自动驾驶学术之星 | 清华AIR詹仙园团队近一年工作盘点
- 2026-03-07 14:09:12

点击下方卡片,关注“自动驾驶之心”公众号
编辑 | 自动驾驶之心
本文只做学术分享,如有侵权,联系删文
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
自动驾驶这波浪潮里,中国研究者早就不是跟跑选手了,而是妥妥的主力玩家。高校实验室们也各有绝活儿:有的死磕感知,让车“看得更清”;有的all in端到端,追求“一气呵成”;还有的在仿真世界里疯狂“内卷”,提前把corner case刷个遍。
为了带大家摸清国内自动驾驶的学术地图,“自动驾驶之心”特别策划【学界之“星”】系列专栏。专门挖一挖那些低调但超能打的老师们。本期为第二期。上回聊了清华智能产业研究院 AIR 的赵昊老师,这期咱们把镜头转向同在 AIR 的另一位大佬——詹仙园。

詹教授走的是“土木 -> 交通 -> AI”的跨界路线:
2007年本科读清华土木工程,2011年去美国普渡大学进修——同时拿了计算机科学和交通工程的双硕士,最后拿的是交通工程博士; 博士期间(顺手读了个 CS 的硕士),有一半时间泡在计算机系搞机器学习,算是早期“交通+AI”交叉玩家; 2017年博士毕业后先在微软亚洲研究院(MSRA)做副研究员搞研究,后来跳槽到京东科技当数据科学家,主导开发基于离线强化学习的火力发电优化系统; 2021年加入清华AIR任副教授,现在带着 AIR-DREAM 的实验室,专注用强化学习、具身智能这些技术解决实际问题。
詹仙园老师同时也在多个交通和计算机领域的国际专业期刊及会议担任审稿人,并担任中国计算机学会人工智能与模式识别专委会(CCF-AI)委员,其研究方向也非常的前沿:离线强化学习、具身智能、自动驾驶、工业系统优化——简单说就是“怎么让AI在真实世界里更聪明地干活。
最新的工作Hyper Diffusion Planner系统地探索了如何训练和设计基于扩散模型的自动驾驶端到端模型,并成功在 Xiaomi SU7 上完成部署并进行了实车验证。
几个月前,他带领团队开发出跨本体具身模型 X-VLA,通过可学习的软提示技术解决机器人硬件异构性问题。该模型以 0.9 B参数在五大仿真基准刷新性能纪录,仅用 1200 条示教数据即可完成叠衣服等复杂任务,并于 2025 年 10 月带队获得 IROS 2025 AGIBOT World Challenge 国际具身智能竞赛冠军。
更多详细内容,感兴趣的大家可以点开詹老师的主页看看:
个人主页:https://zhanxianyuan.xyz/ 实验室主页:https://air-dream.netlify.app/ GitHub:https://github.com/THU-AIR-DREAM
那么本篇文章,笔者将着重介绍 2025 年詹仙园老师的一些重要研究成果。
[Aixiv] Unleashing the Potential of Diffusion Models for End-to-End Autonomous Driving
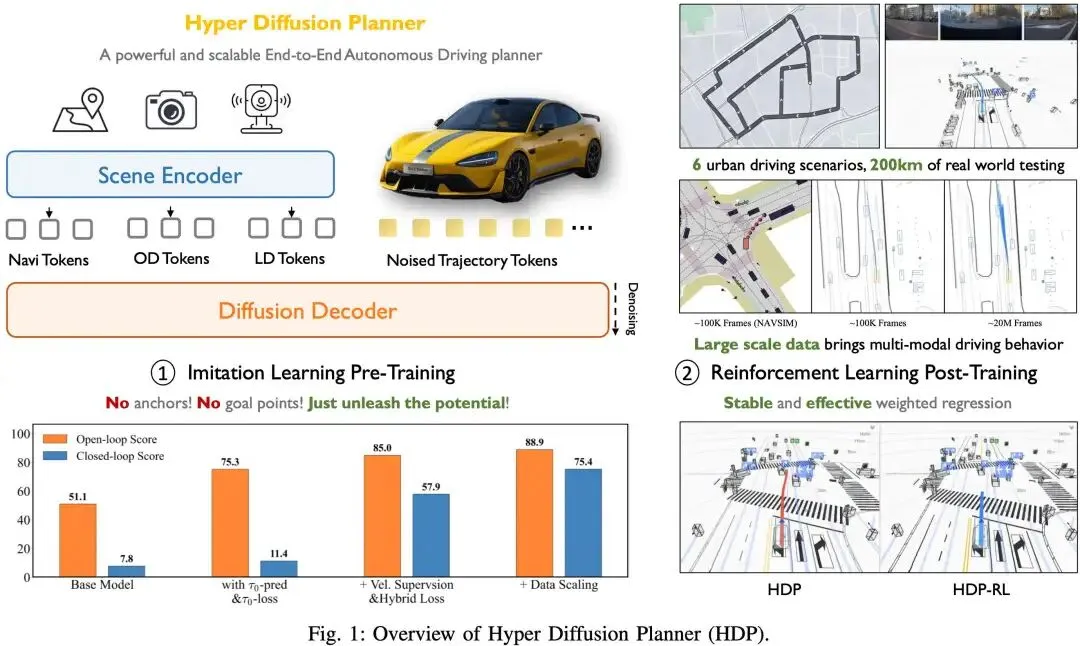
