自动驾驶的数据驱动开发体系建设
- 2026-03-16 23:42:28
上一篇为什么现有数据库,撑不起智能汽车的数据闭环?从数据基础设施选型的视角,对智能汽车数据闭环的业务背景、特点和挑战,以及数据库选型做了一些整理,本文从更加落地的视角,看下自动驾驶系统中的数据驱动开发体系建设。本文从建设目标、整体建设思路以及数据层架构三个方面,总结一套可供自动驾驶企业参考的数据驱动开发体系建设方法。下一篇会给出一个自动驾驶企业的实践案例。
一、数据驱动开发体系建设目标
自动驾驶数据体系的建设首先需要明确目标。从研发实践来看,核心目标主要体现在三个方面。
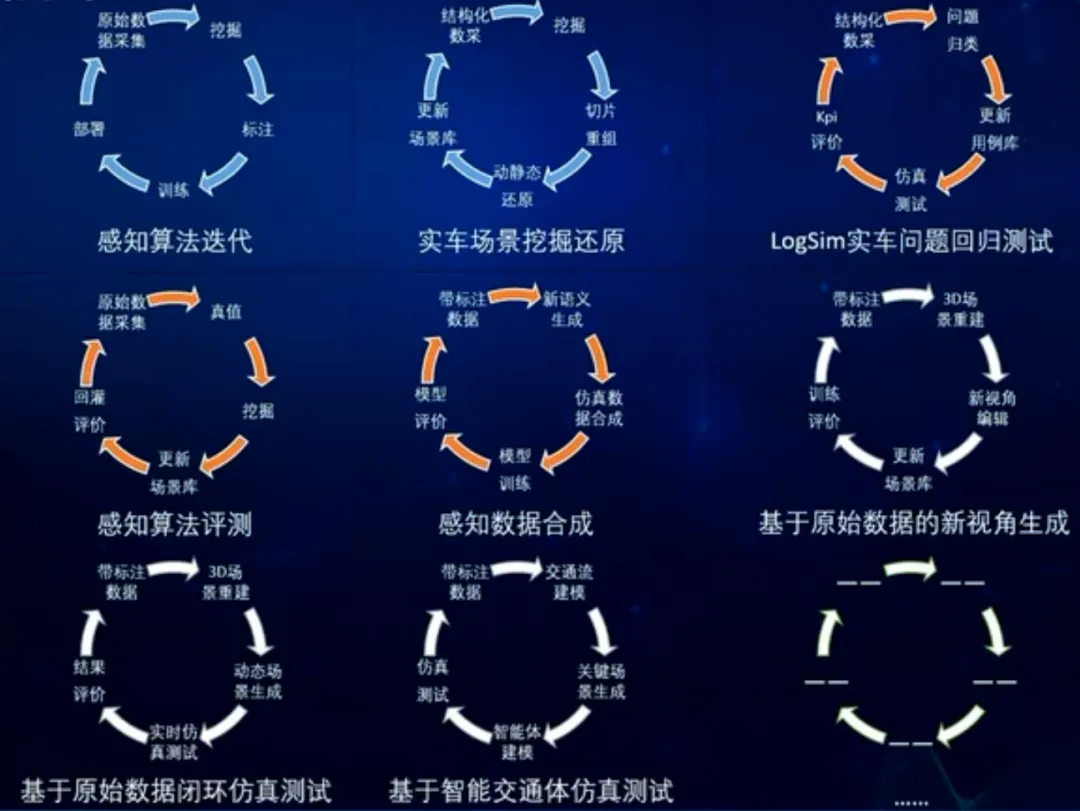
首先,需要支撑数据闭环中的多种业务场景。自动驾驶研发不仅仅是数据采集与模型训练,还涉及大量数据相关业务。例如数据标注、模型训练、仿真评测服务、基于视觉语言模型(VLM)的场景挖掘、仿真数据合成以及基于3D高斯重建的闭环仿真等。这些业务都会消费数据、生成新的数据,并不断反馈到研发流程中。因此数据体系必须能够同时支撑这些多样化的数据应用,而不是仅仅服务某一个单一环节。
其次,需要最大化数据资产复用。自动驾驶研发过程中会产生大量中间数据,例如自动标注结果、算法推理结果、场景标签、仿真数据以及向量特征等。如果这些数据只在某个系统中短暂存在,而无法被其他业务复用,就会造成巨大的资源浪费。因此数据体系必须能够沉淀数据资产,让不同业务可以基于同一份数据开展工作。
最后,数据体系需要具备面向未来发展的能力。随着自动驾驶技术的发展,数据的表达方式、数据来源以及数据应用方式都在不断增加。例如向量化表示、3D高斯场景表达、仿真生成数据等。同时新的业务需求也会不断出现,因此数据体系必须具备良好的扩展性,使新业务能够快速接入,而不需要频繁重构底层系统。
二、基本建设思路
为了实现上述目标,可以采用“数据层 + 服务层 + 平台层”的三层架构来构建自动驾驶数据体系。
最底层是数据层。数据层需要以场景为核心组织数据。在自动驾驶系统中,一组数据本质上是同一场景的不同模态表达,例如图像、点云、雷达信号、车辆状态以及各种结构化标签等。这些数据虽然形式不同,但描述的是同一段驾驶场景,因此需要使用统一的数据组织方式和统一的标签语言体系。通过这种方式,可以将不同来源、不同模态的数据统一管理,并保证不同系统之间的数据能够互相理解和复用。
第二层是服务层。服务层的核心职责是完成数据模态之间的转换,或者生成新的数据片段。从数据处理的角度来看,大多数服务都可以归纳为两类。一类是数据模态转换服务,例如自动标注、算法回灌、特征提取等,这类服务会将同一场景的数据从一种表达形式转换为另一种表达形式。另一类是新场景生成服务,例如仿真数据生成、世界模型生成场景、天气转换以及行为扰动等,这类服务会基于已有场景生成新的场景数据。
