关键词:#自动驾驶 #VLA
- 论文题目:The Blind Spot of Adaptation: Quantifying and Mitigating Forgetting in Fine-tuned Driving Models
- https://github.com/AutoLab-SAI-SJTU/FidelityDrivingBench

TL;DR:
本文首次揭示并量化了视觉-语言模型(VLM)在自动驾驶微调过程中的灾难性遗忘现象,提出通过"提示空间路由"(Prompt Space Routing)而非"权重空间修改"来解耦领域适应与知识保留,实现了在提升驾驶任务性能的同时,将世界知识保留率从 68.4% 提升至 79.0%。
Abstract 翻译:
将视觉语言模型(VLMs)整合到自动驾驶领域,有望解决长尾场景问题,但这一范式面临着灾难性遗忘这一关键且尚未解决的挑战。正是通过微调过程使这些模型适应驾驶专用数据的同时,也侵蚀了其宝贵的预训练世界知识,形成了一种自相矛盾的困境,削弱了其应用的核心价值。本文首次对这一现象进行了系统性研究。我们引入了一个包含 18 万个场景的大规模新数据集,首次构建了专门用于量化自动驾驶中灾难性遗忘的基准测试。我们的分析表明,现有方法存在显著的知识退化问题。为解决这一问题,我们提出了驾驶专家适配器(DEA),这是一种新颖的框架,通过将适应过程从权重空间转移到提示空间来规避这一权衡。DEA 根据场景特定线索动态引导推理过程通过不同的知识专家,从而在不破坏模型基础参数的前提下提升驾驶任务性能。 大量实验表明,我们的方法不仅在驾驶任务上取得了最先进的成果,而且有效缓解了灾难性遗忘问题,保留了使视觉语言模型成为自动驾驶系统变革性力量的关键泛化能力。数据和模型已在 FidelityDrivingBench 平台发布。一、研究背景与动机
研究背景
