
🐉 龙哥读论文知识星球来了!自动驾驶规则打架,AI该“死机”还是“闯关”?星球里不仅有这篇论文的深度拆解,更有海量自动驾驶、机器人、大模型等前沿论文、资讯、开源代码和招聘信息,一站式解决你的信息焦虑!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
这篇论文戳中了自动驾驶落地的一个核心痛点:当多条安全规则和任务目标在现实中“打架”时,AI控制器该怎么办?是直接“死机”停车(这本身就很危险),还是莽撞“闯关”?本文提出的两阶段框架给出了一个优雅且实用的解决方案,不仅让系统在冲突中“活”下来,还能做出更优的“妥协”决策,对于提升自动驾驶在复杂场景下的安全性和可靠性具有重要参考价值。
原论文信息如下:
论文标题:
Feasibility Restoration under Conflicting STL Specifications with Pareto-Optimal Refinement
发表日期:
2026年03月
发表单位:
Stanford University 等 (根据论文作者信息推断)
原文链接:
https://arxiv.org/pdf/2603.06947v1.pdf
现实痛点:当规则打架,自动驾驶该“死机”还是“闯关”?
想象一下,你开着车,前方突然有行人横穿马路,你下意识要刹车。但后视镜里,一辆救护车正闪着灯紧急驶来,你不能原地急刹挡住“生命通道”。路两边还停满了车,无处可躲。😨 那一刻,你的大脑是不是也瞬间过载:刹,会挡救护车;不刹,可能撞行人;变道,又违法压实线。 这就是典型的“规则冲突”场景。对于人类司机,我们或许会凭经验和直觉做出一个“权衡”(比如轻微减速同时尽量靠边,祈祷行人和救护车司机也配合)。但对于依赖精确规则和优化的自动驾驶系统(尤其是基于模型预测控制的控制器),问题就大了。为了让AI守规矩,工程师们会用一种叫 信号时序逻辑(Signal Temporal Logic, STL)的“数学语言”来编写各种规则,比如“永远别压线”、“10秒内到达目标”、“始终与行人保持2米以上距离”。STL的厉害之处在于,它不仅能判断规则是否被违反,还能给违反的“严重程度”打个分,这个分数叫做鲁棒度。当所有规则都能被满足时,控制器开开心心算出一条最优路径。可一旦像上面那样规则“打起架来”,没有任何一条路径能同时满足所有STL约束,控制器解方程就直接“无解”了。这时,很多系统会采取一个保守的“死机”策略:原地停车或等待。