
🐉 龙哥读论文知识星球来了!想让你的AI模型像这篇论文里一样,快速学会“入乡随俗”,高效适配新场景吗?星球里每天都有自动驾驶、域适应、模型迁移的最新论文拆解和实战代码分享,帮你省下90%的试错时间!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
这篇论文探讨了一个非常实际的问题:顶尖的自动驾驶模型,换个地方还灵不灵?🤨 它没有提出炫酷的新算法,而是用扎实的实验,对比了四种让模型“入乡随俗”的策略,找到了一个简单又高效的“最优解”。对于任何想把AI模型部署到新场景的工程师和研究者来说,这篇论文的结论都极具参考价值,堪称一份实用的“模型迁移操作指南”。
原论文信息如下:
论文标题:
COTTA: COntext-aware Transfer adaptation for Trajectory prediction in Autonomous driving
发表日期:
2026年04月
发表单位:
梨花女子大学,首尔大学,尚明大学,OUTTA,NVIDIA
原文链接:
https://arxiv.org/pdf/2604.00402v1.pdf
想象一下,你把一个在美国考了驾照、开惯了宽阔大道的老司机,突然空降到首尔傍晚的市中心。面对密密麻麻的车流、突如其来的加塞和复杂的环形路口,他大概率会手忙脚乱,怀疑人生。
今天的自动驾驶预测模型,就面临着类似的困境。那些在Waymo、Argoverse等美国数据集上拿高分的“学霸模型”,到了亚洲尤其是韩国这种高密度、高互动性的交通环境里,预测精度往往会“断崖式”下跌。
来自梨花女子大学、首尔大学和NVIDIA的研究团队最近就盯上了这个问题。他们没有去发明一个更花里胡哨的新模型,而是做了一件更“工程师”的事情:拿起一把“手术刀”,对现有的一个顶尖模型——QCNet(Query-Centric Trajectory Prediction,查询中心轨迹预测)——进行了四种不同的“适应性改造”实验。
结果发现,其中一种看似简单的策略,效果出奇的好,能让模型在韩国数据上的预测错误率暴降超过66%。这到底是什么神奇的“手术”?背后又有什么道理?今天龙哥就带你盘一盘这篇名为《COTTA》的论文。
域差距:西方模型在亚洲“水土不服”?
在自动驾驶领域,轨迹预测是个核心任务。简单说,就是让AI根据周围车辆、行人过去几秒的运动历史,以及高精地图信息,预测他们未来几秒会怎么走。这直接关系到自动驾驶车自己该怎么规划路线,是安全驾驶的基石。
这几年,这个领域的“卷王”是QCNet。它在CVPR 2023上被提出,用了一种“查询中心”的新范式,效率和精度都很高,当年就在Argoverse挑战赛上拿了冠军。你可以把它想象成自动驾驶预测模型里的一个“高考状元”。
但问题来了:这位“状元”是在美国(主要是匹兹堡、迈阿密)的交通数据上训练出来的。它的“知识”和“经验”都源自那里的道路规划、驾驶习惯和交通密度。
而韩国的交通环境是另一番景象:城市更密集,交叉口更复杂,驾驶行为更“aggressive”(论文原词),比如频繁的加塞、近距离变道。这种数据分布上的差异,在机器学习里就叫域差距(Domain Gap)。
域差距直接导致模型“水土不服”。论文引用了一项名为UniTraj的研究,该研究做了跨数据集测试,发现一个模型从一个数据集换到另一个数据集测试,性能可能会下降20-30%。这就好比一个在北京考了满分驾照的司机,直接去重庆开山路,不出问题才怪。
所以,当QCNet这个“美国学霸”直接空降到韩国数据集ETRI Trajectory Dataset (ETD)上做“零样本”测试时,预测精度大幅下滑,几乎是必然的。
那么,怎么解决这个问题?最朴素的想法有两种:1. 让“学霸”在当地从零开始学(从头训练);2. 让“学霸”用当地教材复习一下(全量微调)。但本文的研究者想得更细,他们系统性地对比了四种策略,想找出性价比最高的“本地化”方案。
四招拆解:如何让QCNet适应韩国路况?
