论文信息
题目:VLMPlanner: Integrating Visual Language Models with Motion Planning
视觉语言模型与运动规划的集成:VLMPlanner
作者:Zhipeng Tang、Sha Zhang、Jiajun Deng、Chenjie Wang、Guoliang You、Yuting Huang、Xinrui Lin、Yanyong Zhang
一、痛点直击:现有规划方法的两大核心问题
此前基于大语言模型(LLMs)的规划方法,要么将驾驶场景转换为结构化自然语言或鸟瞰图输入模型,受标记限制丢失细粒度视觉特征;要么仅将感知输出馈入LLM/VLM,压缩的信息无法捕捉道路水坑、非机动车转向信号等关键细节,导致规划决策缺乏安全性和鲁棒性。
即便部分方法尝试将LLM集成到实时规划器中,也未能充分利用原始图像的丰富信息,难以应对复杂的长尾驾驶场景。如何兼顾细粒度场景理解、精准轨迹规划与计算效率,成为自动驾驶运动规划的关键瓶颈。
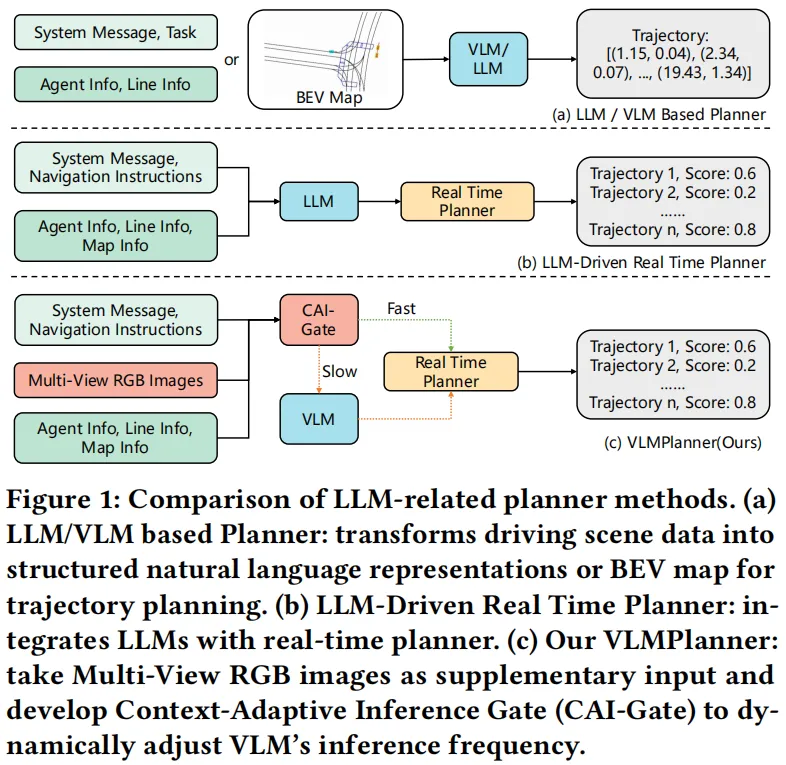 图1:(a)传统LLM规划方法依赖结构化表示,(b)部分集成方法仍受限感知输入,(c)VLMPlanner利用多视图图像捕捉细粒度细节
图1:(a)传统LLM规划方法依赖结构化表示,(b)部分集成方法仍受限感知输入,(c)VLMPlanner利用多视图图像捕捉细粒度细节
二、VLMPlanner:四大创新点破解行业难题
创新点1:多视图图像驱动的VLM-规划器混合框架
VLMPlanner最核心的突破,是放弃了“用LLM直接生成轨迹”的思路,转而将基于学习的实时规划器与能处理原始图像的VLM深度融合。VLM接收多视图图像作为核心输入之一,捕捉道路标线、行人动作、突发障碍物等细粒度视觉信息,再通过常识推理能力引导实时规划器生成安全轨迹,大幅提升了复杂场景下的决策鲁棒性。
创新点2:上下文自适应推理门(CAI-Gate)
为解决VLM推理耗时、难以适配实时规划的问题,研究团队设计了CAI-Gate机制。该模块以多视图图像和地图信息为输入,通过基于学习(EfficientNet-B0+序数回归模型)和基于规则(车辆/行人数量、车道数、车速等维度)两种方式评估场景复杂度,动态调整VLM的推理频率——简单场景降低推理频次节省算力,复杂场景提高频次保证性能,完美模仿人类“按需分配注意力”的驾驶行为。
创新点3:专属自动驾驶的VQA数据集
