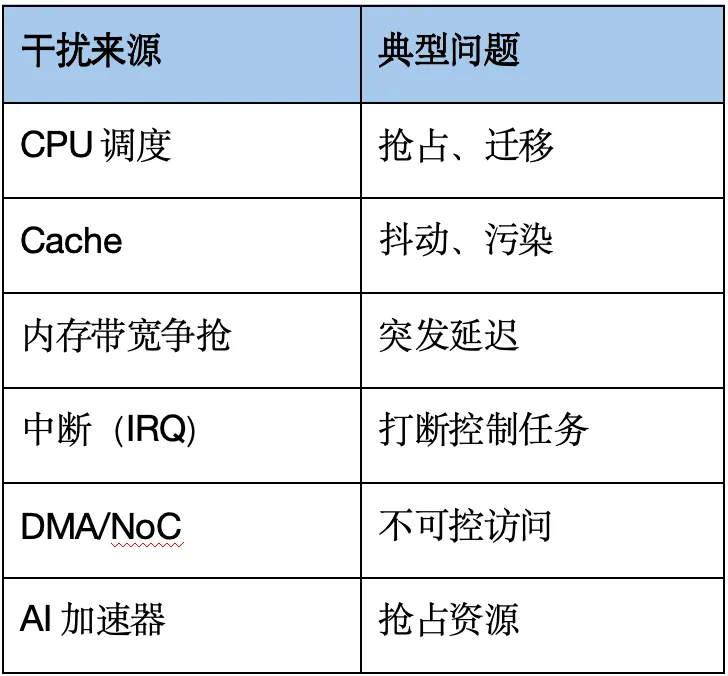
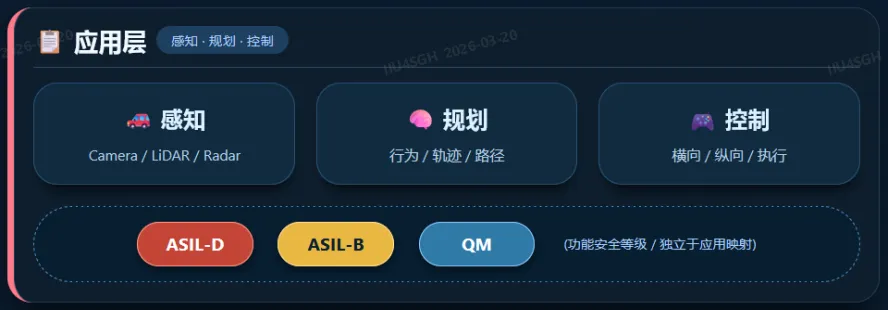
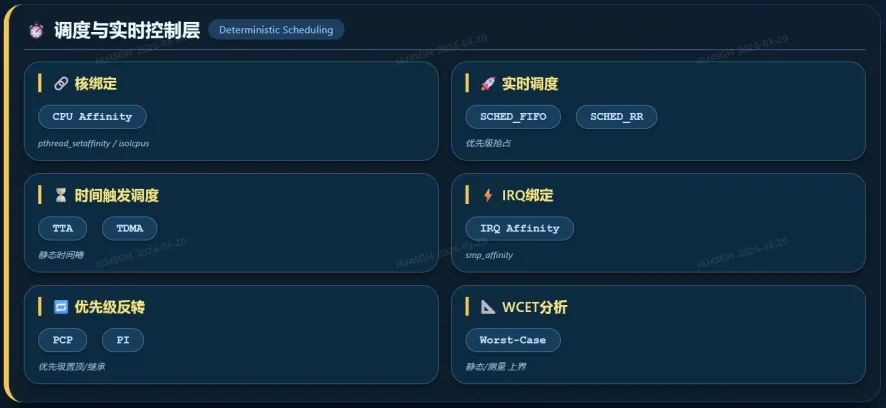
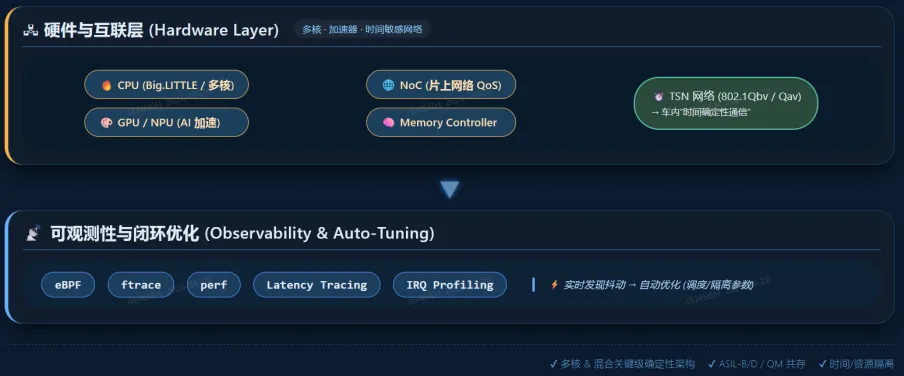
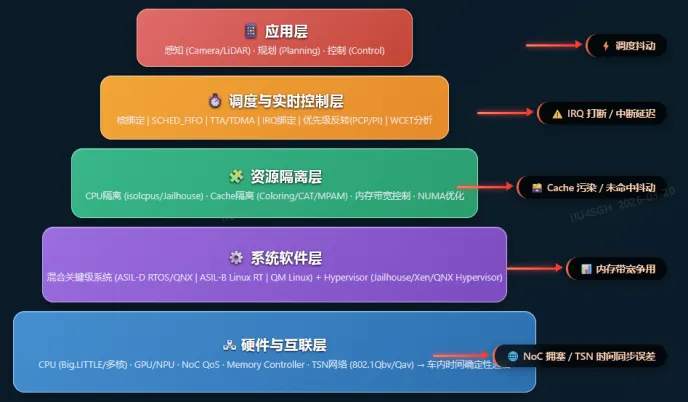
我们将调度问题上升为一个完整的系统模型:
注意:本文前面从“问题来源”角度(CPU → Cache → Memory → IRQ → System)展开,
而上图从“系统架构分层”角度进行抽象,两者是同一体系的不同视角。
2.1 CPU层:核绑定与实时调度(基础但不充分)
这确实是基础。目标:避免任务被抢占或迁移,我们通过 sched_setaffinity 把任务钉死在核心上,用 SCHED_FIFO 赋予它实时优先级,甚至用内核启动参数 isolcpus 把某些核心完全隔离出来,只运行指定任务。
为避免优先级反转问题,需要引入 PCP(优先级天花板协议)或 PI(优先级继承机制),确保高优先级任务不会被低优先级任务间接阻塞。
核心技术:
sched_setaffinity
SCHED_FIFO / SCHED_RR
isolcpus / cpuset
作用:
降低上下文切换
提升响应优先级
固定执行位置,防止缓存失效
局限性:即使绑核,系统仍然可能抖动(原因在下面几层),因为它控制不了共享资源。
2.2 Cache层:缓存隔离(决定实时性的关键因素)
这是很多工程师容易忽略的“性能黑洞”。
