导读
如果说 2023—2024 年是"扩散规划器(Diffusion Planner)"在自动驾驶规划赛道的崛起期,那么 2025 年下半年以来的真正风向,是怎么用强化学习(RL)把这些生成式规划器从"模仿专家"推到"自己从闭环反馈里学"。扩散模型擅长画出多模态的候选轨迹,却缺少一个机制告诉它哪条候选在几秒后会撞车——纯模仿学习(Imitation Learning,IL)只见专家的成功、不见自己的错误,闭环里极易"随机地滑出分布"。
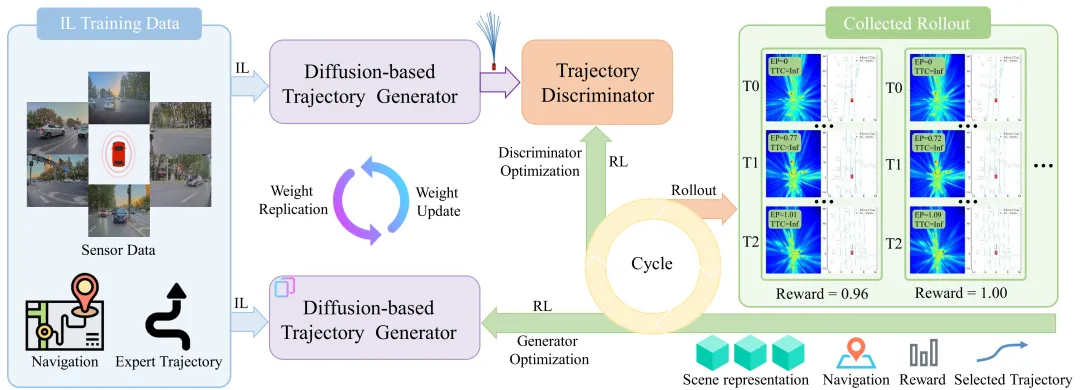
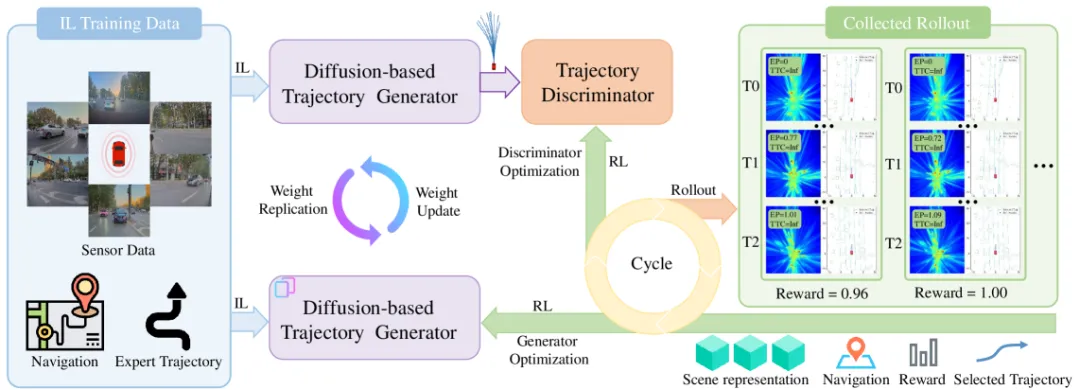
RAD-2 就是这一路线上一个很关键的动作:来自华中科技大学 Hao Gao、Shaoyu Chen、Xinggang Wang 团队(2026-04-16 arXiv)的这篇论文,把规划整件事拆成了扩散生成器 + RL 判别器的"双塔"结构,再加一个自研的 BEV 特征级仿真器 BEV-Warp 做闭环训练的"数据工厂"。在 512 个安全场景的闭环评测里,它相比同数据训练的扩散规划基线 ResAD 把碰撞率从 0.533 砍到 0.234,降幅 56%;在 3DGS 真实感仿真和 Senna-2 开环基准上同样拿到 SOTA;并且实车部署给出了"更顺、更稳"的主观感受。
这篇文章不重复摘要翻译,更想讲清楚三件事:一、为什么规划必须从"单塔扩散"走向"生成-判别解耦"?二、TC-GRPO 和 On-policy Generator Optimization 到底在数学上做了什么?三、BEV-Warp 这种"特征级仿真"为什么是大规模 RL 规划训练真正的拐点?