这在现实中非常危险!论文里就提到了旧金山和奥斯汀的真实案例:自动驾驶出租车因为规则冲突而“冻结”在路中间,挡住了正在执行任务的救护车。这比人类司机做出一个可能不完美、但能动的决策还要糟糕。所以,核心痛点就是:当多条安全、交规、任务目标在现实世界中无法同时满足时,自动驾驶系统如何不“死机”,而是做出一种可解释、可权衡的“最优妥协”? 斯坦福的这篇论文,就是来回答这个问题的。核心方案:两阶段破局,先“保底”再“择优”
本论文的思路非常清晰,就像一个高明的谈判专家或交警处理突发事故:第一步,先确保交通不彻底瘫痪(恢复可行性);第二步,在能动的方案里,找一个综合危害最小的(帕累托优化)。它把STL规则分成了两类:
1. 不可谈判的硬约束:比如车辆动力学极限(不能飞起来)、保持在可行驶区域内。这些是物理红线,死也不能违反。
2. 可以谈判的软约束:比如“不压线”、“让行”、“保持安全距离”。这些是社会规则或任务目标,在极端情况下可以“略微通融”,但要付出代价。
当控制器发现所有规则无法同时满足(原问题无解)时,启动这个阶段。它的目标很简单:找到那个能让系统“动起来”的、对软约束违反总量最小的方案。具体做法是,给每个可谈判的软约束 φ (比如“与行人距离≥2米”) 引入一个“松弛变量” δ_φ ≥ 0。原来要求鲁棒度 ρ_φ ≥ 0(完全满足),现在放宽到 ρ_φ ≥ -δ_φ(允许你违反一点,违反程度就是δ_φ)。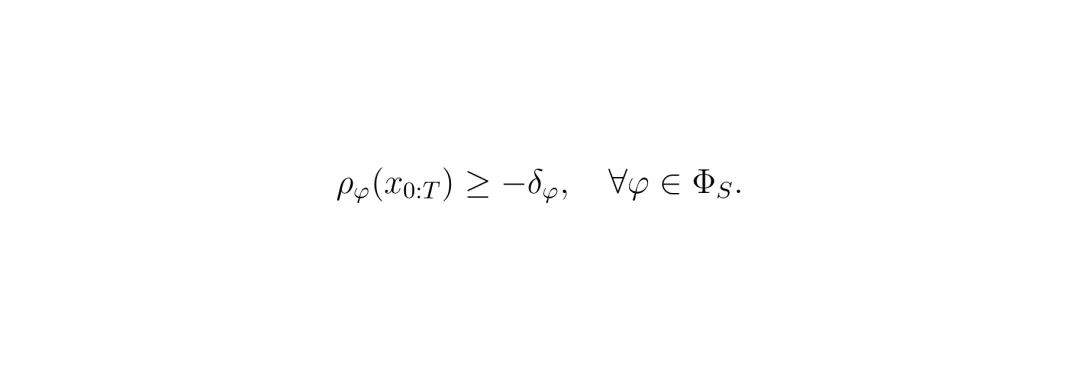 然后,控制器求解一个新的优化问题:在满足所有硬约束的前提下,寻找一组控制指令和松弛变量,使得所有松弛变量的总和(L1范数)最小。 这个最小值记为 Δ_min。
然后,控制器求解一个新的优化问题:在满足所有硬约束的前提下,寻找一组控制指令和松弛变量,使得所有松弛变量的总和(L1范数)最小。 这个最小值记为 Δ_min。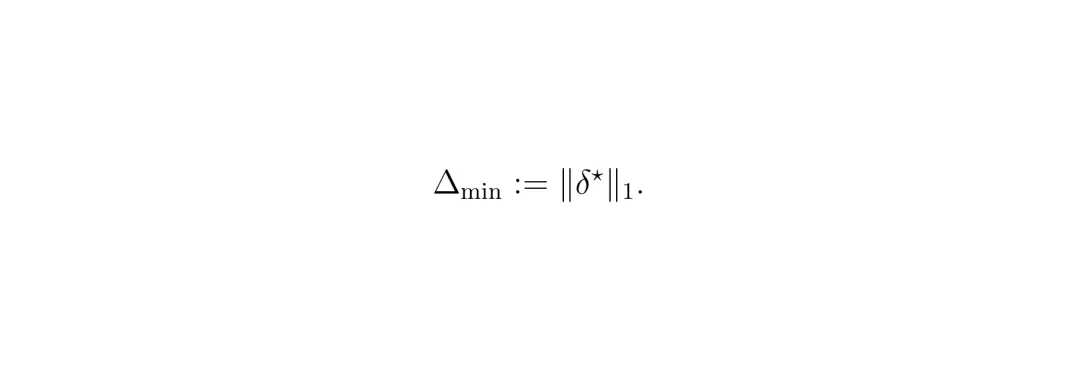 Δ_min = 0 意味着规则本来就不冲突,皆大欢喜。Δ_min > 0 则意味着冲突确实存在,且这个值就是让系统恢复运行所必须的“最小违规成本”。 这解决了“死机”问题,保证了系统至少能动,而不是僵在原地。但只做到“能动”还不够。第一阶段只关心“总共违规了多少”,并不关心“违规的代价是什么”。比如,同样是总共违规5个单位,是轻微压线但避免了事故,还是严重靠近行人但守住了交规?二者后果天差地别。因此,第二阶段引入了一个后果目标向量 g(u, δ)。它不再直接优化松弛变量本身,而是优化这个决策带来的实际后果,比如“对行人的碰撞风险”、“对后方救护车的风险”、“任务进度”等。
