开头先说个事儿。
去年你让ChatGPT帮你写个年终总结,惊掉了下巴。今年,同样的大模型技术,已经在学开车了。
而且学得还不错,今年小鹏的VLA2.0已经上车而且取得了不错的评价。
这个东西叫VLA,全称Vision-Language-Action Model,翻译过来就是"视觉-语言-动作模型"。你可以把它理解成一个既能看路、又能听懂人话、还能直接打方向盘的AI司机。
这不是概念,不是PPT。英伟达在推,Waymo在用,国内的几家头部智驾公司已经跑通了闭环。
2026年,VLA就是智能驾驶最大的技术变量。没有之一。
今天这篇文章,我尽量用人话把这件事讲透。
一、先搞明白一件事:现在的智驾到底"笨"在哪
你有没有想过一个问题:为什么现在的智能驾驶,高速上表现还行,一进城就抓瞎?
答案很简单——它不是真的在"开车",它是在做填空题。
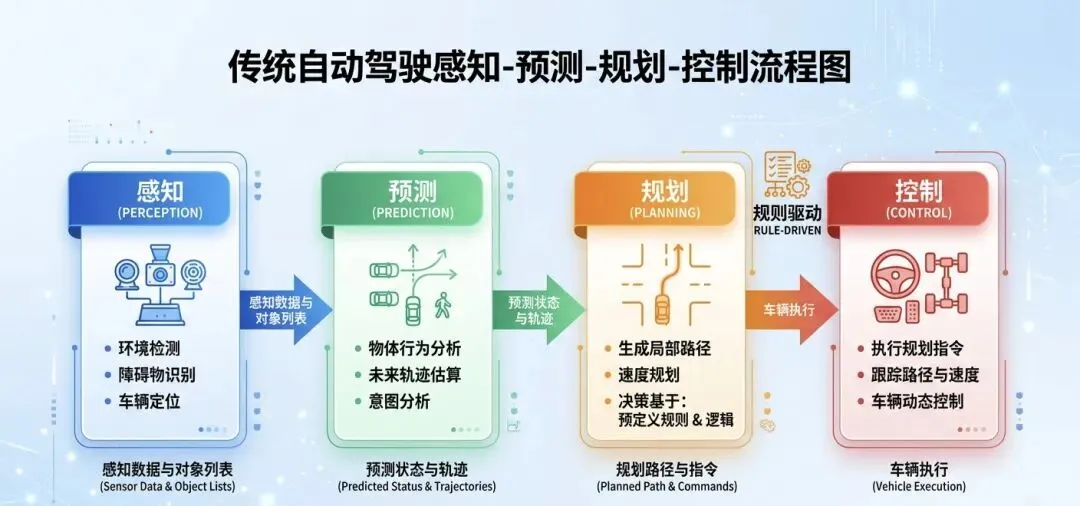
现在主流的智驾方案,本质上是一条流水线:
感知模块负责看——前面有辆车,左边有个行人,右边有个锥桶。
预测模块负责猜——那辆车可能要变道,行人可能要过马路。
规划模块负责算——我应该减速、让行、然后从左侧绕过去。
控制模块负责执行——打方向盘、踩刹车,完事。
四个模块,各干各的,中间靠一套规则串起来。
问题出在哪?出在"规则"两个字上。
城市道路最让人头疼的是什么?是那些"规则覆盖不了"的场景。
外卖小哥逆行,你让还是不让?前面有辆三轮车,上面堆了两米高的纸箱子,挡住了你的视野,你怎么处理?工地施工,地上画的线和实际通行路径完全不一样,你信谁的?
老司机处理这些场景靠的是什么?靠的是"经验"加"常识"。
他知道外卖小哥赶时间不会让你,他知道三轮车速度慢要提前变道,他知道工地这种情况跟着前车走就对了。
这种能力,你没法写成规则。你写一千条、一万条,永远有第一万零一种情况在路上等着你。
这就是传统智驾的天花板。
二、VLA是什么?一句话说清楚
好,铺垫完了,该请主角登场了。
VLA的核心思路特别简单,简单到你会觉得"这不是显而易见的吗"。
既然大模型能看图、能聊天、能推理——那为什么不能让它直接开车?
