
🚗 自动驾驶遇上大语言模型,怎么还“听不懂人话”?理想汽车和浙大联手,刚刚在arXiv上放了个大招——LinkVLA。它让AI不仅“听懂”指令,更能“精准执行”,告别语言和动作的“鸡同鸭讲”。想第一时间拆解这种能解决实际痛点的顶会级论文?来龙哥星球,每日AI前沿论文、资讯、代码、招聘一站式搞定!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
这篇论文戳中了当前视觉-语言-动作(VLA)模型在自动驾驶应用中的一个核心痛点:语言指令与车辆动作严重错位。想象一下,你让车“向左变道”,它却直行,这谁受得了?LinkVLA从架构根源入手,提出了统一码本、双向对齐、粗到细生成三大创新,不仅在指令跟随成功率上大幅提升,还把推理速度提升了86%,真正做到了性能与效率的双赢。对于追求实用落地的自动驾驶研究,这篇工作提供了非常清晰且有价值的思路。
原论文信息如下:
论文标题:
Unifying Language-Action Understanding and Generation for Autonomous Driving
发表日期:
2026年03月
发表单位:
理想汽车 (Li Auto), 浙江大学 (Zhejiang University)
原文链接:
https://arxiv.org/pdf/2603.01441v1.pdf
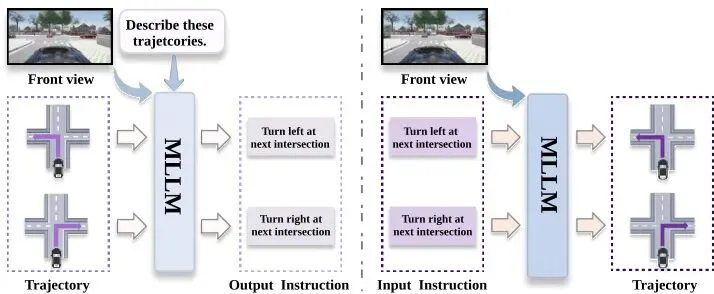
你开车的时候,有没有幻想过能用嘴“指挥”汽车?比如,前面路况复杂,你直接说一句:“减速,准备向左变道超车。”然后你的车就丝滑地完成了这套动作。听起来很美好对吧?但目前的AI司机(视觉-语言-动作模型,VLA)却常常上演“鸡同鸭讲”的戏码。你让它“向左变道”,它可能脑瓜子理解了,轮子却诚实地选择了直行。😒 这种语言指令和车辆动作之间的严重错位,成了VLA在自动驾驶领域落地的一大障碍。今天要聊的这篇论文,就是专门来治这个“听不懂人话”的毛病的。理想汽车&浙大联手,让AI开车告别“听不懂人话”
这篇名为《Unifying Language-Action Understanding and Generation for Autonomous Driving》的论文来自理想汽车(Li Auto)和浙江大学。他们提出了一种全新的架构——LinkVLA。痛点一:语言与动作“两张皮”模型理解了指令,但生成的轨迹就是“不听话”。
