开车这事儿,说白了就是在和不确定性打交道。前车突然急刹、旁边车突然变道、鬼探头——老司机靠的是"预判",脑子里快速过一遍"如果他这样,那我那样"的剧本。
但问题是,AI开车能不能也学会这招?
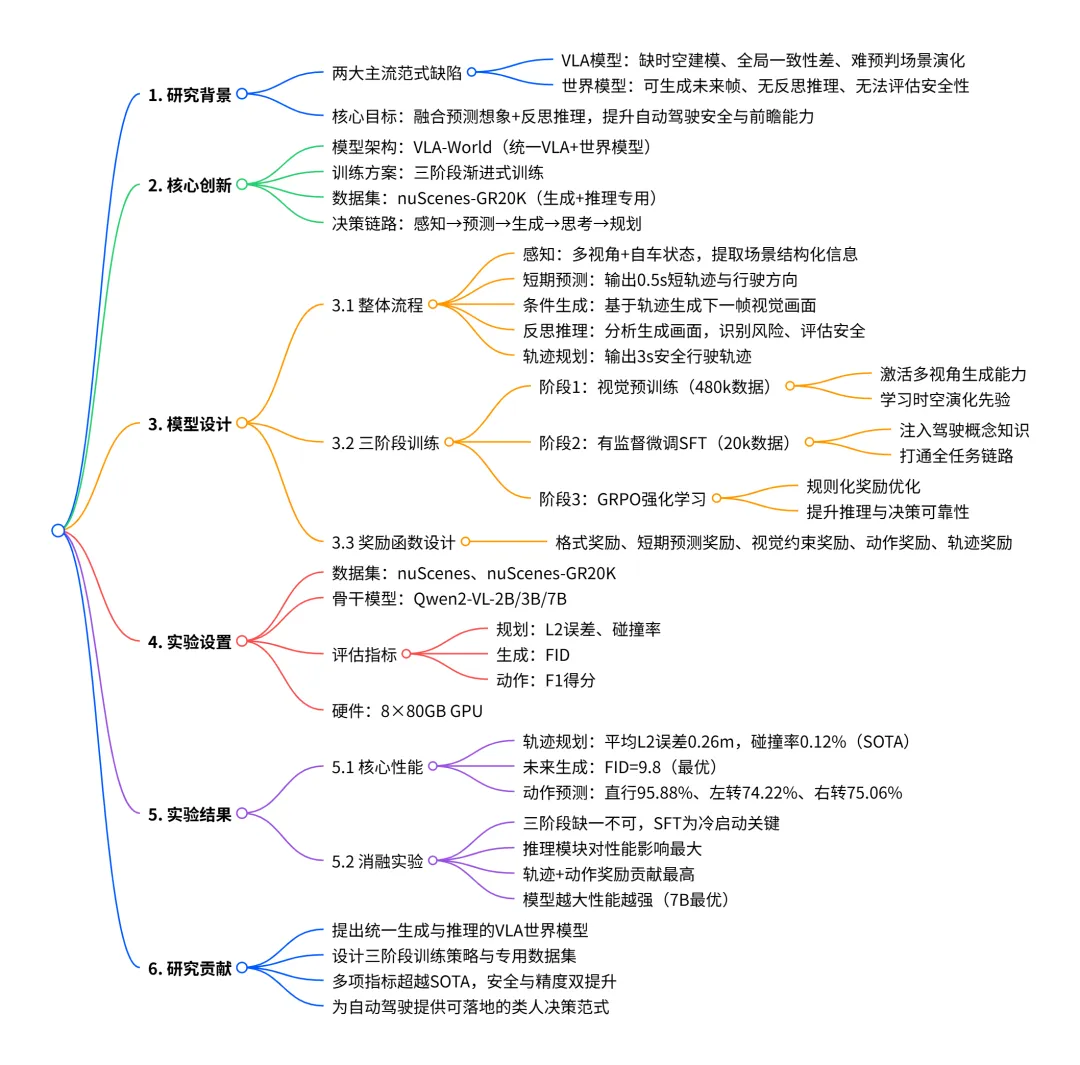
最近上海交通大学和华为中央研究院联合发布了一篇论文,提出了一个叫VLA-World的模型,核心就一件事:让自动驾驶系统学会"预见"未来,还要学会"反思"自己看到的未来够不够安全。
先说现有方案的问题。现在主流分两类:VLA模型和世界模型,听着挺唬人,但各有致命短板。
VLA模型能看路况、能推理、能输出驾驶动作,但你问它"接下来0.5秒会发生什么",它一脸懵——它只能看到眼前这一帧,不知道世界下一秒怎么变。就像一个人只会看当下,不会想象未来。
世界模型呢?它能生成未来驾驶场景,预测下一秒路况长什么样。但问题是,它生成完之后就结束了,没能力去"理解"和"评估"这些画面。它只知道"可能发生什么",不知道"这意味着什么"——生成一个危险场景,它也不会主动修正决策。
简单说,传统模型要么"会想不会算",要么"会算不会想",始终无法复刻人类司机"先预判、再反思、再行动"的驾驶逻辑。
VLA-World解决这个问题的思路很直接:把预测和生成接起来,再加上一层推理能力,形成闭环。
它的五步法全流程决策是这样的:
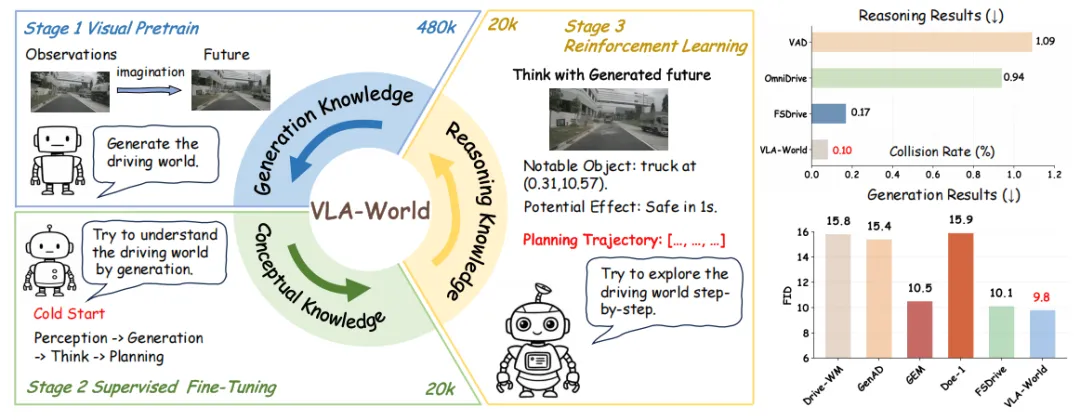
第一步感知,模型检测周围车辆、行人、车道边界;第二步短期预测,精准推算未来0.5秒的轨迹,锚定车辆运动方向;第三步未来生成,用预测的轨迹引导下一帧图像生成——不是凭空生成,而是根据"我要往哪开"来生成"到时候路况什么样";第四步反思推理,对生成的未来画面进行风险评估;第五步轨迹规划,修正决策,输出3秒安全行驶轨迹。