于是就有人真这么干了。
VLA的"三个字母"代表三种能力:
V是Vision,视觉。给它摄像头画面,它能看懂路况。
L是Language,语言。你可以用自然语言跟它交流,比如"前面在修路,靠右走",它能听懂。
A是Action,动作。它的输出不是一段文字,而是直接的驾驶指令——方向盘转多少度、油门踩多深、刹车力度多大。
看到、理解、行动。一个模型,端到端,一步到位。
你可以把它想象成这样一个场景:
副驾坐了一个人,他看着前面的路,脑子里在思考,然后手直接握着方向盘开。他不需要先跟旁边的人说"前面有障碍物",再让另一个人说"建议减速",再让第三个人踩刹车。
他自己就全干了。
这就是VLA和传统方案最本质的区别——它不是一条流水线,它是一个完整的"大脑"。
三、VLA到底怎么工作的?拆给你看
光说概念没用,我们来拆一下VLA的技术实现。别怕,我不写公式,保证你能看懂。
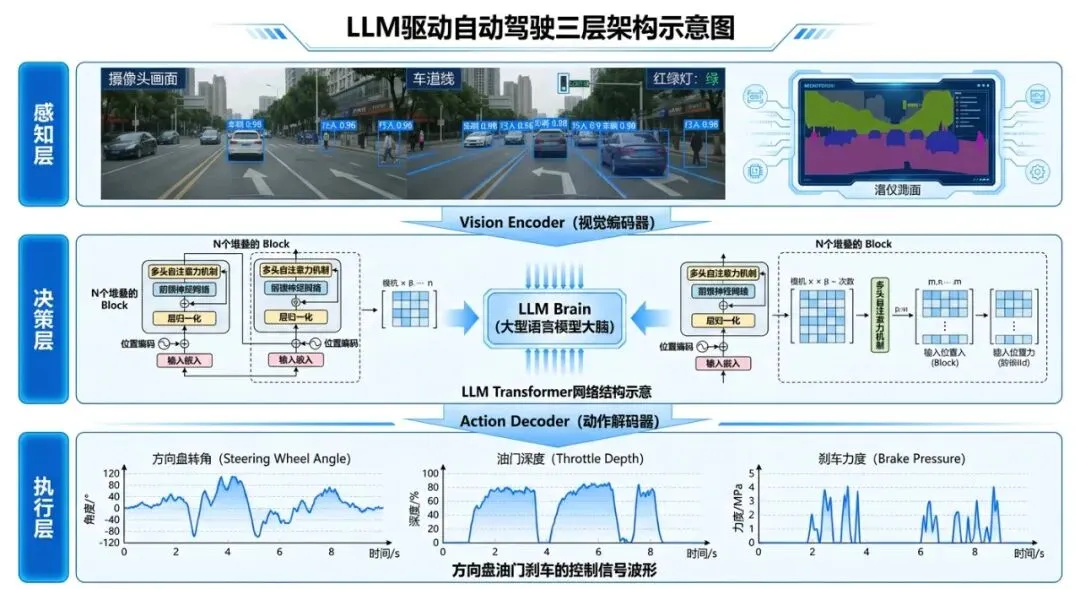
VLA模型通常由三个核心部分组成:
第一层:视觉编码器——"眼睛"
摄像头拍到的画面,是一堆像素。VLA需要先把这些像素变成模型能理解的"语言"。
怎么变?用视觉编码器。
你可以把它理解成一个"翻译官"。它把图像里的每个区域翻译成一个个"视觉token"——本质上就是一串数字向量。
这些向量包含了丰富的信息:这块区域是一辆白色的SUV、距离大概30米、正在减速、车尾灯亮了。
主流方案里,视觉编码器一般用的是ViT(Vision Transformer)或者SigLIP这类预训练模型。你不用记这些名字,只需要知道——这些模型在海量图片上训练过,已经非常擅长"看图说话"了。
这一步做完,图像就变成了一种大模型能处理的数据格式,可以和文本信息放在一起处理了。
第二层:大语言模型——"大脑"
这是VLA的核心中的核心。
视觉编码器输出的视觉token,加上可能存在的语言指令(比如导航信息、用户的语音命令),一起喂给一个大语言模型。