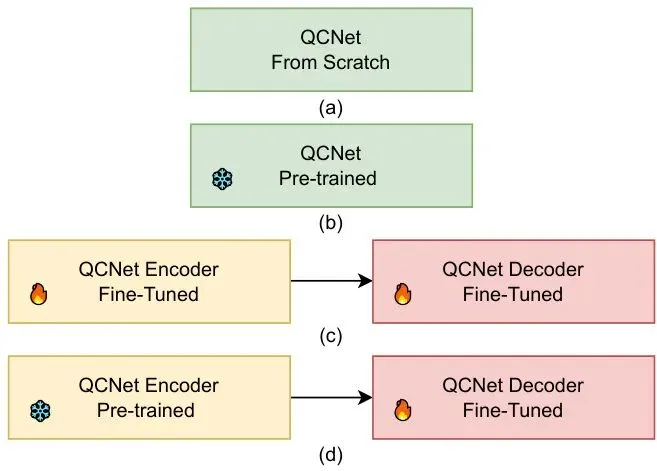 图2:四种从Argoverse 2到ETRI轨迹数据集的迁移学习策略概览:(a) 零样本评估,(b) 从头训练,(c) 全量微调,(d) 编码器冻结微调。
本文的实验设计非常清晰,就像上面图2展示的,一共对比了四种“改造”QCNet的策略:策略一:零样本评估 (Zero-shot)直接把在美国训练好的QCNet模型拿出来,不进行任何额外训练,直接在韩国ETD测试集上跑一遍。这是为了验证“域差距”到底有多大,相当于测量“水土不服”的严重程度。策略二:从头训练 (Scratch Training)把QCNet的网络结构拿过来,但所有的参数都随机初始化,然后只用韩国的ETD训练集来从头训练这个模型。这相当于请一个“空白大脑”的智能体,完全用韩国教材从头学起。策略三:全量微调 (Full Fine-tuning)把在美国预训练好的QCNet模型作为起点,然后允许它的所有参数(包括编码器和解码器)都在韩国ETD训练集上继续学习和调整。这相当于让“美国学霸”用韩国教材进行全面复习和知识点修正。策略四:编码器冻结微调 (Encoder Freezing)这是本文重点考察的策略。它把预训练好的QCNet模型拿来,但“冻住”它的编码器(Encoder)部分(参数不更新),只允许解码器(Decoder)部分在韩国数据上微调。这背后的思想是:编码器负责从复杂的交通场景(车辆历史轨迹、地图)中提取和理解特征,这些底层特征(比如物体的运动趋势、与车道的关系)可能是通用的;而解码器负责根据这些特征生成具体的未来轨迹,这部分需要适配本地具体的驾驶风格。
图2:四种从Argoverse 2到ETRI轨迹数据集的迁移学习策略概览:(a) 零样本评估,(b) 从头训练,(c) 全量微调,(d) 编码器冻结微调。
本文的实验设计非常清晰,就像上面图2展示的,一共对比了四种“改造”QCNet的策略:策略一:零样本评估 (Zero-shot)直接把在美国训练好的QCNet模型拿出来,不进行任何额外训练,直接在韩国ETD测试集上跑一遍。这是为了验证“域差距”到底有多大,相当于测量“水土不服”的严重程度。策略二:从头训练 (Scratch Training)把QCNet的网络结构拿过来,但所有的参数都随机初始化,然后只用韩国的ETD训练集来从头训练这个模型。这相当于请一个“空白大脑”的智能体,完全用韩国教材从头学起。策略三:全量微调 (Full Fine-tuning)把在美国预训练好的QCNet模型作为起点,然后允许它的所有参数(包括编码器和解码器)都在韩国ETD训练集上继续学习和调整。这相当于让“美国学霸”用韩国教材进行全面复习和知识点修正。策略四:编码器冻结微调 (Encoder Freezing)这是本文重点考察的策略。它把预训练好的QCNet模型拿来,但“冻住”它的编码器(Encoder)部分(参数不更新),只允许解码器(Decoder)部分在韩国数据上微调。这背后的思想是:编码器负责从复杂的交通场景(车辆历史轨迹、地图)中提取和理解特征,这些底层特征(比如物体的运动趋势、与车道的关系)可能是通用的;而解码器负责根据这些特征生成具体的未来轨迹,这部分需要适配本地具体的驾驶风格。
*表格超出部分左右可以滑动
| 策略 |
是否利用预训练知识 |
训练成本 |
核心思想 |
| 零样本 |
❌ 不训练 |
无 |
直接测试域差距 |
| 从头训练 |
❌ 抛弃 |
高 |
完全本地化学习 |
| 全量微调 |
✅ 全面利用 |
中高 |
知识迁移与修正 |
| 编码器冻结 |
✅ 选择性利用 |
低 |
通用特征 + 本地解码 |
实验结果:冻结编码器为何成为“最优解”?