痛点二:动作生成“慢吞吞”传统的自回归生成方式,一步接一步地“吐”出路点,推理速度慢,难以实时应用。
那么,LinkVLA是怎么解决的呢?它祭出了三大法宝:法宝一:统一码本 —— 让语言和动作“说同一种语言”,从根源上消除隔阂。
法宝二:双向对齐训练 —— 不仅要“听令行事”,还得能“看图说话”,强迫模型真正理解两者关系。
法宝三:粗到细两步生成 —— 告别缓慢的自回归,先画“大纲”再填充“细节”,推理速度飙升86%。
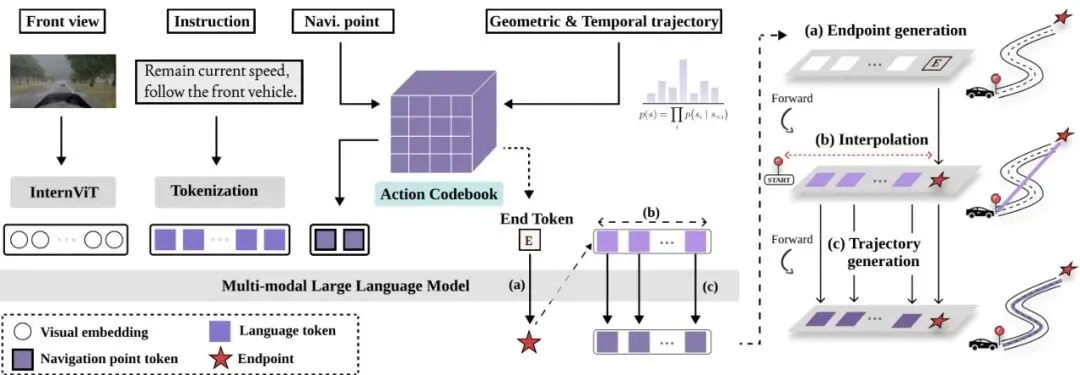
效果如何?在权威的自动驾驶仿真评测中,LinkVLA在指令跟随成功率、驾驶综合性能上全面领先,同时实现了高性能与低延迟的完美平衡。图2:LinkVLA的整体架构概览。模型包含一个预训练的视觉主干和一个大语言模型。核心是将语言token和动作token统一到一个共享的离散码本中。训练采用统一的语言-动作理解和生成目标。推理时采用高效的粗到细过程。核心设计:三大法宝,招招制敌
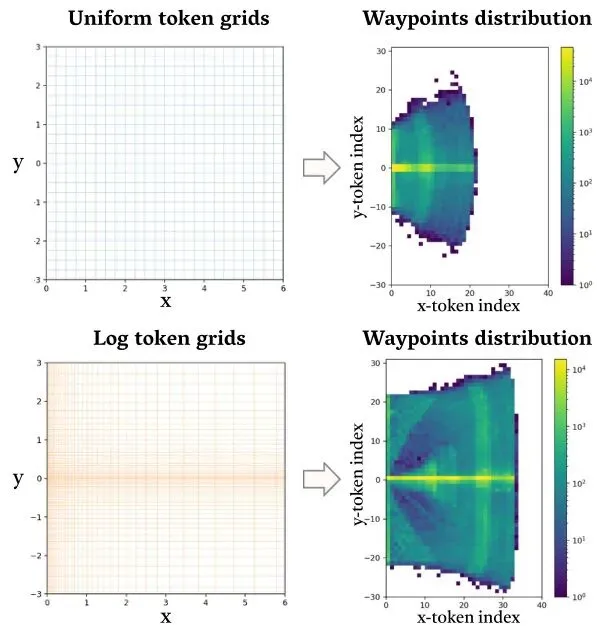
过去的VLA模型,语言和动作是两套系统。语言走LLM的文本词表,动作要么是连续的坐标,要么是另一套编码。这就像两个人在用不同的方言交流,容易产生误会。LinkVLA的解决办法很彻底:创造一个“普通话”码本。它把车辆前方鸟瞰图(BEV)空间划分成网格,每个格子对应一个唯一的“动作token”。这样,一条连续的轨迹就变成了一串离散的token序列。然后,把这个动作码本和原本的语言词表直接拼在一起,形成一个超大的统一码本。现在,模型处理“向左变道”这句话和处理“向左前方第5格”这个动作token,从根本的表示层面上就在同一个空间里了。这就强制模型在底层编码时,就把语言概念和空间位置关联起来。简单的均匀网格划分有两个问题:1)对近处(需要精细控制)和远处(粗略即可)给了同样的分辨率,浪费;2)硬性的one-hot标签丢掉了网格间的空间邻近关系。
1. 对数坐标变换:对坐标x, y分别做一个带符号的对数变换。公式如下:
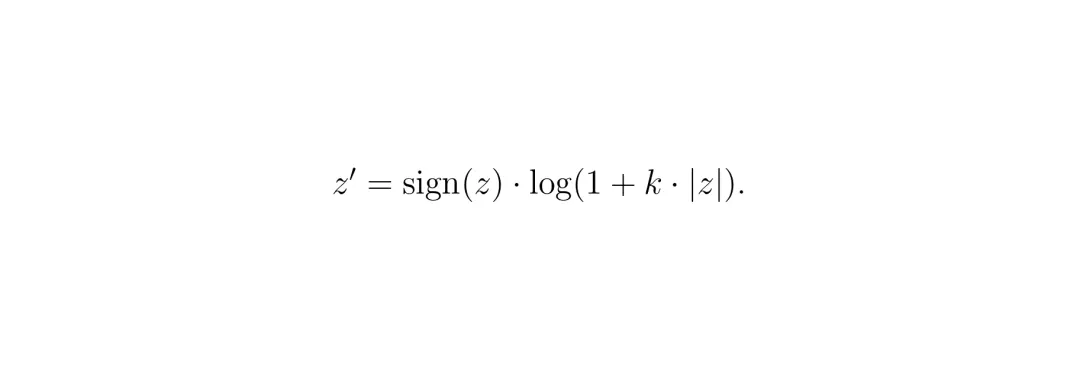 这个变换的妙处在于,它把靠近车辆原点(0,0)的区域“拉伸”了,而把远处的区域“压缩”了。这样在变换后的空间再做均匀网格划分,就相当于在原始空间里,离车越近网格越密,精度越高;离车越远网格越稀。这非常符合驾驶需求!
