萝卜趴窝:自动驾驶商业化何去何从
- 2026-04-17 23:50:56
2026年3月31日20时57分,武汉二环线、三环线、白沙洲高架等主干道突发罕见一幕:80至100台萝卜快跑自动驾驶车辆集体停摆,快车道上的静止车辆引发追尾隐患,被困乘客最长滞留超1小时,多名乘客反映SOS按钮及客服电话响应失灵。这场事件不仅造成城市交通局部瘫痪,更给自动驾驶商业化敲响警钟。这对普通消费者意味着什么?答案很直接:你所信赖的“AI司机”,可能在突发故障时无法完成有效避险,你的出行安全,仍依赖于企业未完善的技术冗余和应急机制。
武汉交警于4月1日凌晨发布通报,初步判定故障为系统故障,无人员受伤,乘客已全部安全下车,事故原因正在进一步调查中;萝卜快跑客服随后称故障系“网络原因”所致。截至4月1日10时,百度方未披露故障具体原因及受影响乘客赔偿方案,其武汉全域服务一度暂停,后续逐步恢复,据当日出行数据估算,此次故障影响超800名当日出行用户。这起事件的核心拷问是:为何近百台车辆会因网络异常集体“脑死亡”?
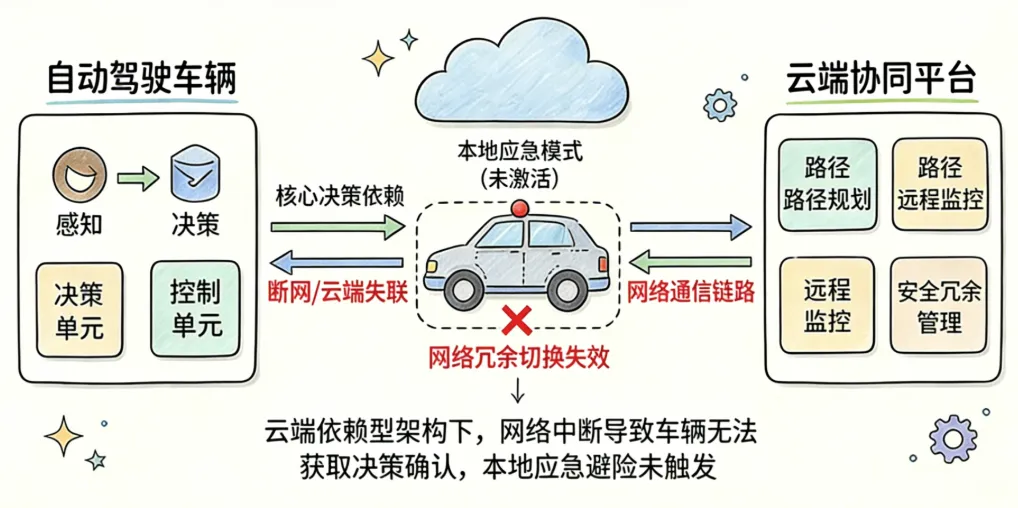
根源在于百度Apollo“单车智能+云端协同”架构的实操短板,云端协同与本地冗余的衔接失效,据萝卜快跑官网及行业公开信息,其系统虽采用“单车智能+云端协同”架构,且宣称配备十重安全冗余(含网络冗余),但百度Apollo系统对云端的依赖度较高,核心决策需云端协同确认,一旦云端协同失效,应有的紧急避险措施形同虚设。交通运输部规定,自动驾驶出租车远程安全员与车辆比例不低于1:3,这意味着每辆车必须时刻保持云端连接,一旦断连,安全监管链条直接断裂,这也是此次故障中车辆无法正常响应的重要原因之一。
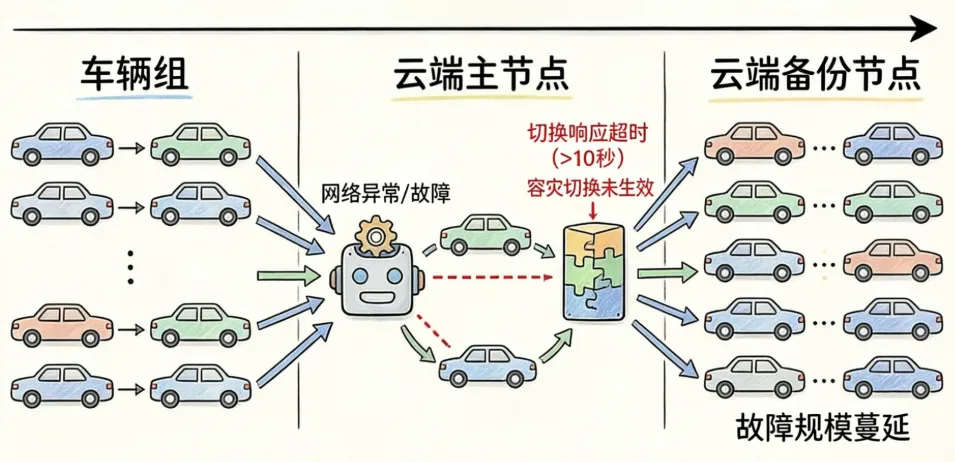
理想状态下,网络中断后,车辆应自动切换至本地应急模式,执行减速、靠边、开双闪等避险操作,但本次事件中,车辆直接原地停滞,并没有靠边停放,暴露了网络冗余机制的实操失效。据萝卜快跑官网介绍,其配备“混合网络、千兆以太网和高速CANFD、四路四通”的网络冗余设计,但此次故障中未实现有效切换。此外,近百台车辆同时故障,说明云端协同系统的并发故障处理能力不足,据行业标准,L4级自动驾驶系统的云端容灾备份节点切换响应时间应不超过10秒,此次故障中该机制未及时生效,导致故障规模化蔓延。
