自动驾驶赛道里,视觉-语言跨模态理解一直是核心关卡——既要让车看懂复杂路况,还要精准响应各类交互指令。视频问答定位(VideoQG)、车载文档解析还有动态时序感知,这些更是支撑智能驾驶落地的关键技术。
可眼下主流模型依旧痛点频发:要么陷在数据伪相关里,靠偏倚得出不可信的推理结果;要么没有统一的评测标尺,模型性能优劣难辨;要么面对长时动态路况,直接出现推理失效,完全跟不上自动驾驶高安全、高精准的硬性要求。
本次我们精选三篇CVPR 2025的重磅研究,分别从跨模态因果去偏、全场景评测基准搭建、动态时序感知优化三个方向破局,直击自动驾驶跨模态理解的核心堵点,为相关技术落地提供完整的科研参考。
我整理了10篇“因果推断+时序定位"相关论文(包括本章3篇论文),供大家学习了解这个方向,找到课题,挖掘创新点。
扫码回复
“因果推断+时序定位"
免费领取&进交流群
论文一:视频问题定位的跨模态因果关系对齐
1. 论文信息
- 论文名称:Cross-modal Causal Relation Alignment for Video Question Grounding
- 作者与机构:Weixing Chen, Yang Liu, Binglin Chen 等,中山大学、新加坡南洋理工大学
- 论文链接:https://arxiv.org/abs/2503.07635
- 代码链接:https://github.com/WissingChen/CRA-GQA
2. 创新点
视频问答中的“时间定位”(Video Question Grounding)要求模型不仅输出答案,还要给出答案对应的视频时间段。现有模型常犯一个毛病:答案对了,但定位的依据是错的。比如图1(a)中,模型回答“推婴儿椅”是正确的,但它的视觉注意力却集中在“气球”和“拥抱”上——这属于典型的虚假关联。
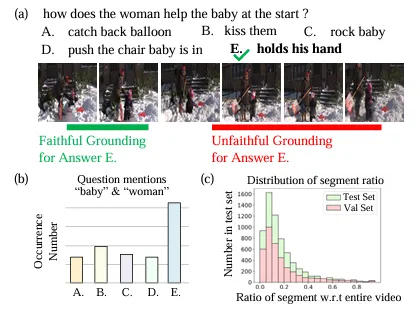 图1:模型在NextGQA数据集上的错误定位案例,以及数据集的偏差分布
图1:模型在NextGQA数据集上的错误定位案例,以及数据集的偏差分布本文的核心创新是引入结构因果模型,把视频定位问题拆解为两个因果干预路径:
前门干预(Front-door Intervention)用于视觉去偏:将模型估计出的视频片段作为“中介变量”,切断视频全局特征与答案之间的虚假路径。通俗讲,就是强制模型必须“凭良心说话”——你定位到哪里,就必须依据哪里来回答。
后门干预(Back-door Intervention)用于语言去偏:通过对问题中的实体(如“baby”“woman”)进行结构化分解(主谓宾),阻断语言先验对答案的干扰。