这个变换的妙处在于,它把靠近车辆原点(0,0)的区域“拉伸”了,而把远处的区域“压缩”了。这样在变换后的空间再做均匀网格划分,就相当于在原始空间里,离车越近网格越密,精度越高;离车越远网格越稀。这非常符合驾驶需求!
2. 空间软标签:在训练时,对于一个真实的路点,它的监督信号不是非此即彼的one-hot,而是一个以它为中心的高斯分布。公式如下:
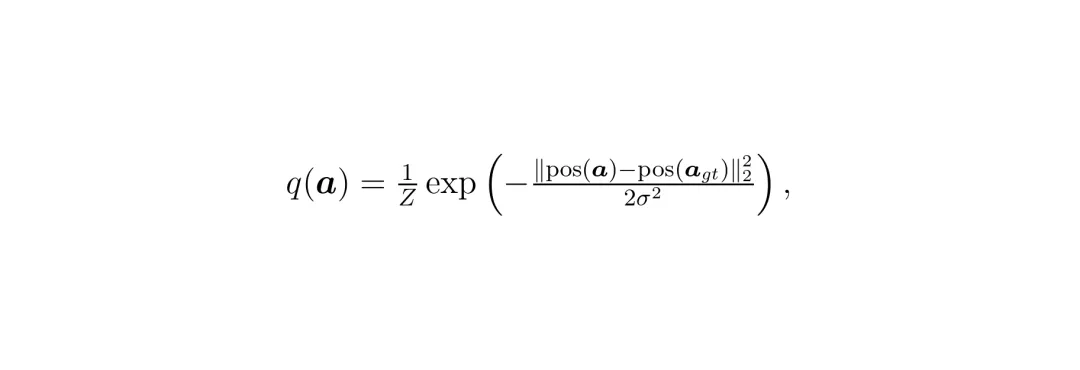 这个分布会对正确的网格赋予最高概率,同时也会给它的空间邻居分配一些概率。这样,模型学习到的动作空间就是平滑的,知道“向左前方第5格”和“向左前方第6格”是相似的,而不是完全独立的。这让模型更加鲁棒。图S1:均匀网格与对数变换网格的对比,以及每种网格下路点的分布情况。只有结构统一还不够,还得确保“普通话”说出来的意思是对的。LinkVLA借鉴了图像生成领域一个深刻的洞见:“文生图”和“图生文”这两个任务相互促进,能学到更好的跨模态表示。
这个分布会对正确的网格赋予最高概率,同时也会给它的空间邻居分配一些概率。这样,模型学习到的动作空间就是平滑的,知道“向左前方第5格”和“向左前方第6格”是相似的,而不是完全独立的。这让模型更加鲁棒。图S1:均匀网格与对数变换网格的对比,以及每种网格下路点的分布情况。只有结构统一还不够,还得确保“普通话”说出来的意思是对的。LinkVLA借鉴了图像生成领域一个深刻的洞见:“文生图”和“图生文”这两个任务相互促进,能学到更好的跨模态表示。· 动作生成(文生图):给模型看当前场景和一句指令(如“超过前方慢车”),让它生成轨迹。
· 动作理解(图生文):给模型看当前场景和一条已经执行了的轨迹,让它“猜”司机刚才收到了什么指令。
这个“动作理解”任务就是LinkVLA的创新点。它强迫模型去深入思考轨迹背后的意图,建立从动作空间反推语言语义的映射。当模型既能“听令行事”,又能“看图说话”时,它对语言和动作之间关联的理解就深刻多了,自然能更好地跟随指令。图3:动作理解(左)与动作生成(右)的示意图。两者共同训练,实现双向对齐。ℒ_total = ℒ_generation + λ * ℒ_understanding其中 ℒ_generation 是动作生成损失(用空间软标签的交叉熵),ℒ_understanding 是动作理解损失(标准语言生成交叉熵)。λ 是平衡两个任务的超参数。前面两大法宝解决了“不准”的问题,但VLA模型还有个“不快”的问题。传统自回归生成一条30个点的轨迹,就需要模型顺序“跑”30次,太慢了。LinkVLA的解决方案非常巧妙:把长序列的串行依赖,拆成两步走的并行计算。模型只做一次前向传播,直接预测出整个轨迹的最终目标点(终点)。