自动驾驶前决策算法之POMDP入门必备知识
- 2026-04-17 23:10:47
自动驾驶中POMDP应用分类
按不确定性建模来源分类(辅助分类,对应自动驾驶核心不确定性)
- 感知不确定性导向 POMDP
:核心建模传感器噪声、遮挡、误检漏检、恶劣天气感知降级带来的观测不确定性,通过信念更新修正感知误差,适配复杂遮挡、雨雪雾等低能见度场景。 - 交互不确定性导向 POMDP(实际应用最多)
:核心建模其他交通参与者的意图、驾驶风格、决策逻辑的隐状态不确定性,聚焦多智能体博弈推理,适配城市路口、人车混行等强交互场景。 - 动力学 / 环境不确定性导向 POMDP
:核心建模自车动力学误差、路面附着系数、坡度、侧风等环境不确定性,保证轨迹跟踪的鲁棒性,适配湿滑路面、高速过弯、坡道行驶等场景。
按工程落地的求解架构 / 近似方法分类
POMDP 的核心落地瓶颈是 “维度灾难” 与实时性,这一分类是业界针对车载算力约束,对 POMDP 进行工程化近似求解的主流实现形式。
- 高斯信念 POMDP(Belief MPC)
最基础的落地形式,将 POMDP 转化为信念空间的等价 MDP,假设信念状态服从高斯分布,通过卡尔曼滤波类方法完成信念更新,计算开销最低,可直接与模型预测控制(MPC)框架融合。适用场景:高速巡航、直道跟车等弱交互、单模态不确定性场景,缺点是无法处理多模态意图分布。 - QMDP 近似 POMDP
工业界量产落地最广泛的方案,通过忽略未来观测对信念更新的影响,仅基于当前信念求解 MDP 的最优价值函数,将计算复杂度降低至与 MDP 同量级,可通过矢量化并行实现车载 CPU 毫秒级实时求解。代表方案:Vec-QMDP,在 nuPlan 基准上实现 9ms 级规划延迟,可支撑万级场景的并行求解(9ms刷新NuPlan SOTA!上交&理想最新Vec-QMDP)。适用场景:城市道路、高速合流、路口通行等中等交互场景,兼顾实时性、安全性与通行效率。 - 多场景 / 场景树 POMDP