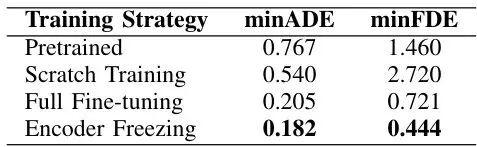
实验结果的答案,直接看下面这个表格就一目了然。评估指标是轨迹预测领域最常用的两个:minADE(最小平均位移误差)和minFDE(最小最终位移误差)。数值越低,说明预测得越准。
简单解释一下:minADE衡量的是整个预测轨迹(比如未来4秒)与真实轨迹的平均偏差;minFDE只关心预测终点与真实终点的偏差。FDE往往更难,因为它需要模型对长期意图有准确的把握。
第一行(零样本):minADE 0.767,minFDE 1.460。这证实了域差距的存在,直接拿美国模型来用,预测误差很大。
第二行(从头训练):minADE降到了0.540,这说明用本地数据学习是有效的。但!minFDE飙升到了2.720,比零样本还差!这意味着模型虽然能学到一些短期的运动规律,但对长期目的地的预测完全跑偏了。原因可能是韩国本地数据量(约2万多个场景)相比大规模预训练数据还是太少,模型“学不透”复杂的长期行为模式。
第三行(全量微调):效果大幅提升!minADE 0.205,minFDE 0.721。这证明了利用预训练知识的巨大价值。预训练模型从海量美国数据中学到的“世界知识”和“推理能力”是宝贵的财富,微调让它在保留这些能力的基础上,快速适应新环境。
第四行(编码器冻结):效果最好!minADE进一步降到0.182,minFDE大幅降至0.444。相比于“从头训练”,minADE降低了66.3%,minFDE降低了惊人的83.7%!
为什么“冻结编码器”这招这么灵?论文给出了精妙的解释:
大规模预训练提供了通用的运动表示先验,而使用韩国数据进行微调使模型能够有效地学习特定领域的驾驶行为和交通模式。
龙哥帮你翻译一下:编码器就像模型的“眼睛”和“理解中枢”,负责看懂交通场景(谁在哪、怎么动、和车道啥关系)。这部分能力是相对通用的——无论是在美国还是韩国,识别车辆、理解基本的运动趋势(加速、减速、转向)的逻辑是相通的。冻结它,就保住了模型从海量数据中学到的这种“基础世界观”。
解码器则像是“决策和生成器”,它根据编码器提供的“理解”,来“画”出未来的轨迹。韩国司机具体怎么加塞、在复杂路口倾向于选择哪条路径、跟车距离有多近……这些“本地习俗”需要解码器来快速学习适应。
“编码器冻结”策略聪明地实现了“保通用,学特色”的完美分工。它不仅效果最好,而且因为只训练解码器,参数更新量小,训练效率更高,更不容易过拟合(毕竟可调的参数少了)。这简直就是为实际工程部署量身定制的方案!
未来展望:如何让模型更“懂”本地交通?