然后,从车辆当前位置到这个预测终点,用一条简单的直线连接起来,并在这条直线上均匀采样出几个“粗”路点。这就得到了一个轨迹的“骨架”或“大纲”。现在,模型以这个“粗轨迹”为输入,在视觉和语言上下文的指导下,对每一个粗路点进行并行地、一步到位地“细化”。这个细化过程会考虑车道线、障碍物、交通规则,把那条生硬的直线,变成一条平滑、安全、符合指令的最终轨迹。这个方法之所以叫“Coarse-to-Fine”(C2F,粗到细),就是因为它的生成思路是先粗后细。它把原先T次的序列生成,变成了“1次(终点)+ 1次(并行细化)”,推理速度得到质的飞跃。实验结果:三项全能,全面领先
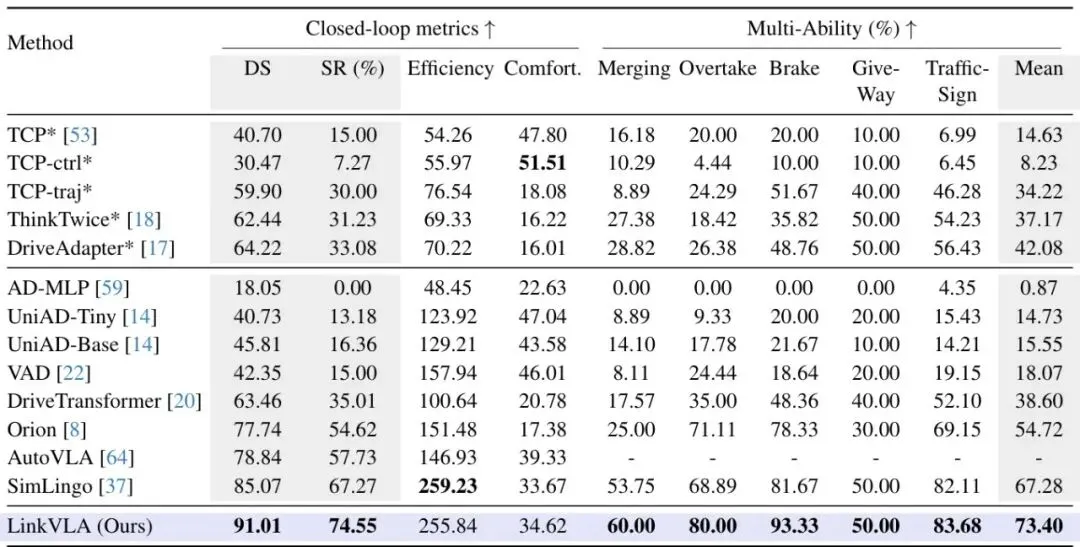
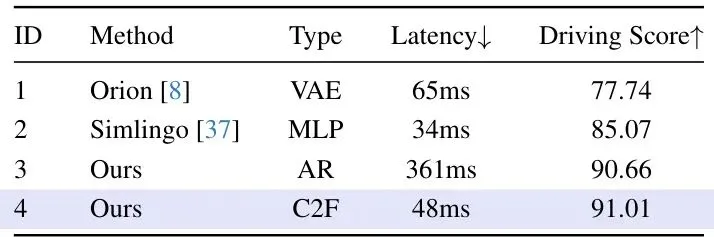
LinkVLA在自动驾驶领域权威的仿真平台CARLA上进行了闭回路评测,对比了包括TCP、UniAD、VAD、Orion、SimLingo等在内的众多SOTA方法。表1:在Bench2Drive基准上的主要结果和多能力评估。*表示使用了专家特征蒸馏。驾驶性能:LinkVLA取得了最高的驾驶得分(91.01)和成功率(74.55%),全面超越了之前的SOTA模型SimLingo(85.07和67.27%)。在变道、超车、刹车等各项交互能力上,LinkVLA也几乎都取得了最佳成绩。表2:性能与延迟对比。所有指标均在CARLA基准上评估。延迟是每步的平均推理时间,在H20 GPU上测量。推理效率:这是LinkVLA最亮眼的数据之一!如果不使用C2F方法,LinkVLA的自回归版本虽然性能高(驾驶得分90.66),但延迟高达361ms。而启用C2F后,延迟骤降至48ms,同时驾驶得分还提升到了91.01。对比最强的竞品Orion(65ms,得分77.74),LinkVLA在性能高出13.27分的同时,延迟还降低了26%。相比于最快的SimLingo(34ms),LinkVLA以仅增加14ms延迟的代价,换来了5.94分的性能大幅提升。C2F带来的加速效果高达约86%!指令跟随能力:论文在专门的指令跟随数据集上进行了测试。结果表明,逐步引入Token化、C2F和对齐训练,指令跟随成功率从70.11%稳步提升至87.16%。尤其是在“加速”、“变道”等具体指令上,LinkVLA展现出了惊人的准确率。表3:在Action Dreaming数据集上的指令跟随评估。Align.指统一对齐训练。消融实验:每个组件贡献几何?
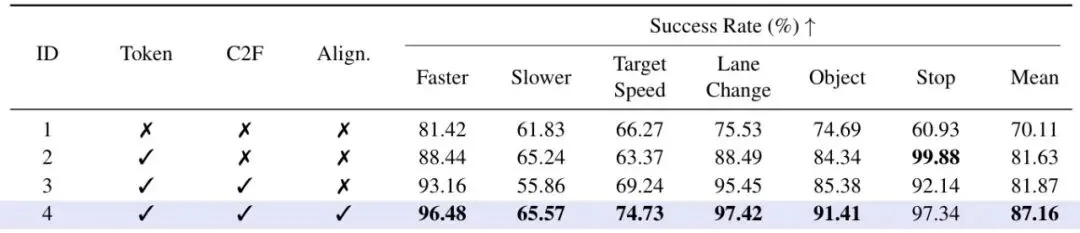
