从“看见”到“推演”:DLWM如何用双潜在世界模型把自动驾驶预训练带进高斯时代
http://arxiv.org/abs/2604.00969v1
引言(把自动驾驶拉回到“可计算的未来”)
要理解自动驾驶感知为何总像在追赶现实,我们需要回到控制论和概率论的源头。上世纪中叶,人们开始相信:一个足够准确的模型,可以让机器不仅识别世界,还能预测世界,从而做出稳定的决策。自动驾驶的难点从来不在“看清楚一帧图像”,而在于“把下一秒的世界算出来”。这件事本质上是一种时间上的推理:车辆必须在不完备、含噪且不断变化的观测下,构造一个可推演的内部世界。
过去十年,深度学习让感知网络在静态任务上突飞猛进:检测、分割、跟踪的指标不断刷新。但当我们把这些能力放到规划与控制链路里,问题会立刻暴露:感知输出往往是离散的、片段的、缺少不确定性刻画的;更关键的是,它们不天然服务于“动态推演”。于是行业开始转向世界模型(World Model)路线,即用一个可学习的动力学模型在潜在空间里预测未来,再把规划建立在预测之上。
本论文正是在这条路上向前迈了一步:它提出双潜在世界模型(Dual Latent World Models),并以整体高斯中心(Holistic Gaussian-centric)的方式做预训练,让模型在更统一的表征里同时承载几何、语义与时序动力学。这不是又一个更大的Backbone,而是一次把“表示”和“推演”重新对齐的尝试。
背景(为什么“感知强”不等于“可规划”)
自动驾驶的经典模块化流水线是:感知输出目标与车道,预测输出轨迹分布,规划输出自车动作。这个体系的问题并非工程上不能做,而是信息接口天然丢失:感知往往给出边界框或栅格占用,但规划真正想要的是一个可微、可推演、带不确定性的场景状态。
要理解这一矛盾,我们可以用一个类比:感知像在给你一本“场景词典”,列出这条街上有什么;而规划需要的是“连续剧剧本”,不仅要知道角色是谁,还要知道下一幕怎么演。静态识别做得再好,如果不能稳定编码速度、加速度、交互意图,以及遮挡下的多解性,就很难支撑长时域决策。
近年的解决思路大致分三类:
1. 以BEV为中心的统一空间表征,把多相机、多帧融合到鸟瞰图里,强化几何一致性与融合效率,但动力学建模常常依赖额外的时序模块,预测与不确定性刻画并不天然。
2. 以占用或流为中心的中间表示,用占用网格、体素场或运动流来连接感知与规划,能对动态做一定表达,但在精细结构、遮挡恢复、以及多模态未来上仍显吃力。
3. 以世界模型为核心的端到端推演,把场景压缩到潜在变量中,再做序列预测与规划。然而世界模型的关键挑战在于潜在空间怎么设计:如果潜在变量太抽象,几何对不上;如果太具体,学习难度和计算成本又陡增。
该论文切入的正是这个“潜在空间设计”的关键点:用高斯中心作为场景的基本构件,并引入双潜在路径分别承载互补的信息,从而在预训练阶段就让模型学会“以规划友好的方式编码动态”。
核心创新(双潜在世界模型与整体高斯中心:把场景写成可推演的“概率几何”)