此外,作者还提出高斯平滑定位模块,用可学习的高斯滤波器对跨模态注意力进行平滑,抵抗时间维度的噪声波动。
3. 方法/实验设计
框架命名为CRA(Cross-modal Causal Relation Alignment),整体流程如图2所示:
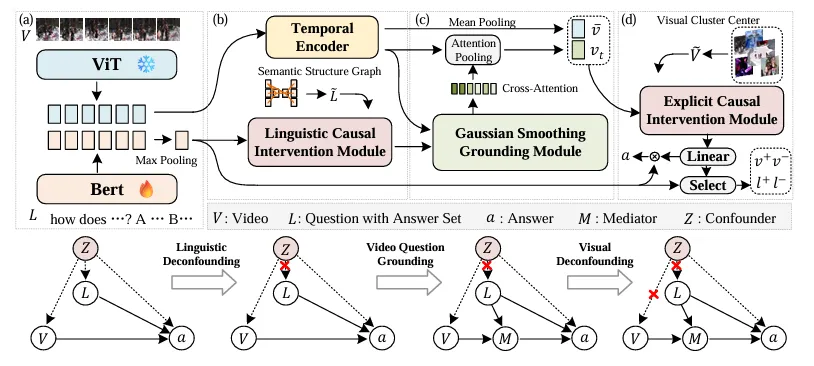 图2:CRA整体框架图,包含特征提取、语言干预、高斯定位、显式干预四个模块
图2:CRA整体框架图,包含特征提取、语言干预、高斯定位、显式干预四个模块关键技术流程:
- 视频帧用CLIP提取特征,文本用RoBERTa编码;
- 高斯平滑定位模块计算文本与各帧的相关性,生成时间注意力,并用自适应高斯滤波去噪;
- 语言因果干预:将问题分解为“主语-谓语-宾语”结构图,聚类后作为混杂因子进行后门调整;
- 显式因果干预:将定位出的视频片段作为中介,结合全局视频特征进行前门调整,最终输出去偏后的答案。
实验在NextGQA和STAR两个数据集上进行,对比基线包括IGV、SeViLA、Temp[CLIP]、FrozenBiLM等。
4. 研究成果
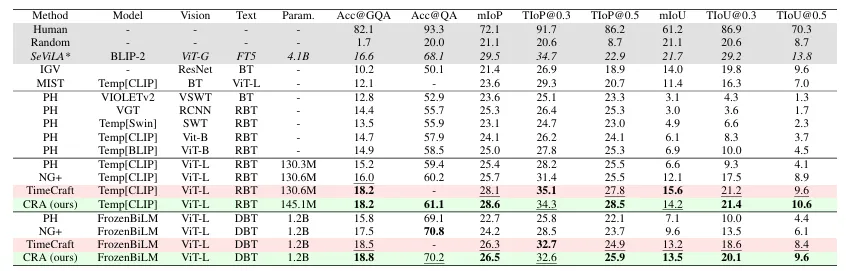 表1:NextGQA测试集上的VideoQG性能对比
表1:NextGQA测试集上的VideoQG性能对比从表1的结果看,CRA在NextGQA上Acc@GQA达到18.2% (比Temp[CLIP] NG+高出2.2个百分点),IoP@0.5达到28.5% ,显著优于同类方法。
更值得关注的是表1中对“偏差错误”和“不忠实回答”的量化分析:CRA将不忠实回答率从41.4%降至40.0% ,偏差错误减少1.1个百分点。这说明因果干预确实让模型“看得更准”。
从图3的可视化可以看出,CRA的注意力集中在真正相关的区间,而FrozenBiLM虽然答对了,但注意力峰值完全落在了错误的时间段——这正是“答对但不可信”的典型案例。
 图3:NextGQA上的可视化对比,展示CRA与其他方法的注意力分布差异
图3:NextGQA上的可视化对比,展示CRA与其他方法的注意力分布差异小结:CRA通过因果干预,把“定位”和“回答”绑在一起,强迫模型必须用定位到的证据来回答问题。这种思路对提升多模态模型的可解释性和可信度极具价值。
论文二:VTON 360:来自任意视角的高保真虚拟试穿
1. 论文信息
- 论文名称:VTON 360: High-Fidelity Virtual Try-On from Any Viewing Direction