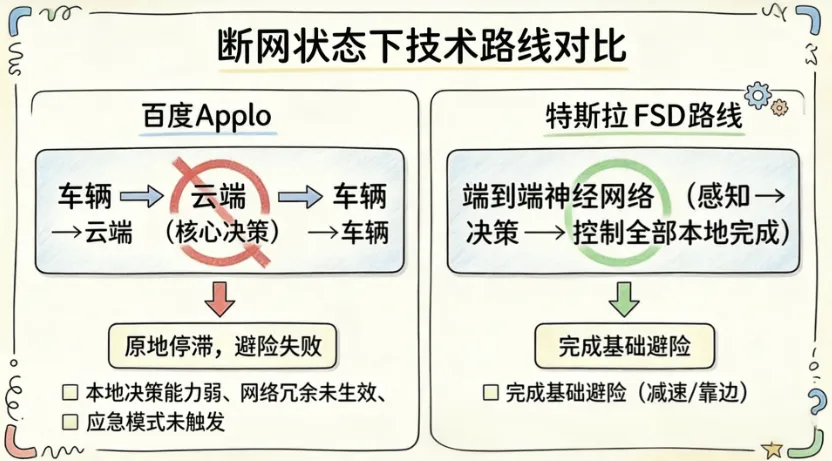
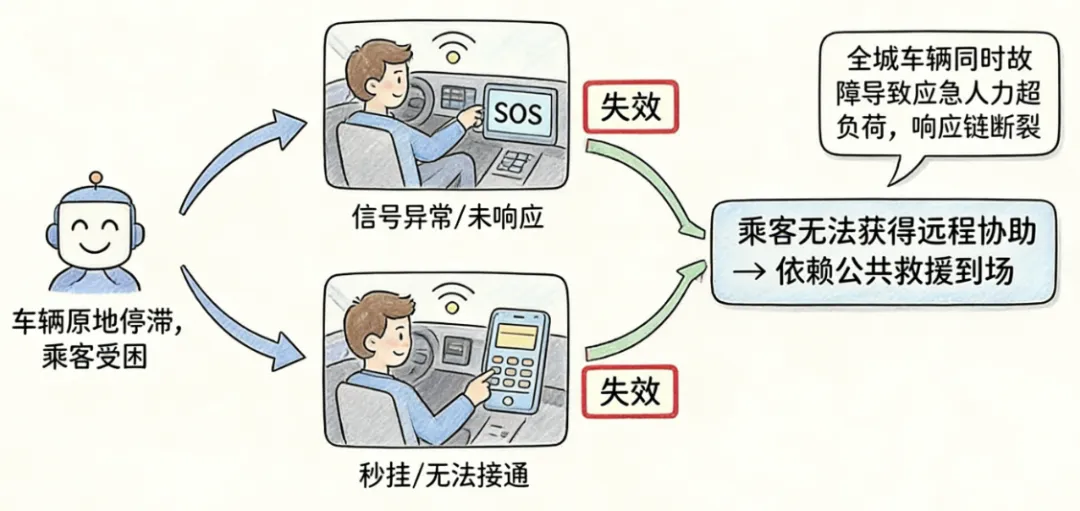
据多名被困乘客反馈及媒体报道,此次故障中,多数乘客遇到SOS按钮响应异常、客服电话秒挂或无法接通的情况,百度CEO李彦宏后续也坦言,因全城车辆同时停摆,工作人员应对不及时。最终,武汉交管、交通运输部门调集警力,会同萝卜快跑工作人员赶赴现场处置,徒步上高架疏散被困乘客,公共资源被迫为企业的技术疏漏“兜底”。但这并非孤立事件,此前旧金山曾因停电导致Waymo无人车大面积停摆,与本次事件如出一辙,两者均暴露了“云端依赖型”技术路线在极端场景下的脆弱性。作为对比,特斯拉FSD中国版采用端到端技术路线,2025年9月已实现全量推送,其城区NOA实测通过率达89%,具备较强的本地决策能力,断网状态下仍能完成基础避险操作,无需过度依赖云端指令。
事件发生后,不少人开始反思,当前的自动驾驶技术是否能够支撑商业化的推广。公开数据显示,萝卜快跑于2022年5月在武汉正式落地,2022年8月启动全无人商业化运营,截至2025年Q4,其订单量达340万单,累计运营覆盖全球22座城市,2025年8月已在武汉实现单车收支平衡。但规模化扩张的同时,其应急响应体系未能同步完善,据曾任职萝卜快跑的工作人员透露,部分城市40余人的团队需管理20多辆车,应急人力配置与运营规模不匹配。现行《武汉市智能网联汽车发展促进条例》虽明确企业责任,但对AI故障的责任认定、交管部门的干预权限仍有空白。
最后借着这个事件总结下吧,从从业者视角,本次事件提醒技术研发需回归“安全优先”,通信冗余、本地应急能力的完善刻不容缓;从企业视角,商业化扩张不能以削减安全成本为代价,需建立与规模匹配的应急体系;从行业视角,需加快完善法规,明确技术标准,避免“技术试错”由公众和公共资源承担。自动驾驶的成熟,从来不是速度的比拼,而是安全冗余的持续迭代。关注我,后续继续介绍自动驾驶最新新闻和业务逻辑。
#萝卜快跑 #自动驾驶瘫痪 #云端依赖 #本地冗余 #应急机制 #通信冗余 #最小风险 #自动驾驶技术 #FSD #车联网 #公共安全 #商业化安全 #智能网联汽车 #智能网联车联网技术