将连续信念空间离散化为有限的带权重场景分支,构建场景树进行滚动优化,天然与预测模块的多模态意图输出对接,可灵活处理多智能体的多意图不确定性。适用场景:路口多车交互、加塞应对、无保护左转等多意图博弈场景,是当前量产车中处理交互场景的主流方案,核心挑战是场景数量爆炸,需配套高效剪枝策略。 - 基于采样的 POMDP(POMCP/DESPOT)
基于蒙特卡洛树搜索(MCTS)对信念空间进行采样,通过有限的信念点近似完整高维信念空间,可处理非高斯、多模态的复杂不确定性,决策性能最优。适用场景:人车混行、复杂环岛、盲区通行等高不确定性、强交互场景,缺点是算力开销高,需高性能车载硬件支撑。 - 鲁棒 POMDP(信念鲁棒 MPC)
针对安全关键场景设计,不建模完整概率分布,仅考虑信念的支撑集(最坏情况),保证所有可能的真实状态下安全约束都能满足,极致优先安全性。适用场景:紧急避撞、恶劣天气感知降级、盲区通行等安全临界场景,会牺牲部分通行效率换取绝对安全。
自动驾驶POMDP行为决策核心知识体系
POMDP的核心价值,就是解决自动驾驶场景中「部分可观测性」与「多源不确定性」带来的决策鲁棒性问题,这也是规则式决策、确定性MDP决策在复杂城市场景中频繁失效的核心原因。
下面从「底层核心定义→自动驾驶场景专属建模→核心求解算法→工程落地关键技术→避坑指南」补全落地所需的核心知识。
一、先搞透核心底层:POMDP vs MDP
1. 本质区别:解决「部分可观测」的核心痛点
自动驾驶的真实场景,永远不存在「完全可观测的状态」:
传感器固有缺陷:噪声、误检/漏检、测距误差; 环境固有遮挡:路口盲区、大车遮挡、建筑遮挡带来的不可见目标; 交通参与者隐性状态不可知:其他交通参与者的驾驶意图、性格、未来动作,永远无法直接观测。