背景与动机
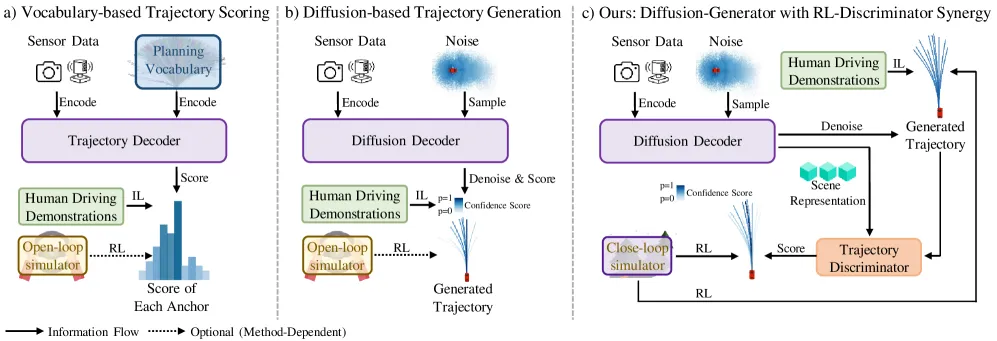
过去两年,端到端规划里出现了三代"多模态"范式:
- 词表式打分(Vocabulary-based Scoring)——把轨迹离散化成一个锚点词表,由一个 scorer 给每个锚点打分。优点是评估稳定,缺点是词表限制了能表达的动作空间,尾部场景几乎不可能用一小撮模板拟合。
- 扩散生成(Diffusion Generation)——用扩散模型在连续轨迹空间里采样,天然多模态。代表工作是 GenAD、ResAD 等;缺点是完全 IL 训练下,闭环里一旦进入专家分布之外的状态就会"越走越歪",而且生成本身有随机性,同一场景可能既生成"稳健减速"也生成"激进加速",没有机制抑制后者。
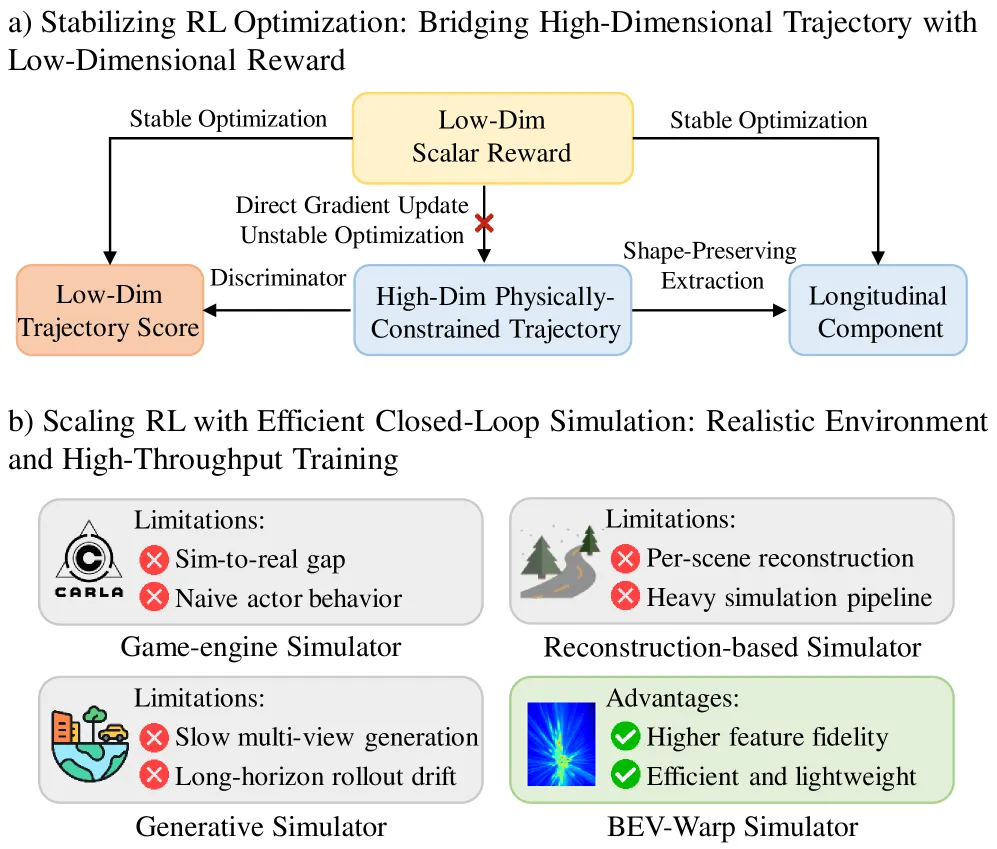
- RL 加持的端到端规划——试图把稀疏的碰撞/进度奖励直接回传给生成器。问题是:奖励是一个低维标量,动作却是高维、物理受约束的轨迹序列,直接用标量梯度去推整条轨迹,会在高维空间里到处乱撞,优化极不稳定(后面 Figure 7 会给出对比曲线)。
这三个痛点可以用一句话总结:IL 缺纠错、词表缺表达、直接 RL 缺稳定。RAD-2 给出的回答是"不要试图让扩散生成器自己承担所有职责,而是把它拆成两个角色"。
除此之外,仿真环境本身也是瓶颈。CARLA、SMARTS 这类游戏引擎仿真有严重的 sim-to-real gap、背景车行为过于幼稚;3DGS、ReconDreamer 这类基于重建的仿真画面真实但每个场景都要重建、流水线沉重;世界模型类的生成式仿真长期 rollout 会漂移、多视角合成又慢。