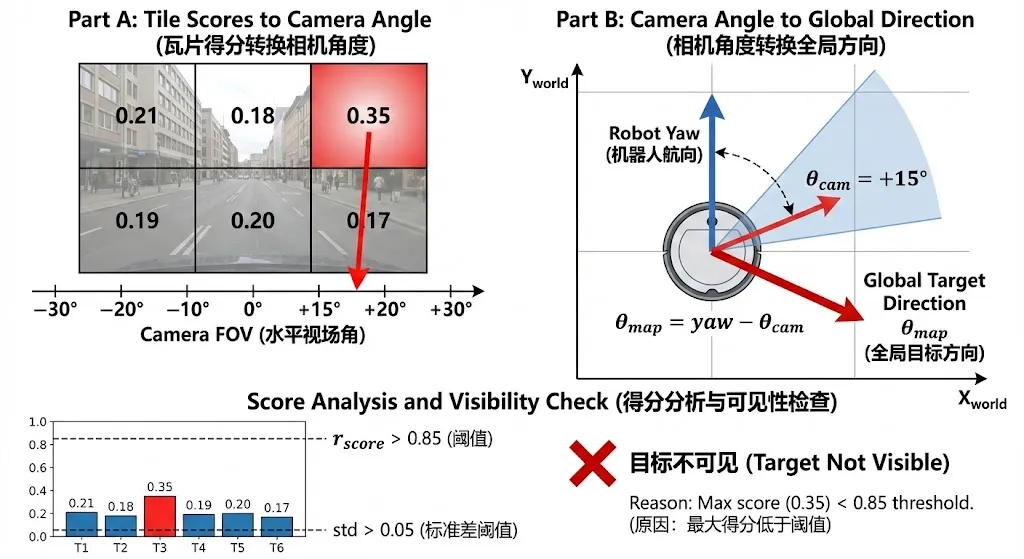
融合完成后,系统在粗糙层(2x3)上找到得分最高的图块,将其中心像素坐标通过相机内参和外参投影到世界坐标系,得到目标的全局方向角。同时,系统通过分析得分分布的统计特征来判断目标是否可见。
以下是 tile_node.py 中方向计算和可见性判断的实现:
# tile_node.py — 方向计算与可见性判断# 1. 计算每个图块中心对应的相机坐标系角度def map_tile_to_cam_angles(grid, h_fov): """将图块索引映射为相机水平视场角""" rows, cols = grid tile_angles = [] for i in range(rows): for j in range(cols): center_ratio = (j + 0.5) / cols - 0.5 # [-0.5, 0.5] angle = center_ratio * h_fov # 映射到FOV范围 tile_angles.append(angle) return tile_angles# 2. 可见性判断:基于显著性比率和标准差的双重阈值max_score = float(np.max(scores))mean_score = float(np.mean(scores))std_score = float(np.std(scores))r_score = max_score / (mean_score + 1e-6) # 稀疏比率visible = (r_score > 0.85 and std_score > 0.050)# 3. 方向转换:相机角 → 全局地图角if visible: best_idx = int(np.argmax(scores)) best_angle_cam = float(tile_angles[best_idx]) # 相机角度 + 机器人朝向 = 全局方向 theta_in_map = current_yaw - best_angle_cam theta_in_map = (theta_in_map + math.pi) % (2 * math.pi) - math.pi可见性判断的逻辑值得展开说明。系统使用两个条件的"与"来判断目标是否可见:稀疏比率 r_score 衡量最高得分相对于平均得分的突出程度,标准差 std_score 衡量得分分布的离散程度。只有当两者都超过阈值时,才认为目标可见。这种双重条件可以有效过滤两类误报:(1)所有图块得分都很高但差异不大的情况(高均值低方差,可能是语义相似的背景);(2)某个图块得分略高但整体分布平坦的情况(噪声波动)。
5. 核心技术二:基于显著性的航向维持
目标被遮挡后,机器人该怎么办?这是户外导航中无法回避的问题。在城市环境中,建筑、树木、地形起伏都会导致目标频繁消失。如果机器人每次目标消失就停下来等待,或者随机探索,导航效率将极其低下。
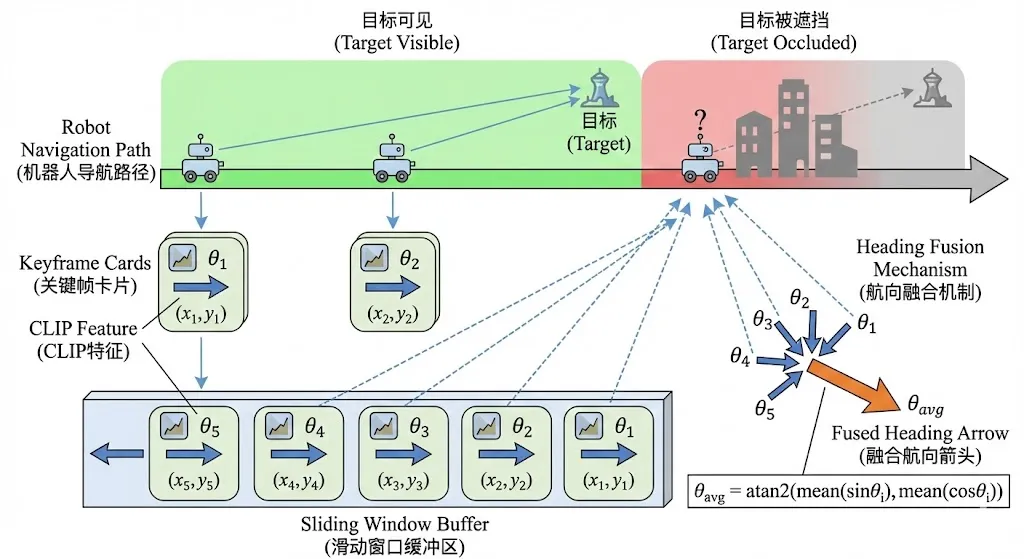
EzReal的解决方案是一套"关键帧记忆 + 方向融合"机制。其核心思想是:在目标可见时持续记录"快照"(关键帧),在目标消失时利用这些快照中的方向信息推算出一个合理的前进方向。
5.1 关键帧记录
每当目标可见且系统成功估计出全局方向时,当前观测会被存储为一个关键帧。每个关键帧包含四个要素:目标区域的CLIP语义特征向量、目标的全局方向角、以及机器人当时的位置坐标。这些关键帧被维护在一个固定大小的滑动窗口中(默认容量50帧),新帧进入时最旧的帧被淘汰。