Δ_min = 0 意味着规则本来就不冲突,皆大欢喜。Δ_min > 0 则意味着冲突确实存在,且这个值就是让系统恢复运行所必须的“最小违规成本”。 这解决了“死机”问题,保证了系统至少能动,而不是僵在原地。但只做到“能动”还不够。第一阶段只关心“总共违规了多少”,并不关心“违规的代价是什么”。比如,同样是总共违规5个单位,是轻微压线但避免了事故,还是严重靠近行人但守住了交规?二者后果天差地别。因此,第二阶段引入了一个后果目标向量 g(u, δ)。它不再直接优化松弛变量本身,而是优化这个决策带来的实际后果,比如“对行人的碰撞风险”、“对后方救护车的风险”、“任务进度”等。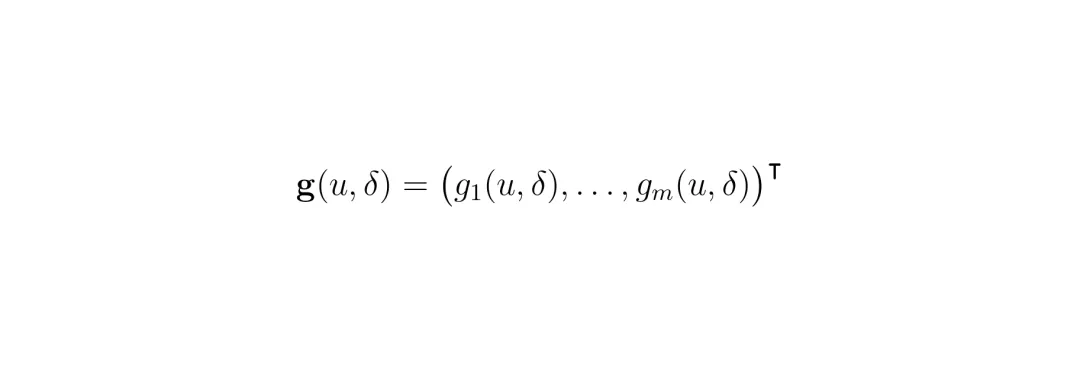 然后,它在一个允许的松弛预算内(比如从 Δ_min 到 Δ_min+α),寻找帕累托最优解集。什么是帕累托最优?简单说就是:在解集里,你找不到另一个解能在不损害任何一个其他目标的情况下,让某个目标变得更好。论文使用经典的 ε-约束法 来近似求解这个帕累托前沿。最终,系统不是只给出一个“最优”解,而是呈现一组最优权衡方案及其对应的后果(比如,方案A:行人风险低但救护车延误高;方案B:反之)。上层决策者可以根据具体场景的价值取向(例如,生命权优先于通行效率)从中选择最终执行的动作。这个两阶段框架的精妙之处在于:第一阶段负责“保底”(找到可行域),第二阶段负责“择优”(在可行域内找高质量的解),并且整个过程是可解释的——为什么选这个动作?因为它在所有能动的方案里,对各项风险的综合权衡最好。
然后,它在一个允许的松弛预算内(比如从 Δ_min 到 Δ_min+α),寻找帕累托最优解集。什么是帕累托最优?简单说就是:在解集里,你找不到另一个解能在不损害任何一个其他目标的情况下,让某个目标变得更好。论文使用经典的 ε-约束法 来近似求解这个帕累托前沿。最终,系统不是只给出一个“最优”解,而是呈现一组最优权衡方案及其对应的后果(比如,方案A:行人风险低但救护车延误高;方案B:反之)。上层决策者可以根据具体场景的价值取向(例如,生命权优先于通行效率)从中选择最终执行的动作。这个两阶段框架的精妙之处在于:第一阶段负责“保底”(找到可行域),第二阶段负责“择优”(在可行域内找高质量的解),并且整个过程是可解释的——为什么选这个动作?因为它在所有能动的方案里,对各项风险的综合权衡最好。技术细节:如何量化“违规”与“风险”?
