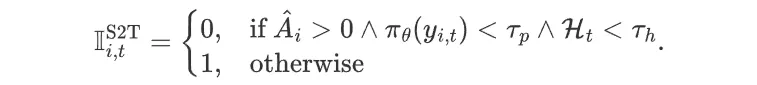近日,清华大学车辆与运载学院智能驾驶课题组(iDLab)与滴滴自动驾驶的深穹远航实验室联合提出了用于大模型微调训练的 STAPO(Spurious-Token-Aware Policy Optimization)算法,旨在解决强化学习(RL)训练过程中常见的策略熵失稳和性能震荡衰退难题。
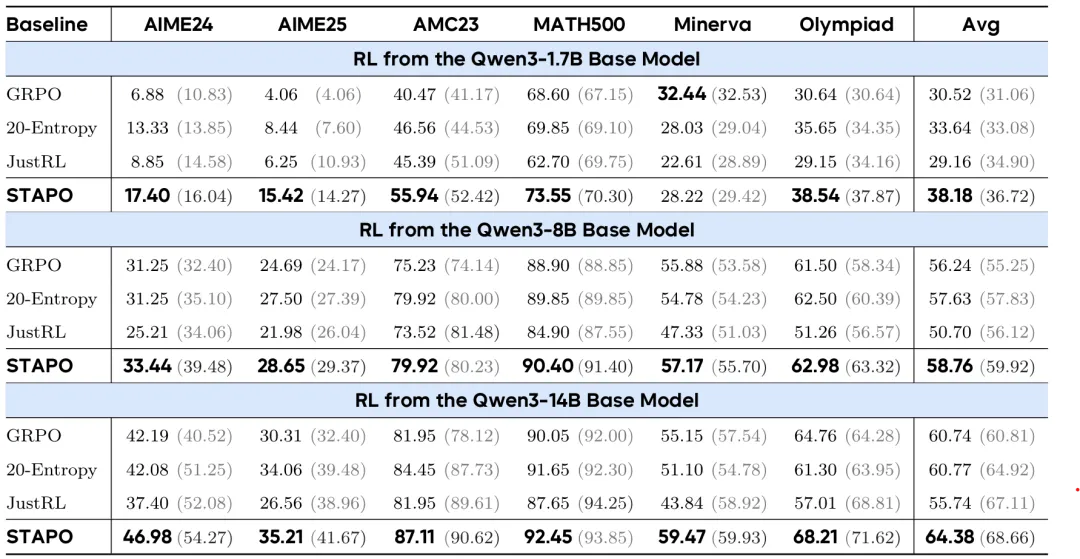
以六个基准测试(AIME24、AIME25、AMC23、MATH500、Minerva 和 OlympiadBench)和三个大模型(Qwen3 1.7B、8B 和 14B)的实验表明,STAPO 超越了GRPO、20-Entropy 和 JustRL等算法,达到基准测试任务的SOTA性能。
这为以词元(token)为基本要素的大模型训练技术提供了全新设计方案,包括自动驾驶汽车、具身智能机器人的VLM和VLA等模型。
该研究的创新在于:
通过碰撞概率与香农熵的上下界分析,从数学层面揭示了词元级策略梯度的范数不仅取决于词元生成概率,而且还和词元生成熵(token-level generation entropy)呈现负相关联系,这为大模型强化学习算法的设计提供了全新的理论支撑。
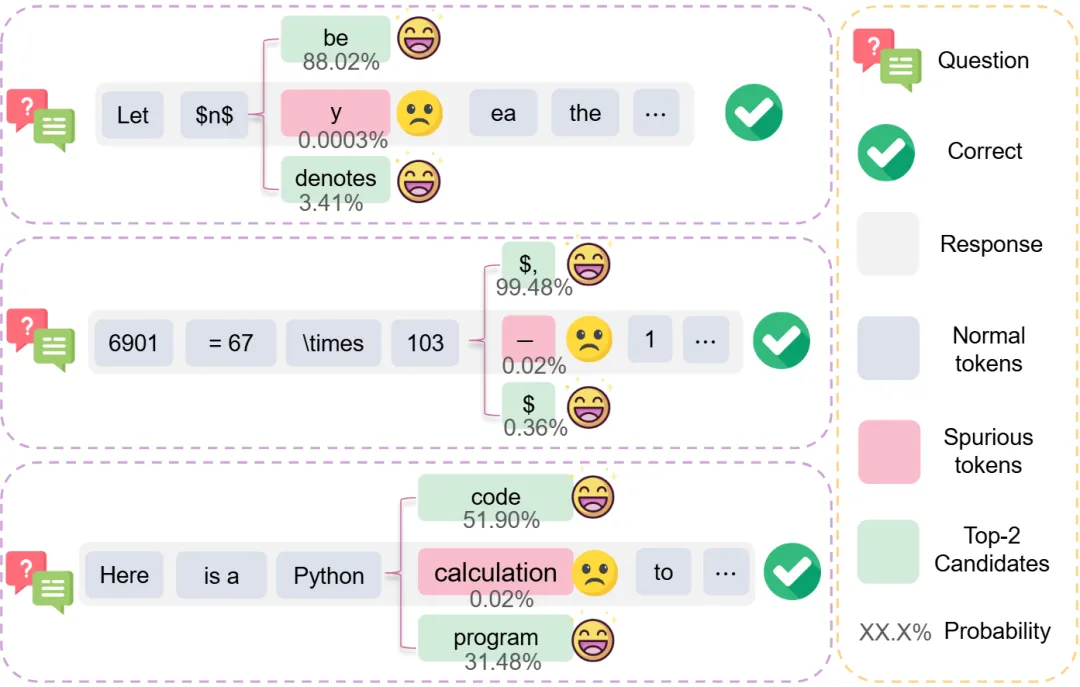
首次定义了“虚假词元 (spurious token)”的概念,即虽然出现在正确回答中,但对推理过程几乎无贡献甚至为负的词元。通过构建涵盖策略梯度范数、生成熵变化方向和学习潜力的三维度分析框架,建立了以“低”生成概率、“低”生成熵、“正”优势函数为准则的虚假词元判别条件。