现有VLM缺乏自动驾驶场景的针对性训练数据,研究团队基于nuPlan数据集构建了两大专属数据集:
- DriveVQA(49673个样本):聚焦自动驾驶指令、轨迹、控制信号理解,通过算法生成图像-文本问答对,强化VLM对驾驶操作的认知;
- ReasoningVQA(1099个样本):结合手动规则与GPT-4生成,让VLM学习基于交通规则和场景信息的规划推理逻辑,提升场景理解与决策能力。
创新点4:两阶段训练范式
为最大化模型效果,团队采用“预训练+微调”两阶段训练:
- 预训练阶段:先用DriveVQA增强VLM对驾驶指令/轨迹的理解,再用ReasoningVQA+少量DriveVQA提升推理能力,全程采用LoRA轻量化训练;
- 微调阶段:基于nuPlan的10000个采样实例,将VLM增强的特征注入实时规划器,结合规划损失与速度预测、交通灯识别等辅助任务损失,优化最终轨迹生成效果。
三、核心架构:VLMPlanner的整体设计
VLMPlanner的总体框架清晰易懂,核心是“实时规划器+VLM模块+CAI-Gate”的三位一体结构:
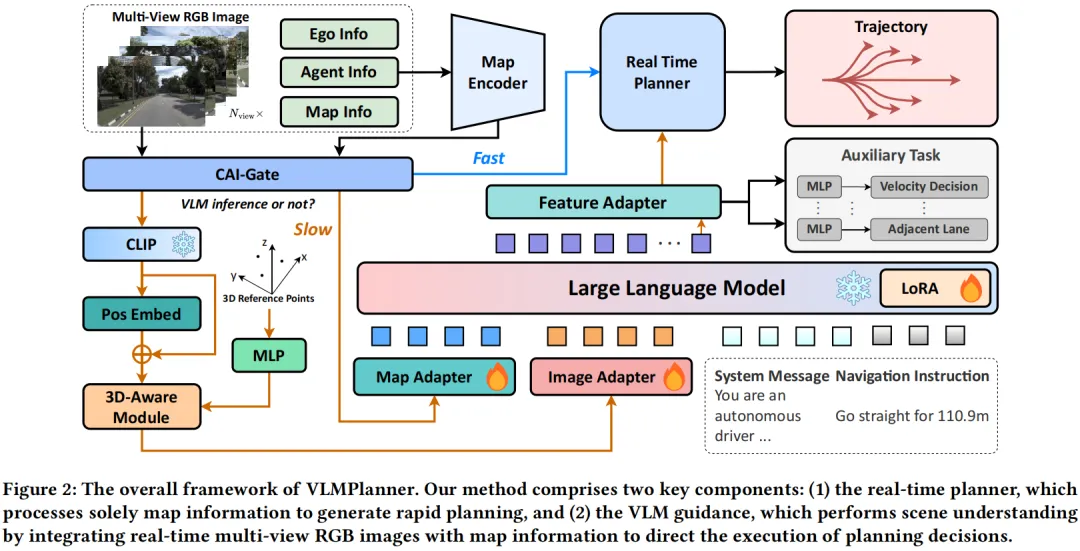 图2:VLMPlanner总体架构图
图2:VLMPlanner总体架构图
多模态输入处理
- 地图信息:提取自车/邻车历史状态、车道/人行横道特征,经MapEncoder编码+MLPAdapter维度匹配后,生成地图特征标记;
- 多视图图像:先通过CLIP编码视觉特征,再经3D感知模块(引入3D位置编码、可学习参考点)将2D图像特征投影到3D空间,既减少标记数量,又增强空间理解,最后通过ImgAdapter对齐VLM维度;
- 系统消息+导航指令:系统消息定义VLM的“自动驾驶角色”,导航指令由真实轨迹/地图信息生成,引导模型聚焦规划任务。
VLM引导的实时规划
将地图、图像、语言特征输入VLM得到隐藏层特征,通过自适应注入块将VLM的场景理解结果融入实时规划器的解码层,既保留规划器的数值计算优势,又赋予其VLM的场景推理能力,最终生成精准、安全的轨迹。
四、实验验证:性能与效率双优
研究团队基于nuPlan基准构建了Open-Hard20(开环)、Close-Hard20(闭环)两大长尾场景测试集,对比PDM、GameFormer、PlanTF、AsyncDriver等主流方法,VLMPlanner展现出显著优势:
定量结果
- 开环测试:两个版本的VLMPlanner均超越基线规划器,性能优于SOTA方法PlanTF;