问题核心:现代多核SoC的最后一级缓存(LLC)通常是共享的。一个核心上的任务,会悄无声息地把另一个核心上关键任务的缓存数据“挤出去”。这导致关键任务每次运行时,都面临“缓存冷启动”,延迟剧烈抖动。
CPU 多级缓存基础知识补充
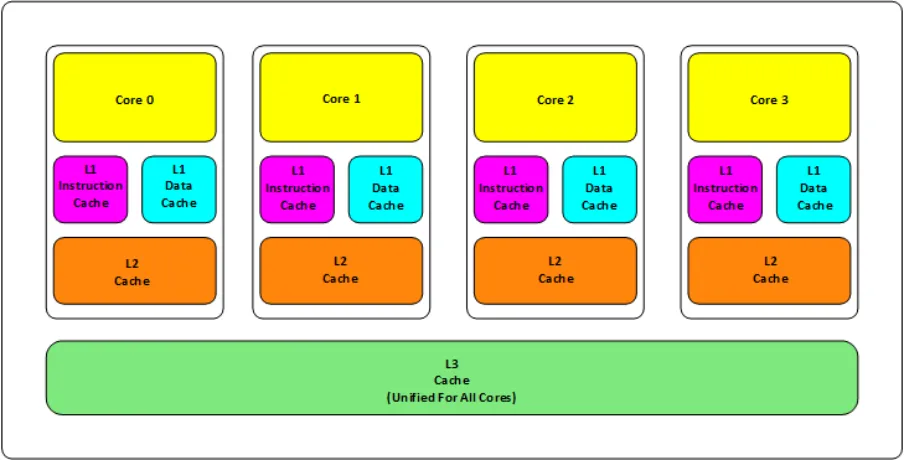
现代 CPU 普遍采用多核架构与多级缓存设计,早期处理器多为两级缓存(L1、L2),新款处理器则普遍升级为三级缓存(L1、L2、L3),整体存储体系遵循离核心越近、速度越快、容量越小的设计原则。如下图所示:
缓存结构与分工
L1 缓存:分为指令缓存与数据缓存,是最靠近运算核心的高速缓存,每个 CPU 核心独立拥有。
L2 缓存:不区分指令与数据,同样为每个核心独占,容量与速度介于 L1 和 L3 之间。
L3 缓存:不区分指令与数据,由所有 CPU 核心共享,容量最大、速度相对最慢。
访问速度对比(以 CPU 时钟周期为单位)
L1 缓存:约 4 个时钟周期
L2 缓存:约 11 个时钟周期
L3 缓存:约 39 个时钟周期
内存(RAM):约 107 个时钟周期
可见 L1 缓存的访问速度约是内存的 27 倍,但容量差异悬殊:L1、L2 多为KB 级,L3 则达到MB 级。缓存之后依次为系统内存、硬盘等存储设备,速度逐级下降、容量逐级增大。
为什么要设计三级缓存?以及由此带来的核心问题
CPU 采用三级缓存架构,本质是在速度、容量、物理实现、多核协同之间做综合权衡,并非单纯追求更快或更大。
一、为什么要分成 L1 / L2 / L3 三层?
1. 物理限制:速度与容量天生矛盾
想要更大容量,就需要更多晶体管,不仅会增大芯片面积,更关键的是信号传输路径变长、延迟上升。访问速度和电路距离强相关,离计算核心越远,速度越慢。大容量高速缓存从物理上就无法实现。
