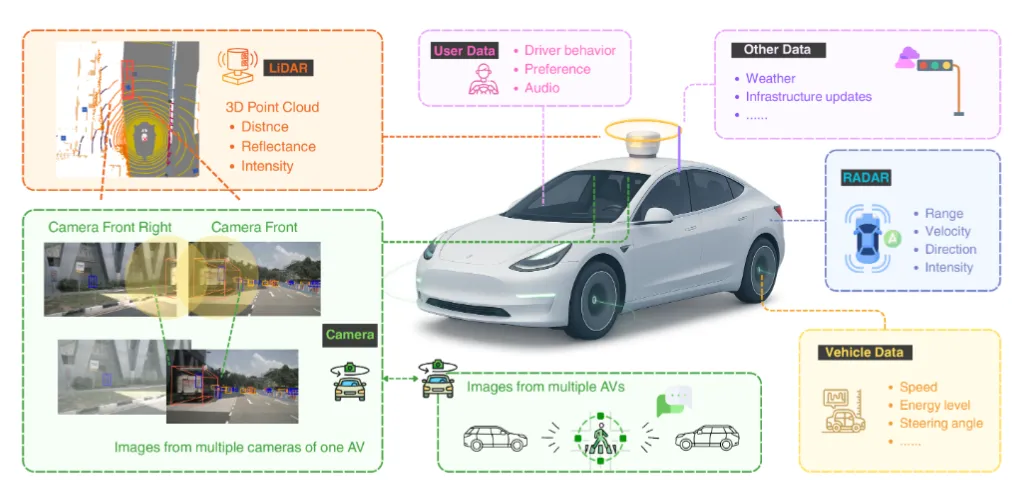
1. 冗余建模:多源与多模态的精准定义(真相1)
论文针对自动驾驶目标检测任务,明确多源(相机-相机)与多模态(相机-LiDAR)冗余的核心定义,为量化提供基础:
| | | |
|---|
| | 自动驾驶车辆配备多相机(如前视、左前视),视场存在重叠区域(如车头前方) | |
| 同一物理目标被图像与LiDAR同时检测,信息高度重叠 | 相机与LiDAR同步采集,近距目标在两种模态中均能清晰表征,信息互补性弱 | 模态冗余,表现为3D边界框覆盖同一目标,近距更显著 |
(1)数学形式化定义
- 多源数据冗余:设时间步的重叠相机对集合为,对于相机对,若两相机的重叠视场区域与检测到同一目标,则该目标标注为冗余;
- 多模态数据冗余:设同步图像与LiDAR点云,若相机检测的2D边界框与LiDAR检测的3D边界框对应同一目标,且信息重叠度超过阈值,则判定为冗余。
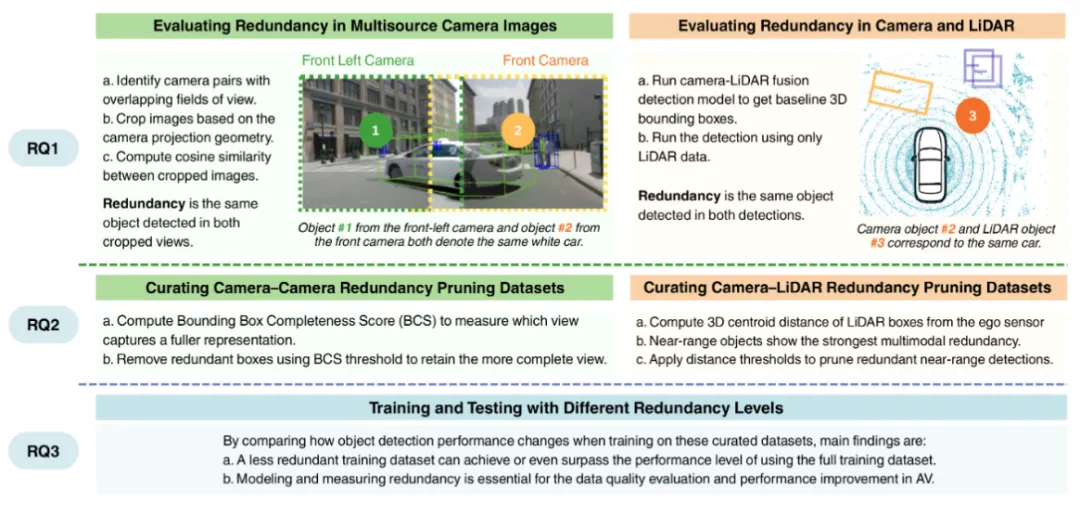
2. 量化与剪枝:任务驱动的精准筛选(真相2)
论文设计针对性量化指标与剪枝策略,确保“去冗余留关键”,不损失检测性能:
(1)多源相机冗余:边界框完整性评分(BCS)+ 阈值剪枝
核心逻辑:保留对目标表征更完整的相机视图,剔除重复冗余视图。
- 步骤1:识别重叠视场相机对,通过相机标定参数或3D标注投影,确定视场重叠区域;
- 步骤2:裁剪重叠区域图像,计算目标边界框完整性评分(BCS)——量化视图对目标的覆盖程度,得分越高表示表征越完整;
- 步骤3:设定BCS阈值,仅保留得分最高的视图对应的标注,移除其他相机的冗余标注。
(2)多模态冗余:3D中心距 + 距离阈值剪枝
核心逻辑:近距目标的图像与LiDAR表征冗余度高,远距目标互补性强,差异化剪枝。
- 步骤1:用相机-LiDAR融合检测模型获取基线3D边界框,单独用LiDAR数据检测获取LiDAR-only边界框;
- 步骤2:计算LiDAR边界框的3D中心到自车传感器原点的距离(egocentric distance);
- 步骤3:设定近距阈值,移除阈值内的LiDAR冗余标注(图像已能精准表征),保留远距目标的LiDAR标注(补充图像盲区信息)。
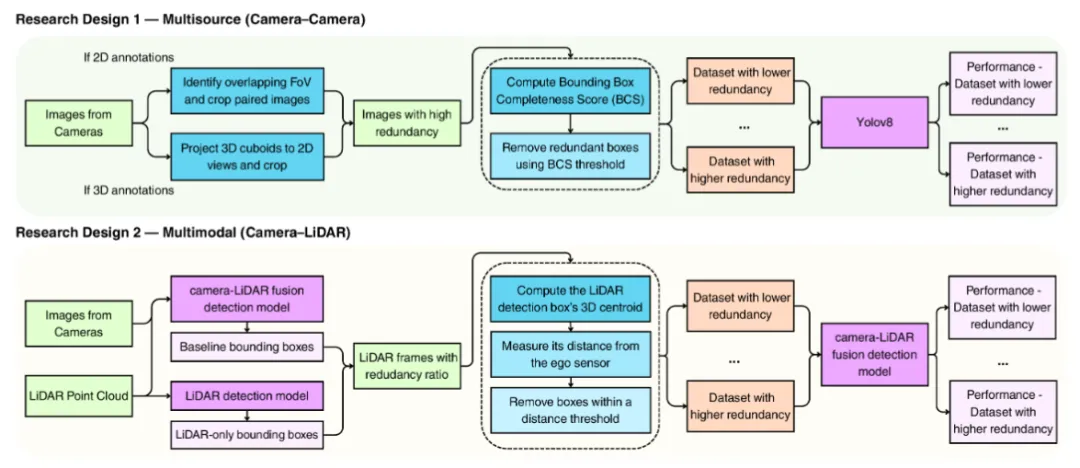
3. 实验设计:跨数据集验证框架有效性(真相3)
(1)实验配置