框架听上去很美,但要把“违规”和“风险”变成控制器能懂的数学语言,需要精巧的设计。这里涉及到两个核心量化:STL规则的鲁棒度和第二阶段后果目标中的风险。STL公式由一些基本元素通过逻辑和时序操作符组合而成。比如“最终到达目标区域”可以写作 F_[0,T] (x_ego ∈ R_goal),“始终与行人保持安全距离”可以写作 G_[0,T] (d(x_ego, x_ped) ≥ d_safe)。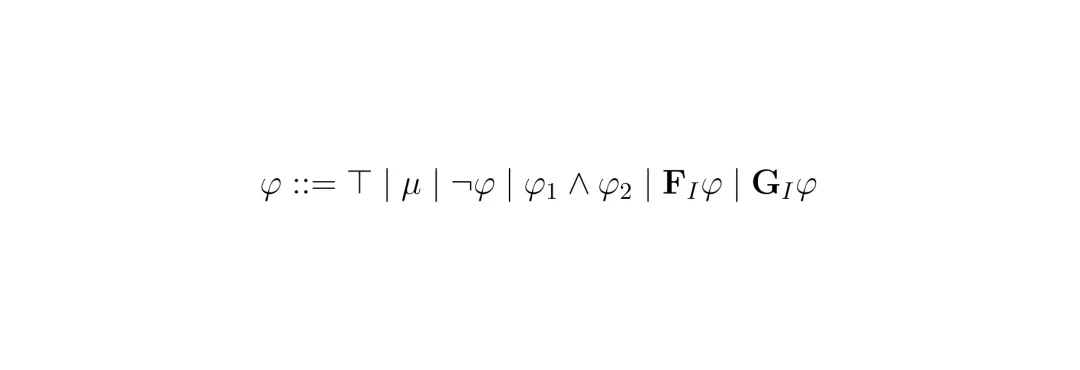 它的定量语义(鲁棒度)递归定义如下。这个定义保证了:鲁棒度 ρ ≥ 0 当且仅当规则被满足;ρ < 0 则表示违反,且 |ρ| 越大,违反得越严重。关键性质:ρ(φ,S,t) ≥ 0 ⇔ (S,t) ⊨ φ。 这就像给每条规则装了个带刻度的“体温计”,不仅能告诉你“发烧了”(违规),还能告诉你“烧到多少度”(违规程度)。
它的定量语义(鲁棒度)递归定义如下。这个定义保证了:鲁棒度 ρ ≥ 0 当且仅当规则被满足;ρ < 0 则表示违反,且 |ρ| 越大,违反得越严重。关键性质:ρ(φ,S,t) ≥ 0 ⇔ (S,t) ⊨ φ。 这就像给每条规则装了个带刻度的“体温计”,不仅能告诉你“发烧了”(违规),还能告诉你“烧到多少度”(违规程度)。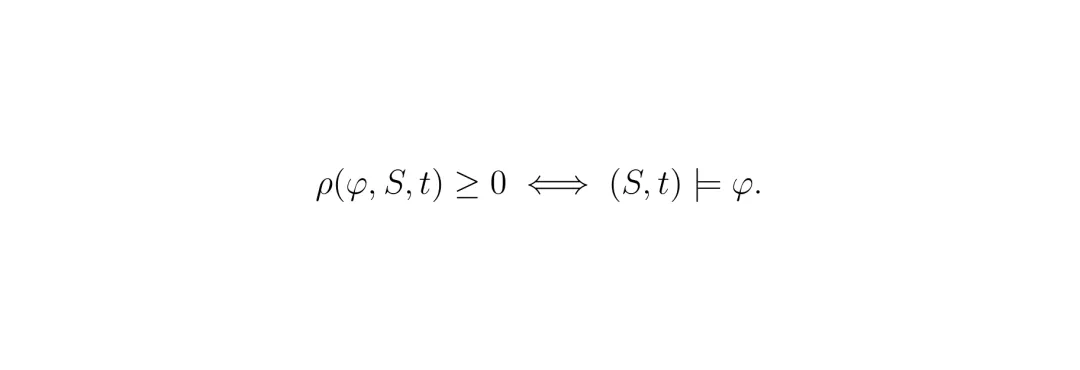 第二阶段要优化的后果目标 g(u, δ),在自动驾驶场景下,核心是对不同交通参与者的风险。论文提出了一个综合风险度量 R_j(u) 用于评估对第 j 个周围车辆/行人造成的风险:
第二阶段要优化的后果目标 g(u, δ),在自动驾驶场景下,核心是对不同交通参与者的风险。论文提出了一个综合风险度量 R_j(u) 用于评估对第 j 个周围车辆/行人造成的风险: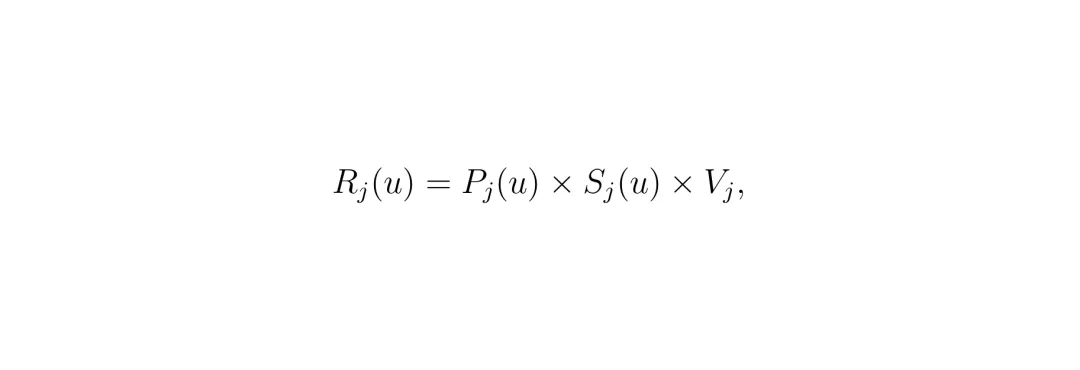 这个公式拆解开来非常直观,体现了工程上的深思熟虑:
这个公式拆解开来非常直观,体现了工程上的深思熟虑:
1. 碰撞概率 P_j(u):通过对周围车辆未来轨迹进行随机采样(加入速度高斯噪声),统计与自车预测轨迹发生“接触”(距离小于安全阈值 d_safe)的样本比例。这是一种基于采样的近似方法。
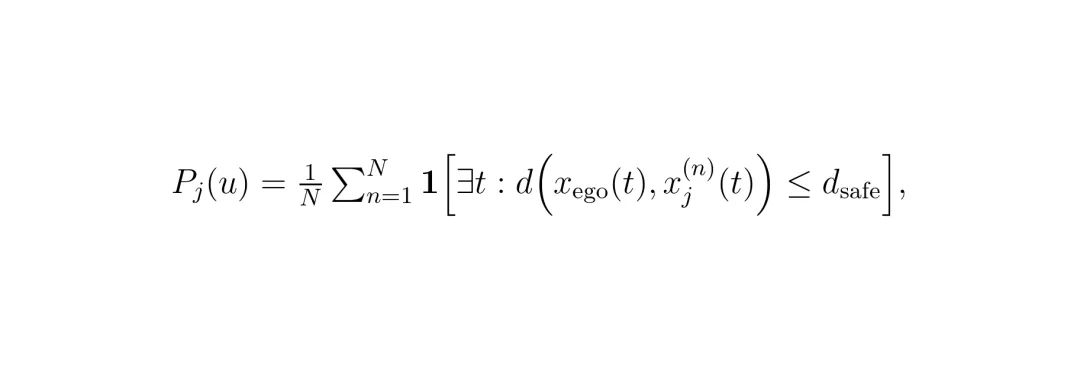