# keyframe_utils.py — 关键帧管理class KeyframeManager: def __init__(self, node): self.node = node # 持有ROS节点的引用 def add_keyframe(self, embedding, theta, x, y): """记录一个关键帧:语义特征 + 方向 + 位置""" self.node.keyframes.append((embedding, theta, x, y))关键帧的触发时机也经过了精心设计——它不是每帧都记录,而是在前沿点模块发布新的导航目标时才触发记录。这意味着关键帧与导航决策点是对齐的,每个关键帧都对应一次有意义的导航状态变化,避免了冗余存储。
5.2 方向融合:目标消失后的航向推算
当可见性判断模块判定目标不可见时,系统从滑动窗口中取出最近的若干关键帧(默认5帧),对其中记录的方向角进行加权平均,得到一个平滑的推测航向。
# tile_node.py — 目标不可见时的关键帧回退# 取最近的关键帧recent_keyframes = list(self.keyframes)[-int(self.max_keyframe_compare):]if len(recent_keyframes) > 0: thetas = [theta for _, theta, _, _ in recent_keyframes] avg_theta = average_angles(thetas) # 角度的圆周均值 self.pub_theta.publish(Float32(data=avg_theta))else: # 无关键帧时,沿当前朝向继续前进 self.pub_theta.publish(Float32(data=self.current_yaw))这里有一个容易被忽略的细节:角度的平均不能简单地用算术平均,因为角度是周期性的(例如359度和1度的算术平均是180度,但正确答案应该是0度)。代码中使用的 average_angles 函数通过正弦和余弦分量的均值来计算圆周均值:
# angle_utils.py — 角度的圆周均值def average_angles(angles): """正确处理角度周期性的均值计算""" return math.atan2( np.mean([math.sin(a) for a in angles]), np.mean([math.cos(a) for a in angles]) )论文中还提到了基于显著性和时间衰减的加权方案——越近期的、显著性越高的关键帧权重越大。这确保了短期遮挡下机器人不会轻易偏离航道,同时随着时间推移,过时的方向信息会逐渐被淡化。
6. 核心技术三:前沿点导航与主动搜索策略
感知模块输出的方向和可见性信号,最终需要转化为机器人的具体运动指令。EzReal采用了基于占据栅格的前沿点探索(Frontier-based Exploration)框架来完成这一步。前沿点是占据栅格地图上已知自由区域与未知区域的边界——直觉上,前沿点代表了"值得去探索的方向"。
6.1 占据栅格构建
3D22D.py 负责将3D点云转换为2D占据栅格地图。它以机器人当前位置为中心,维护一个固定大小的栅格(默认500x500,分辨率0.1米),通过Bresenham射线追踪算法标记自由空间和障碍物:
# 3D22D.py — 射线追踪标记自由空间def _mark_ray_free(self, x0, y0, x1, y1): """从机器人位置到点云端点画射线,沿途标记为自由空间""" # Bresenham直线算法 x, y = x0, y0 dx, dy = abs(x1 - x0), abs(y1 - y0) sx = 1 if x0 < x1 else -1 sy = 1 if y0 < y1 else -1 err = dx - dy while True: if x == x1 and y == y1: break if self.grid[y, x] == -1: # 未知 → 自由 self.grid[y, x] = 0 e2 = 2 * err if e2 > -dy: err -= dy; x += sx if e2 < dx: err += dx; y += sy # 射线端点标记为障碍物 self.grid[y1, x1] = 100这段代码实现了经典的占据栅格更新逻辑:从机器人位置向每个点云端点发射射线,射线经过的栅格标记为自由(0),端点标记为障碍(100),未被射线触及的区域保持未知(-1)。

6.2 前沿点检测与方向约束选择