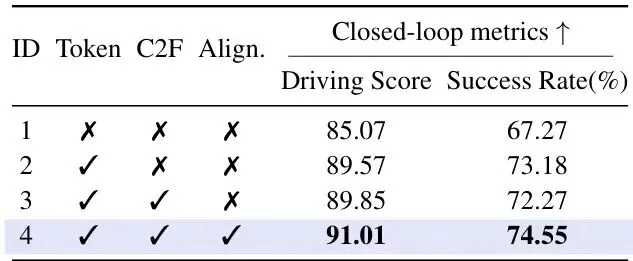
为了验证每个“法宝”的效用,论文做了详尽的消融实验。表5:闭回路性能消融研究,对比了我们提出的不同组件。
统一Token化是性能基石:仅引入Token化(ID 2),驾驶得分就从基线的85.07大幅提升至89.57,成功率从67.27%提升至73.18%。这说明将动作离散化并与语言统一表示,本身就是一项强大的性能提升手段。
C2F主要提效,对齐训练锦上添花:在Token化基础上加入C2F(ID 3),性能仅有微小变化。而当同时加入C2F和对齐训练(ID 4)时,才取得了最佳性能(91.01和74.55%)。这表明C2F的核心价值在于提升推理速度(表2已证明),而对齐训练则能进一步提升最终的性能上限和指令跟随的准确性(表3已证明)。
其他消融实验还验证了对数坐标变换、空间软标签等设计的有效性。所有组件的叠加,最终造就了LinkVLA的全面领先。图4:在不同语言指令下的挑战性环境中的可视化。生成的轨迹在复杂环境中准确遵循语言指令,同时保持安全可行。龙迷三问
这篇论文要解决的核心问题是什么?当前基于视觉-语言-动作(VLA)模型的自动驾驶系统存在两个关键问题:1)语言指令与车辆生成的行驶轨迹严重错位,即“听懂但做不到”;2)动作生成采用缓慢的自回归方式,推理延迟高,难以满足实时驾驶需求。
VLA和VLM是什么意思?VLM是Vision-Language Model(视觉-语言模型)的缩写,例如GPT-4V,它能理解图片并用语言描述。VLA是Vision-Language-Action(视觉-语言-动作)模型,是VLM的延伸,它不仅能理解,还能基于视觉和语言输入直接输出物理世界可执行的动作(如机器人抓取、车辆轨迹)。LinkVLA就是一个用于自动驾驶的VLA模型。
LinkVLA最主要的优势体现在哪里?可以总结为“高精度、低延迟、强对齐”三位一体。1)驾驶性能高:在闭回路评测中得分和成功率全面领先。2)推理速度快:粗到细生成方法将延迟降低86%,达到48ms的实用水平。3)指令跟随准:通过统一码本和双向训练,大幅提升了模型对复杂语言指令的理解和执行准确率。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★★ 将图像领域的“文生图/图生文”双向训练思想创造性地迁移到“语言-动作”对齐上,思路清晰且有效。统一码本从表示层面对齐,粗到细生成从效率层面优化,整套组合拳打得非常漂亮。
实验合理度:★★★★☆ 实验设计全面,在权威仿真基准上对比了当前主流VLA和端到端驾驶方法。消融实验详尽,清晰地展示了每个组件的贡献。唯一的扣分点在于所有实验均在CARLA仿真中进行,缺少真实路测数据佐证。