确定性MDP假设「系统全部状态完全可观测」,只能处理预设场景,面对上述不确定性时,只能基于「最可能的状态」做决策,极易出现极端场景失效(比如盲区有车却按无车决策);而POMDP(部分可观测马尔可夫决策过程),正是把「不确定性」本身纳入决策建模,基于对所有可能状态的概率分布做决策,从根源上提升决策的鲁棒性。
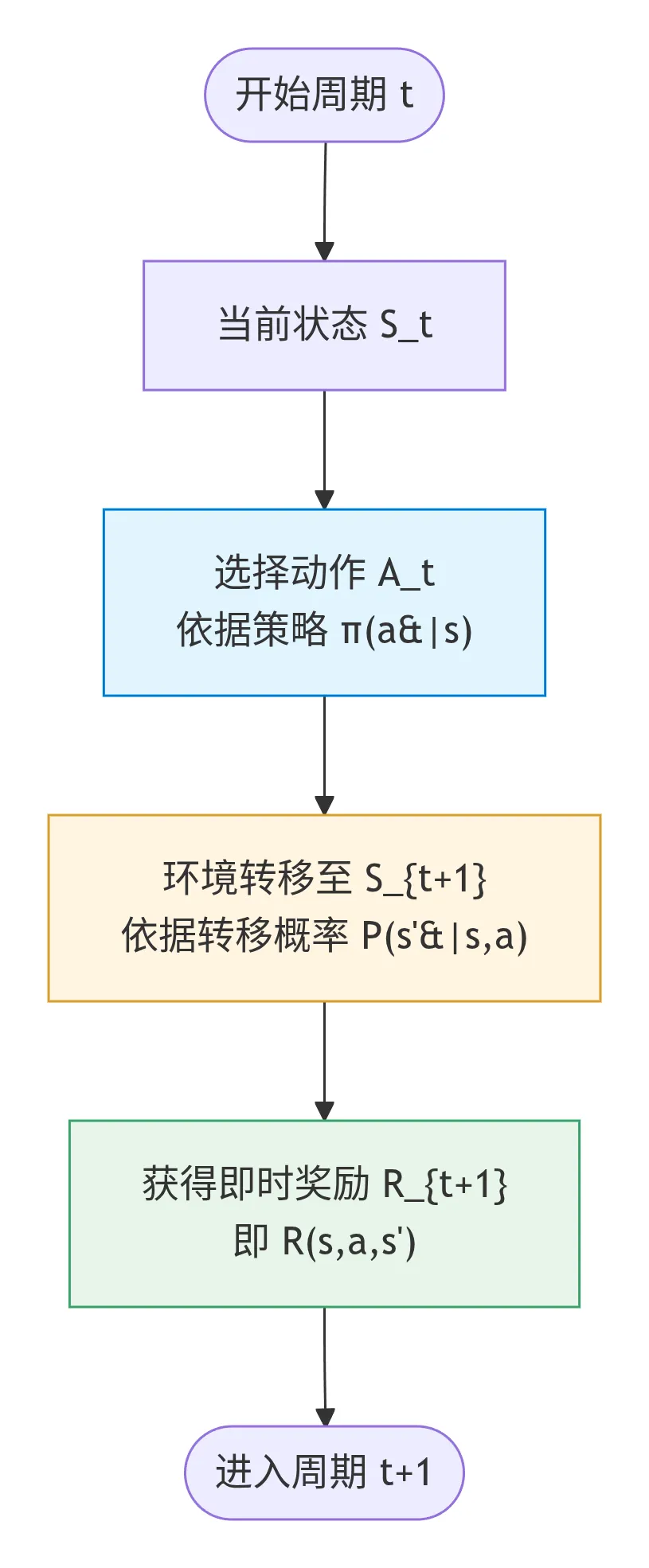
MDP (Markov Decision Process) - 马尔可夫决策过程:
- 完全可观测
智能体能准确知道当前状态 - 五元组⟨S, A, T, R, γ⟩
S: 状态空间 A: 动作空间 T(s'|s,a): 状态转移概率 R(s,a): 奖励函数 γ: 折扣因子
2. POMDP标准七元组数学定义
POMDP的标准形式为七元组 ,
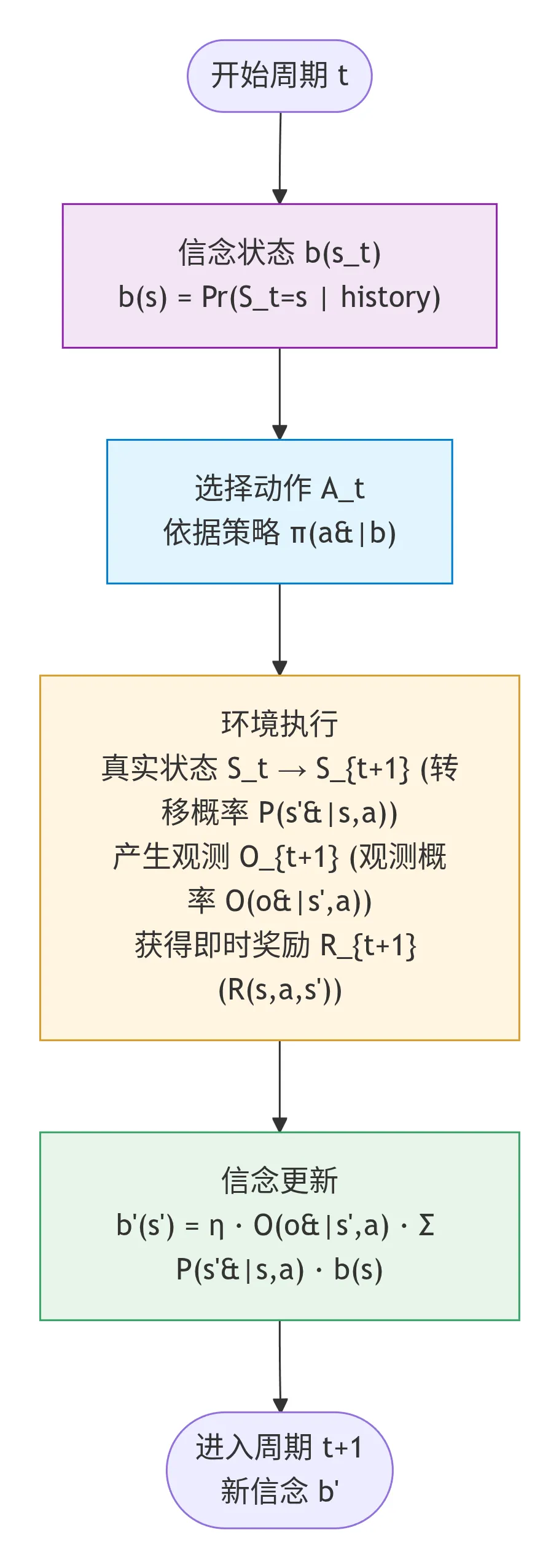
*信念b(s)是一个高维空间的联合分布函数,高维空间维度取决于状态S的维度,相当于隐空间的前身“显空间”,每个维度有具体物理含义、强制要求联合概率。
每个元素在自动驾驶中的对应关系:
| ||
在环境进入真实状态s′、智能体执行动作a后,智能体获得观测o的条件概率 | 刻画感知系统的不确定性(噪声、遮挡、有限视场等),≈ 感知系统的“误差模型” | |
涉及全局视角和智能体视角的算法初学都比较难理解,因为相关理论为了保证客观性、会陈述整个过程,描述过程包含了全局视角与智能体视角的无缝切换叙述,导致理解困难,下面时序逻辑单设智能体视角以辅助理解:
我(智能体)永远、绝对、不可能知道环境的"真实状态s"是什么。我的整个世界里只有三样东西:
我对世界的概率估计 → 信念b 我自己主动做出的动作 → 动作a 我的传感器返回给我的读数 → 观测o
所有理论里提到的"真实状态s"、"状态转移函数P",都只是研究者用来描述的数学工具,我的代码里永远不会出现"真实状态"这个变量。
