自动驾驶仿真新技术,世界通用模型,让智驾路上偶遇大象/犀牛/恐龙...
- 2026-03-16 23:42:11
本期转载一篇来自公众号【自动驾驶之心】的文章,文章格式略有变动。
先看图:

上面这个是原始驾驶视频 👆
下面这些是仿真生成的 👇

反事实生成:道路上出现大象

反事实生成:道路上出现犀牛

反事实生成:道路上出现恐龙
然后再来看看,上面这些仿真泛化场景是怎么产生的吧。
如下。
#自动驾驶仿真 领域长期面临三大挑战:
1. 多视角数据采集成本高2. Corner Case 覆盖困难3. 仿真与真实场景差距大
一套多视角采集系统动辄百万级成本,而实际路测中几乎不可能系统性地覆盖"大象横穿马路"这类极端场景。
今年 2 月,Waymo 联合 Google DeepMind 重磅发布了 Waymo World Model(Waymo的世界模型),基于 Genie 3 构建,能生成超逼真的多传感器仿真数据,把行车记录仪视频变成可控仿真环境,甚至能让大象、恐龙"上路"——为 Corner Case 验证提供了全新思路。

但 Waymo World Model 依赖闭源生态,数据和模型均未开放。我们能否不依赖闭源体系,用开放数据走出另一条路?
来自中科院自动化所和 CreateAI 的 NeoVerse 给出了回答:不依赖昂贵的多视角采集设备,而是从百万级互联网单目视频中学习,构建通用的 4D 世界模型,在自动驾驶仿真中实现了单目→多视角生成、长尾物体反事实场景构建、相机轨迹与焦距控制等核心能力——并且完全开源。
论文链接:https://arxiv.org/abs/2601.00393
项目主页:https://neoverse-4d.github.io
开源代码:https://github.com/IamCreateAI/NeoVerse
NeoVerse 自动驾驶应用展示
单目变环视:从行车记录仪视角到多目视角
环视多视角数据是感知训练和闭环仿真的基础,但现实中大量存量数据来自单目行车记录仪,难以直接用于多视角仿真。
NeoVerse 能从单个行车记录仪视频出发,通过 4D 重建与新视角生成,自动产出多个视角的仿真视频。这意味着大量的行车记录仪数据可以被低成本地转化为环视仿真资源,大幅扩展仿真数据的供给。这一能力与 Waymo World Model 提出的"Dashcam to Simulation"理念不谋而合——不同的是,NeoVerse 不需要闭源多视角采集系统。
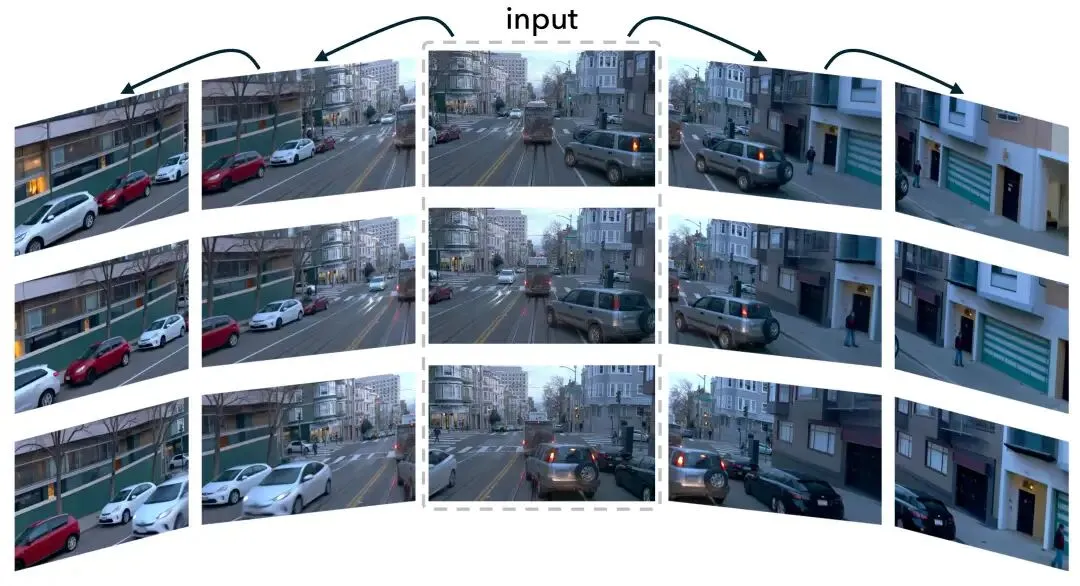
单视角生成多视角效果展示