- 数据集:nuScenes-mini(6相机+1LiDAR,10场景404帧)、nuScenes-in-KITTI(KITTI格式适配,支持多模态验证)、Argoverse 2(9相机+2LiDAR,1000场景20000LiDAR序列);
- 模型:YOLOv8目标检测模型,训练批次16、迭代50轮,评估指标为mAP50(核心)与召回率;
- 变量:不同冗余剪枝强度(BCS阈值、距离阈值),对比全量数据与剪枝后数据的性能差异。
(2)核心实验结果
实验1:多源相机冗余剪枝(nuScenes)
实验2:多模态冗余剪枝(AV2)
实验3:冗余分布特征(多模态)
- 关键发现:近距目标(距离<10m)的图像-LiDAR冗余度最高,移除这部分LiDAR冗余标注对性能影响极小;
- 远距目标(距离>30m)的图像表征模糊,LiDAR标注的互补性强,冗余度低,需保留以提升检测召回率。
4. 优势机制:为何任务驱动剪枝优于传统方法?(真相4)
(1)针对性适配任务需求
传统剪枝基于图像相似度或IoU,忽视目标检测的核心需求——边界框完整性;BCS评分直接量化视图对目标的覆盖质量,保留高价值标注,剔除低质量冗余。
(2)差异化处理多模态特性
不同于简单移除重复标注,论文基于传感器物理特性(近距图像精准、远距LiDAR优势)设计距离阈值,既降低冗余,又保留模态互补性,平衡性能与效率。
(3)跨数据集泛化性强
框架不依赖特定数据集的传感器配置或标注格式,通过相机标定、3D投影等通用步骤适配nuScenes与AV2,为工业级应用提供可能。
关键内容
1. 数据集核心参数对比
| | | | | |
|---|
| | 6相机(12Hz)、1LiDAR、RADAR、GPS/IMU | | | |
| | | | | |
| | | | | |
2. 冗余剪枝策略对比
💬 Q&A
Q1:论文定义的多源/多模态冗余与传统冗余有何区别? A:核心区别在“任务针对性”与“传感器特性适配”:传统冗余多定义为“信息重复”,缺乏任务关联;而论文结合自动驾驶目标检测需求,明确多源冗余是“重叠视场中同一目标的重复标注”,多模态冗余是“近距场景中图像与LiDAR的信息高度重叠”,且冗余度与传感器探测距离、视场配置强相关。这种定义更贴合实际应用,避免了“为去冗余而去冗余”,确保剪枝后不损失关键感知信息。
Q2:BCS评分为何能有效指导多源相机冗余剪枝? A:BCS评分的核心价值是“量化标注质量而非单纯去重”:目标检测的核心是精准定位目标,边界框完整性直接反映视图对目标的表征质量——同一目标在不同相机视角下,可能因遮挡、角度问题导致边界框不完整,这类标注对模型训练价值低,反而会引入噪声;BCS评分筛选出边界框最完整的视图,既剔除了冗余,又保留了高价值标注,因此能提升模型性能。实验显示,基于BCS的剪枝使nuScenes部分区域mAP50提升4个百分点,验证了其有效性。