学术研究价值:★★★★★ 为解决VLA模型中的模态鸿沟问题提供了一个系统性的框架。其核心思想(统一表示、双向对齐、高效生成)不仅适用于自动驾驶,对机器人、具身智能等需要连接语言与物理动作的领域都有很高的借鉴价值。
稳定性:★★★☆☆ 在仿真的限定场景和指令集下表现出了很高的稳定性。但面对开放世界的无限长尾指令和极端复杂场景,其稳定性有待进一步验证。目前看是一个强而有力的研究原型。
适应性以及泛化能力:★★★☆☆ 方法本身具有通用性,但其性能严重依赖于训练数据(仿真驾驶数据+语言指令标注)。要迁移到新的城市、新的驾驶规则或新的指令表述,需要重新收集和标注大量数据,泛化成本较高。
硬件需求及成本:★★★☆☆ 模型基于现成的中小规模VLM(InternViT + Qwen2-0.5B),推理时使用C2F加速至48ms。这对于车载计算平台(如Orin)仍有压力,但已进入可优化、可讨论的范畴。训练成本因需要大量仿真交互数据而较高。
复现难度:★★★★☆ 论文方法描述清晰,技术细节充分(如公式、超参数)。但复现需要搭建完整的CARLA仿真数据采集管道,并具备处理大规模驾驶数据集的能力,门槛不低。
产品化成熟度:★★☆☆☆ 仍处于研究阶段。虽然性能优异且推理速度达到实用边缘,但距离上车应用还有“仿真到现实”的巨大鸿沟需要跨越,包括传感器差异、决策安全认证、接管逻辑、人类指令的模糊性处理等。
可能的问题:论文在定义“指令跟随成功”时,依赖于仿真环境中预设的、相对规整的指令和判定标准。在现实中,人类语言指令更加模糊、多样且依赖上下文,如何定义和评估“成功跟随”将是一个更严峻的挑战。
[1] Xinyang Wang, Qian Liu, Wenjie Ding, et al. Unifying Language-Action Understanding and Generation for Autonomous Driving. arXiv preprint arXiv:2603.01441, 2026. (本论文)*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

想让你的AI模型也像LinkVLA一样“知行合一”吗?🚗 来龙哥读论文粉丝群,和志同道合的伙伴一起交流自动驾驶、大模型、机器人等前沿技术!
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 自动驾驶+北京+理想汽车+龙哥),根据格式备注,可更快被通过且邀请进群。






 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