1. 高斯中心表征:用一组可学习的“概率粒子”写场景
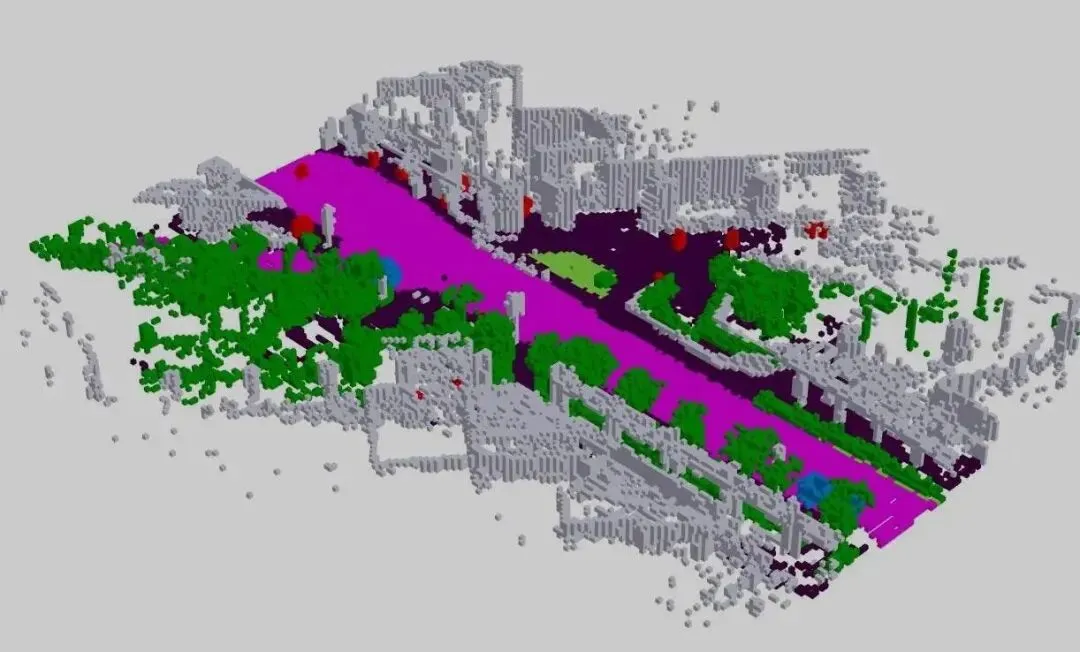
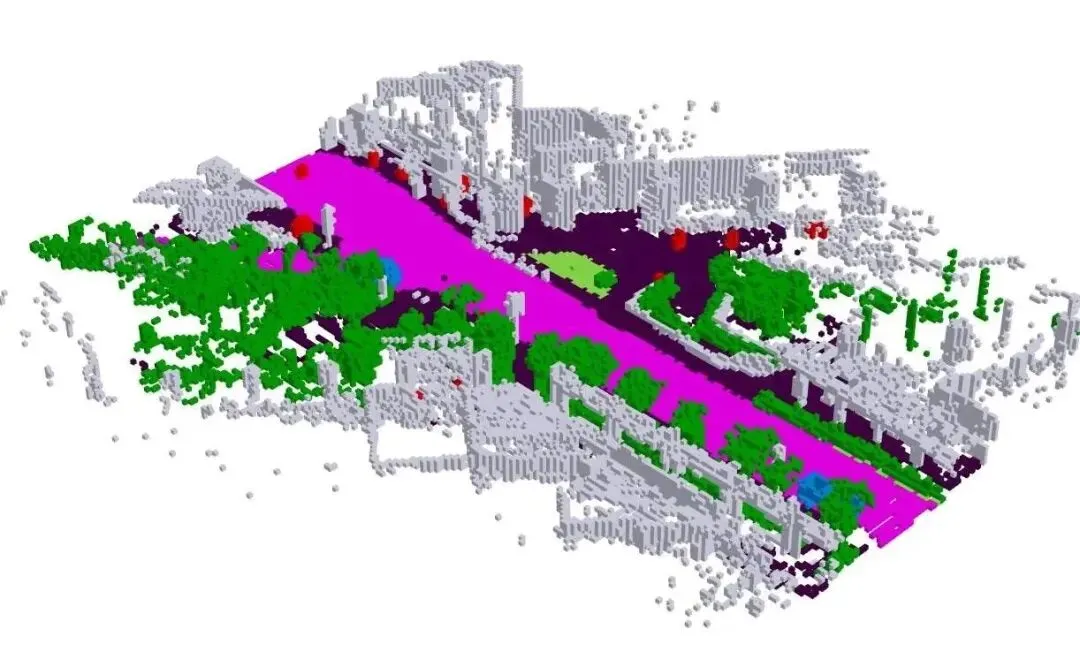
该论文选择以高斯中心作为核心表征。可以把它理解为:场景不是一张密集栅格,也不是一串离散目标列表,而是一组带位置、尺度、方向以及可能的语义属性的高斯“粒子”。每个粒子像是一个可微的局部实体:它既能表达连续几何(相比栅格更细腻),又能容纳不确定性(相比硬边界更符合现实)。
更重要的是,这种表示天然适合渲染与重建类目标:如果你能用这些高斯粒子在不同视角下重投影并解释观测,那么潜在变量就被几何约束住了,不会漂移成“只对某个损失函数有用”的抽象向量。这一点对世界模型尤其关键,因为时间上的预测必须建立在稳定、可组合的状态变量上。
所谓整体高斯中心(Holistic Gaussian-centric),核心含义是:预训练的目标不是让网络学一个局部任务,而是让它围绕高斯中心这一统一载体,学习从多视角、多时间的观测中抽取、维护、更新整套场景状态。这样一来,后续无论接规划、预测还是行为克隆,都能复用同一套“可推演的场景记忆”。
2. 双潜在世界模型:把“看见的世界”和“推演的世界”分开建模
世界模型通常包含两个部分:编码器把观测压到潜在空间,动力学模型在潜在空间做时间递推。现实中的矛盾在于:观测带来的证据是强约束的,但不完整;动力学推演需要保持连贯性,却必须容忍遮挡、多解与噪声。如果只用单一潜在空间,很容易在“贴合观测”和“保持可预测性”之间拉扯。
该论文的双潜在设计,本质上是在潜在层面做了分工:一条潜在路径更偏向从观测中抽取即时的场景证据,另一条潜在路径更偏向维持可递推的动态状态。你可以把它类比为人类驾驶的两套系统:一套是视觉系统不断刷新眼前信息;另一套是脑内的运动模型保持对周围车辆速度与意图的连续估计。两者必须协同,但不必完全同构。
在训练上,这种结构带来的直接好处是:模型可以在有观测时进行校正,在观测不足或遮挡时依赖动力学维持合理的场景演化,从而更稳地编码场景动态。对于自动驾驶而言,这意味着在长时序、复杂交互、以及传感器不稳定的情况下,状态表征不至于崩塌。
3. 以预训练为核心:让“规划所需的信息”在无标注或弱标注阶段就学到
该论文强调预训练骨干的价值:不是为某个特定下游任务刷指标,而是提前把动态编码能力注入表示里。过去很多预训练更像是“视觉特征预训练”,得到的是对纹理、边缘、局部语义敏感的表示;但规划需要的是另一类信息:速度场、交互关系、可行驶空间的连续几何,以及对未来不确定性的刻画。
围绕高斯中心的整体预训练,配合双潜在世界模型的时间递推,使得模型在预训练阶段就被迫回答一个更难但更接近驾驶的问题:怎样用一个统一的潜在状态解释多帧、多视角观测,并能稳定预测其演化。它训练出来的骨干更像“可推演的场景状态机”,而不仅是“图像特征提取器”。