2. 碰撞严重程度 S_j(u):只针对那些发生碰撞的样本,计算碰撞瞬间的相对动能(通过简化后的约化质量 μ_j 和相对速度来表征),然后归一化到[0,1]区间。速度越快,质量越大,严重程度越高。
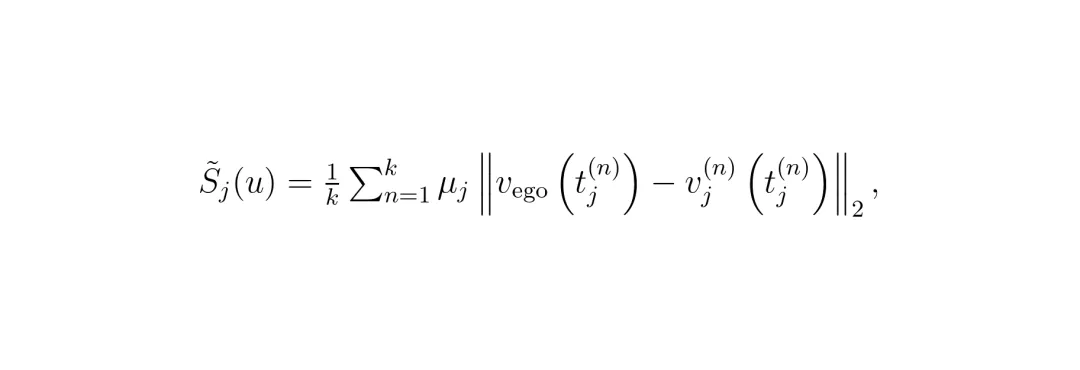
3. 脆弱性 V_j:这是一个先验知识,表示不同交通参与者自身的易受伤程度。行人、自行车骑手几乎“裸奔”,V_j 接近1;坐在钢铁车身里的司机有一定保护,V_j 较小。论文用公式 V_j = 1/(1+κ_type) 来计算,其中 κ_type 是保护系数。
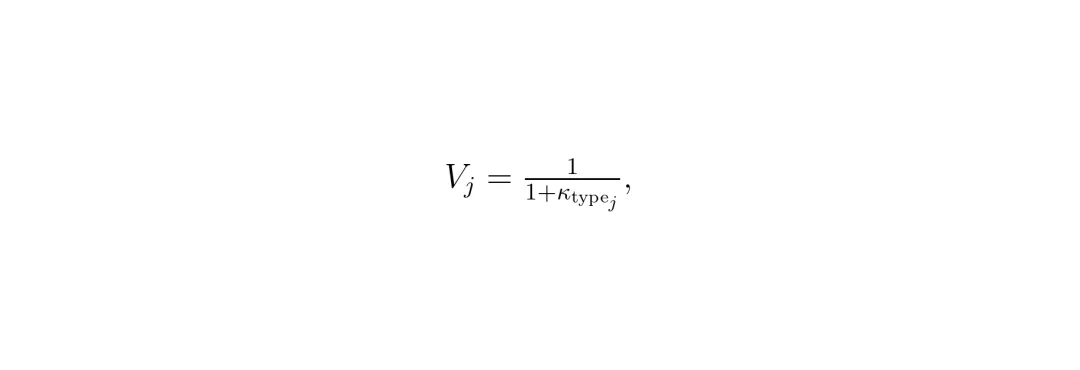 将三者相乘,得到的 R_j(u) 就是一个既考虑事故发生可能性,又考虑事故后果严重性,还兼顾了道德伦理层面(对弱势道路使用者的保护)的综合风险指标。 第二阶段优化,本质上就是在不同方案间权衡这些针对不同对象的 R_j 值。
将三者相乘,得到的 R_j(u) 就是一个既考虑事故发生可能性,又考虑事故后果严重性,还兼顾了道德伦理层面(对弱势道路使用者的保护)的综合风险指标。 第二阶段优化,本质上就是在不同方案间权衡这些针对不同对象的 R_j 值。实验验证:从“可行”到“最优”的跨越
理论需要实践检验。论文设计了两个经典的自动驾驶冲突场景,以滚动时域(MPC)的方式运行提出的两阶段框架,并与仅使用第一阶段(最小松弛)的结果进行对比。场景:自车要通过无信号灯路口,后方有紧急救护车,两侧停满车无法靠边。此时,一名行人突然开始横穿路口。
规则冲突:“到达目标”(尽快通过)、“与行人保持安全距离”、“与救护车保持安全距离”三者无法同时满足。硬约束是“保持在可行驶车道内”。
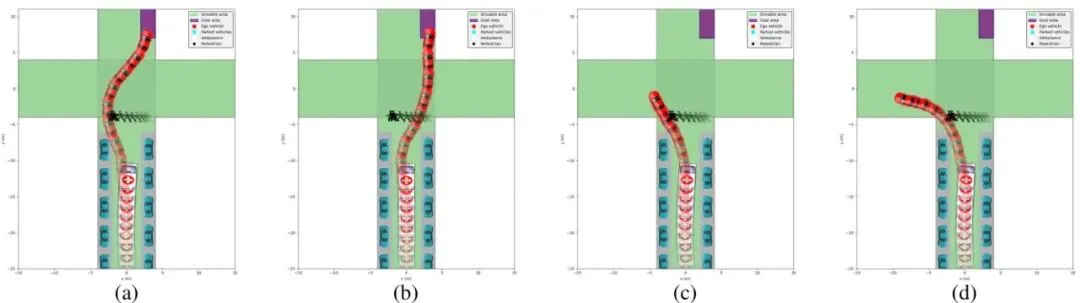
下图展示了在该场景下,通过ε-约束法生成的一系列可行轨迹,并标识了帕累托最优解。
图(a)-(c) 非帕累托最优解:它们都满足了最小松弛要求(能动了),但在风险权衡上存在缺陷。(a)左转加速,虽避开行人但高速接近交互区,增加了碰撞严重性风险。(b)右转直行,产生了不同的空间风险分布。(c)减速但停在行人行进方向上,且急刹增加了被救护车追尾的风险。
图(d) 帕累托最优解:选择了一个平滑左转并轻柔减速的轨迹。它平衡了分离与速度,降低了总体风险,且没有导致其他风险指标严格升高。这直观地证明了第二阶段的必要性:仅仅“可行”不够,还要“明智”。
