26年3月来自浙大和理想汽车的论文“Unifying Language-Action Understanding and Generation for Autonomous Driving”。
视觉-语言-动作(VLA)模型正逐渐成为端到端自动驾驶领域极具前景的范式,其价值在于能够利用世界知识并推理复杂的驾驶场景。然而,现有方法存在两个关键局限性:语言指令与动作输出之间持续存在的不匹配,以及典型自回归动作生成方法固有的低效性。本文提出一种名为LinkVLA的架构,旨在直接解决这些挑战,从而提高匹配度和效率。首先,通过将语言和动作token统一到一个共享的离散码本中,并在单个多模态模型中进行处理,从而建立结构性联系。这从根本上实现跨模态的一致性。其次,为了建立深层的语义联系,引入一个辅助动作理解目标(objective),该目标训练模型从轨迹中生成描述性字幕,从而促进双向的语言-动作映射。最后,用一种由粗-到-精的两步生成方法(C2F)取代缓慢的逐步生成方法,该方法能够高效地解码动作序列,节省86%的推理时间。
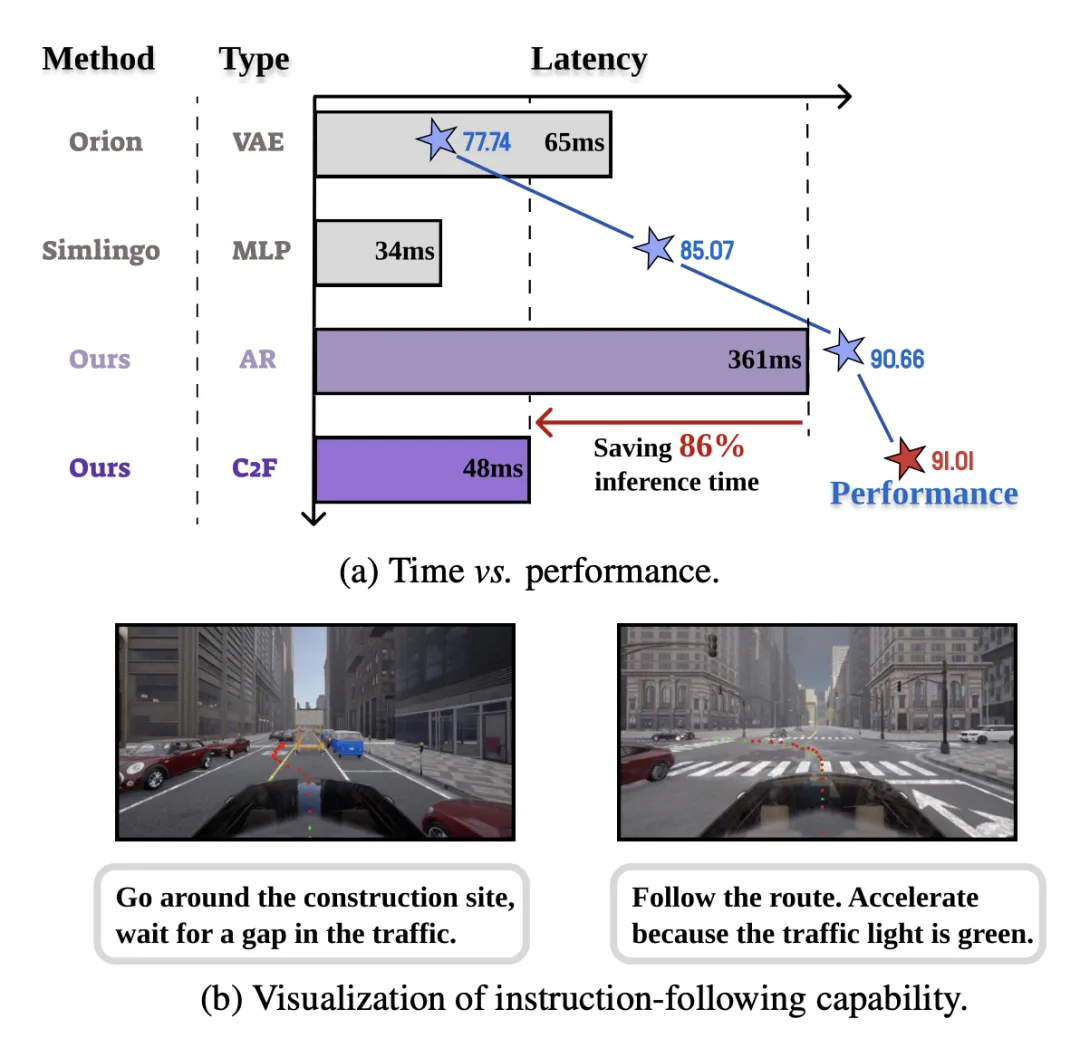
如图所示:LinkVLA 不仅大幅降低推理延迟,而且在指令跟踪准确性和驾驶性能方面也取得持续的提升。
如图所示,LinkVLA 是一种视觉-语言-动作(VLA)模型,旨在提升自动驾驶中的语言-动作一致性和推理效率。其方法引入三项创新。首先,建立一个统一的自回归框架,将语言和动作词符建模于单一离散空间中;其次,为了增强语义一致性,引入一种动作理解目标,促进语言和轨迹之间的双向映射;第三,用一种高效的由粗-到-精的生成机制取代缓慢的顺序解码,从而显著降低推理延迟。
统一token化框架
自动驾驶中的语言-动作不匹配是模态架构割裂的直接后果。为了消除这种割裂,本方法基于统一原则:在单一的统一框架内对整个过程(从理解指令到生成轨迹)进行建模。该方法将语言指令 L 和动作轨迹 T 映射到一个统一的离散token序列,然后由 VLM 主干网络进行处理。对于语言,利用 VLM 现有的token化器。对于本质上连续的动作,设计一种空间-觉察的动作token化方案。模型不是回归连续值,而是根据token化后的码本预测一系列动作token。
统一token空间。该方法基于一个统一的语言和动作token空间。首先对连续轨迹进行量化来实现这一点:局部鸟瞰图(BEV)空间被划分成一个由 K_action 单元格组成的网格,每个单元格定义一个唯一的动作token。轨迹 T = {w_1,...,w_T} 通过将每个路径点映射到其对应的单元格,转换为动作token序列 A = {a_1,...,a_T}。然后,将此动作码本(C_action)与模型的文本词汇表(大小为 K_text)合并,形成一个大小为 K = K_text + K_action 的统一码本 C。动作token嵌入以端到端的方式学习,迫使模型将语言和空间概念映射到共享表示中,从而使单个 VLM 模型能够同时处理两者。在推理过程中,每个预测的动作token只需解码回其对应网格单元格的中心即可。