论文作者指出,这些限制构成了"RL 规划没法 scale"的真实原因——算法再好,每步 200 毫秒的仿真速度根本顶不住 50 万环境步的训练预算。
核心方法
1. 生成-判别解耦:让奖励只打在"可优化"的维度
RAD-2 的顶层结构非常简洁:
- 扩散生成器 :在每个时间步基于 BEV 特征和导航意图采样出一组候选轨迹 ${\hat{\tau}i}{i=1}^G$;
- 轨迹判别器 :对每条候选输出一个标量分数 ,按分数重排(reranking)选出被执行的那一条。
这个设计的关键不在于"多塔"本身,而在于奖励只沿着低维路径回传:
- 判别器吃的是标量奖励,它的输出本来就是标量分数——维度对齐,梯度稳定;
- 生成器要动的是"整条轨迹的分布",直接用 RL 去推会不稳;所以 RAD-2 只在**纵向分量(longitudinal component,即加减速剖面)**上给生成器提供监督,不碰横向路径。
论文里用一张图把这一点讲得非常清楚:低维奖励没法直接梯度更新高维物理受约束轨迹(红叉),必须经由"判别器分数"和"纵向分量"两个低维投影分别回传。这其实是个朴素但被长期忽视的工程观察——RL 的稳定性问题常常不是算法问题,而是维度不匹配问题。
2. TC-GRPO:让时间一致性解决信用分配
判别器的 RL 训练用的是 GRPO(Group Relative Policy Optimization)家族的扩展。GRPO 本身是 DeepSeek 在 LLM 后训练里推开的路线:不用 critic,而是把一个 prompt 采样的 条回答作为一个"组",用组内归一化优势取代 value 估计。这省掉了价值网络带来的训练不稳定,并在 LLM 领域被反复验证过。