2. 多核场景下的协同与同步成本
多核架构中,多个核心会同时访问、修改数据,缓存越大、共享越复杂,数据同步开销就越高。
同时,缓存与内存速度差距极大,如果只用一级缓存,要么容量太小频繁失效,要么太大速度跟不上。多级缓存可以用小容量极速缓存 + 中容量高速缓存 + 大容量共享缓存的组合,最大化整体吞吐。
这个世界永远是平衡的,一面变得有多光鲜,另一面也会变得有多黑暗。
3. 工程上的折中艺术
技术世界永远是权衡:速度上去了,容量就要妥协;容量做大了,速度必然下降。多级缓存就是在这对矛盾里找到最优平衡点。
二、多级缓存带来的两大关键问题
更多层级、更多副本,必然引入新的复杂度,最核心的是两个问题:
1. 缓存命中率
数据是否刚好在缓存里,直接决定访问速度。命中率越低,CPU 越要去慢速内存取数,性能急剧下降。
2. 缓存一致性(多核下尤为复杂)
多个核心各自有独立 L1/L2,同一份数据可能在多处缓存中存在副本。一旦某个核心修改数据,其他副本必须同步更新或失效,否则会出现数据不一致。
多核缓存一致性,本质和分布式系统多节点数据同步非常相似。
三、先理解一个基础概念:Cache Line
CPU 不会以单个字节为单位从内存加载数据,效率太低。它会整块批量读取,这个最小读取单位就叫 Cache Line。
主流 CPU 通常为 64 字节
部分架构使用 32 字节或 128 字节
64 字节相当于 16 个 32 位整数
举例:如果 L1 缓存大小为 32KB:32KB = 32768 字节
32768 / 64 = 512 个 Cache Line
也就是说,这片 L1 缓存被划分为 512 个槽位,数据只能以整行的形式载入。
四、内存地址与缓存的映射策略(CPU Associativity)