场景:自车在红灯前排队,对向车道有自行车。突然,一辆失控车辆高速从后方冲来。
规则冲突:“不得驶入应急车道”、“与自行车保持安全距离”、“与后车保持安全距离”。硬约束同样是“保持在可行驶区域内”。
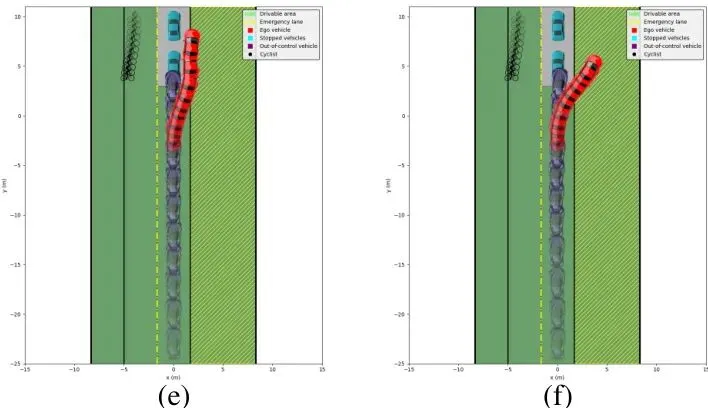
这个实验直接对比了仅第一阶段和两阶段完整框架的行为差异。
图(e) 第一阶段结果:为了最小化总的违规量,车辆只是轻微右转,刚刚蹭进应急车道一点点。这虽然支付了最小的“违规成本”,但并没有有效地快速脱离危险区域,追尾风险依然很高。
图(f) 第二阶段结果:车辆更果断地加速并驶入应急车道,以更快地离开碰撞点。它重新分配了松弛预算——在“不进入应急车道”这条规则上多违反一些,以换取在“与后车安全距离”这条规则上更好的表现,从而显著降低了追尾风险。
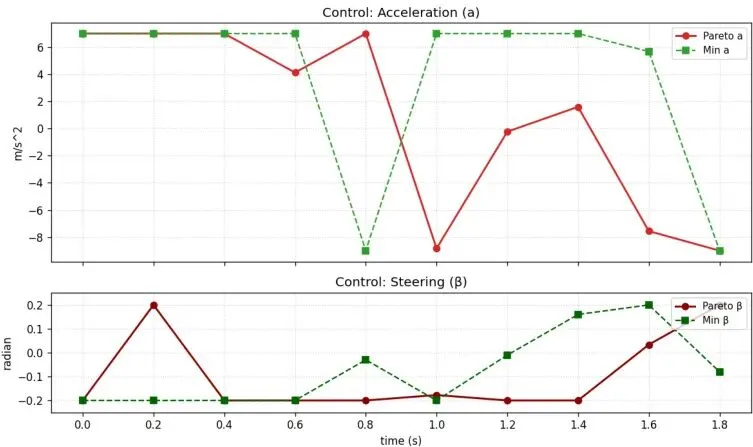
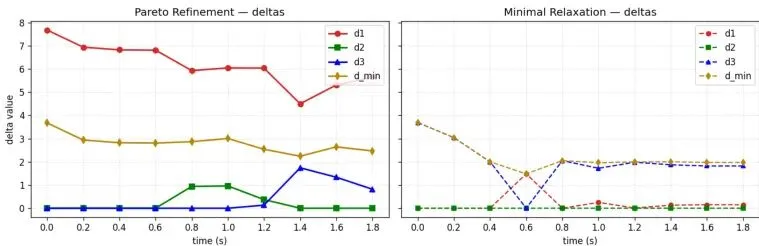
对应的控制输入(加速度和前轮转角)对比如下图所示,第二阶段方案的控制量更积极。下图则清晰展示了两个阶段在违规预算分配上的策略差异。第一阶段(左)力求各规则违规最小且均衡;第二阶段(右)则主动将更多“违规额度”分配给“不得进入应急车道”这条交通规则,从而让安全相关的规则(与自行车、后车距离)尽可能不被违反或仅轻微违反,这直接对应了风险目标的优化。未来展望:更智能的妥协艺术
这篇论文为自动驾驶乃至更广泛的机器人安全决策提供了一个极具价值的框架。它承认现实世界的不完美和冲突的必然性,并将决策从“非黑即白”推向“灰度权衡”。未来的发展方向可能包括:
1. 动态与分层的规则分类:“可谈判”与“不可谈判”的边界可能是动态的。在极端危险下,某些硬约束(如“不驶入对向车道”)也可能需要重新评估。未来的系统可能需要更灵活、分层的规则体系。
2. 交互式与学习型权衡:如何从海量人类驾驶数据或专家偏好中,学习在不同场景下“应该”如何权衡不同风险?能否通过与乘客或其他道路用户的简短交互来确定当前的价值偏好?这些都是将框架推向实用化的关键。
3. 计算效率的提升:在线求解包含STL约束和采样风险评估的优化问题,计算负担很重。如何利用深度学习进行近似、设计更高效的求解器,是实现实时应用必须跨越的障碍。
自动驾驶的终极考验,或许不是如何永远遵守规则,而是当规则与现实发生不可调和的冲突时,如何做出那个负责任、可解释且伤害最小的“次优选择”。这项研究,正是迈向这个目标坚实的一步。龙迷三问