但开车和写文本不一样:文本是离散 token、每次采样独立;开车是连续动作、每个时间步都要做决策,而且当前动作的后果要到几秒后才显现。如果天真地每一步都重新采样一条新轨迹候选、每一步都重新打分,一个碰撞的发生到底归功于(或归罪于)哪一步的轨迹选择?这就是论文反复提到的"credit assignment problem"。
RAD-2 的答案是 Temporally Consistent GRPO (TC-GRPO),关键技巧叫 latched execution:
- 在 rollout 过程中,选中的轨迹假设会被锁存一个固定的时域 步才允许切换;
- 奖励只在锁存区间的起点 处计入优化目标——这保证稀疏奖励被归因到那条真正被执行了一段时间的轨迹,而不是被一堆高频切换的决策稀释。
形式化地:对组内第 条 rollout ,优势为
裁剪目标只在锁存起点生效:
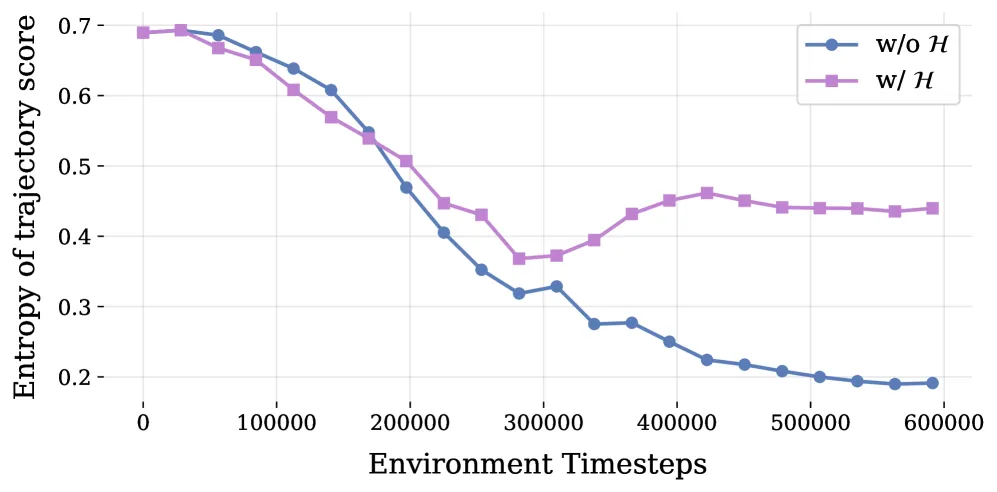
并配一个自适应熵正则,只有当平均熵 (快要坍缩到极端分数 0/1)时才激活。熵正则的效果在图 9 里非常直观——没有熵项时判别器分数的熵一路从 0.69 滑到 0.19(评分极化、探索消失),加上之后稳定在 0.44 左右。
论文的消融给出了 TC-GRPO 几个超参的理想取值:
- 锁存步数 是安全与效率的最佳折中(小了信用归因噪声大、梯度不稳;大了反应变迟钝);