纯智能体视角的5步循环
与全局视角的关键对比
**不要纠结"真实状态"**:写POMDP代码时不需要处理真实状态,它只在仿真器里用来生成观测。
b_{t+1}(s') = η * O(o_{t+1}|s',a_t) * [ Σ_s P(s'|s,a_t) * b_t(s) ]方括号里的部分:预测步(只用到P和旧信念b_t) 方括号外的部分:更新步(只用到观测模型O和新观测o_{t+1}) η:归一化常数,保证所有概率加起来等于1
状态转移概率P,只在第一步"预测步"中起作用,和第二步"更新步"完全无关。
用智能体第一人称解释这两步
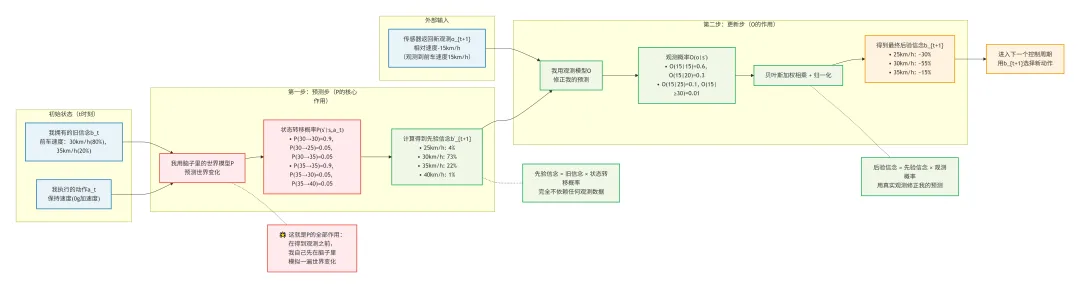
第一步:预测步(我自己脑子里先猜一遍)
我刚才做了动作a_t。虽然我还不知道世界真实变成了什么样,但我可以用我脑子里的世界模型P,来预测一下:
基于我上一轮对世界的所有认知b_t(s),再考虑到我刚才做了动作a_t,那么现在世界处于状态s'的概率有多大?
这个预测出来的中间结果,我叫它**先验信念b'_{t+1}(s')**。
这就是P的全部作用:它是我用来预测"我的动作会如何改变世界"的工具。
第二步:更新步(用新观测修正我的猜测)
现在我的传感器给了我一个新观测o_{t+1}。我把我刚才预测的b'{t+1}(s'),和观测模型O结合起来,看看哪个状态s'最有可能产生这个观测o{t+1}。
然后我把预测和观测加权平均,得到最终的后验信念b_{t+1}(s')。
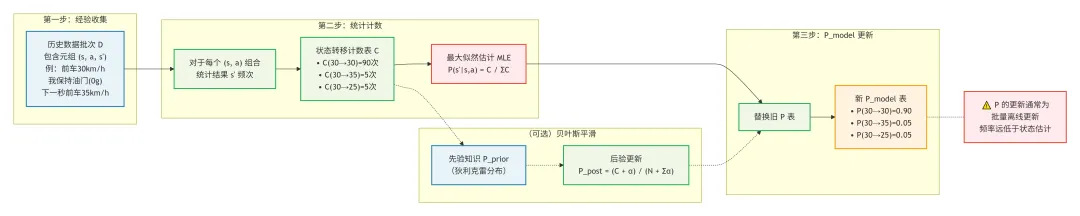
从智能体的角度看,P不是环境的"真实"转移规律,而是智能体自己"相信"的转移规律。
全局视角说:"环境按照真实的P(s'|s,a)转移" 智能体视角说:"我按照我脑子里的P_model(s'|s,a)来预测世界"
这两个P可能完全不一样!