没错,就是你用的那种大语言模型。LLaMA、Qwen、GPT这些架构,换个训练数据,就能用在驾驶场景里。
这个大语言模型做什么?做推理。
它会综合所有输入信息,理解当前场景,做出判断:
"前方30米有一辆SUV正在减速,可能是要右转。右侧车道有一辆公交车正在靠站。左侧车道空闲。当前车速60km/h。最优策略是轻踩刹车减速至45km/h,同时向左微调方向准备从左侧通过。"
注意,这段"思考"在模型内部完成,实际推理时间可能只有几十毫秒。但它确实在做类似人类老司机的"场景理解"和"决策推理"。
这就是大模型的威力——它见过海量的驾驶场景,它知道SUV亮刹车灯通常意味着什么,它知道公交车靠站以后可能会有乘客下车横穿马路。
这些"常识"和"经验",不是写规则写出来的,是从数据里学出来的。
第三层:动作解码器——"手脚"
大模型想好了怎么开,但它的输出还是一串数字。最后一步,需要把这些数字变成具体的控制指令。
这就是动作解码器干的事。
目前主流有两种方案:
第一种是直接回归。模型直接输出连续值——方向盘角度、加速度、制动力。简单粗暴,但有时候精度不够。
第二种更聪明,叫离散化token预测。
什么意思?把动作空间也变成"词汇"。
比如,把方向盘的转角从-540度到+540度切成256个离散值,每个值对应一个token。加速度也切成256个值。这样,输出驾驶动作就变成了"说下一个词"——本质上和大模型生成文字是完全一样的机制。
Google旗下DeepMind的RT-2就是这么干的,效果出奇的好。
这三层合在一起,就是一个完整的VLA模型:
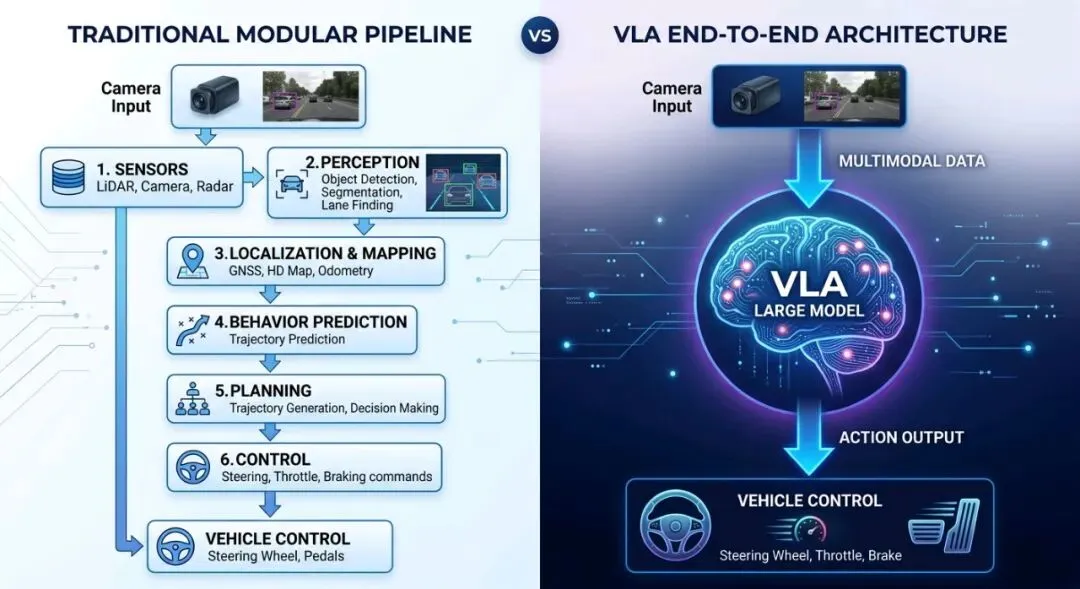
摄像头画面进去,方向盘指令出来。中间只有一个模型,没有人为设定的规则,没有模块间的信息损耗。
四、VLA和端到端有什么区别?这个问题问得好
有人会说:端到端不是早就有了吗?特斯拉的FSD v12不就是端到端?VLA有什么不同?