- 组大小 在 Safety@1、CR 指标上都最好,增到 8 会略降安全性;
- 判别器从预训练 planning head 初始化比随机初始化 CR 低 9 个百分点(0.337 vs 0.426),预训练的空间理解能力不能浪费。
这些不是"调参经验",而是把一个 LLM 后训练里久经考验的算法"移植"到驾驶域时必须做的结构化调整。
3. On-policy Generator Optimization:在纵向分量上"推"扩散分布
如果只优化判别器,生成器输出的候选集上限就被锁死了——判别器再聪明,也只能从一堆糟糕的候选里挑一个"相对最不糟"的。所以 RAD-2 必须让生成器的分布本身也朝高奖励流形移动,这就是 On-policy Generator Optimization(OGO)。
OGO 的巧思在于:不去全轨迹 RL,而是只动纵向分量。给定生成器吐出的原始轨迹 ,根据闭环反馈:
- 安全驱动的减速:若当前 Time-to-Collision ,对加速度序列施加一个统一的负偏移(时域压缩比例 ),整条路径形状不变、但跑得更慢;
- 效率驱动的加速:若自车进度落后且安全余量充足,施加正偏移(),跑得更快。
得到"修正后的轨迹" 之后,把它们汇聚成一个在线数据集 ,用 MSE 回头微调生成器:
因为修正只在纵向(一维标量 offset)、目标 是从自己策略的 rollout 中 on-policy 派生的,整个分布迁移是渐进、稳定的——这相当于一个"轻量版 DAgger + 速度剖面整形",既不破坏扩散模型原本多模态的横向分布,又持续把速度剖面推向"安全且高效"的流形。