- 作者与机构:Zijian He, Yuwei Ning, Yipeng Qin 等,中山大学、卡迪夫大学、上海科技大学
- 论文链接:https://arxiv.org/abs/2503.12165
- 项目主页:https://scnuhealthy.github.io/VTON360
2. 创新点
3D虚拟试穿一直有两个痛点:一是高保真纹理保留(LOGO、条纹不能糊),二是任意视角一致性(转个角度衣服就变样)。现有方法要么依赖3D扫描成本太高,要么用扩散模型“脑补”但丢失细节。
VTON 360的核心思路是:把3D问题转化为多视图2D编辑问题。它利用“3D模型与其渲染的多视图2D图像等价”这一关系,将任意视角的试穿统一成一个多视图2D VTON任务。
三个关键技术突破:
- 伪3D姿态表示:用SMPL-X模型的法线贴图代替传统的DensePose。DensePose在每个身体部位给统一标签(如“大腿”),缺乏3D几何一致性;而法线贴图能捕捉表面朝向细节,跨视角更稳定。
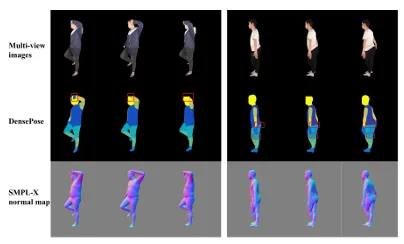 图4:DensePose与SMPL-X法线贴图的对比,红色框标出DensePose的伪影
图4:DensePose与SMPL-X法线贴图的对比,红色框标出DensePose的伪影- 多视图空间注意力:不同视角的图像不是均匀分布的,视角越近相关性越强。本文设计了一个相关性矩阵C,用相机旋转矩阵的夹角余弦值来调节注意力权重,让相近视角的特征交互更强。
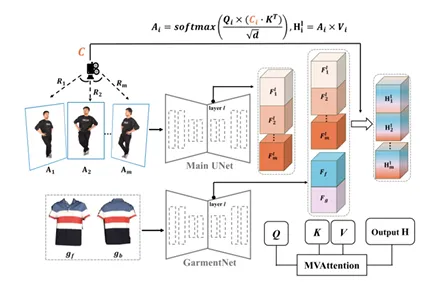 图5:多视图空间注意力机制示意图
图5:多视图空间注意力机制示意图- 多视图CLIP嵌入:将相机参数(旋转矩阵)编码后拼接到CLIP特征中,让模型知道“当前看的是哪个角度”。
3. 方法/实验设计
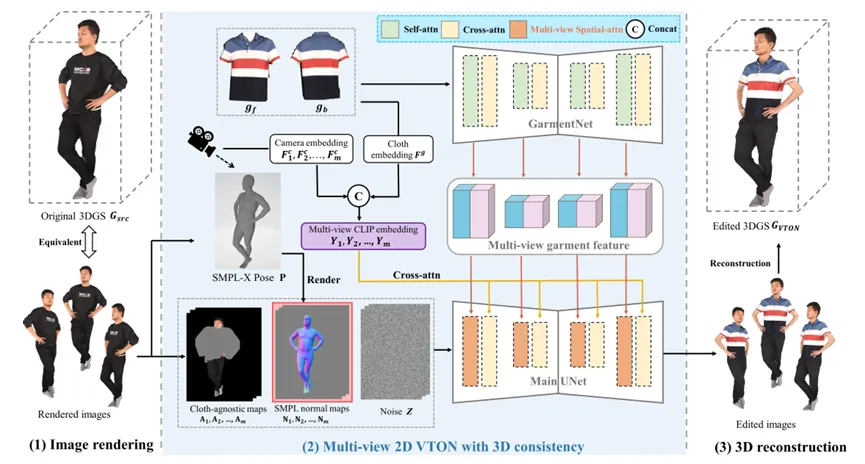 图6:VTON 360整体流程图
图6:VTON 360整体流程图整体流程如图6所示:输入3D人体和前后两件衣物图 → 渲染多视图2D图像 → 用增强的2D VTON模型编辑 → 重建为3D模型。
训练分两阶段:
- 阶段一:单视图训练,让网络学会特征提取和基础生成;
- 阶段二:多视图训练,随机选8个视角,重点训练多视图空间注意力模块。
数据集:Thuman2.0(526个扫描人体)和MVHumanNet(4990个多视角人体)。
4. 研究成果