这个问题问到了关键。
端到端是一个大的方向,VLA是端到端里面的一个技术路线。
特斯拉FSD v12确实是端到端——传感器输入直接到控制输出,中间用一个大网络搞定。但它用的不是大语言模型架构,它的网络结构更多是传统的深度学习范式。
VLA的关键区别在于那个"L"。
语言,不仅仅是让你能跟车对话。语言带来的是三个巨大的优势:
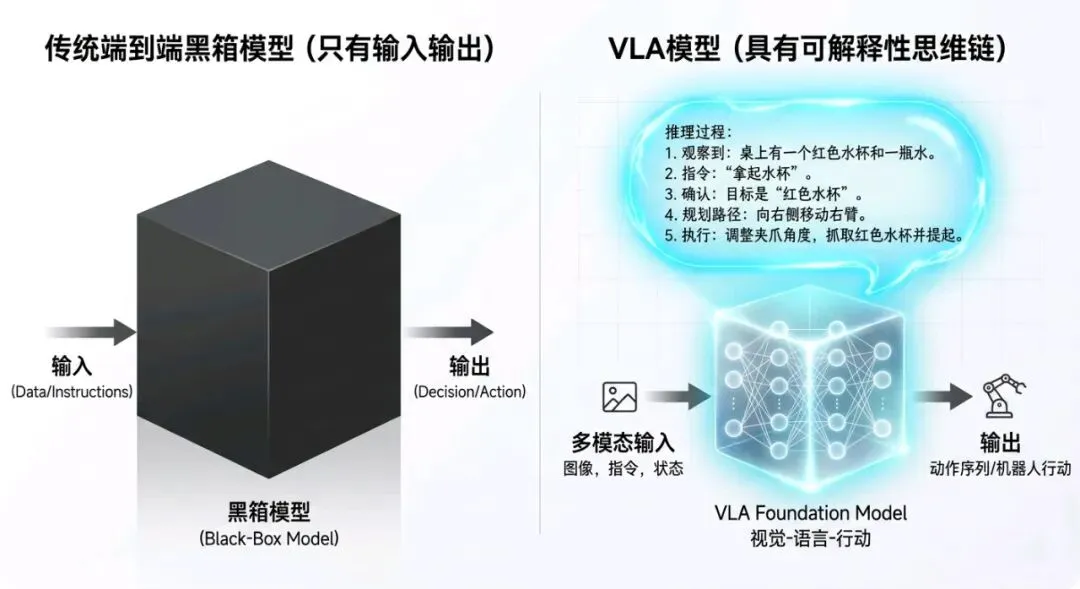
第一,可解释性。
传统端到端是个黑箱。车做了一个动作,你不知道它为什么这么做。出了事故,你复盘都没法复盘。
VLA因为内核是语言模型,它可以"说出"自己的推理过程。比如:
"我检测到前方有施工区域,道路变窄,限速降低。右侧有临时护栏,左侧有对向来车。我决定减速至20km/h,保持当前车道缓慢通过。"
这个能力在量产车上非常关键。OTA出了问题,工程师可以回看模型的"思维链",快速定位是哪个环节出了错。这对于法规审批也至关重要——你得告诉监管部门,这台车为什么要这么开。
第二,泛化能力。
大语言模型最强的能力是什么?是它在海量文本上学到的世界知识。
你从来没让它学过"看到前面有辆洒水车就别跟太近"这个规则,但它从大量文本中知道洒水车会喷水、路面会湿滑、跟太近会影响视野。
这种跨领域的知识迁移,是传统感知-预测-规划流水线根本做不到的。
一个训练数据里从来没出现过的罕见场景——比如一辆拉着巨大气球的卡车——传统方案可能直接懵了,但VLA大模型可能通过它对"气球"和"风"的常识理解,判断出这个气球可能会飘动遮挡视线,从而提前做出规避。
这叫zero-shot能力。传统方案靠数据覆盖,VLA靠常识推理。
第三,交互能力。
你可以对车说:"我赶时间,开快一点。"
你可以说:"右边那个商场,我要去那儿,找个好停的位置。"
你甚至可以说:"前面那辆车开得太慢了,帮我找机会超过去。"
VLA天然具备理解自然语言的能力。这不是把一个语音助手和一个驾驶系统硬拼在一起,而是在同一个模型里同时处理语言理解和驾驶决策。
语言不再只是一个附加功能,它成了驾驶决策的一部分。
五、训练一个VLA模型需要什么?
说完了推理端,我们来看训练端。很多人好奇——VLA这么厉害,它怎么训出来的?
核心答案就一个词:数据。
但这个数据和你想的不一样。VLA的训练数据不是简单的"图片+标注",而是一种全新的数据格式:
场景视频 + 语言描述 + 对应的驾驶动作)三元组
举个例子:
一段10秒的行车记录仪视频,画面内容是一个左转弯场景。
对应的语言描述是:"在路口左转,注意对向直行车辆,等待间隙后完成转弯。"
对应的驾驶动作是:前3秒匀速直行,第4秒开始减速,第6秒方向盘左打30度,第8秒加速驶出弯道。
成千上万、成百上千万条这样的三元组数据,喂给模型训练。
数据从哪来?两个渠道:
第一,真实道路数据。
量产车跑在路上,每时每刻都在产生数据。摄像头画面、车辆控制信号(CAN总线数据)、GPS轨迹、IMU数据,全都可以自动采集。
特斯拉有几百万辆车在路上跑,这就是它最深的护城河。国内的蔚小理、华为、比亚迪,也在拼命上量——上量不是为了卖车,是为了采数据。
采回来的数据做后处理:用自动标注工具给场景打标签,用大模型自动生成语言描述,再和CAN总线里的方向盘油门刹车信号对齐。一条三元组数据就有了。
第二,仿真数据。
真实数据永远不够。特别是那些corner case——翻车、侧翻、行人鬼探头——这些你没法在真实道路上主动采集。
所以需要仿真。
在仿真环境里,你可以生成任意场景:暴雨、大雾、逆光、道路塌方。而且仿真里的数据自带精确标注,不需要人工标注。
NVIDIA的DRIVE Sim、Waymo的仿真平台,都是为了批量生产训练数据。
有了数据,训练过程一般分三步:
第一步,预训练。用海量的互联网图文数据训练视觉编码器和语言模型的基础能力。这一步不涉及驾驶,就是让模型学会"看"和"说"。
第二步,微调。用驾驶领域的三元组数据做微调,让模型学会把"看到的场景"和"应该执行的动作"关联起来。
第三步,强化学习。让模型在仿真环境里自己跑,跑得好给奖励,跑得差给惩罚。不断优化它的驾驶策略。
这三步和ChatGPT的训练流程几乎一模一样——预训练、SFT(有监督微调)、RLHF(基于人类反馈的强化学习)。只不过输出从文字变成了驾驶动作。
你看,智能驾驶和大模型,在技术底层其实是同一件事。
六、VLA面临的三大挑战:别光吹,也得说问题
技术很性感,但离量产还有几座大山要翻。我不当吹鼓手,实打实说三个问题。
第一座山:推理速度。
开车这件事,对延迟的要求是毫秒级的。
你踩刹车,100毫秒内车必须有反应。200毫秒以上,在120km/h时速下,车已经往前冲了6.7米。
大语言模型有多慢你是知道的。ChatGPT回答一个问题要好几秒,token一个一个往外蹦。
VLA面临同样的问题。模型参数量一大,推理就慢。但驾驶场景不允许你慢。
怎么解?