Q3:多模态冗余为何呈现“近距高、远距低”的分布特征? A:这一特征源于相机与LiDAR的传感器物理特性差异:① 近距场景中,目标在图像中像素占比高、细节清晰,能精准完成定位与分类;LiDAR点云对近距目标的覆盖密度高,但提供的信息与图像高度重叠,互补性弱,因此冗余度高;② 远距场景中,目标在图像中像素占比低、易受光照影响,表征模糊;而LiDAR不受光照限制,能精准测量目标距离与轮廓,提供关键空间信息,互补性强,因此冗余度低。论文的距离阈值剪枝策略正是基于这一特性设计,实现差异化冗余优化。
Q4:该冗余优化框架在工业化部署中还面临哪些挑战? A:核心挑战集中在自动化适配、动态场景适配与标注联动:① 自动化适配,BCS评分与距离阈值需根据不同传感器配置(如相机数量、LiDAR分辨率)手动调整,缺乏自适应机制,难以适配多样化车型;② 动态场景适配,现有实验基于静态数据集,真实驾驶中目标遮挡、光照变化会影响冗余度,框架的动态调整能力需验证;③ 标注联动,剪枝策略依赖高质量标注(如精准3D边界框),实际低质量标注可能导致冗余判断失误;④ 实时性,冗余量化与剪枝需在数据预处理阶段完成,大规模数据集下的计算效率需优化,避免拖慢训练流程。
Q5:该研究如何推动自动驾驶从“模型中心”向“数据中心”转型? A:传统自动驾驶研究侧重优化模型架构(如更深的网络、更复杂的融合策略),忽视数据质量对性能的影响;而该研究证实,数据冗余是关键质量因子,通过精准量化与剪枝,无需修改模型架构,即可提升检测性能或维持基线的同时降低成本。这一发现凸显了“数据治理”的重要性,引导行业从“盲目堆数据、堆模型”转向“精准用数据、优数据”,为数据中心AI在自动驾驶中的应用提供了实证支撑,后续可进一步拓展到数据偏差、标注错误等其他质量因子的优化。
🎯 点评
- 核心贡献:首次系统构建自动驾驶多源多模态数据的冗余建模-量化-剪枝框架,明确冗余定义与任务驱动的优化策略;跨数据集验证框架泛化性,证实冗余优化的实用价值;揭示多模态冗余的距离依赖特性,为差异化数据利用提供科学依据;推动行业关注数据质量,为自动驾驶数据治理提供全新视角。
- 亮点:① 问题定位精准,直击多源多模态数据的核心痛点,填补冗余量化领域的研究空白;② 方法实用性强,BCS评分与距离阈值策略计算简单、易工程实现,无需复杂硬件支持;③ 验证全面,覆盖不同传感器配置、数据集规模,结果可信度高;④ 价值导向明确,既提升性能,又降低标注、存储与计算成本,契合工业化需求。