提出时间:2026.02提出机构:清华大学 AIR、小米汽车等论文链接:https://arxiv.org/pdf/2602.22801项目主页:https://zhengyinan-air.github.io/Hyper-Diffusion-Planner/研究背景:扩散模型轨迹生成已经成为端到端、VLA等算法的主流选择,但在业内一直缺少实车的大规模验证,且各家车企基本上鲜有对外宣传的硬货。清华AIR和小米的这篇Hyper Diffusion Planner可以为学术界&工业界提供很强的参考价值。在这项研究中,我们系统地探索了如何训练和设计基于扩散模型的自动驾驶端到端模型,并成功在 Xiaomi SU7 上完成部署并进行了实车验证。论文内容:在本研究中,我们基于大量实车数据和道路测试,进行了一项系统性和大规模的研究,以充分挖掘扩散模型作为E2E AD Planner的潜力。通过全面的研究,我们发现了对扩散损失空间、轨迹表示和数据scaling的insight,这些insight对E2E planning有显著影响。此外,我们还提供了一种有效的强化学习后训练策略,以进一步提高planner的安全性。由此诞生了Hyper Diffusion Planner(HDP)。并且HDP做了实车部署验证,在6个城市和200公里的真实世界测试中进行了评测,与基础模型相比,性能显著提高了10倍。结果表明,扩散模型在经过适当设计和训练后,可以作为复杂、现实世界自动驾驶任务中有效且可扩展的E2E AD Planner。
本文的主要发现如下:
扩散损失空间至关重要。我们观察到规划轨迹存在于一个低维流形中,这与图像生成不同。因此,我们重新审视了扩散损失空间的设计,并发现将数据(τ0)预测与直接在数据上监督的扩散损失(τ0损失)相结合,最能捕捉轨迹流形,从而实现更好的学习性能和高质量的轨迹生成; 轨迹表示至关重要。我们观察到,直接生成waypoint能输出更强的空间感知能力,而速度预测则能生成更平滑的轨迹。因此,我们的模型输出速度,但同时接受速度和waypoint的监督。更重要的是,我们从数学上证明了这种混合损失公式不会改变扩散训练的最优解,同时使我们能够利用两者的优势; 数据scaling的涌现。保持极简的设计就可以让HDP在实车测试中有效利用data scaling。我们发现,当驾驶数据扩展时,我们的模型能捕捉到更丰富的多模态驾驶行为,并展现出更优的闭环性能。而在常用的自动驾驶基准数据集上训练扩散模型时,由于训练数据集过小,并未观察到此类扩展性。
此外,也跟大家着重介绍下Diffusion Planner一作 —— 郑一楠博士。郑博在自动驾驶和具身智能领域研究颇深,已有多篇工作中稿ICLR、NeurIPS、ICML、CVPR等国际顶会。是Diffusion Planner、Flow Planner、ReflectDrive和DIPOLE等工作的核心贡献者,欢迎大家Follow他的个人主页。
链接:https://zhengyinan-air.github.io/

[ICLR 2026] Dichotomous Diffusion Policy Optimization
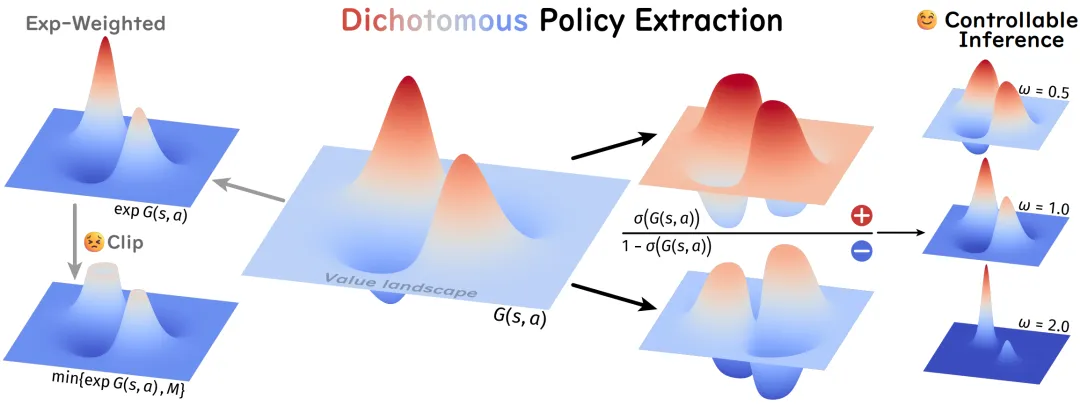
提出时间:2026.01提出机构:中科院自动化所、清华大学 AIR、小米汽车等论文链接:https://arxiv.org/pdf/2601.00898研究背景:Diffusion Policy(扩散策略)因其卓越的多模态分布建模能力,已在机器人操控与自动驾驶等领域取得了显著成功。然而,利用强化学习(Reinforcement Learning, RL)对预训练的 Diffusion Policy 进行进一步微调,仍然面临一系列关键挑战。论文内容:为了解决上述痛点,该工作通过重构 KL 正则化强化学习损失函数,并将策略改进分解为一对二分扩散策略,从而能够在推理时精确控制策略最优性,同时保持训练动态的稳定性,实现了稳定、可控的大规模扩散模型强化学习。
为什么 DIPOLE 值得关注?