为进一步提升以词元为基本要素的大模型推理性能,提出了虚假词元剔除机制(Silencing Spurious Tokens, S2T),将该机制与组优势目标函数相结合进行策略梯度计算,所衍生的STAPO算法实现了策略熵稳定性和收敛性能的综合提升,典型测试场景超越了主流的Baseline算法。
目前,强化学习正成为自动驾驶端到端模型、机器人具身智能模型、语言类多模态模型的重要训练算法,尤其是在大规模神经网络的微调(Fine-tuning)阶段,具有提升场景泛化性、对齐人机偏好度、增强逻辑推理性能的潜在价值。
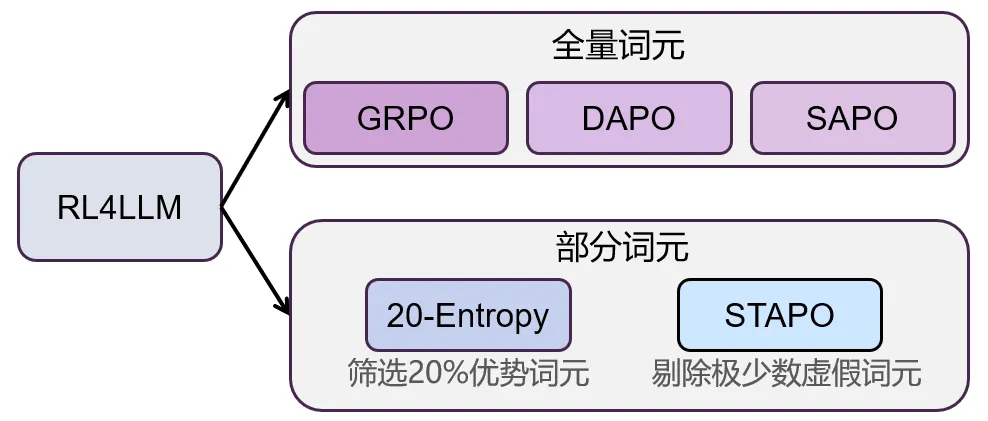
在大模型强化学习领域,学界已演化出两大算法设计范式:一是以GRPO、DAPO等为代表的全量词元范式,主张数据的全面性和多样性以提升训练效率。其中,GRPO是DeepSeek团队提出的大模型强化学习算法,已用于DeepSeek-R1等模型的训练;二是以20-Entropy和本研究提出的STAPO为代表的部分词元范式,前者筛选前20%的优势词元进行训练,而STAPO则通过剔除极少数虚假词元(仅0.01%),确保数据纯洁度和训练稳定性。这种从“全量覆盖”向“精细筛选”的范式演进,正成为提升模型训练效率与逻辑推理连贯性的关键。
STAPO算法的核心原理是降低虚假词元对优化的影响,同时尽量保留策略对真实错误的纠错能力,所采用的方案是剔除虚假词元的S2T机制。S2T机制本质是一个二值掩码函数,用于在神经网络反向传播时选择性屏蔽落入破坏性区域的词元梯度。
当某个词元同时满足优势函数为正()、生成概率较低()和生成熵较低()的条件时,将其判定为虚假词元并剔除;其余情况则保留正常梯度计算。