这篇论文解决的核心问题是什么?它解决了自动驾驶(及机器人)系统中,当多条用信号时序逻辑(STL)形式化的安全规则、交通法规和任务目标在现实场景中发生冲突、无法同时满足时,控制器会因优化问题“无解”而“死机”(如急停)的问题。本文提供了一个两阶段框架,先以最小代价恢复系统可行性(能动起来),再从中寻找对各方风险综合最优的“妥协”方案。
STL和鲁棒度具体是什么意思?STL(Signal Temporal Logic,信号时序逻辑)是一种用于描述信号(如车辆轨迹)在时间上应满足何种属性的形式化语言。比如“在10秒内到达A点”或“始终与B保持5米以上距离”。鲁棒度是STL的定量语义,它给每个规则一个实数值分数:分数≥0表示满足,且越大满足得越好(余地越大);分数<0表示违反,绝对值越大违反得越严重。它就像是规则满足程度的“温度计”。
论文中提到的“帕累托最优”在自动驾驶里怎么理解?你可以把它理解为“没有更好选择”的权衡方案集合。在冲突场景下,降低对行人的风险,可能就会增加对后方车辆的风险或导致任务延误。一个方案如果是帕累托最优,就意味着:你找不到另一个方案,能在不增加其他任何一方风险(或导致其他目标变差)的前提下,进一步降低某一方的风险(或改善某个目标)。系统提供这样一组“最优权衡”方案供最终决策,而不是一个武断的单一解。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★✰
将STL控制中的可行性恢复与多目标帕累托优化相结合,思路清晰且新颖。并非开创全新领域,但在解决“规则冲突”这一具体痛点上,框架设计得非常系统和完整。实验合理度:★★★★✰
实验场景设计典型(路口冲突、后车追尾),能有效验证方法价值。对比实验(仅阶段一 vs 两阶段)设置合理,结果可视化清晰。但实验规模较小,缺乏更大规模、更多样场景的统计性验证。学术研究价值:★★★★★
价值很高。它直面了形式化方法(STL)落地到动态开放世界中的核心挑战——冲突处理,为安全关键自主系统的决策理论提供了重要思路。其“可行性恢复+价值优化”的两阶段范式,对机器人学、自动驾驶决策等领域有很强的启发和借鉴意义。稳定性:★★★✰✰
在论文设定的确定性优化和已知环境模型下,方法输出是稳定的。但实际中,风险预测依赖对周围车辆轨迹的采样和简化模型,环境感知的不确定性会直接影响风险估计和优化结果的稳定性,需要额外的鲁棒性设计。适应性以及泛化能力:★★★★✰