数学优美:给出了基于 KL 正则化目标的闭式解,理论解释性强。 训练稳定:告别了传统 Diffusion RL 训练中的 Loss 爆炸和梯度消失。 即插即用:推理阶段的 CFG 形式,使得部署和调试极其灵活。 大模型验证:不只是玩玩 Toy Env,直接在 1B+ 参数的 VLA 模型上验证了有效性,对具身智能(Embodied AI),自动驾驶落地意义重大。
[ICLR 2026] X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
这篇工作此前自动驾驶之心也有介绍,在 IROS-AGIBOT World Challenge 上大放异彩,夺得冠军。
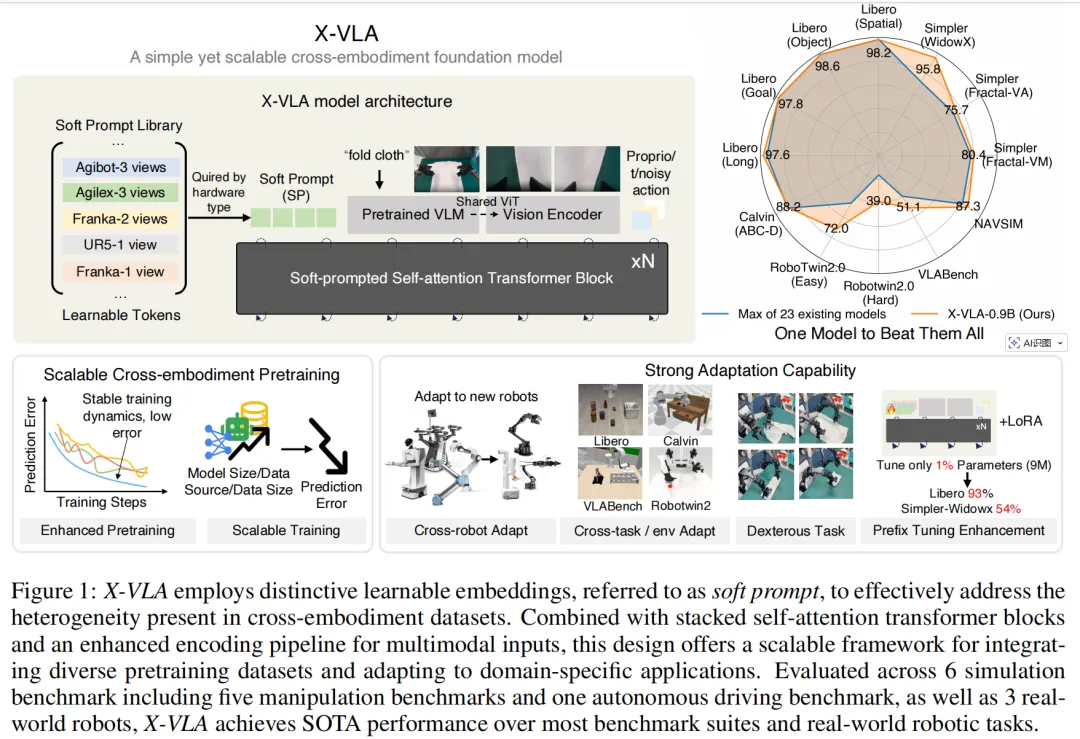
提出时间:2025.10提出机构:清华大学智能产业研究院(AIR)、上海人工智能实验室等论文链接:https://arxiv.org/pdf/2510.10274项目链接:https://thu-air-dream.github.io/X-VLA/研究背景:构建能理解人类指令并在多种机器人平台上灵活操作的通用智能体是机器人领域的重要目标。当前VLA模型虽借助VLM取得进展,但在跨本体、跨环境训练中面临严重的异构性问题,包括动作空间、视觉设置、任务分布等多维差异。现有方法多仅通过独立解码头处理动作空间,忽略其他异构来源,导致训练不稳定、泛化能力差。因此,需要一种能有效建模异构性的统一框架。论文内容:为此,詹老师的团队提出X-VLA,一种基于软提示(Soft Prompt)机制的流匹配VLA框架,旨在高效应对跨本体训练中的异构性问题:
异构性建模新范式:将软提示引入VLA,为每个数据源(如不同机器人平台)分配一组可学习的嵌入向量,用于编码其硬件配置、视觉设置等异构特征。这些提示在特征融合早期即注入模型,引导模型进行“本体感知”的表征学习,从而实现异构知识的有效整合。
高效的两阶段训练与适配流程:阶段一:预训练,模型在包含7个平台、5类机械臂、290K条轨迹的异构数据集上联合优化骨干与软提示,学习本体无关的通用策略。阶段二:域适配,为新硬件配置引入新的软提示,先冻结骨干仅优化提示,再联合微调,实现高效、低成本的快速适配。
模型架构创新:采用Florence-2作为VLM编码器,分别处理固定视角与腕部视角图像,缓解视觉-语言与具身推理之间的语义鸿沟。动作生成部分使用Transformer编码器替代传统DiT解码器,提升跨模态融合效率。引入动作空间对齐(6D旋转表示、末端执行器位姿统一)、意图抽象(4秒预测窗口)、平衡数据采样等工程优化,显著提升训练稳定性与泛化能力。