行车记录仪视角

多视角生成对比
反事实 Corner Case 生成:大象、犀牛、恐龙直接"上路"
长尾场景覆盖是自动驾驶安全验证的核心挑战。真实道路上几乎不可能采集到"大象横穿马路"或"恐龙出现在路口",但自动驾驶系统必须具备应对能力。仅靠路测来覆盖这些场景,效率极低且不可控。
Waymo World Model 展示了在仿真中生成大象、穿着恐龙衣的行人等长尾场景的能力。NeoVerse 同样可以在真实驾驶场景中插入各类长尾物体,生成高保真的反事实视频——以下是在同一段真实驾驶视频中,分别插入大象、犀牛、恐龙后的效果:

原始驾驶视频

反事实生成:道路上出现大象

反事实生成:道路上出现犀牛

反事实生成:道路上出现恐龙
这些反事实场景生成为 Corner Case 的自动化构建提供了高效方案,能够系统性地扩展自动驾驶测试场景库。
自由视角漫游:支持任意相机轨迹渲染
仿真不仅需要固定视角。传感器位姿鲁棒性测试、场景理解可视化、数据增强等任务都需要灵活的视角控制能力。
NeoVerse 支持在重建的 4D 场景中进行任意相机轨迹的渲染,用户可以自由定义视角和路径,实现驾驶场景的多角度漫游。

场景1:原始视频 vs 自由相机轨迹

场景1:相机轨迹控制结果

场景2:原始视频 vs 自由相机轨迹

场景2:相机轨迹控制结果
场景编辑:精准修改场景元素
仿真数据多样化的一个常见需求是:同一个场景,能否快速生成不同的外观变体? 例如将前方车辆从白色修改为黄色或红色。
NeoVerse 结合 SAM2 等分割工具,可以对驾驶场景中的特定目标进行精准编辑,且编辑结果在时间维度上保持一致。这一能力可用于仿真数据多样化和数据增强。

原始驾驶视频

编辑效果:车辆变为黄色

编辑效果:车辆变为红色
相机抖动控制:按需去抖或加抖
行车记录仪视频常因路面颠簸产生抖动,影响后续处理和标注质量。传统 2D 稳像算法仅做像素级对齐,难以保证几何一致性。另一方面,在仿真中有时也需要反向操作——在平稳视频上人为添加抖动,模拟崎岖路段的采集效果,用于测试感知算法的鲁棒性。
NeoVerse 通过 4D 重建获取全局场景结构后,可以灵活地重新规划相机轨迹:既能平滑化处理崎岖路段的抖动视频,也能在正常行驶视频上施加抖动模拟崎岖路况——两个方向的控制均基于对场景 4D 结构的理解,而非简单的像素变换。

原始抖动视频

去抖处理结果

原始平稳视频

加抖处理结果
变焦控制:支持相机焦距动态调整
除了相机位姿控制,NeoVerse 还支持对相机焦距(视场角)的动态调整。在重建的 4D 场景中,用户可以自由切换不同焦距,实现从广角(短焦、大视野)到长焦(小视野、局部放大)的连续变焦效果。这一能力可用于仿真中不同传感器配置的模拟,以及对特定区域的细节观察。

原始视频

变焦效果:默认焦距 → 短焦(广角)→ 长焦(特写)
更多演示
更多演示视频
技术方案:重建-生成混合架构
NeoVerse 的核心思想是将 4D 重建与视频生成有机结合,构建"重建-生成"混合架构——让模型既能理解场景的 4D 结构,又能生成高质量的新视角视频。
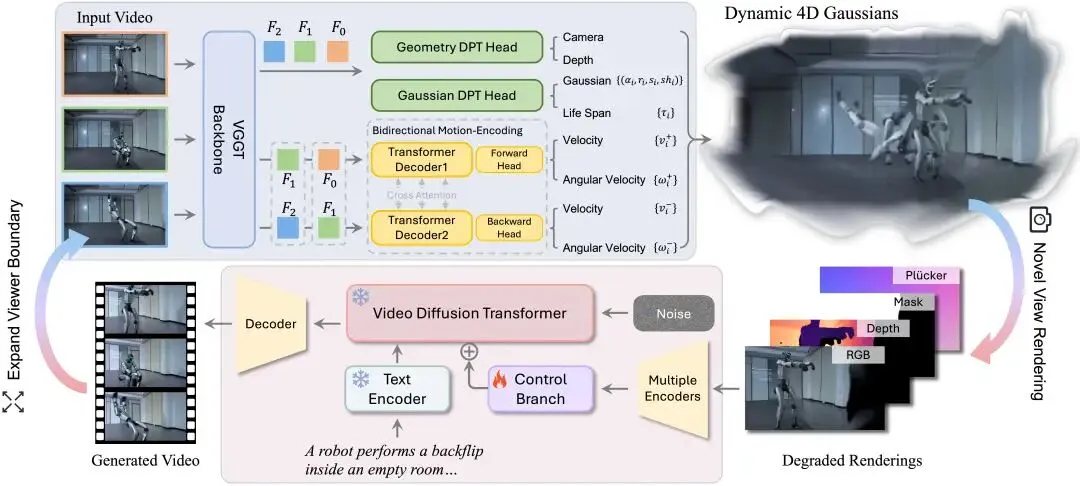
整体技术方案包含以下关键组件:
前馈式 4DGS 重建:基于 VGGT 构建免位姿的前馈式 4D Gaussian Splatting 重建器,输入一段单目视频,无需预估相机位姿,秒级(2-10 秒)完成 4D 场景重建。
双向运动建模:每个 4D Gaussian 额外携带双向速度、角速度和生命周期参数。通过交叉注意力机制同时建模前向(t→t+1)和后向(t→t-1)运动特征,精确描述动态场景中物体的运动。
稀疏重建 + 密集渲染:双向运动建模带来了时间插值能力——对稀疏关键帧重建后,通过双向运动对非关键帧进行 Gaussian 插值,实现密集帧渲染,显著提升训练效率。
在线单目退化模拟:要从百万级单目视频中学习,核心难题在于单目视频只有一个视角,如何构造"输入-目标"训练对?NeoVerse 通过三种机制解决:
基于可见性的 Gaussian 裁剪:模拟遮挡效应 平均几何滤波器:模拟飞边像素和几何畸变 退化渲染条件注入:将退化后的 RGB、深度图、不透明度掩码和 Plucker 嵌入作为条件输入