最上层是平台层。平台层主要面向具体业务需求,例如数据管理平台、训练平台、标注平台、仿真平台等。平台层通常会随着业务需求不断演进,其核心职责是为研发团队提供易用的工具和入口。而底层的数据层和服务层一旦设计稳定,就可以长期复用并支撑不同平台的发展。
三、数据层架构
在自动驾驶数据体系中,数据层是整个架构的基础,需要同时设计清晰的逻辑数据模型和可扩展的物理数据模型。
以场景为核心的数据组织方式
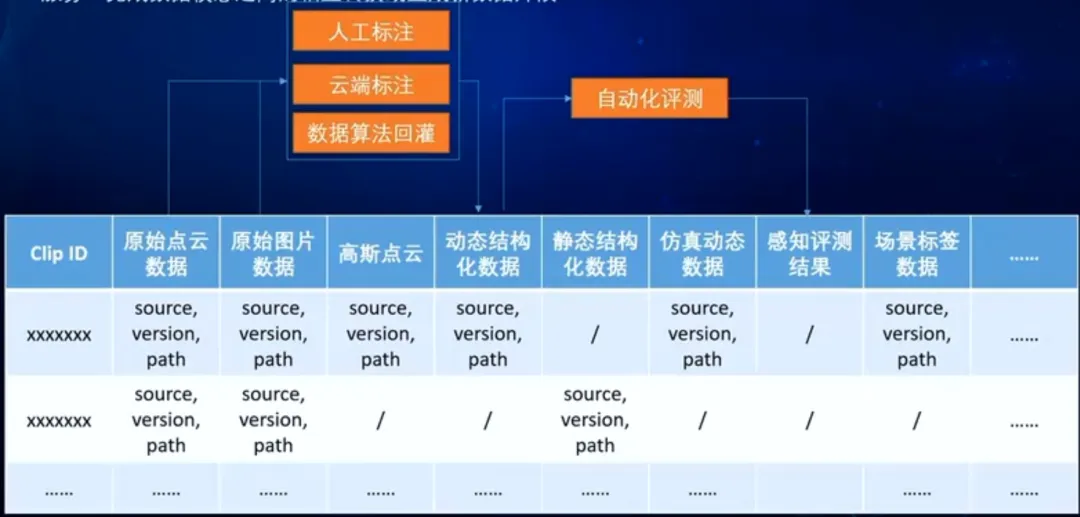
自动驾驶研发中最重要的实体其实不是单个数据文件,而是 场景(Scene)。数据平台应该以 Scene / Clip 为基本单位组织数据。一个场景可能包含:原始相机图像、点云数据、目标检测标签、OCC标签、向量特征、仿真重建数据等。
这些数据本质上是 同一场景的不同模态表达。
图片来源:https://www.bilibili.com/video/BV16c87z6EQy
逻辑数据模型
逻辑数据模型上,有三个最重要的核心实体:Clip、帧和标签。
Clip(也可以称为Scene或Asset)表示一段连续的驾驶场景,是数据组织的基本单位。Clip通常由车辆ID和时间段唯一标识。Clip由帧(Frame)组成,除了帧级数据外,Clip还会包含大量元数据,例如车辆信息、软件版本、GPS轨迹、事件信息等,这些信息能够帮助研发人员快速理解和检索场景。 帧,每一帧对应某一个时间点的车辆状态,例如相机图像、雷达信号、激光雷达点云、车辆控制信息等。 标签,帧之上会附带各种标签信息,例如目标检测标签、车道线标签、轨迹标签以及场景标签等。
物理数据模型
在物理数据模型上,可以根据数据类型将数据划分为四类。
第一类是原始数据,主要包括车辆上传的传感器数据,例如图像、点云和雷达数据,这类数据通常规模最大,往往达到PB级。 第二类是结构化数据,通过解析原始数据并进行ETL处理后生成,例如各种标签、特征以及统计数据。 第三类是向量数据,通过视觉语言模型或其他特征提取模型生成,用于相似场景检索和数据挖掘。 第四类是元数据,包括车辆状态、事件信息、标签信息等,用于快速检索和组织场景数据。通过这种物理数据模型,可以在保证存储效率的同时,为不同业务提供高效的数据访问能力。
目前很多企业的这个物理数据模型,往往采用了四种不同类型的存储系统或数据库,也有部分企业开始实践使用SelectDB\Doris这样的数据库,统一结构化数据、向量数据、元数据的存储和检索。
通过以上逻辑和物理模型的设计,数据层可以成为自动驾驶数据驱动开发体系的稳定基础,并为上层服务和平台提供统一的数据支撑。对于平台层来说,就是对Clip的正向和反向查询。可以根据Clip的唯一标识,可以找到这个Clip的原始数据、结构化标签、向量、元数据等,对平台层都是统一视图。同理,也可以基于结构化标签、向量、元数据对Clip进行检索和分析。