全面且优异的实验验证:在6个仿真基准(包括Libero、Simpler、CALVIN、NAVSIM等)和3个真实机器人平台上均取得SOTA结果,部分任务成功率超95%。在灵巧布料折叠任务中,仅用1200条轨迹即可达到与闭源模型π0相当的性能,验证其数据效率。参数高效微调(PEFT) 实验显示,仅微调1%参数(9M)即可在多个任务上取得与全量微调相当的效果,展现了强大的迁移能力。
综合来看,X-VLA通过软提示机制有效解决跨本体异构训练难题,展现出良好的扩展性与适配效率,为构建通用具身智能模型提供了新思路。
[NeurIPS 2025] Flow Matching-Based Autonomous Driving Planning with Advanced Interactive Behavior Modeling
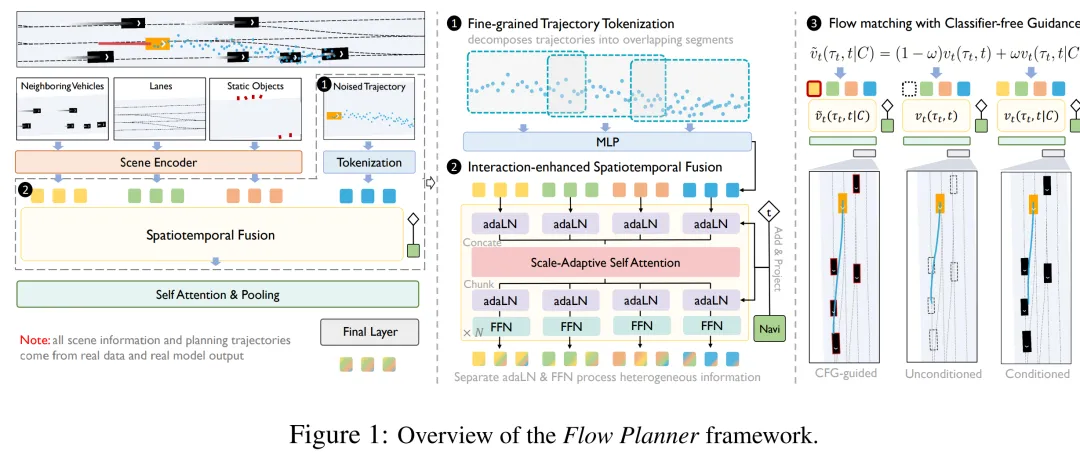
提出时间:2025.10提出机构:清华大学智能产业研究院(AIR)、中国科学院自动化研究所、香港中文大学等论文链接:https://arxiv.org/pdf/2510.11083项目链接:https://github.com/DiffusionAD/Flow-Planner研究背景:自动驾驶规划在复杂交互场景中面临严峻挑战:交通参与者行为多模态、交互密集,而现有模仿学习方法难以从数据稀缺的交互场景中学习有效策略。简单堆叠Transformer架构缺乏交互建模专用设计,依赖规则先验或辅助损失的方法又难以泛化至动态环境,亟需一种兼具表达能力与交互建模能力的生成式规划框架。论文内容:本论文提出 Flow Planner,一个基于流匹配(Flow Matching)的端到端规划框架,通过数据建模、架构设计、学习范式三方面协同创新,显著提升了复杂交互场景下的规划能力:
细粒度轨迹Tokenization(笔者认为这是创新核心):将全长轨迹拆分为重叠的短段,每段由独立token表示。既避免单token全轨迹压缩导致的信息丢失,又克服自回归逐点生成带来的误差累积。引入一致性损失(Consistency Loss)约束重叠段预测一致性,推理时简单平均即可融合。
交互增强的时空融合架构:采用尺度自适应注意力(Scale-Adaptive Attention):根据token间欧氏距离动态调整注意力权重,使模型可忽略远距无关参与者,聚焦关键交互。通过独立adaLN + FFN将异构模态(车道、邻居、自车轨迹)分别投影至共享隐空间后再融合,有效缓解模态异质性问题。
基于流匹配的无分类器引导:采用流匹配损失替代扩散损失,训练更稳定、采样更快。在训练时随机mask邻居车辆信息,使模型同时学习有条件和无条件轨迹分布;推理时通过无分类器引导(CFG)动态重加权条件强度,显著提升对周围车辆的响应敏感度与交互合理性。
全面领先的实验验证:在nuPlan Val14上首次实现90.43分,成为首个无规则后处理突破90分的学习型规划器。在interPlan交互密集基准上以61.82分大幅超越Diffusion Planner(52.90),尤其在“Jaywalk”等难例中提升超17分。消融实验系统验证各组件有效性:轨迹分段最优为20段(每段8帧,重叠4帧),CFG最优尺度1.80,尺度自适应注意力需配合独立adaLN方能发挥最大收益。