业界正在从几个方向突破:
模型蒸馏——用大模型训练小模型,保留80%的能力,推理速度快5倍。
专用芯片——NVIDIA的Thor、地平线的征程6,都在做针对Transformer推理的硬件加速。
稀疏推理——不是每一帧都需要完整的推理。直道上一切正常,模型可以"偷懒",只有遇到复杂场景才全力运转。
目前头部方案已经能做到50-100毫秒级的推理延迟,勉强够用。但要做到人类驾驶员的反应速度(150毫秒左右),还需要继续优化。
第二座山:安全性验证。
这可能是最大的问题。
传统的模块化方案,每个模块的行为是可预测的。你设定了规则"前方障碍物距离小于10米就刹车",它一定会刹车。你可以穷举测试。
VLA是个端到端的大模型。你没法穷举测试它在所有场景下的行为。你甚至没法完全理解它为什么在某个瞬间做了某个决策。
这对安全性验证来说是噩梦级别的挑战。
怎么证明一个VLA模型"足够安全"可以上路?目前没有标准答案。
行业正在探索的方向包括:
形式化验证——用数学方法证明模型在某些关键场景下的行为边界。
影子模式——VLA在后台运行,和传统方案的决策做对比,持续验证但不实际控车。
安全笼架构——VLA做主驾驶决策,但套一层规则化的安全层。VLA想做的任何动作,如果违反了安全底线(比如碰撞检测),安全层直接否决。
最后这个方案最现实,也是目前量产车大概率会采用的架构。VLA负责"聪明",安全层负责"兜底"。
第三座山:数据壁垒。
前面说了,训练VLA需要海量的驾驶三元组数据。
这个数据,不是谁都有的。
特斯拉靠几百万辆车采集,这是它独家的数据飞轮。Google靠Waymo的无人车队,跑了几千万英里的真实道路。
国内呢?
蔚来有大几十万辆车,小鹏有大几十万辆,理想超过了一百万辆。这些量产车每天在路上跑,每天都在产生数据。
但华为和大疆这样的方案商,自己不造车,数据要靠合作车企提供。数据的量和质都受制于人。
纯创业公司就更难了。没有车队,没有数据飞轮,只能靠仿真和开源数据集训练。这在VLA时代会越来越吃力。
数据壁垒,可能会让智驾行业加速洗牌。
七、谁在做VLA?全球玩家盘点
光讲技术太干,我们看看谁在真正做这件事。
国外:
Google DeepMind的RT-2是VLA的开山之作。2023年发布,首次证明了"大语言模型可以直接输出机器人动作"这条路走得通。虽然它最初是用在机械臂上的,但架构可以迁移到驾驶场景。
Waymo被曝出在内部研发基于大模型的端到端驾驶方案EMMA,本质上就是VLA路线。Google的Gemini大模型是它的底座。
特斯拉的FSD v12虽然目前不是严格意义上的VLA(没有显式的Language组件),但马斯克多次暗示下一代FSD会整合多模态大模型能力。以特斯拉的数据量和工程能力,它一旦切VLA路线,速度会非常快。
NVIDIA在CES 2025上重点推了它的DRIVE Thor平台,专门为VLA类模型的车端推理做了硬件优化。它同时还开源了一些VLA的研究框架,想做这个领域的"基础设施"——卖铲子的永远不亏。
国内:
华为在VLA上投入非常重。ADS 3.0已经引入了大模型,而内部被称为"ADS Next"的下一代系统据说全面转向VLA架构。华为的优势是全栈能力——芯片(昇腾)、模型(盘古)、算法、数据工具链全自研,不受制于人。
小鹏去年拿出了基于大模型的端到端智驾方案,何小鹏在多个场合提到"VLA是智驾的终局技术路线"。小鹏的优势是自研芯片(图灵芯片)加上自有车队数据,闭环能力强。
理想也在布局VLA。理想的打法比较务实——先用端到端跑通高速和城区NOA,积累数据和经验,再逐步引入大语言模型的能力。一百多万辆的车队是理想最大的筹码。
还有一些专注VLA的创业公司值得关注,比如商汤绝影、毫末智行、元戎启行等。这些公司在模型层面有不错的积累,但最终能不能跑出来,取决于它们能不能拿到足够的数据和上车机会。
八、VLA会怎样改变你的用车体验?