- 闭环测试:非反应式设置下比DTPP提升1.68%,反应式设置下比GameFormer提升3.33%,核心指标“碰撞概率”大幅降低,安全性显著提升。
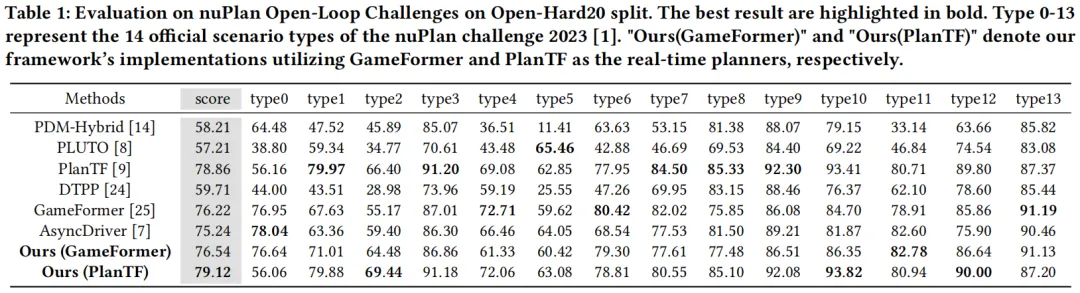 表1:Close-Hard20非反应式配置下各方法性能对比
表1:Close-Hard20非反应式配置下各方法性能对比
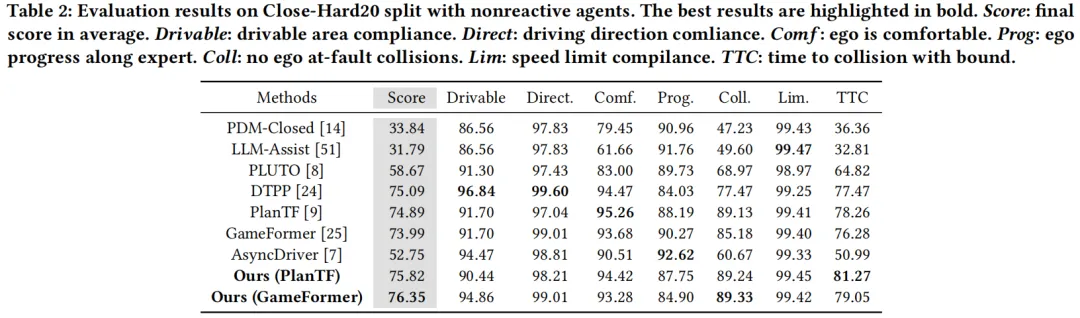 表2:Close-Hard20反应式配置下各方法性能对比
表2:Close-Hard20反应式配置下各方法性能对比
消融实验
- CAI-Gate有效性:即使VLM平均推理间隔提升至91,模型仍保持优异性能,远超固定间隔推理的AsyncDriver;
- 预训练价值:经DriveVQA+ReasoningVQA预训练后,闭环测试性能显著提升,验证了专属数据集的必要性。
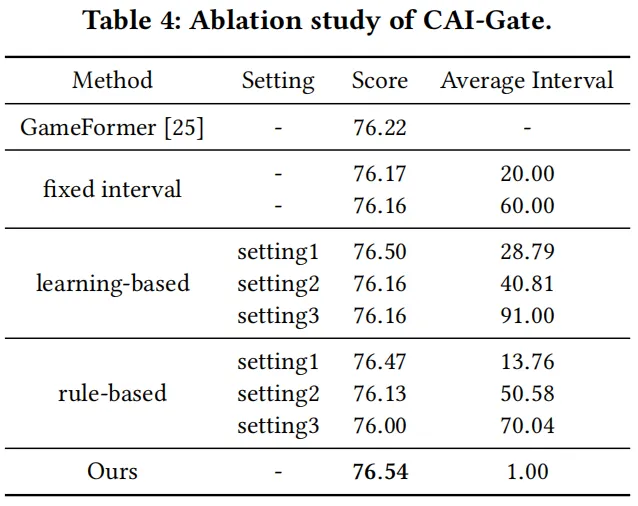 表3:不同CAI-Gate配置下的性能对比
表3:不同CAI-Gate配置下的性能对比
定性案例
视觉对比实验更直观展现VLMPlanner的优势: 图3:VLMPlanner与AsyncDriver的场景应对对比
图3:VLMPlanner与AsyncDriver的场景应对对比
- “行人过马路”场景:AsyncDriver未识别行人导致碰撞,VLMPlanner通过多视图图像捕捉行人动作,停车等待直至行人通过;
- “红灯静止”场景:AsyncDriver误判交通灯继续行驶,VLMPlanner精准识别红灯信号,等待放行后再通行。
五、总结与展望
VLMPlanner的核心价值,在于打通了“原始视觉信息-语言推理-实时规划”的链路:通过多视图图像充分利用细粒度场景信息,通过CAI-Gate平衡性能与效率,通过专属数据集和两阶段训练让VLM真正适配自动驾驶场景。这一框架不仅在nuPlan基准上取得了SOTA性能,更为解决自动驾驶长尾场景难题提供了可落地的新思路。
未来,随着多模态大模型的持续演进,结合更高清的多视图感知、更精细的场景复杂度评估、更丰富的自动驾驶语料,VLM与运动规划的融合有望实现更安全、更高效的自动驾驶决策,推动行业向L4级完全自动驾驶更进一步。
如果大家有要宣传的工作(paper、项目、rp、招聘等),欢迎后台留言
关注+星标不迷路~
CCF/SCI/SSCI论文辅导