Flow Planner 通过轨迹分段化表示、交互导向注意力与流匹配引导三大支柱,首次使纯学习型规划器在nuPlan上超越规则混合方法,为复杂交互场景下的自动驾驶规划提供了高表达、高交互、高效率的新范式。
[ICLR 2026] ReflectDrive:DISCRETE DIFFUSION FOR REFLECTIVE VISIONLANGUAGE-ACTION MODELS IN AUTONOMOUS DRIVING
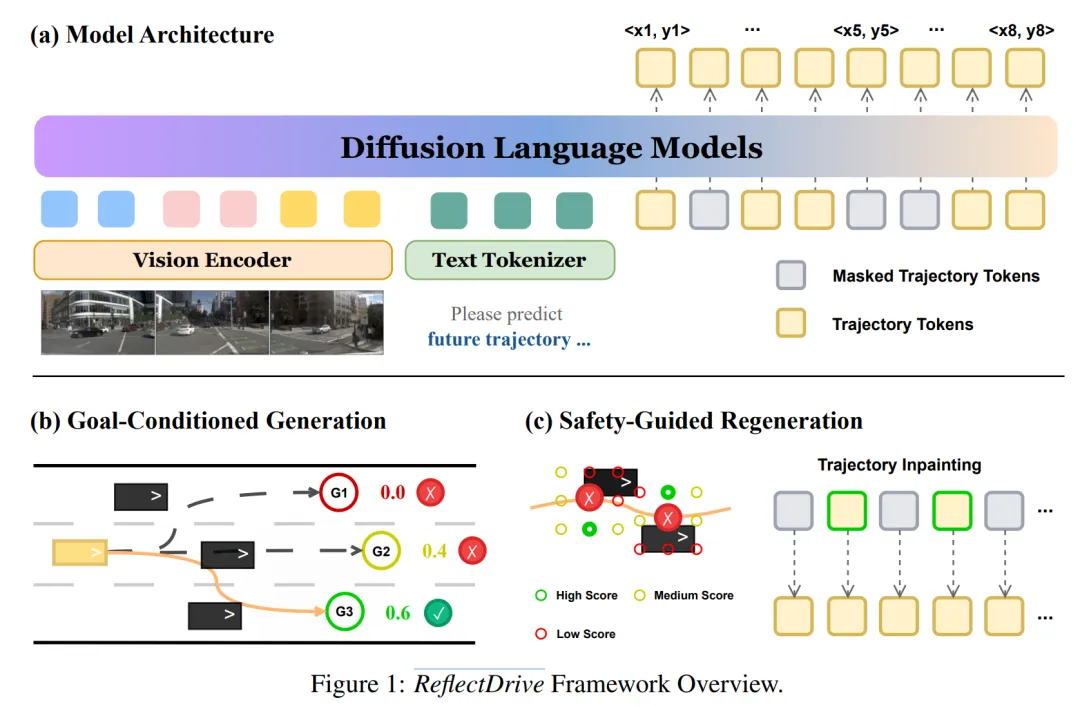
提出时间:2025.09提出机构:清华大学智能产业研究院(AIR)、理想汽车论文链接:https://arxiv.org/pdf/2509.20109研究背景:端到端自动驾驶规划面临两大难题:模仿学习易产生因果混淆、缺乏可验证的安全保障;现有扩散模型虽能通过引导机制提升可控性,但依赖梯度计算、采样速度慢且参数敏感。如何在不牺牲实时性与行为自然度的前提下,将硬性安全约束无缝嵌入生成式规划器,仍是该领域亟待突破的核心瓶颈。论文内容:针对上述痛点,詹老师的团队提出 ReflectDrive,一种基于离散扩散模型与反射机制的全新端到端自动驾驶规划框架,旨在在不依赖梯度计算的前提下实现安全、可控、实时的轨迹生成。其主要创新与贡献如下:
离散化轨迹表示与VLA规划器:将连续二维驾驶空间通过均匀网格量化,构建离散动作码本,将轨迹表示为扁平化的离散token序列。基于预训练的离散扩散语言模型(LLaDA-V)进行微调,构建VLA规划器,支持并行解码与双向特征融合,具备可扩展的训练能力与天生的inpainting能力。
两阶段反射推理机制:目标条件生成:从模型输出的末端token分布中采样多样化的高置信度终点,经非极大值抑制(NMS)筛选后,通过inpainting生成完整轨迹候选,并由全局评分函数选出最优轨迹。安全引导修复:针对轨迹中首个违反安全约束的waypoint,在局部离散邻域内进行高效搜索,获得“安全锚点”后利用模型inpainting能力修复周围轨迹。该过程为梯度自由、迭代闭环,平均1–3轮即可收敛。
轻量、可插拔的安全约束注入:反射机制完全在推理阶段运行,无需重新训练或梯度计算,支持实时部署。离散token空间使局部搜索极为高效,且评分函数可灵活替换(如加入中心线偏离惩罚等),具备强可扩展性。