动作token化。朴素的token化方法使用one-hot编码将航点token化到均匀的BEV网格上,存在两个关键问题。首先,均匀网格均匀分配分辨率,无法提供近场控制所需的精细精度。其次,硬性分配one-hot编码标签会忽略网格固有的空间拓扑结构,使空间先验的学习变得复杂。为了缓解这些问题,引入两项改进:对数坐标变换和空间软标注。
1)对数坐标变换。设计一种非均匀量化方案,优先考虑自车附近的精度。这是通过首先对航点坐标 (x, y) 沿每个轴独立地应用非线性变换来实现的。具体来说,每个坐标 z ∈ {x, y} 使用带符号的对数函数进行变换:
z′ = sign(z) · log(1 + k · |z|)
这里,k 是一个正缩放因子,用于控制原点周围线性区域的大小。由此得到的变换空间 (x′, y′) 随后被均匀量化,以生成动作tokens。
2) 空间软标注。为了将关于动作空间连续性的物理先验信息嵌入到学习目标中,采用一种空间软标注策略。标准的one-hot编码目标提供一个离散的监督信号,但并没有显式地考虑动作网格的空间拓扑结构。本方法通过定义一个平滑的目标分布来改进这一点,该分布考虑空间邻接性。
具体来说,对于一个真实token a_gt,构建所有动作token a ∈ C_action 的目标分布 q(a),该分布是一个以 a_gt 的坐标为中心、半径为 R 的归一化二维高斯分布q(a) 。对于动作生成,模型预测的分布 p(a) 会使用交叉熵损失 L_generation 进行优化,以匹配该软目标。
该目标鼓励模型不仅为正确的token分配概率质量,还根据高斯形状为其空间邻域分配概率质量。这有利于形成局部平滑的动作流形,使模型对细微的真实值误差更加鲁棒。当引入思维链时,会在该目标中添加一个用于语言生成的标准交叉熵损失。
最终的训练目标是这两个损失的加权和:L_total = L_generation + λL_understanding,其中 λ 是一个平衡超参。通过强制模型解决这个逆问题,确保共享嵌入空间内的双向一致性。这一过程丰富动作token的语义基础,确保它们与描述性语言概念内在关联,从而提升指令执行能力。实际上,这两个任务由同一个解码器处理,只需简单地交换文本指令 L 和动作token A 作为预测目标的角色即可。
由粗-到-精的动作生成
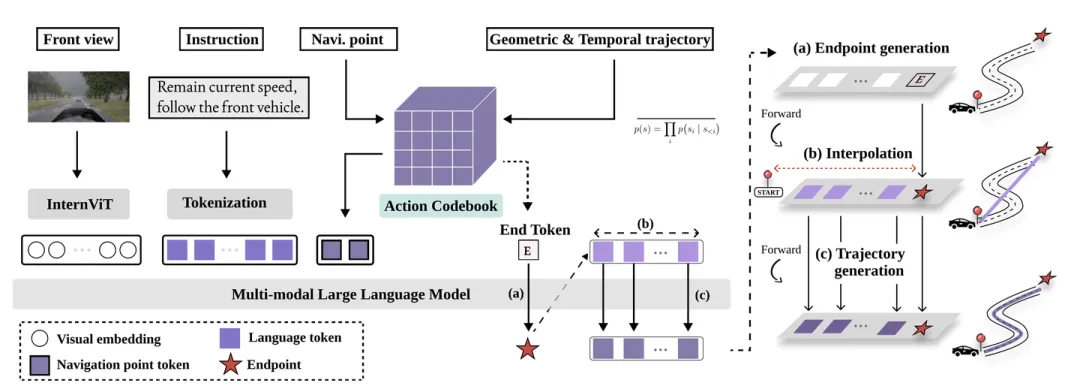