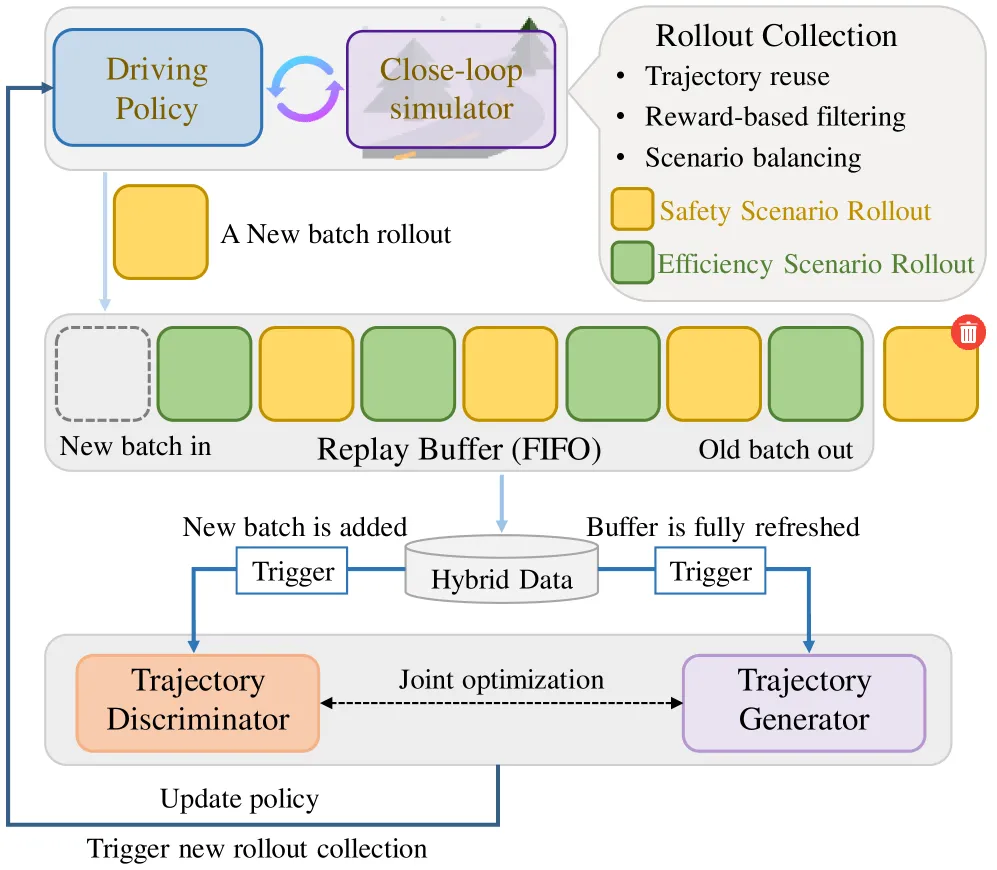
判别器与生成器的训练频率是 8:1:每收集 8 个新 batch 的 rollout,判别器用当前 buffer 全量优化一次;集满后触发一次生成器 OGO。这是一个很工程化的节奏——既保证判别器始终"追上"生成器分布的变化,又让生成器的迁移不会过度漂移。
4. BEV-Warp:特征级仿真才是 scale 的真正解
再好的算法,如果仿真跑不快、一个月只能跑几万步 rollout,那跟没有没区别。RAD-2 专门为此造了一个仿真环境 BEV-Warp。
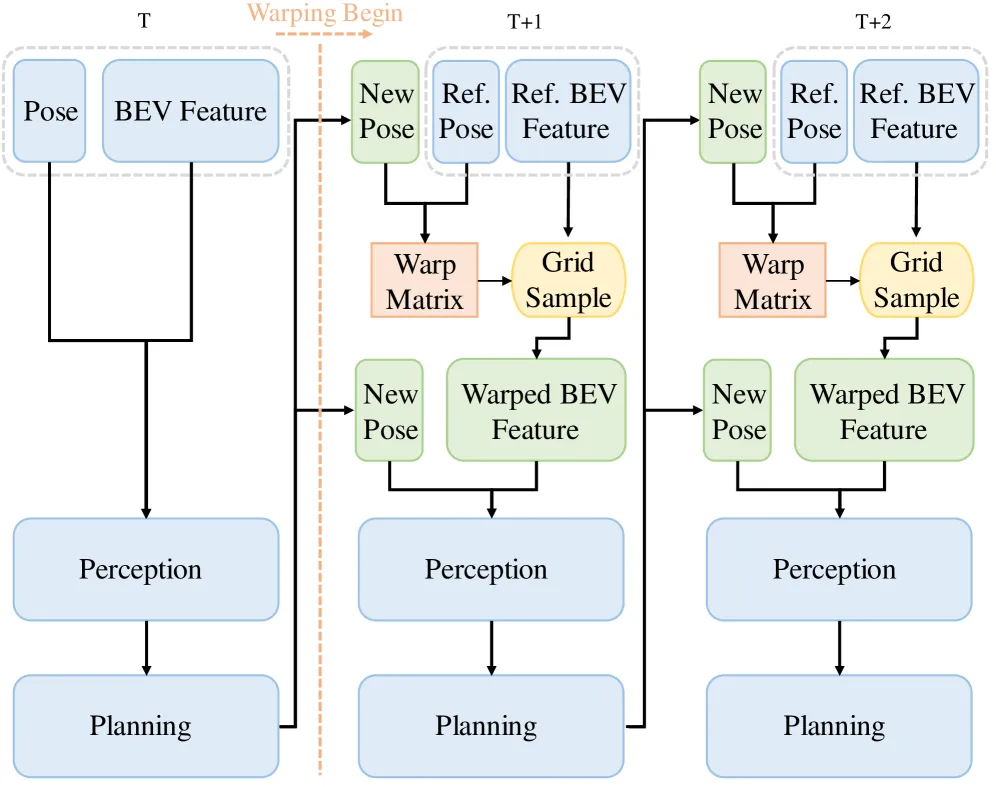
核心观察是:自车的闭环评估其实不需要从像素重新渲染一遍世界。BEV 特征空间已经是规划/感知的直接输入,如果 BEV 特征具备空间等变性(spatial equivariance)——即对 BEV 特征做一个几何变换 ,下游解码出的 3D 框、agent token 等也会对应地移动——那么闭环的"下一帧"就可以直接由一个 warp 矩阵 (含旋转 、平移 )作用在参考 BEV 特征上得到,完全绕开图像级的 rendering。
形式上,warp 矩阵就是一个 2D 刚体变换:
从日志的参考轨迹和仿真中的自车位姿差得到 ,做 grid sample 得到 warped BEV feature,下游感知和规划继续走原本的解码流程。
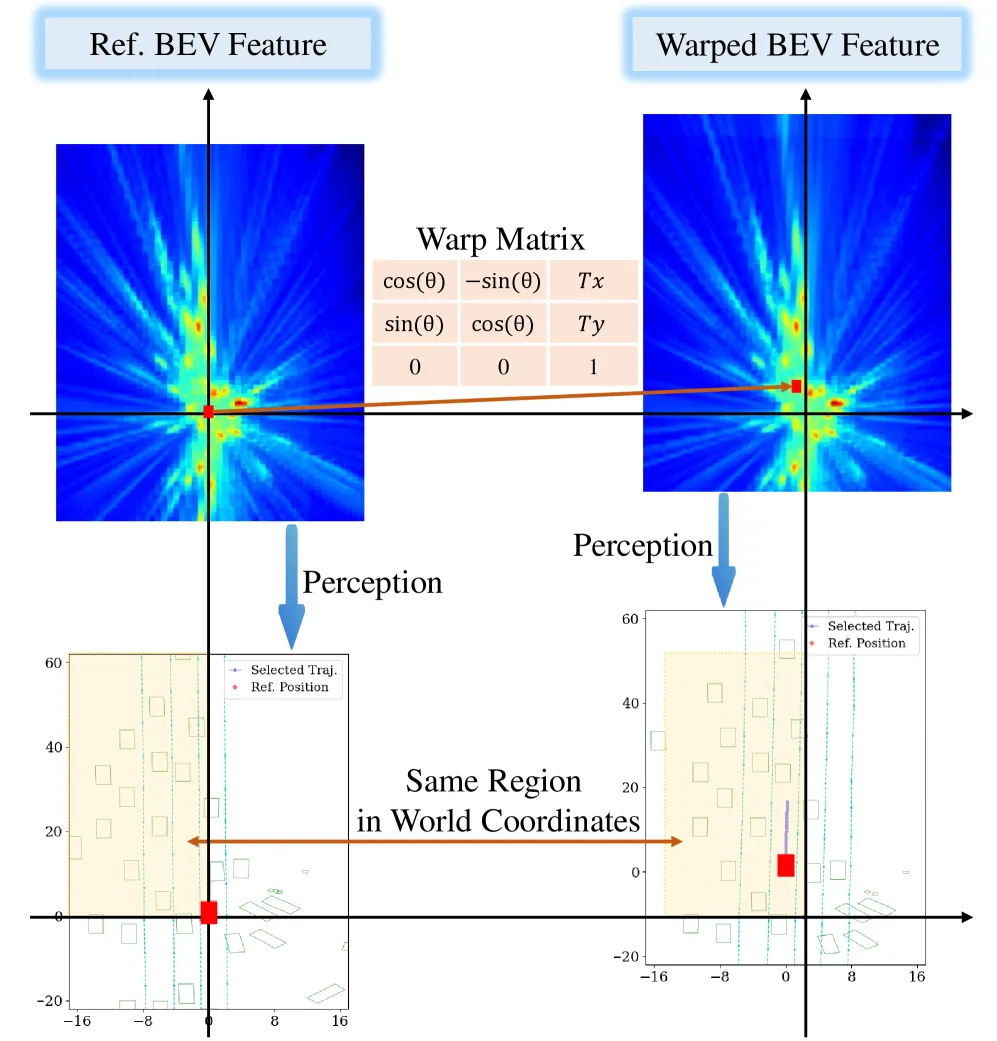