- 从图7的定性结果看,DreamWaltz、GaussCtrl、Tip-Editor等基线要么丢失纹理,要么无法保持一致性,而VTON 360能清晰保留条纹、文字、LOGO。
 图7:与三个基线方法的定性对比,蓝色框标出细节保留
图7:与三个基线方法的定性对比,蓝色框标出细节保留表2的定量结果也显示,VTON 360在DINO相似度上显著领先,说明与参考衣物的纹理匹配度最高。
图8展示了在真实电商衣物(MVG数据集)上的泛化效果,即使模型只在Thuman2.0上训练,仍能准确还原条纹领带、纽扣等细节。
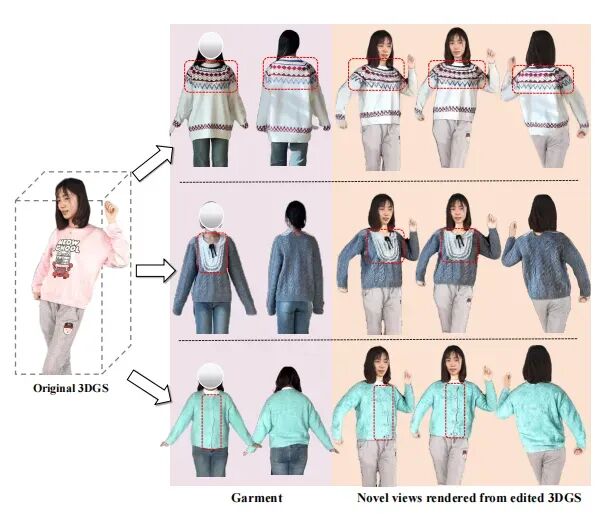 图8:在电商衣物上的泛化结果
图8:在电商衣物上的泛化结果小结:VTON 360通过多视图2D编辑的思路,巧妙绕开了3D扫描和纯生成式方法的局限,在高保真纹理保留和多视角一致性之间取得了更好的平衡。
论文三:OmniDocBench:使用全面注释对多样化PDF文档解析进行基准测试
1. 论文信息
- 论文名称:OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations
- 作者与机构:Linke Ouyang, Yuan Qu, Hongbin Zhou 等,上海AI实验室、Abaka AI
- 论文链接:https://arxiv.org/abs/2412.07626
- 代码链接:https://github.com/opendatalab/OmniDocBench
2. 创新点
文档解析(PDF转Markdown/HTML)是RAG系统的上游依赖,但现有评测存在三大问题:
- 指标粗糙:只算编辑距离,对公式、表格的格式多样性不敏感;
OmniDocBench提供了一个高质量、多类型、细粒度标注的评测集:
- 9大文档类型:除学术论文外,包含教科书、试卷、手写笔记、报纸、杂志、财报、幻灯片等真实场景;
- 多层标注体系:19种布局类别(标题、段落、表格、公式等)+ 15种属性标签(语言、背景色、旋转、合并单元格等);
- 灵活评测框架:支持端到端、任务级、属性级三级评测,对表格用TEDS、公式用CDM,避免格式差异带来的不公平。
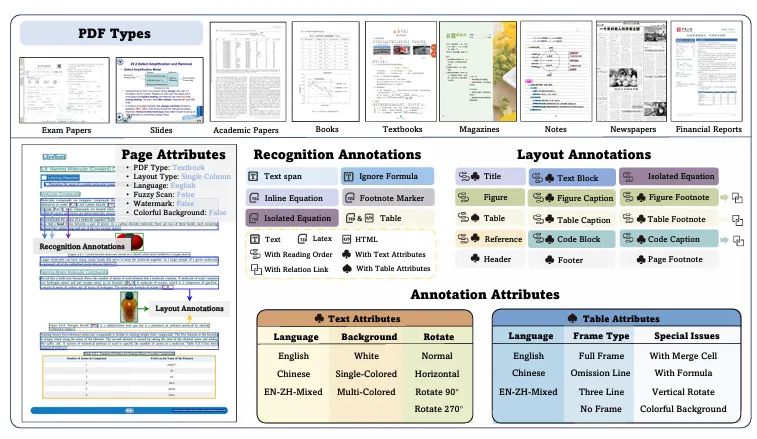 图9:OmniDocBench数据多样性概览,包含文档类型、标注层级、属性标签
图9:OmniDocBench数据多样性概览,包含文档类型、标注层级、属性标签3. 方法/实验设计