这套机制使模型能够从退化的单目渲染中学习恢复出高质量的多视角输出,从而让训练可以扩展到百万级互联网单目视频——这正是 NeoVerse 数据可扩展性的关键所在。
实验亮点:速度与质量双重领先
NeoVerse 在重建和生成两个维度均取得了 SOTA 表现:
✅ 重建质量:静态和动态场景重建 benchmark 均达 SOTA
✅ 生成质量:在 400 个样例中通过 Vbench 评测全面领先现有方法
✅ 推理速度:重建 2-10 秒 + 生成 18 秒 = 总计仅需 20-28 秒
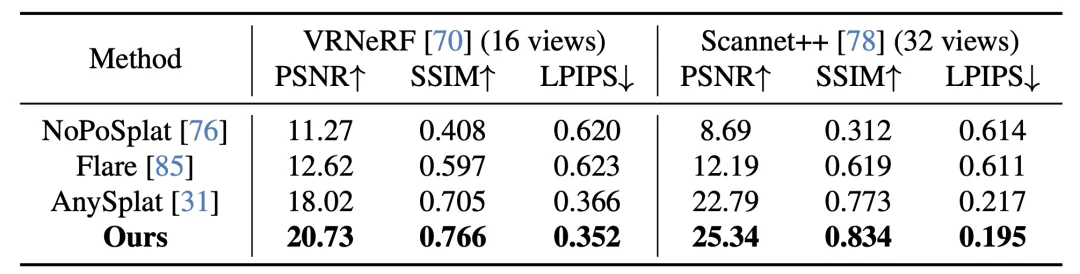
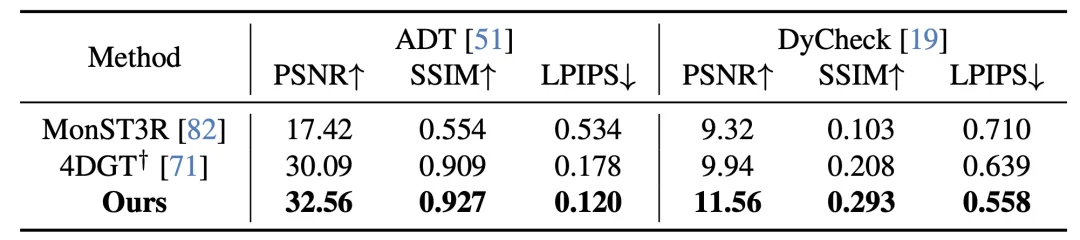

速度与质量的双重优势,使 NeoVerse 具备了实际部署自动驾驶仿真流水线的潜力。
一句话总结
NeoVerse 证明了不依赖闭源多视角采集系统,开放数据 + 开源代码也能构建强大的 4D 世界模型。
从单目行车记录仪视频出发,NeoVerse 以"重建-生成"混合架构为核心,高效实现了 4D 重建与多视角生成、反事实 Corner Case 构建、自由视角漫游、场景编辑、相机抖动控制和变焦调整等丰富应用。它与 Waymo World Model 的技术愿景高度一致,但走出了一条开放、可扩展、完全开源的路——降低了 4D 世界模型的技术门槛,也为社区提供了可复现的基线。
以上,原文完。