缓存远小于内存,同一块内存数据不可能同时存在所有位置,因此需要一套映射规则,决定内存数据应该放到缓存的哪个位置。
1. 全相联映射(Full Associativity)
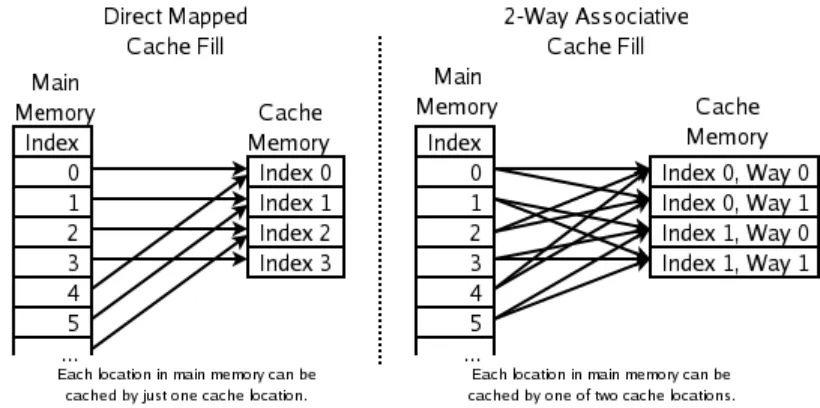
2. 直接映射(Direct Mapped)
类似最简单的哈希表,用取模方式定位:
缓存索引 = 内存地址 mod 缓存行数
举例:L1 有 512 个 Cache Line,则
地址 mod 512 就能直接算出对应 Cache Line 位置。
3. N 路组相联映射(N-Way Set Associativity)
为兼顾前两种方案的优缺点,现代 CPU 普遍采用此方案:
(1) 先把缓存分成若干组(Set),每组包含 N 个 Cache Line,称为 “N 路”。
(2) 通过地址哈希先定位到对应的组。
(3) 再在这一组内的 N 个 Cache Line 中查找。
这样既降低了搜索开销,又大幅减少冲突,是速度、成本、命中率之间最成熟的折中方案。
扯远了,咱们把话题再拉回来。
核心问题:多核系统中,Cache是共享的, 干扰不可避免。
即使任务固定在核心上,其他核心仍然可能污染LLC,cache miss导致延迟不可预测
工程常见解法:缓存着色(Cache Coloring)与硬件分区想象一下,如果把Cache比作一个有很多行(Set)的书架。默认情况下,所有程序的书都可以随意放在任何一行。缓存着色技术,就是通过软件手段,控制物理内存页映射到Cache的哪一行。这样,我们可以把关键任务的书,只放在书架的前几行,而其他任务的书只能放在后几行,物理上隔离。
一段对话:
A: “这听起来很底层,实现起来难吗?”