论文用图 5 实证了等变性:在相同世界坐标下,warp 前后解出的 3D box 保持一致,说明 warp 操作在特征层面是"物理正确"的。这一性质看似朴素,其实是近两年多视角 BEV 感知方法(BEVFormer / VAD 路线)带来的"副产品"——只有当 backbone 已经把图像投影到世界坐标下的 BEV 特征上、且特征对刚体变换稳定,才可能做这种跳过 rendering 的仿真。
BEV-Warp 的局限当然也有:它不能模拟"相机视角变化导致的遮挡重分配"或"光照变化",所以论文同时在 Senna-2 的 3DGS 仿真上做了交叉验证,证明判别器学到的不是 BEV-Warp 特定的 artifact,而是更一般的闭环质量信号。
实验与结果
核心闭环指标:BEV-Warp 512 场景
| | | | | | |
|---|
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| RAD-2 | 0.234 | 0.092 | 0.730 | 0.596 | 0.736 | 0.984 |
几个关键读数:
- 碰撞率从 0.533 降到 0.234,降幅 56.1%,且**"自己负主责"的碰撞率 AF-CR 下降 65%**(0.264 → 0.092)——这比总碰撞率的下降更重要,它意味着判别器学到了"谁该让"而不仅仅是"别撞";
- Safety@2s 从 0.281 提升到 0.596,翻了一倍多——这对应"还有 2 秒才可能撞"的比例,是乘坐体感的直接相关指标;
- EP@1.0[3](100% 完成导航目标的场景比例)从 0.516 升到 0.736,说明变保守没以"龟速爬行"为代价。