frontier_node.py 在占据栅格上检测前沿点,然后结合语义方向信号选择最佳导航目标。前沿点的检测逻辑是:找到所有"自由且相邻未知区域"的栅格单元,再通过连通域分析过滤掉面积过小的噪声区域。
关键的创新在于前沿点的选择策略——系统不是简单地选择最近的前沿点,而是选择与目标方向最一致的前沿点:
# frontier_node.py — 方向约束的前沿点选择def select_and_publish_frontier(self, frontier_points, stamp): """选择与目标方向角度差最小且距离最近的前沿点""" best = None min_dist = float('inf') for wx, wy in frontier_points: # 计算前沿点相对于机器人的方向角 theta_f = math.atan2(wy - self.robot_y, wx - self.robot_x) # 与目标方向的角度差 d_theta = (theta_f - self.target_theta_in_map + math.pi) \\ % (2 * math.pi) - math.pi # 只考虑角度差在阈值内的前沿点(默认15度) if abs(d_theta) < self.frontier_angle_threshold: dist = math.hypot(wx - self.robot_x, wy - self.robot_y) if dist < min_dist: min_dist = dist best = (wx, wy)这个15度的角度约束是一个精妙的设计:它既保证了机器人大致朝目标方向前进,又给予了足够的灵活性来绕过障碍物。如果没有任何前沿点满足角度约束,系统会放宽条件或触发主动搜索。
6.3 可见性感知的行为切换
导航模块根据目标可见性状态执行不同的行为策略,形成了一个清晰的状态机:
目标可见 → 生成虚拟目标点(沿目标方向0.5米处),直接朝目标前进目标不可见 → 使用关键帧融合方向,选择对齐的前沿点探索短期搜索失败 → 导航到最近关键帧位置,执行 ±30度 扫描长期搜索失败 → 回退到最后一次看到目标的位置,360度全景环视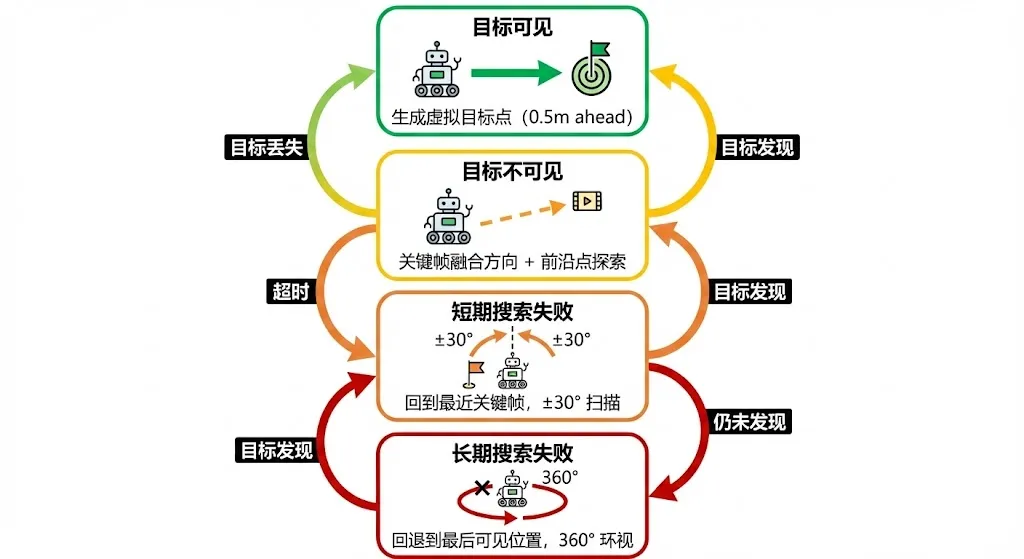
当目标可见时,系统生成一个"虚拟前沿点"——在目标方向上距机器人0.5米处放置一个临时导航目标。这个距离很短,意味着机器人会频繁更新目标点,实现对目标方向的实时跟踪。当目标消失时,系统切换到前沿点探索模式,利用关键帧融合的方向来筛选前沿点。
为了防止机器人在前沿点之间频繁切换(导致"抖动"),系统还引入了行程距离锁定机制:一旦选定一个前沿点,机器人必须走完预期距离后才能切换到新的目标点。
7. 快速上手指南(代码已开源)
EzReal的核心代码已开源,以下是基本的部署流程:
# 依赖环境# - ROS (Noetic 或更高版本)# - Python 3, PyTorch, OpenAI CLIP# - OpenCV, NumPy# 安装CLIPpip install git+https://github.com/openai/CLIP.git# 启动三个核心节点(需要根据实际硬件修改话题名称)rosrun zson_nav_tools 3D22D.py # 占据栅格构建rosrun zson_nav_tools tile_node.py # 多尺度语义感知rosrun zson_nav_tools frontier_node.py # 前沿点导航关键配置参数:
# tile_node.py 核心参数target_text: ["a red building"] # 目标的自然语言描述use_multiscale: true # 启用多尺度金字塔(推荐)grid: [2, 3] # 粗糙层网格尺寸saliency_base_8x12_to_4x6: 1.5 # 精细→中间的放大基数saliency_base_4x6_to_2x3: 1.5 # 中间→粗糙的放大基数# frontier_node.py 核心参数frontier_angle_threshold_deg: 15.0 # 前沿点角度约束(度)virtual_goal_dist: 0.5 # 虚拟目标点距离(米)use_virtual_frontier: true # 目标可见时使用虚拟目标use_travel_distance_lock: true # 启用行程距离锁定需要注意的是,论文中提到的主动搜索(Active Search)和回退策略(Fallback Strategy)目前与规划器代码集成在一起,研究团队正在改进中,预计近期开源。当前版本的用户可以先接入自己的路径规划器,订阅 /best_frontier_pose 话题即可驱动机器人运动。
8. 局限性与未来方向
尽管EzReal在远距离导航和动态遮挡恢复方面取得了显著进展,论文也坦诚地讨论了当前框架的局限性。
首先,当遮挡持续时间过长(超过10秒)时,航向记忆虽然能维持大致方向,但主动搜索可能扩展到过大的区域,导致重新识别延迟和轨迹偏移。其次,短暂但频繁的遮挡会造成外观歧义——如果目标可见的时间窗口太短,系统可能无法形成足够置信的语义匹配。第三,反复的恢复循环会累积路径长度,增加超时风险,这揭示了鲁棒性与效率之间的内在张力。
此外,当前系统依赖对目标的初始观测来启动导航——如果机器人从一开始就看不到目标,系统无法自主引导。路径规划模块也缺乏高级推理能力,在高度杂乱或不确定的环境中,仅靠前沿点探索可能不够。
研究团队指出,未来的工作将探索融合历史观测、语义线索和环境上下文的机器人推理机制,以实现更智能的前沿点选择和路径规划。这可能涉及将大语言模型的推理能力与EzReal的实时感知能力相结合——用LLM进行高层策略规划,用EzReal的多尺度感知提供低层方向引导。
更多ROS、具身智能相关内容,请关注古月居
👉 关注我们,发现更多有深度的自动驾驶/具身智能/GitHub 内容!
🚀 往期内容回顾 👀
🔥 行业杂谈 | 触觉感知在机器人操作中的应用与技术突破🔥 十分钟实用教程 | PlatformIO 配置指南:Arduino 与 ESP-IDF 框架切换🔥 读读代码 | 大幅超越π0.5和X-VLA,Motus——统一潜在动作世界模型深度解析
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 马斯克为什么说已经解决了自动驾驶?因为FSD的累积训练量已经达到了100亿公里,每日产生的数据量约等于人类500年的驾驶经验
- 10万出头的纯电SUV,吉利这波操作我是真没想到!
- 怎么样搜索未留手机号的轿车
- 2026 年春节档观影人次破亿,特斯拉自动驾驶支持识别手势,三星S26 Ultra官方宣传材料曝光,阿里云百炼上新,这就是今天的其他大新闻!
- 2026 自动驾驶纪元:颠覆认知的五大转折,重塑驾驶的未来
- 33款六座SUV大盘点:3款待定价新车领衔,谁是2026家用首选?
- 什么是自主神经系统它是身体的自动驾驶系统
- 又一合资车降到5万,SUV比朗逸轩逸亲民,配天窗+CVT,油耗低至5L
- 2026上半年SUV市场要疯?十几款重磅新车盘点,最后一款别错过!
- 丰田这款新SUV要火!颜值不输奥迪Q5L,一公里油耗才3毛钱,又要排队买了.