B: “确实需要内核或BSP(板级支持包)层面的支持。但带来的收益是巨大的——关键任务的延迟抖动可以减少30%到70%。像一些高性能实时系统,已经在用类似技术。新一代ARM芯片的MPAM(内存系统资源分区与监控)功能,更是直接在硬件层面支持这种分区,让隔离更干净、配置更简单。”
2.3 内存与NoC层:带宽与访问控制(隐形瓶颈)
典型场景:你监控到CPU负载很低,但控制任务就是偶尔“卡顿”。查了半天,发现是AI加速器正在通过DMA(直接内存访问)大量搬运数据,把内存带宽吃满了。你的控制任务虽然CPU有空,但等不到内存数据,只能干等。
这就是内存带宽和片内网络(NoC,Network-on-Chip)争用带来的问题。
工程解法:带宽控制与QoS
我们需要给关键任务开辟一条“高速公路专用道”。
1) 内存带宽控制:利用 resctrl(Linux内核的资源控制接口)、cgroup 等机制,限制非关键任务(如AI推理、日志记录)可以使用的最大内存带宽。
2) QoS机制:现代SoC(如ARM系列)内部有总线仲裁器。通过配置ARM QoS扩展,我们可以给关键事务(如控制CPU的访存请求)更高的优先级,确保它永远能插队先行。
关键价值
2.4 中断层:IRQ调度(最容易翻车的点)
IRQ 的全称是 Interrupt Request,即中断请求。
在自动驾驶 ECU 的确定性调度体系中,中断层是造成系统抖动的关键来源之一。IRQ 是硬件向 CPU 发出的信号,用于通知某个事件(如传感器数据到达、定时器超时)需要立即处理。如果不加控制,频繁或高优先级的中断会随时打断关键实时任务的执行,导致延迟不可预测。
你是否遇到过:CAN总线突然涌入大量报文,触发的中断直接把正在执行的控制任务给打断了?如:摄像头中断打断控制任务,CAN中断导致刹车延迟。这就是中断带来的不确定性。
工程解法:中断隔离与线程化
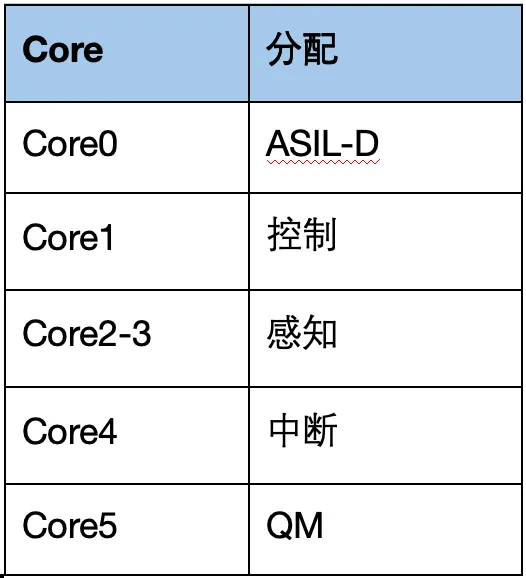
一个典型的分区策略:
按核心功能分区 + 中断集中管理的思路,把不同任务和中断精准分配到不同 CPU 核心,互不干扰:
1) Core 0-1 作为安全岛
只负责最高安全等级的制动、转向等 ASIL-D 控制任务,关闭一切非必要中断,保证安全功能绝对稳定可靠。
2) Core 2-3 负责感知计算
专门处理摄像头、激光雷达数据和 AI 推理,同时承接这些传感器相关的中断,让感知和计算在同一组核心内闭环运行。
3) Core 4 作为专职管家
统一接管 CAN、以太网等所有外设中断,避免各类外设中断去打扰安全核心和感知核心,保证关键业务不被频繁打断。
4) Core 5...及以后核心负责娱乐系统
运行类 Linux等非实时系统,处理车机、人机交互等对实时性要求不高的应用。
2.5 系统层:混合关键级 + 虚拟化隔离(决定上限)
这是从“调度优化”到“系统架构”的跃迁。
当我们把CPU、Cache、内存、中断都做到极致后,如果还想更进一步,或者要满足严格的功能安全要求(如ISO 26262的免于干扰,FFI,Freedom From Interference),就需要从“逻辑隔离”走向“物理隔离”。
为什么需要?
因为:Linux本质上不是确定性系统
工程解法:混合关键级系统 + 虚拟化
这是从“优化”到“架构”的质变。
这样,不同安全等级的任务,从一开始就生活在不同的“物理世界”里,从根本上消除了干扰的可能。
本质提升
从“尽量不干扰” → “物理隔离”
满足ISO 26262 FFI要求




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