全面且领先的实验验证:在真实世界自动驾驶基准NAVSIM上,ReflectDrive达到PDMS 91.1,显著超越UniAD、Hydra-MDP、DiffusionDrive等主流方法,逼近人类驾驶水平(94.8)。在特权信息(ground-truth agents)条件下,PDMS提升至94.7,NC、DAC、TTC等核心安全指标全面接近或超越人类。消融实验证明:目标条件生成显著提升任务进度(EP +7.9),安全引导修复大幅改善安全指标(DAC +3.9,TTC +1.3);离散化粒度、目标候选数、迭代轮次等参数均表现出强鲁棒性。
规模扩展性与开源潜力:在含10亿样本的内部数据集上,离散扩散VLA在长时域预测(120m)上显著优于连续扩散基线(FDE 2.19 vs. 2.71),验证其优越的扩展能力。
ReflectDrive 首次将离散扩散与反射机制引入端到端自动驾驶规划,在保持生成多样性与行为自然度的同时,实现了可验证、可干预、高效率的安全轨迹生成,为下一代可信具身智能规划器提供了全新范式。
[ICLR 2025] Diffusion-Based Planning for Autonomous Driving with Flexible Guidance
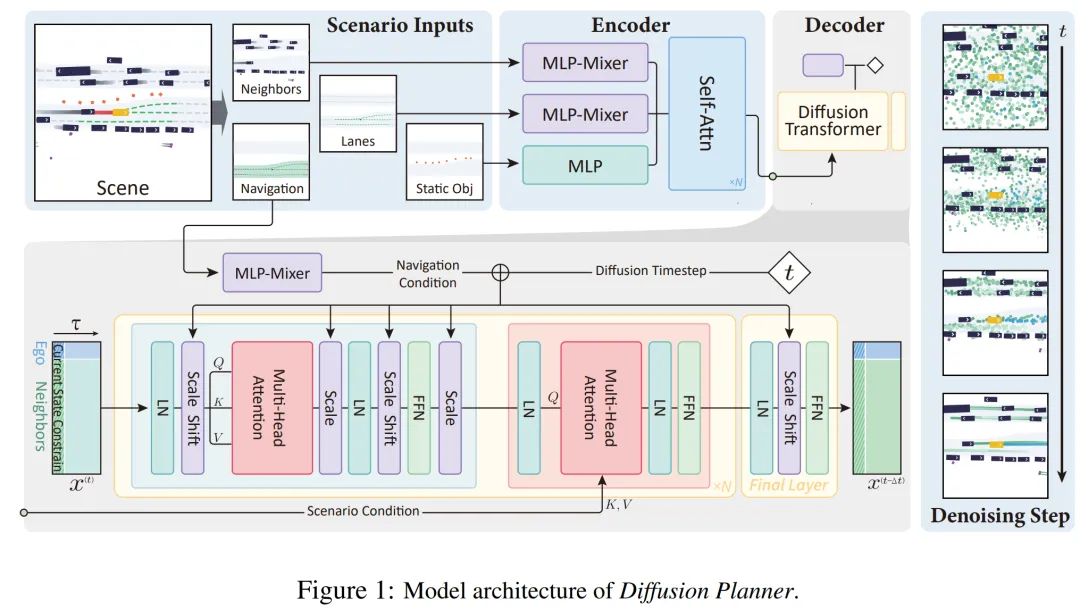
提出时间:2025.01提出机构:清华大学智能产业研究院(AIR)、港中文、上交等论文链接:https://arxiv.org/pdf/2501.15564项目链接:https://zhengyinan-air.github.io/Diffusion-Planner/研究背景:现有 learning-based 自动驾驶 planner 多采用模仿学习,难以拟合人类驾驶的多模态分布,且面对分布外场景时严重依赖规则后处理。同时,通过辅助损失注入安全或舒适偏好易导致多目标冲突,且训练后难以灵活调整驾驶风格。如何在无规则依赖的前提下实现高质量、可适配的闭环规划,仍是核心挑战。论文内容:这篇工作詹老师的团队提出了 Diffusion Planner,是首个将扩散模型完整应用于自动驾驶闭环规划的工作,在不依赖任何规则后处理的前提下,实现了生成质量、多模态建模与行为可编辑性的统一。主要有以下一个 Highlights:
扩散模型驱动的联合轨迹生成框架:将自车规划与邻车预测统一建模为条件轨迹生成任务,在同一扩散解码器中联合生成,使模型能够隐式学习交互协作行为。采用DiT架构,通过交叉注意力机制融合场景编码与噪声轨迹,替代传统复杂模块化设计。
无规则后处理的高质量规划:首次实现纯学习型规划器在nuPlan上超越规则混合方法(Val14 89.87,Test14 89.19),推理频率达20Hz,满足实时部署要求。
推理时灵活的行为引导机制:利用扩散后验采样,无需额外训练即可在推理时通过可微能量函数注入安全、舒适、目标车速、可行驶区域等偏好。支持多种引导组合(如碰撞规避+可行驶区域),实现个性化驾驶风格即时适配,极具工程实用价值。