尽管“编码器冻结”策略效果显著,但论文也承认,定性地看,模型在韩国特有的一些复杂场景下依然会犯错。为了让模型彻底“入乡随俗”,作者们指出了几个未来的研究方向:
收集更多样、更高质量的本地数据,覆盖更广的区域和更极端的场景。同时,可以使用数据增强技术,专门模拟韩国那种“高密度互动”和“侵略性变道”等行为,给模型“上难度”。
本文用的是有监督微调,需要带标签的本地数据。未来可以探索无监督域适应(Unsupervised Domain Adaptation, UDA)方法,比如用对抗学习让模型提取的特征分辨不出是来自美国还是韩国,从而直接减少源域和目标域之间的分布差异。这尤其适合本地标注数据稀缺的情况。
终极目标是训练一个“全球通”模型。可以研究多域学习(Multi-Domain Learning),让一个模型同时学习美国、韩国、中国、欧洲等不同地区的驾驶数据,通过一些技术(如混合专家网络)让模型既能保持全球通用性,又能针对特定地区进行微调,实现“一套模型,全球部署”的梦想。
龙迷三问
这篇论文主要解决了什么问题?本文没有提出一个新的预测模型,而是解决一个非常实际的工程问题:如何将一个在欧美数据上训练出的顶尖自动驾驶轨迹预测模型(QCNet),高效且有效地适配到驾驶环境截然不同的新地区(如韩国)。它通过系统性的实验,找到了一个简单高效的迁移学习策略。
QCNet是什么?QCNet是CVPR 2023上提出的一种基于“查询(Query)”的轨迹预测模型。它创新性地用一组可学习的查询(Queries)来同时建模智能体(车、人)之间的交互以及智能体与地图的交互,从而在保持高效率的同时取得了很高的预测精度,曾是Argoverse预测榜单的冠军模型。
minADE和minFDE这两个指标具体是什么意思?它们是评估轨迹预测精度的核心指标。minADE (Minimum Average Displacement Error):模型会预测K条可能的未来轨迹,取其中与真实轨迹在所有时间点上平均距离最小的那条,计算其平均误差。它衡量整体轨迹的准确性。minFDE (Minimum Final Displacement Error):同样取K条预测轨迹中终点误差最小的那条,计算其终点误差。它更考验模型对长期目的地的预测能力。两个值都是越低越好。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★☆☆
本文的核心贡献不在于算法创新,而在于通过扎实、系统的对照实验,验证并量化了一个在工程直觉上可能成立,但缺乏实证的策略(冻结编码器微调)。这是一种务实的、面向工程落地的研究风格。实验合理度:★★★★☆
实验设计清晰,对比了四种合理且具有代表性的迁移学习策略。使用公开的预训练模型和标准的评估指标,结果具有可比性和说服力。唯一美中不足的是只在QCNet这一个模型和一个目标域(韩国)上进行了验证,结论的普适性有待更多实验支撑。学术研究价值:★★★★★
价值非常高!它为“如何将SOTA模型有效迁移到新领域”这一极具现实意义的问题提供了清晰的实验范式和强有力的实证结论。论文中关于“编码器学通用特征,解码器学领域特性”的洞见,对迁移学习、领域自适应乃至模型压缩等方向都有启发。稳定性:★★★☆☆
实验表明该方法在特定迁移任务(美->韩)上效果稳定且显著。但模型的整体稳定性(如面对极端天气、传感器噪声等)依赖于其Backbone模型QCNet本身,本文未做相关测试。适应性以及泛化能力:★★★☆☆
本文验证的是“有监督的领域适应”,高度依赖目标域的标注数据。如果换一个完全没有标注的新地区,该方法无法直接应用。其泛化能力主要体现在方法思路(冻结编码器)上,而非模型本身。硬件需求及成本:★★★★☆
QCNet本身是一个高效的模型。所提出的“编码器冻结”微调策略,由于只更新部分参数,所需的计算资源和训练时间远低于“从头训练”和“全量微调”,部署成本低,非常适合工程实践。复现难度:★★★★☆
难度较低。QCNet是公开工作,其代码和预训练模型权重大概率已开源。ETRI数据集也是公开的挑战赛数据。实验步骤和超参数在论文中描述清晰,具备良好的可复现性。产品化成熟度:★★★★☆
成熟度较高。该策略逻辑简单,效果显著,训练和部署成本可控,可直接作为自动驾驶公司进行模型区域化适配的标准流程之一。前提是目标地区有足够的标注数据进行监督微调。可能的问题:本文的实验范围相对聚焦(单一模型、单一目标域)。“冻结编码器”策略的有效性可能依赖于编码器所学特征的“通用性”程度,对于架构差异巨大的模型或域差距特别大的场景,需要重新评估。此外,未考虑目标域无标签的更严峻情况。
[1] Zhou et al., “Query-centric trajectory prediction,” CVPR 2023.[2] Feng et al., “Unitraj: A unified framework for scalable vehicle trajectory prediction,” ECCV 2024.[3] Wilson et al., “Argoverse 2: Next generation datasets for self-driving perception and forecasting,” arXiv:2301.00493.[4] ETRI Trajectory Dataset and Prediction Challenge 2025.*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

想让你的AI模型也学会“入乡随俗”,快速适配新场景吗?🚗 加入龙哥读论文粉丝群,和自动驾驶、机器人领域的小伙伴一起交流模型迁移、域适应的实战经验!
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 自动驾驶+北京+清华+龙哥),根据格式备注,可更快被通过且邀请进群。


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