自回归生成包含 T 个路径点的长轨迹需要 T 次连续的前向传播,这计算成本高昂,并且会引入显著的推理延迟。为了解决这个问题,将 T 步序列依赖关系简化为一个两阶段过程:(1)终点预测和粗略轨迹初始化,以及(2)并行轨迹细化。参考 [37],动作输出包括时间速度路径点和几何路径点。由于两者都被视为点序列并在框架中对称处理,为了清晰起见,将它们统称为轨迹,将其组成部分称为路径点。
用粗略轨迹先验进行训练。通过精心设计的训练目标来实现由粗-到-精的推理。为了直接预测终点,在解码器输入序列的开头放置特殊tokens。在训练过程中,真实目标序列被重新排序为 {w_T, w_1, w_2, ..., w_T−1},从而教会模型将特殊tokens与终点预测关联起来。在细化阶段,用真实终点通过线性插值模拟粗略轨迹,将其量化为粗略路径点tokens作为模型输入,并训练模型将这些粗略tokens映射到相应的细粒度轨迹。
粗略轨迹初始化。在推理过程中,首先为轨迹建立一个强结构先验,用于指导后续的生成步骤。利用改进的训练序列,模型执行一次前向传播以精确预测最终路径点 wˆ_T。虽然这一初始步骤的灵感来源于目标点预测方法 [55],但该方法本质上是不同的,因为其将终点预测和轨迹细化集成在一个统一的 Transformer 架构中。
给定起点 w_0(自车原点位于 (0, 0))和预测的终点 w_T,通过线性插值构建粗略轨迹 W_coarse。然后,这些路径点被token化为轨迹tokens,作为后续细化阶段的初始框架。
并行轨迹细化。第二个推理步骤将粗略的直线路径细化为动态可行的轨迹。将其表述为结构保持细化,其中每个粗略路径点 w^coarse^_i 都被映射到其对应的细化路径点 w^fine^_i。给定token化的粗略路径点作为初始输入,LinkVLA 并行预测 T 个细化点。在视觉语言上下文(通过交叉注意机制)的约束下,细化路径能够遵守车道边界、避开障碍物并遵循语言指令。
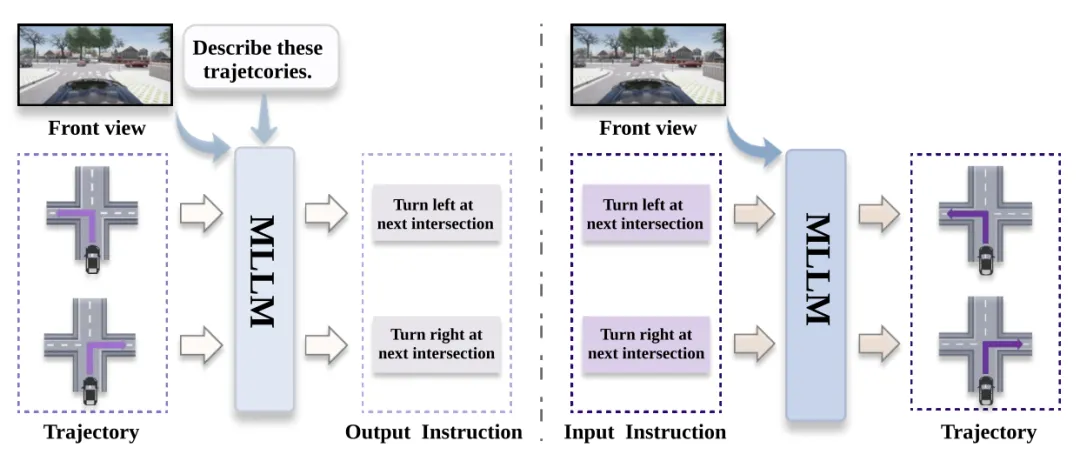
动作生产和理解如图所示:左图理解,右图生成。
设置
Bench2Drive。用 Bench2Drive 基准测试 [19] 对 LinkVLA 进行训练和评估。该基准测试在广泛使用的 CARLA 模拟器 [7] 中提供一系列交互式场景。遵循 SimLingo [37] 的方法,并使用开源专家级 PDM-lite [41] 在 CARLA 模拟器中收集驾驶数据集。评估遵循 CARLA v2 端到端自动驾驶闭环协议,包含 44 个交互式场景,每个场景 5 条路线,总共 220 条官方路线,涵盖各种天气条件。用基准测试的官方指标来报告性能:驾驶评分 (DS)、成功率 (SR)、效率、舒适性和多用途能力。
指令跟随评估。用来自 SimLingo [37] 的 Action Dreaming 数据集来评估模型的指令跟随能力。该数据集旨在评估模型不仅能够理解语言中特定场景的知识,还能将这种理解转化为相应的动作空间。