如果我的P_model和真实的P很接近,那么我的预测就会很准,信念更新也会很稳定 如果我的P_model和真实的P差很多,那么我的预测就会经常和观测矛盾,我的信念就会剧烈波动
这就是为什么在实际的POMDP算法中,状态转移模型P通常是需要学习的,而不是预先给定的。智能体在和环境交互的过程中,会不断更新自己的P_model,让它越来越接近真实的环境规律。
2. 动作是我自己做的:我肯定知道自己刚才做了什么动作,所以a_t是确定已知的。
3. POMDP的核心基石:信念状态(Belief State)
因为状态部分可观测,我们无法获取真实状态,只能基于历史观测和动作,对真实状态的概率分布进行估计,这个概率分布就是**信念状态 **,满足 。
这是POMDP和MDP最核心的区别:
MDP的策略是「状态→动作」的映射 ; POMDP的策略是「信念状态→动作」的映射 ,所有的求解、决策,都基于信念状态展开。
核心能力:信念更新(贝叶斯更新)
每执行一个动作、获得一个新的观测后,就可以通过贝叶斯公式更新信念,得到下一时刻的信念:
其中 是归一化因子,保证信念的概率和为1。
工程化解读:
比如过路口时,初始信念中「盲区有车」的概率是20%,当车辆向前行驶,盲区范围缩小,传感器仍未观测到目标,信念更新后「盲区有车」的概率会下降到5%,决策会从「减速等待」切换为「缓慢通行」; 再比如前车刹车,初始信念中「前车要停车」的概率是30%,随着前车持续减速,观测到刹车灯亮起,信念更新后该概率上升到90%,决策会从「跟车减速」切换为「停车避让」。
二、自动驾驶POMDP核心求解算法
POMDP求解的核心难点在于信念空间是连续、高维的,存在维度灾难,传统的精确求解算法(值迭代、策略迭代、Witness算法)仅适用于小规模离散状态空间,无法适配自动驾驶场景,下面只讲适配自动驾驶实时性要求的近似求解算法。
<1>. 有限时域滚动优化(RHC)+ POMDP(POMDP-MPC)
核心原理
放弃无限时域的全局最优求解,采用滚动时域优化(Receding Horizon Control, RHC):
每一个决策周期,基于当前的信念状态,规划未来步的有限时域(一般,对应500ms~1s的决策时域,匹配自动驾驶的动态场景特性); 在有限时域内,求解最优的动作序列; 仅执行第一个动作,下一个决策周期,基于新的观测更新信念,重新规划时域内的动作序列,以此循环。
工程优势
实时性可控:有限时域内的求解复杂度大幅降低,可适配自动驾驶100ms以内的决策周期要求; 鲁棒性强:每一步都基于最新的观测更新信念,修正之前的状态估计误差,避免长期预测的不确定性累积; 易落地:可无缝对接下层的MPC轨迹规划模块,形成「决策-规划」一体化的不确定性处理框架。
落地适配要点
时域长度的选择:高速场景可稍大(8~10步),城市场景需更小(5~6步),避免复杂交互带来的求解爆炸; 动作剪枝:每一步规划前,先剔除安全上不可行的动作(比如碰撞风险超阈值、逆行、驶出车道),大幅降低求解复杂度; 终端成本设计:有限时域的最后一步,需要设计终端成本函数,近似无限时域的远期价值,避免短视决策。
<2>. POMCP(部分可观测蒙特卡洛规划)
POMCP是MCTS(蒙特卡洛树搜索)在POMDP场景的适配,适配复杂城市场景(无保护左转、环岛、人车混行)。
核心原理
通过蒙特卡洛随机采样,在信念空间中构建搜索树,在线估计每个动作的价值,无需离线训练,泛化性极强。搜索树包含两类节点:
信念节点:代表当前的信念状态; 动作节点:代表在信念下执行的动作。
核心执行分为4步,循环迭代直到达到决策周期的时间上限:
选择:从根节点(当前信念)出发,按UCB公式选择最优的子节点,平衡探索与利用; 扩展:到达未访问的节点时,扩展新的动作/信念节点; 模拟(Rollout):从当前节点出发,用启发式策略模拟未来步的状态转移和观测,获得累计奖励; 回溯:将模拟得到的奖励回溯到根节点,更新每个节点的价值估计。
迭代结束后,选择根节点下价值最高的动作执行。
自动驾驶工程化核心适配要点
POMCP的4个核心问题:
信念状态的粒子滤波表示:高维连续的信念状态,无法用解析形式表示,工程中主流采用粒子滤波(Particle Filter) 来近似信念: 每个粒子代表一个可能的真实状态,粒子的权重代表该状态的概率; 信念更新等价于粒子的权重更新与重采样,完美适配贝叶斯更新逻辑; 粒子数量选择:平衡精度与速度,城市场景500~2000个粒子,高速场景300~1000个粒子即可。 Rollout策略的设计:不能用随机策略模拟,必须用符合人类驾驶习惯的启发式策略,否则模拟结果完全无效,收敛速度极慢: 自车Rollout:用规则式安全策略(比如IDM跟车、安全停车); 其他参与者Rollout:用IDM+MOBIL模型拟合车辆行为,用社会力模型拟合行人行为,或用基于数据训练的行为预测模型。 实时性优化: 限制搜索深度:一般5~8步,匹配有限时域的要求; 并行采样:GPU/多核CPU并行执行蒙特卡洛模拟,大幅提升迭代次数; 树复用:当前决策周期的搜索树,可复用部分子节点到下一个周期,避免重复计算。 安全约束嵌入:在选择和扩展阶段,剔除违反安全硬约束的动作,无需进入模拟阶段,既降低计算量,又保证决策的绝对安全。
进阶改进:DESPOT算法
DESPOT是POMCP的核心改进版,解决了POMCP在高不确定性场景下收敛慢、采样效率低的问题,通过正则化和稀疏采样,聚焦于信念空间中高概率的场景分支,特别适配自动驾驶高遮挡、高交互的场景(比如无保护左转、鬼探头场景),落地时可直接基于DESPOT做二次开发。
<3>. 前沿方向:基于深度学习的POMDP求解
深度学习主要用于解决POMDP高维状态/观测空间的维度灾难问题,工程中不建议直接用端到端深度学习POMDP(可解释性差、安全性无法保证),优先采用「传统POMDP框架+深度学习模块」的半端到端方案,主流方向如下:
信念状态的深度学习编码: 用LSTM/Transformer编码历史观测-动作序列,用隐状态近似信念状态,代表算法DRQN(深度循环Q网络),解决长时序观测的信念建模问题; 用变分自编码器(VAE)将高维信念分布编码到低维隐空间,大幅降低求解复杂度,适配高维观测输入(比如摄像头原始图像)。 模型拟合:用深度学习拟合转移函数、观测函数、奖励函数,替代传统的手工建模,提升复杂交互场景下的模型精度。 策略求解:用PPO、SAC等稳定的深度强化学习算法,直接拟合POMDP的策略,结合安全约束(比如CMDP)保证决策安全性,适合海量数据训练的场景。
三、工程落地的核心关键技术:解决理论到落地的核心Gap
1. 维度灾难的核心解决方案:状态空间降维与分层POMDP
POMDP的计算复杂度随状态维度指数级上升,自动驾驶原生状态空间维度极高,不做降维,再好的求解器也跑不起来。
核心降维手段
状态解耦与无关状态过滤: 静态环境状态:高精地图信息提前预处理,仅保留自车周边50~100米内的局部地图信息,无需纳入实时状态更新; 动态目标过滤:仅保留自车周边关键区域内的目标(前方150米、侧方50米内),无关目标直接剔除,不纳入状态空间; 状态维度精简:仅保留对决策有核心影响的状态量,比如自车状态仅保留速度、位置、所在车道,剔除对决策无影响的次要维度。 隐性状态离散化:将其他参与者的连续意图、性格,离散为有限的类别(比如意图分为:保持车道、左变道、右变道、减速停车、加速),将连续的隐性状态转为离散类别,维度降低2个数量级以上。 分层POMDP(HM-POMDP):这是行业内的标准落地架构,将决策分为两层,彻底解决维度灾难: 高层POMDP:行为级决策,时域长(1~3s),动作空间极小(比如仅决策「是否变道、是否左转、是否停车」),处理长期不确定性与导航目标; 低层POMDP/MPC:动作执行级,时域短(0.5s以内),处理连续动作控制与短期安全约束,仅需关注高层决策对应的局部状态空间。