当前自动驾驶正经历从模块化流水线向端到端系统的范式转移,而VLM-centric方法(如 DriveLM、RecogDrive 等)被视为解决长尾场景的关键路径——利用语言作为中间表示,统一感知、推理与决策。然而,通用 VLM 与真实驾驶场景之间存在显著领域鸿沟(domain gap),因此必须对模型进行驾驶数据的微调(fine-tuning)。
核心动机
作者敏锐地捕捉到一个被业界严重忽视的安全关键悖论:微调过程在赋予模型驾驶专业能力的同时,会灾难性地侵蚀其预训练获得的世界知识(如识别路沿、岩石、动物等通用物体能力)。这种"适应即遗忘"的自我矛盾使得 VLM 失去处理未知长尾场景的核心优势。更严峻的是,现有基准测试(如 DriveLM、NuScenes-QA)因训练/测试分布高度重叠,无法检测这种知识退化,导致系统在真实开放环境中存在"看不见障碍物"的安全隐患(如图 2 所示,微调后的 RecogDrive 忽略了基础模型原本能识别的路沿和岩石)。
二、研究内容
本文构建了首个系统性研究自动驾驶VLM灾难性遗忘的完整框架,包含:
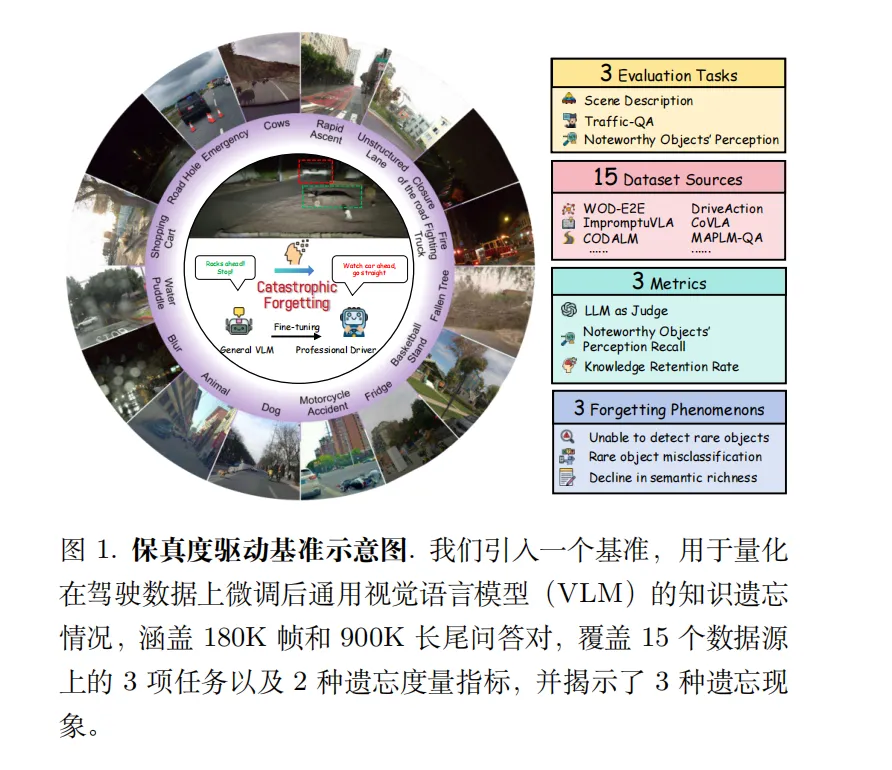
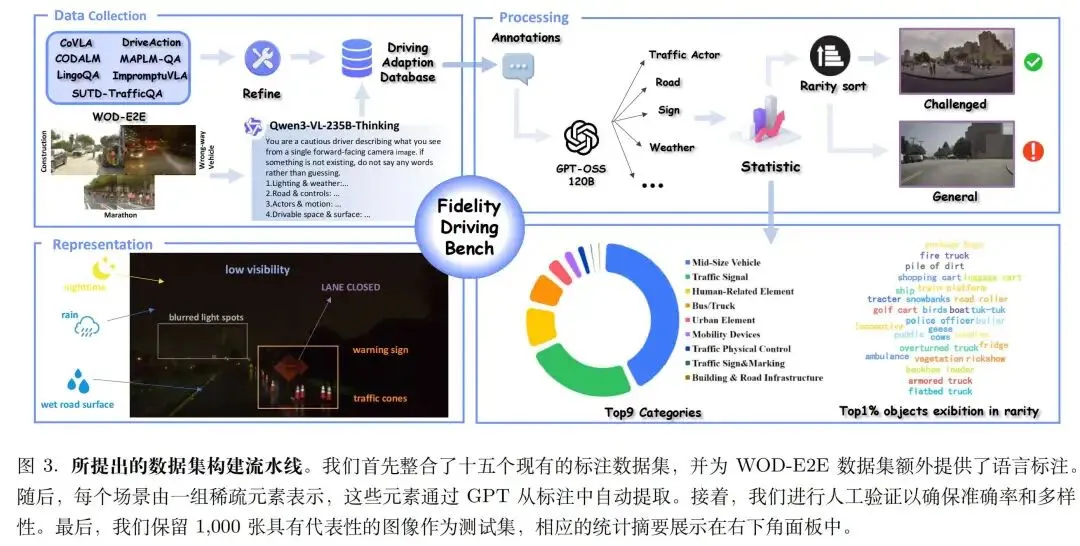
- Fidelity Driving Bench:包含 18 万帧图像、90 万 QA 对、覆盖 15 个数据源的评估基准,其中通过 IDF(逆文档频率) rarity score 算法挖掘出 1,000 个真实长尾场景作为遗忘检测试集。
- Drive Expert Adapter(DEA):一种即插即用的适配框架,将知识适应从传统的"权重修改"转向"提示工程"。
2.1 Fidelity Driving Bench 评测基准
这是第一个专门测 “自动驾驶模型失忆” 的基准。
2.2 基准测出的真相
2.3 论文的解决方案:Drive Expert Adapter(DEA)
一句话:不修改模型权重,只在 “提示词 + 专家路由” 层面做适配,既变强又不忘本。
DEA 由两个轻量模块组成:
Prompt Adapter(提示适配器)