- 不足:① 自适应能力弱,阈值参数需手动调整,缺乏针对不同车型的自动化适配机制;② 动态场景验证不足,未涉及真实驾驶中遮挡、光照变化等动态因素对冗余的影响;③ 未考虑标注质量差异,高质量标注假设可能与实际工业场景脱节;④ 仅聚焦目标检测任务,冗余优化对轨迹预测、语义分割等其他任务的适配性需进一步探索。
🌟 总结金句
自动驾驶感知的精准性,不仅源于强大的模型,更依赖高质量的数据——该研究以冗余量化为突破口,用任务驱动的剪枝策略“挤干数据水分”,既保留关键信息,又降低成本与延迟,证明了数据质量优化的巨大潜力,为自动驾驶从“模型中心”向“数据中心”转型提供了关键技术支撑。
📌 互动引导
你认为该冗余优化框架最需要优先突破的工业化落地瓶颈是什么?
● ✅ 自动化阈值适配(设计自适应机制,适配不同传感器配置);
● ✅ 动态场景适配(验证遮挡、光照变化下的冗余优化效果);
● ✅ 低质量标注鲁棒性(提升对噪声标注的冗余判断准确性);
● ✅ 多任务适配(扩展至轨迹预测、语义分割等任务);
● ✅ 大规模计算效率(优化冗余量化与剪枝的计算速度);
欢迎在评论区分享观点,一起探讨自动驾驶数据治理的落地路径 👇
🧩 思考/研究 Idea 彩蛋(可操作方向)
- 自适应阈值优化:基于强化学习设计自适应机制,自动调整BCS与距离阈值,适配不同车型传感器配置,适合投稿《IEEE Transactions on Intelligent Transportation Systems》;
- 动态场景冗余优化:结合实时感知结果,动态调整冗余剪枝策略,应对遮挡、光照变化,适合投稿《CVPR》;
- 低质量标注鲁棒性:引入噪声鲁棒性BCS评分,提升对标注误差的容忍度,适合投稿《ICCV》;
- 多任务冗余适配:扩展框架至语义分割、轨迹预测任务,设计任务专属冗余量化指标,适合投稿《NeurIPS》;
- 端到端冗余优化:将冗余判断融入感知模型训练流程,实现“数据筛选-模型训练”端到端优化,适合投稿《arXiv(后续转顶会)》;
- 联邦学习场景适配:在联邦学习中引入冗余剪枝,降低节点间数据传输量,提升训练效率,适合投稿《IEEE Internet of Things Journal》;
- 全生命周期数据治理:整合冗余、偏差、标注错误等多数据质量因子,构建全生命周期治理框架,适合投稿《Journal of Machine Learning Research》。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