4. 为什么这条路更像“工业答案”
工业界在意的不只是平均性能,更是稳定性与可维护性。高斯中心的连续表示让系统更容易做几何对齐、做不确定性管理,也更便于与仿真、渲染、重建工具链对接。双潜在结构则提供了一种工程上可解释的分层:观测更新与动力学预测各司其职,便于诊断失败模式。
把这些放在一起,该论文传递的核心洞察是:双潜在世界建模能更好编码场景动力学,从而为面向规划的感知提供更强的预训练底座。它把预训练从“学会看”推进到“学会推演”。
应用与影响(对自动驾驶与更广泛时空AI的意义)
如果这套思路落到系统里,最直接的影响有三点。
1. 它可能降低端到端规划对大规模人工标注的依赖,因为模型在预训练阶段就学到大量时空一致性与几何约束,微调时只需对齐任务头或策略头即可。
2. 它可能改善长尾场景与遮挡场景下的稳定性,因为双潜在机制让模型在“证据不足”时仍能靠动力学维持合理状态,而不是把不确定性错误地当成噪声抹掉。
3. 它可能让“规划友好表征”成为新的共享接口:感知、预测、规划不必各自训练一套互不兼容的中间表示,而是围绕高斯中心这一连续概率几何来协同。
把视野放大到同日的相关研究,会发现一个共同主题:AI正在从静态识别走向时空推演与持续学习。遥感领域对连续视觉-语言学习的关注,揭示了模型在时间维度上的遗忘与迁移规律;LAPIS-SHRED试图从短时序恢复潜在相位,解决稀疏观测下的时空重建;像素内部探查用生成式方法处理非线性解混,本质上也是在不完备观测下重建“隐藏状态”。这些工作与本论文在方法上不同,但都指向同一个产业需求:在不完整数据中建立可演化的内部世界,并让模型在时间中保持一致。
对自动驾驶来说,世界模型的价值不仅是预测准确率,更是让系统具备“把未来当作可计算对象”的能力。一旦这件事成立,规划就不再是规则堆叠,而更接近基于推演的决策。
总结与思考(从表征革命到推演革命)
要理解这项研究的意义,我们需要回到一句朴素的话:驾驶不是识别任务,而是控制任务;控制的前提,是对未来的可计算预测。本论文用双潜在世界模型缓解了观测与预测之间的结构性矛盾,用整体高斯中心把场景状态固定在更连续、更可微、更可表达不确定性的坐标系里,并把这一切前置到预训练阶段,使骨干网络天然服务于规划。
它带来的启发有两点。
1. 未来自动驾驶的竞争,可能不再是“谁的检测更准”,而是谁的世界模型更稳定,谁能在遮挡、稀疏与长尾中保持可推演的场景状态。
2. 预训练的终点不一定是通用表征,而可能是通用动力学:一种能跨城市、跨传感器、跨天气维持一致推演能力的状态空间。
最后留下一个值得行业反复追问的问题:当我们用越来越强的世界模型去“预测未来”,我们究竟在优化什么?是下一帧的像素,是轨迹分布的似然,还是一种能在关键时刻做出正确决策的结构化不确定性管理能力。真正决定自动驾驶上限的,往往是最后一种。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