学习可训练的提示嵌入(learnable prompt tokens),根据输入问题的语义动态检索并前置最相关的任务先验,全程不修改 VLM 骨干参数,从根本上避免参数覆写导致的遗忘。
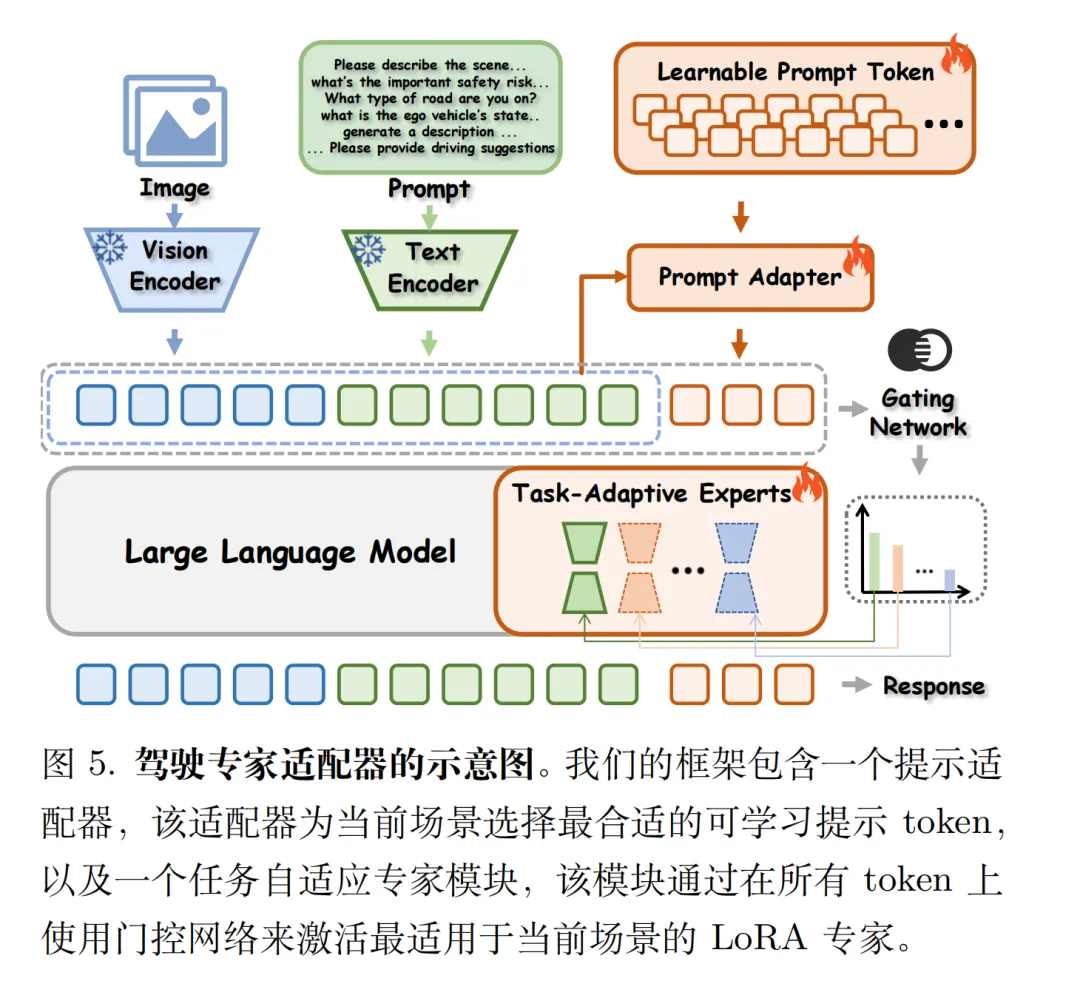
Task-Adaptive Expert Module(TAEM,任务自适应专家)
采用 Mixture-of-Experts(MoE)架构,由门控网络根据场景线索(如能见度、交通密度)和提示语义,动态路由至 specialized LoRA 专家(如城市拥堵专家、恶劣天气专家),解决单一 LoRA 无法适应复杂长尾场景的局限。
- 多个专家分别负责:拥堵、高速、恶劣天气、施工等场景
组合效果
- **知识保留率 KRR 高达 79%**,远优于普通微调
通过"提示空间专家路由",在Qwen2.5VL-3B上实现了79.0%的知识保留率(相比ImpromptuVLA的68.4%),同时在场景描述(+2.2%)和交通QA(+3.6%)任务上超越基线,首次打破了"适应-保留"的零和博弈。
三、实验
在 Qwen2.5VL-3B 上对比:
一句话:DEA 打破了 “要性能就得忘知识” 的死循环。
四、总结
理论层面:
- 问题揭示:首次将"灾难性遗忘"这一持续学习领域的核心问题引入自动驾驶VLM研究,填补了该范式下的关键理论盲点。
- 范式转换:证明了知识适应不必以牺牲基础参数为代价,为"参数高效微调(PEFT)"提供了新的认知边界——不仅冻结骨干网络,更要通过动态知识路由实现功能扩展。
实践层面:
- 安全关键应用:为自动驾驶系统的安全验证提供了新维度(Knowledge Retention Rate),推动行业从"基准测试高分"向"开放环境鲁棒性"转变。
- 资源效率:DEA作为轻量级插件,使得在边缘计算设备上部署具备强泛化能力的大模型成为可能,避免了全参数微调的巨大计算开销。
启发价值: 该研究提示了整个VLM应用领域的共性挑战:任何垂直领域(医疗、法律、工业)在利用基础模型时,都必须警惕"微调即遗忘"的风险,并探索非破坏性的领域适应路径。