评测流程如图10:模型输出的Markdown → 提取表格、公式、文本 → 与GT进行邻近搜索匹配(解决段落拆分不一致问题)→ 分别计算Edit Distance、TEDS、CDM。
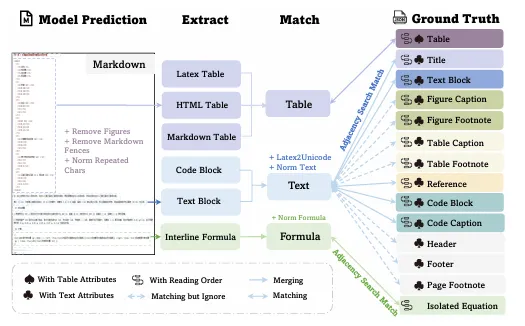 图10:评测流程图
图10:评测流程图评测对象分三类:
- Pipeline工具:MinerU、Marker、Mathpix;
- 通用VLM:GPT-4o、Qwen2-VL-72B、InternVL2-76B。
4. 研究成果
- 从表3的总体结果看,MinerU在文本、公式、表格上均领先,尤其在中文表格上优势明显;Qwen2-VL-72B作为通用VLM表现抢眼,文本编辑距离仅0.096(英文)和0.218(中文)。
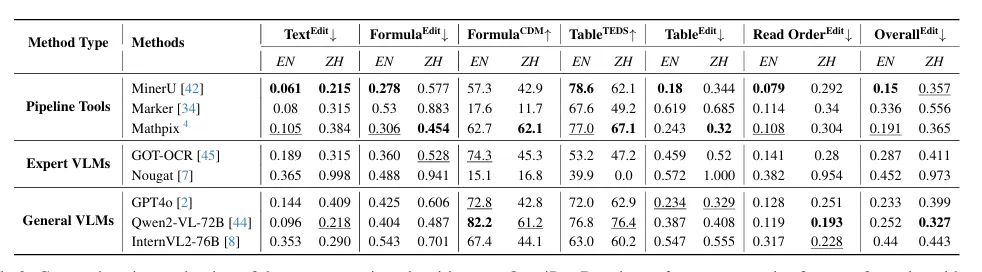 表3:OmniDocBench上各方法的端到端解析结果
表3:OmniDocBench上各方法的端到端解析结果- 表4按文档类型拆解文本识别性能,发现: 1)Pipeline工具在“学术论文”“财报”等规整文档上表现优异; 2)通用VLM在“手写笔记”“幻灯片”等非规整类型上泛化更强; 3)所有模型在“报纸”这种高密度排版上集体翻车,但MinerU仍能靠布局分割勉强维持。
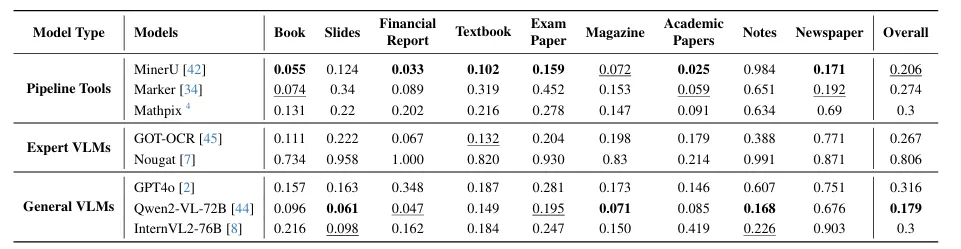 表4:按文档类型拆解的文本识别编辑距离
表4:按文档类型拆解的文本识别编辑距离- 表5等则进一步拆解布局检测、表格识别、OCR、公式识别的细粒度结果,例如: 1)DocLayout-YOLO在布局检测上平均mAP 47.38% ,远超传统方法; 2)旋转文本仍是所有OCR模型的噩梦,Edit Distance普遍飙升; 3)表格含公式对VLM影响较小,但对OCR-based方法影响显著。

小结:OmniDocBench不只是又一个评测集,它提供了一个多维度的“诊断工具”,帮研究者定位模型到底弱在哪儿——是中文不行?还是旋转不行?还是报纸排版不行?这种细粒度反馈对模型迭代极有价值。
总结与展望
三篇论文分别攻克自动驾驶跨模态理解的伪相关偏倚、评测缺失、时序感知低效三大核心痛点,因果去偏保障推理可信性、标准化基准规范模型评测、动态时序优化适配车载落地,形成了从技术创新到评测验证再到工程落地的完整链路。
未来可进一步融合三项技术,打造端到端的自动驾驶跨模态理解系统,优化极端路况、复杂交互场景的推理性能,推动模型从实验室走向实车应用。



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