框架本身是通用的,可应用于任何STL规格描述的机器人任务冲突场景,不限于自动驾驶。泛化能力强弱主要取决于风险量化模型和规则库是否能准确刻画新场景。硬件需求及成本:★★✰✰✰
计算成本较高。在线求解包含STL约束(通常转化为混合整数线性规划MILP)和基于采样的风险估计的优化问题,计算开销大,对车载算力要求高,目前难以满足实时性要求高的复杂场景。复现难度:★★★✰✰
中等偏上。需要较强的优化和形式化方法背景。论文给出了详细的算法和模型,但未提及代码是否开源。复现需要自行实现STL到MILP的编码、风险采样评估以及ε-约束法求解帕累托前沿等模块。产品化成熟度:★★✰✰✰
目前主要为学术原型验证阶段。距离产品化还有相当距离,主要瓶颈在于计算实时性、对不确定环境的鲁棒性、以及如何将复杂的帕累托前沿选择权安全可靠地交付给系统或用户。可能的问题:计算复杂度是落地首要障碍;风险模型虽全面但仍属简化,未考虑更复杂的交互意图;将“规则分类”与“价值权衡”完全分离,在极端复杂场景下可能不够灵活。作为研究论文,在理论框架的完整性和启发性上表现突出,工程务实性则有待后续工作推进。
[1] Wu, T., & Lyu, Y. (2026). Feasibility Restoration under Conflicting STL Specifications with Pareto-Optimal Refinement. arXiv preprint arXiv:2603.06947.[2] 关于信号时序逻辑(STL)的基础,可参考:Maler, O., & Nickovic, D. (2004). Monitoring temporal properties of continuous signals.*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的“阅读原文”,查看更多原论文细节哦!

规则冲突,决策两难?别让算法“死机”!加入龙哥读论文自动驾驶群,和同行一起探讨如何让AI在复杂场景下做出更优、更安全的“妥协”艺术。
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 自动驾驶+北京+清华+龙哥),根据格式备注,可更快被通过且邀请进群。


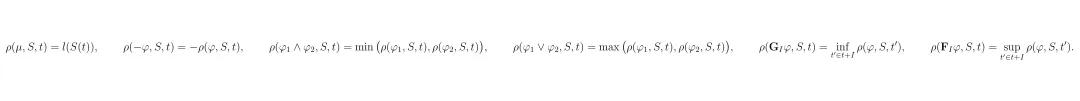


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