跨场景、跨车型的强迁移能力:收集并开源200小时配送车数据集,车辆尺寸小、行驶于非机动车道、人车交互密集。Diffusion Planner在该数据集上取得92.08分,显著优于PlanTF(90.89)、PLUTO(87.77)等 baseline,验证模型对不同驾驶风格与场景分布的鲁棒迁移能力。
系统性的架构与策略消融:验证Z-Score归一化、数据增强、插值重建、邻车数量选择等关键设计;分析当前状态信息丢弃对闭环性能的提升机制;揭示扩散模型在规划任务中低温采样、少步求解器的高效适配策略。
总的来看,Diffusion Planner 证明了:扩散模型可以在无规则后处理、无强化学习、无语言模型介入的条件下,独立支撑起高性能、可干预、可迁移的自动驾驶闭环规划系统,为生成式规划提供了坚实的范式基础。这篇工作算是早期扩散轨迹模型的奠基之作,对后续自驾VLA和扩散轨迹模型的发展有很强的参考价值。
[CVPR 2025] Universal Actions for Enhanced Embodied Foundation Models
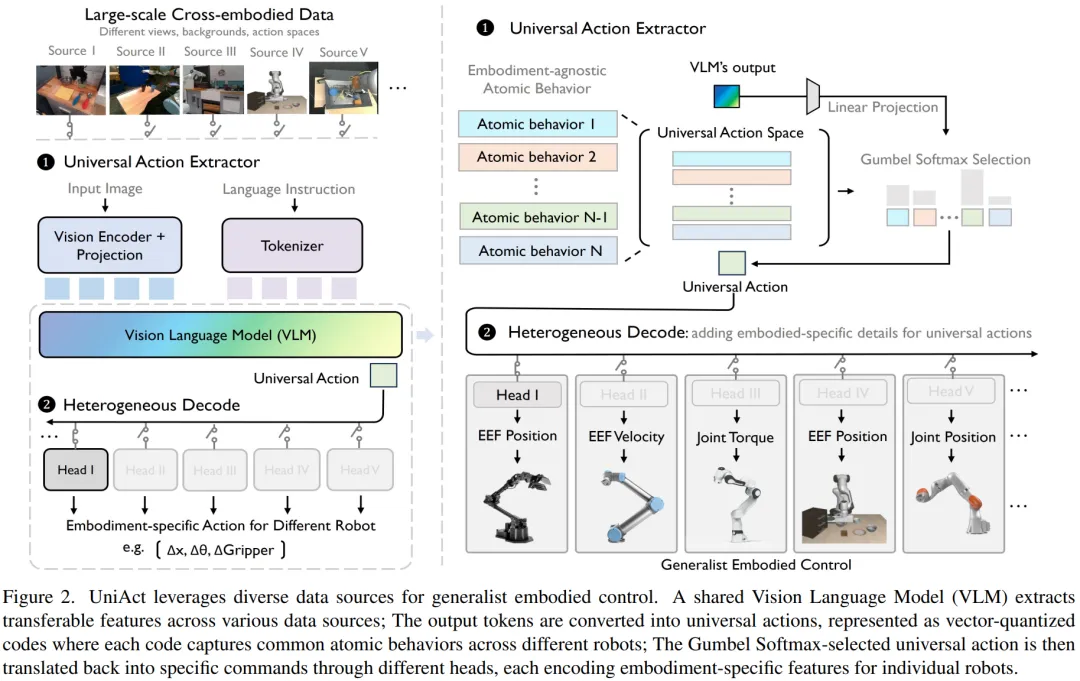
提出时间:2025.01提出机构:清华大学智能产业研究院(AIR)、商汤科技、北京大学等论文链接:https://arxiv.org/pdf/2501.10105研究背景:具身数据存在严重的动作异构性:不同机器人(机械臂、四足、汽车)动作空间完全不同,控制接口(位置/速度)物理意义迥异,同一平台不同操作者行为也多模态。现有方法或粗暴等同处理异构动作,或简单聚合所有动作空间,均未有效挖掘跨本体的共享结构,严重阻碍具身基础模型跨领域数据利用与跨本体泛化。论文内容:这一片具身智能的工作,提出了UniAct,一个在通用动作空间(Universal Action Space)中构建的具身基础建模框架,首次将跨本体共享原子行为(如“向前移动”“抓取”)抽象为离散码本,从根本上解决动作异构性问题。以下为一些 Highlights:
通用动作空间构建:将通用动作空间建模为向量量化码本(256×128),每个码字代表一个跨本体通用的原子行为。利用预训练VLM(LLaVA-OneVision-0.5B)作为通用动作提取器,根据观测与语言指令输出码本上的概率分布,经Gumbel-Softmax重参数化采样,形成信息瓶颈,迫使模型学习跨本体共享行为特征。
异构解码机制:为每个机器人配备轻量级MLP解码头,以通用动作+视觉特征为输入,输出本体特定的控制信号。解码头极简(避免过拟合),确保通用动作提取器承担主要学习负荷,最大化跨本体迁移能力。
高效的两阶段训练与快速适配:预训练阶段在28种不同机器人、1M条轨迹(Open-X、Droid、LIBERO等)上联合优化码本、提取器及各领域解码头。适应新本体时仅冻结提取器、从头训练新解码头,在AIRBOT机器人上仅用4M可训练参数(0.8%)、100条演示即完成适配,远超OpenVLA(1.4%)与Octo(2%)。