2. 信念状态的工程化实现
信念状态的精度,直接决定决策的正确性,工程中只有两种主流实现方案:
粒子滤波(首选): 适配场景:城市场景、高非线性、高不确定性场景; 核心优化点:解决粒子退化问题(采用重采样+正则化)、解决粒子多样性丧失问题(加入马尔可夫链蒙特卡洛MCMC采样)、误检/漏检场景下的粒子新增与删除逻辑。 高斯混合模型(GMM): 适配场景:高速跟车等低非线性、高斯噪声主导的场景; 优势:计算速度远快于粒子滤波,信念更新有解析解,无需采样; 劣势:无法适配强非线性、多模态的信念分布(比如盲区有车/无车的二模态分布)。
3. 奖励函数的设计与调优
奖励函数设计的核心原则:安全优先、合规次之、舒适与效率平衡,绝对不能本末倒置。
工程化设计规范
硬约束与软惩罚分离: 安全硬约束:碰撞、逆行、驶出可行驶区域,直接给负无穷奖励,或在动作剪枝阶段直接剔除,绝对不允许进入求解环节; 软惩罚/奖励:合规、舒适、效率类目标,采用加权求和的方式,权重必须满足:安全权重 > 合规权重 > 舒适权重 > 效率权重。 避免稀疏奖励:自动驾驶中碰撞、到达目的地等都是稀疏奖励,极易导致算法收敛困难,必须设计稠密的中间奖励(比如跟车距离符合安全区间的持续奖励、接近导航目标的奖励)。
四、避坑指南:行业内踩过的90%的坑,提前规避
不要盲目追求复杂模型:落地初期,不要直接上深度学习端到端POMDP,先从「分层POMDP+POMCP/有限时域RHC」入手,先在简单高速跟车/变道场景跑通,再扩展到复杂城市场景,否则会卡在维度灾难、实时性、可解释性上无法推进。 不要忽略观测模型的精度:大部分POMDP决策失效,都不是求解器的问题,而是观测模型建模错误。传感器的噪声、误检漏检、遮挡特性,必须基于实车传感器数据标定,不能用理想的高斯模型敷衍,否则信念更新会完全偏离真实状态,决策必然失效。 不要把所有不确定性都塞进POMDP:只把对决策有核心影响的不确定性纳入状态空间(比如其他参与者的意图、遮挡区域的潜在目标),对于小的不确定性(比如厘米级的定位误差、微小的速度测量误差),用下层的鲁棒轨迹规划/控制处理,否则状态维度会爆炸,完全无法实时求解。 不要用无限时域求解算法:自动驾驶是动态滚动决策场景,无限时域算法在线计算量极大,且远期状态的预测完全没有意义,有限时域滚动优化是唯一的工程可行方案。 不要放弃可解释性:车规级自动驾驶的决策必须可解释,POMDP的优势就是可解释性(比如「因为对向来车不让行的概率≥30%,所以选择停车等待」)。
五、POMDP在自动驾驶行为决策中的适用场景
POMDP的核心能力是处理「部分可观测性」和「多源不确定性」,其适用场景完全围绕这一核心能力展开,明确边界才能精准选择落地场景。
1. 高适配场景
这类场景的共性是存在强部分可观测性、高不确定性、强交互性,规则式决策、确定性MDP决策极易出现鲁棒性问题,是POMDP的核心落地区域。