结合组优势目标函数,STAPO算法的总体更新目标定义为:
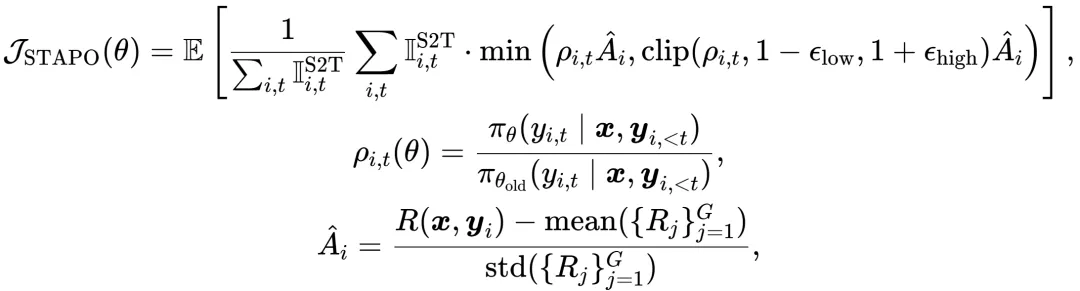
其中,为当前策略对第个词元的生成概率,为该位置的词元生成熵。
研究团队在Qwen3 1.7B、8B 和 14B Base模型上开展系统评测,并在六个数学推理基准上与GRPO、20-Entropy、JustRL等大模型强化学习算法进行对比。结果表明,STAPO在训练阶段展现出超越Baseline的策略熵稳定性,并在不同评测参数设置下均取得SOTA性能:(1) =1.0、top-p=1.0参数(黑色字体),平均提升7.13%;(2) =0.7、top-p=0.9 参数(灰色字体),平均提升3.69%。
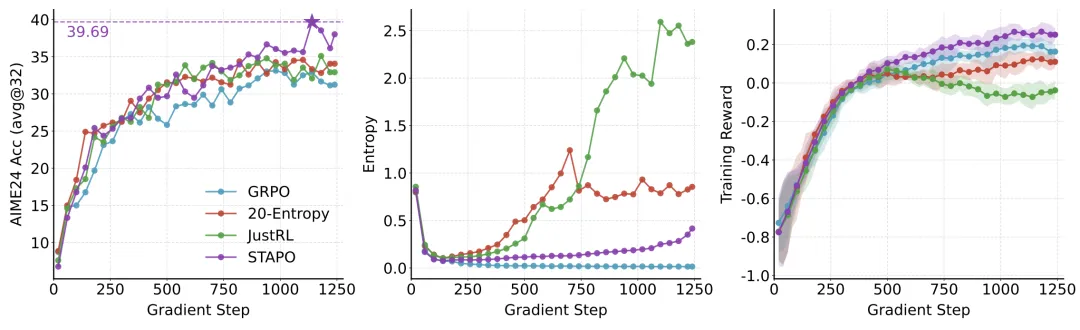
研究团队进一步对准确率(AIME24 Acc@32)、策略熵(Entropy)和训练奖励(Training Reward)等关键指标进行了可视化分析。如下图所示,相较于20-Entropy、JustRL算法,STAPO的策略熵更加平滑、波动更小,体现出更加稳定的探索能力;相较于GRPO算法,STAPO的策略熵不会退化为零,保持了良好的探索能力;与此同时,STAPO的准确率与训练奖励也获得了更加优异的表现。
这一研究还展示了训练过程出现的虚假词元案例。如下图所示,低概率的虚假词元通常表现为语义不当、计算错误、格式混乱等形式,这类词元容易被训练算法局部放大并干扰整体推理路径;相比之下,高概率的候选词元更有助于保持语义一致性与推理链条的连贯性。
下一步,研究团队将推动STAPO算法用于物理世界的具身智能大模型,聚焦于自动驾驶端到端模型的微调训练任务,以提升高级别自动驾驶系统面向未知场景的泛化能力。