核心洞察在这里:短期的0.5秒轨迹预测天然携带丰富的时空信息——它既捕捉了自车运动,也记录了周围车辆的动态,这些信息对安全驾驶推理至关重要。
为了让模型同时具备这些能力,论文设计了独特的三阶段训练策略。第一阶段在海量图像-指令数据上进行视觉预训练,用48万数据激活多视角生成能力;第二阶段在nuScenes-GR-20K数据集上进行监督微调,打通感知、生成、推理全链路;第三阶段用强化学习(GRPO算法)探索类人推理能力,让模型不仅能做事,还能"讲道理"。
实验结果确实漂亮。在nuScenes数据集上,VLA-World的碰撞率降到了0.12%,对比其他VLA方法的9.8%,数字碾压;轨迹规划L2误差低至0.18米(7B模型),生成画质FID值9.8,行业最优。
但我得泼点冷水:0.12%听起来很低,换算一下,全国每天1亿次自动驾驶决策,对应12万次潜在碰撞,这还没算极端边缘场景。这个数字的意义在于证明了"预测-生成-推理"这条路走得通,而不是说问题已经解决。
从技术范式的角度看,VLA-World的价值可能比具体数字更重要。它把世界模型从"能生成"推进到"能理解",又把VLA从"能回答"扩展到"能行动",两者结合才形成真正的闭环。
后续需要重点关注几个问题:数据效率——三阶段训练涉及大量数据,真实场景泛化能力待验证;推理速度——端到端模型的实时性是个挑战;以及多模态输出的可解释性和安全性。
总的来说,VLA-World展示了一条有潜力的技术路径——让自动驾驶学会预判、生成和反思人类驾驶行为。这是上交和华为联合团队的工作,发布于2026年4月10日。碰撞率从9.8%降到0.12%是个不错的进展,但技术演进从来不是一蹴而就的事。
论文链接:https://arxiv.org/pdf/2604.09059v1
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