给定一条自然语言指令,模型需要生成与该指令对应的一系列动作。评估在 CARLA Town 13 dreamer 数据集上进行验证。指令分为六类:减速、加速、达到目标速度、变道、以物体为中心。性能指标为成功率。
DriveLM-hard(VQA)和评论。在 DriveLM-hard 基准测试集 [37] 上评估 VQA 和评论生成能力。这个具有挑战性的验证集源自 DriveLM [41],并专注于 CARLA Town 13 环境。为了确保测试的平衡性,包含罕见情况,基准测试集采用均匀抽样的方式构建,每种答案类型抽取 10 个样本,而不是简单的随机抽样。最终数据集包含 330 种 VQA 答案类型和 190 种评论类型。用 SPICE、BLEU 和 ROUGE-L 指标报告评分。
实现细节
动作token化。该框架在一个鸟瞰图(BEV)空间中运行,坐标范围为 x ∈ [0, 50]m 和 y ∈ [−30, 30]m。为了创建离散的动作空间,首先使用第 3.1 节中详述的对数函数(超参数 k = 5)对这些坐标进行变换,然后将其离散化为步长为 0.1 的均匀网格。此过程生成一个 56 × 101 的网格,构成一个包含 K_action = 5,656 个离散动作tokens的词汇表。对于空间软标注过程,采用邻域加权半径 R = 10 个单元格和高斯标准差 σ = 1.2。此外,为了实现由粗到精(C2F)框架的分层动作生成,引入了两个特殊tokens:路径目标token和航点目标 token。
训练细节。用 Mini-InternVL 系列 [9] 中的 InternVL2-1B 作为主要架构。InternVL2-1B [9] 模型由视觉编码器 InternViT-300M-448px (ViT) [4] 和语言模型 (LLM) Qwen2-0.5B-Instruct [43] 组成。用 AdamW 优化器 [26] 和余弦学习率调度来训练模型。超参数设置如下:基础学习率为 1e-4,权重衰减为 0.1,β1 = 0.9,β2 = 0.999,dropout 率为 0.1。该模型在 32 个 H2O GPU 上训练 30 个 epoch,批大小为 48。模型自适应方面,参考 SimLingo [37] 的方法,应用 LoRA [12],秩为 32,α = 64。
推理过程中,采用思维链 (CoT) 方法。首先,模型生成动作的文本解释。基于此解释,模型预测最终的动作序列。该输出包含每帧 20 个几何路径tokens和 10 个时间路径点tokens。
统一理解与生成。将 (V, L, A) 元组随机连接成:1) [V, A, L],并监督 L 以理解动作;或 2) [V, L, A],并监督 A 以生成动作。两者均与 L_total 一起训练。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