聊了这么多技术,你可能想问:跟我有什么关系?
关系大了。
场景一:你不再需要学习怎么用智驾。
现在的智驾系统,你得知道在哪个界面开启NOA、什么时候该接管、什么路段能用什么不能用。这些心智负担对普通消费者来说是很重的。
VLA时代,你直接说话就行。
"走高速去上海,路上帮我找个服务区休息一下。"
车听懂了,自己规划路线,自己开,到了合适的服务区自动提醒你。
你不需要理解任何技术概念。你就当它是一个司机,用人话跟它交流。
场景二:它真的能处理那些让你心惊肉跳的场景。
加塞、鬼探头、电动车逆行。这些场景在中国的城市道路上每天都在发生。
传统智驾要么处理不了直接退出,要么处理得很僵硬让你恨不得自己来。
VLA因为有"常识推理"能力,处理这些场景会更接近老司机。它不是在查规则库,它是在"理解"这个场景,然后做出合理的判断。
场景三:车真正成为私人助理。
"我下午三点要到机场,帮我算算几点出发。"
"前面那个路口有家星巴克,帮我点杯咖啡,到了之后直接取。"
VLA把驾驶能力和语言理解能力融合在一个模型里,意味着车可以同时处理"开车"和"服务"两件事,而且两件事之间可以互相关联——它知道你要赶飞机,所以会开得快一些;它知道你要取咖啡,所以会选择更靠近门店的车道停车。
这不是两个系统的拼接,是一个系统的自然涌现。
九、终局之战:VLA到底是不是智驾的答案?
说到这里,我想表达一个观点。
VLA不是答案。至少现在不是。
它在推理速度上还有瓶颈,在安全性验证上还没有成熟方案,在数据获取上还有巨大的壁垒。
但VLA代表的方向,几乎是行业共识——智能驾驶的终局,一定是一个统一的大模型,而不是一堆模块拼起来的流水线。
为什么?
因为人类就是一个统一的大模型。
你开车的时候,你的眼睛、大脑、手脚是一个整体。你不会先用一个模块识别障碍物,再用另一个模块预测轨迹,再用第三个模块规划路径。你看到、理解、行动,一气呵成。
VLA的野心,就是复刻这个过程。
而且历史经验告诉我们,在AI领域,大力出奇迹是真实存在的。GPT-3到GPT-4的飞跃,没有本质的架构创新,就是更多的数据、更大的模型、更多的算力。
VLA很可能会走同样的路。当数据从百万条变成十亿条,当模型参数从几十亿变成几千亿,当车端芯片的算力从几百TOPS变成几千TOPS——很多现在看起来难以逾越的问题,可能会自然解决。
这就是Scaling Law的魔力。
2026年,我们正站在智能驾驶的"ChatGPT时刻"前夜。VLA不会一夜之间改变一切,但它会像大语言模型改变互联网一样,从底层重塑整个智能驾驶的技术栈和产业格局。
今天看到这篇文章的人,两年后回头看,可能会发现——这就是那个拐点。
以上。
如果你觉得这篇文章让你对VLA有了更清楚的理解,转发给你那些还在纠结"智驾到底行不行"的朋友。
这个行业正在发生的变化,比大多数人想象的要快得多。





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