全面且领先的实验验证:在真实WidowX机器人上,UniAct-0.5B在视觉、运动、物理泛化维度全面超越14倍大的OpenVLA-7B与LAPA-7B。在LIBERO仿真130个任务上平均成功率显著领先Octo、CrossFormer、OpenVLA等基线。
开箱即用的通用动作Tokenizer:用户可直接通过手动选择动作ID操控机器人完成复杂任务(如Pick & Place),无需任何机器人学知识,为未来大规模具身模型提供可规划的离散动作接口。
总的来说,UniAct 证明了:通过离散码本抽象跨本体共享原子行为,可在不依赖动作空间归一化、不依赖规则后处理的条件下,实现高效率、高泛化、低成本的跨本体具身基础模型构建,为具身智能领域提供了全新的数据利用范式与模型设计思路。
写在最后
以上仅是詹仙园老师众多杰出研究成果中的一部分。在强化学习的基础理论与实际应用方面,他还贡献了一系列优秀工作,例如:
发表在 NeurIPS 2025 的《Towards Robust Zero-Shot Reinforcement Learning》,探讨了零样本情境下的策略鲁棒性问题; 发表在 ICRA 2025 的《H2O+: An Improved Framework for Hybrid Offline-and-Online RL with Dynamics Gaps》,提出了一种应对动力学差异的混合离线-在线强化学习新框架; 发表在ICLR 2026的《Sample Efficient Offline RL via T-symmetry Enforced Latent State-Stitching》是可以实现极小样本下鲁棒离线强化学习的全新算法; 发表在ICLR 2025的《Data Center Cooling System Optimization Using Offline Reinforcement Learning》这个是利用离线强化学习优化了数据中心的冷却系统控制与能耗,实现了2000+小时的稳定节能控制; 以及《Uni-RL: Unifying Online and Offline RL via Implicit Value Regularization》这篇是和UT Austin合作提出的统一在线-离线强化学习范式的全新强化学习框架。
此外,詹老师团队还有多项高质量工作在持续推进中,敬请期待后续成果。
整体来看,詹仙园老师的研究方向以自动驾驶与具身智能为核心,以强化学习的基础理论和方法研究、以及工业系统优化为支撑,形成了系统而富有前瞻性的研究布局。无论你是对上述领域充满兴趣的学习者、研究者,还是正在考虑考研或读博的同学,都可以从他的研究中获得宝贵的启发和参考。更多详细信息,欢迎访问詹老师的主页:https://zhanxianyuan.xyz/

自动驾驶之心
求点赞

求分享

求喜欢