路口盲区/遮挡场景:包括路口大车遮挡、建筑盲区、匝道合流盲区、隧道出入口遮挡等核心corner case。POMDP可通过信念状态建模「盲区存在潜在交通参与者」的概率分布,基于概率做保守但不僵化的决策(比如渐进式通行、动态减速等待),既避免规则式决策「要么冲、要么停」的极端行为,也解决确定性MDP按「无车」决策带来的碰撞风险,是目前行业内处理盲区场景的最优方案之一。 无保护左转/环岛/人车混行高交互场景:这类场景需要和对向车流、横穿行人、多方向汇入车辆进行强博弈,核心不确定性来自其他交通参与者的隐性驾驶意图(让行/抢行、横穿/等待)。POMDP可将意图作为隐性状态纳入信念更新,基于多轮观测持续修正「对方让行概率」的估计,动态调整决策(比如从缓慢试探到正常通行、从准备通行到停车让行),相比规则式决策的固定阈值,泛化性和通行效率大幅提升,是L4城市场景行为决策的主流方案。 鬼探头/弱势交通参与者突发场景:针对行人/非机动车从遮挡物中突然冲出的高频危险场景,POMDP可提前建模「遮挡区域存在潜在横穿目标」的信念分布,在观测到目标之前就提前做好决策预案(比如收油、备刹、预留避让空间),相比规则式决策「必须观测到目标才触发制动」,能大幅缩短制动响应时间,降低事故风险。 恶劣天气/传感器降级场景:雨、雪、雾、强光等恶劣天气会导致传感器噪声增大、误检漏检率飙升,观测的不确定性大幅提升。POMDP可通过观测函数精准建模传感器降级后的噪声特性,基于带噪声的观测持续更新信念,避免因单次误检/漏检导致决策突变,相比确定性决策的频繁误触发,能显著提升恶劣天气下的决策稳定性。 多车博弈变道/汇入场景:高速/城市快速路的强制变道、匝道汇入、拥堵路段加塞场景,核心不确定性来自周边车辆对自车变道动作的反应(减速让行/加速抢位)。POMDP可将周边车辆的驾驶性格(激进/保守)作为隐性状态,通过多轮交互更新信念,选择最优的变道时机和动作,既避免保守决策无法完成变道,也避免激进决策引发碰撞,大幅提升变道成功率和安全性。
2. 有限适配场景(POMDP可应用,但非最优,性价比低)
这类场景的共性是不确定性极低、可观测性强、场景简单固定,POMDP能跑通,但相比规则式决策、确定性MDP,会带来额外的计算开销,工程落地性价比低。
高速直道稳态跟车场景:无遮挡、无变道需求、车流稳定的高速直道场景,周边车辆的状态完全可观测,行为模式固定,规则式PID/IDM跟车、确定性MDP决策就能实现稳定、安全的跟车效果,无需引入POMDP的复杂建模。仅当跟车场景伴随频繁切出切入、大车遮挡等不确定性时,才需要引入POMDP做补充。 固定路线封闭园区低速场景:园区、矿区、港口等封闭场景,环境固定、无社会车辆/行人、可观测性极强,规则式有限状态机就能覆盖99.9%的场景,POMDP的不确定性处理能力几乎没有发挥空间,仅在园区内有动态障碍物、人车混行的局部区域可有限应用。 结构化道路定速巡航场景:无弯道、无车流、无交通灯的结构化道路定速巡航场景,状态完全可观测,无交互需求,确定性控制算法就能完美适配,引入POMDP只会增加计算复杂度,无实际落地价值。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 全尺寸闪充SUV
- 2026年Q1,6座/7座SUV不用看太多,这6台就够了
- 六座变五座,家用SUV的降维打击
- 25万想换大SUV,先别下单:4月这4台,真有必要等一等
- 大五座SUV“奶爸车”,续航2000公里,拥有30万档次,预售13万多
- 火出圈!连续6个月双料冠军,这台方盒子SUV才是真现象级爆款
- “被遗忘”的豪华SUV,从25.77万降到15万多,还要啥奥迪Q3?
- “被忽视”的奔驰纯电SUV,新车从35.2万降到17万多,可惜无人识货
- “被遗忘”的全球畅销SUV,从18.98万降到11万多,可惜却无人识货
- “被忽视”的豪华轿车,媲美BBA,从近19万降到12万多,可惜无人识货