开环 Senna-2 基准
在开环 ADE/FDE/CR 上全部刷新 SOTA,开环 CR 从 Senna-2 的 0.288% 近乎折半到 0.142%。注意 RAD-2 在开环上能赢,并不完全靠 RL——它也得益于 OGO 把生成器的速度剖面推到了更"专家像"的区间。
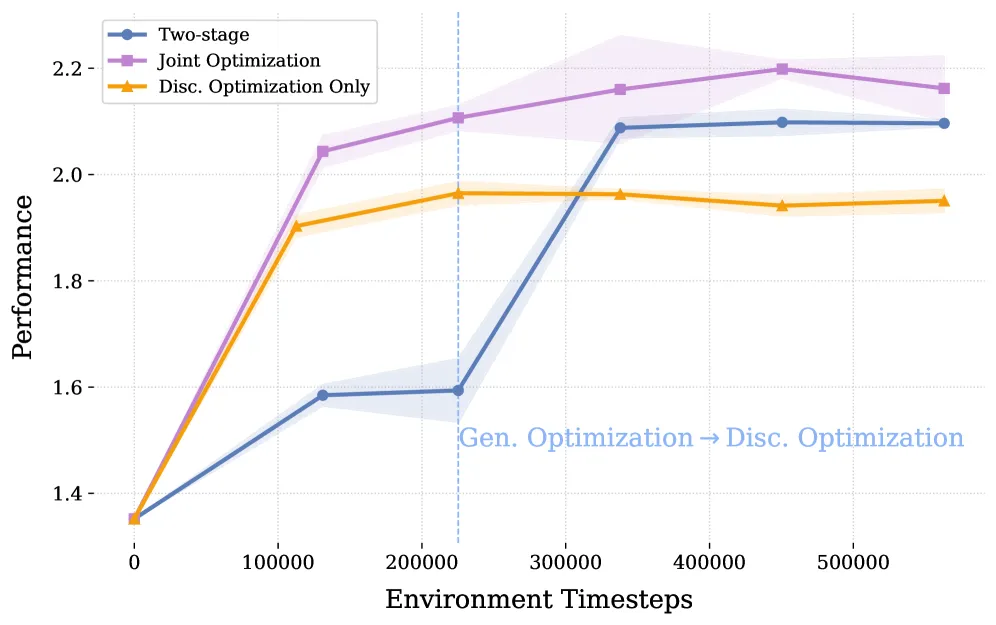
Scaling 曲线:联合优化是"非负和"的
图 7 对比了三种训练范式:
- 两阶段(先判别器,再生成器)(橙)能上到 ~1.95;
- 联合训练(TC-GRPO + OGO 交替)(紫)持续爬升到 ~2.1 附近。
这条曲线传递了一个重要信息:判别器的上限被生成器候选分布锁死,只有让生成器跟着判别器一起漂移,系统才能突破单塔上限。这也是为什么消融里,加上 OGO 后 CR 从 0.337 进一步降到 0.234——29% 的相对降幅都来自这个"让生成器陪跑"的设计。
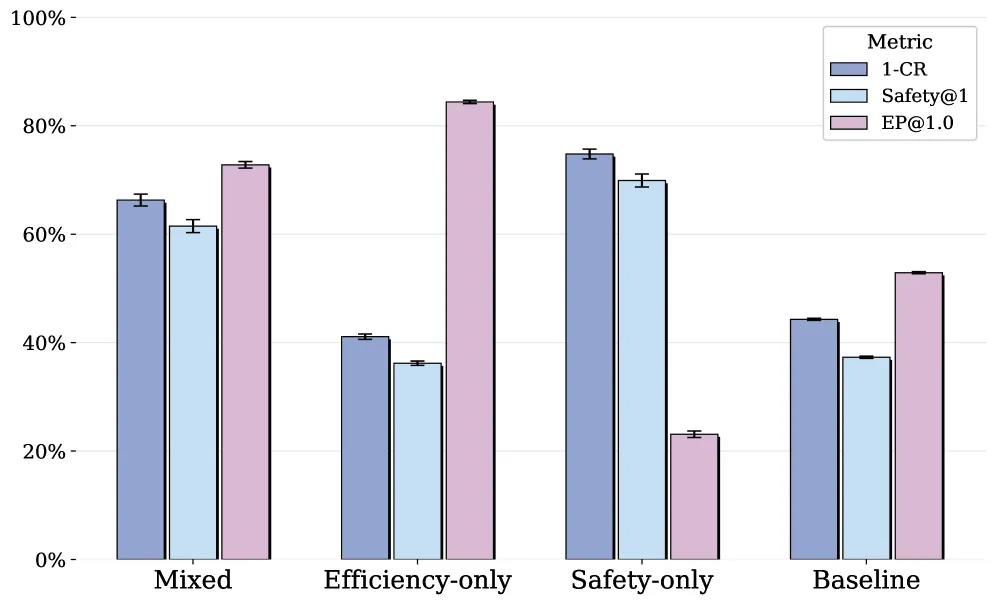
数据组成消融:别只训安全场景
图 10 给了一个很有启发的消融:
- 只用 efficiency 场景训练:EP@1.0[4] 爆到 ~84%,但 Safety@1 才 ~36%——跑得快但容易撞;
- 只用 safety 场景训练:Safety@1 ~70%,EP@1.0[5] 跌到 ~23%——太怂不敢走;
- Mixed(两者 1:1):1-CR ~66%、Safety@1 ~61%、EP@1.0[6] ~73%——平衡最好;
- **Baseline(IL 纯模仿)**三项全部垫底。
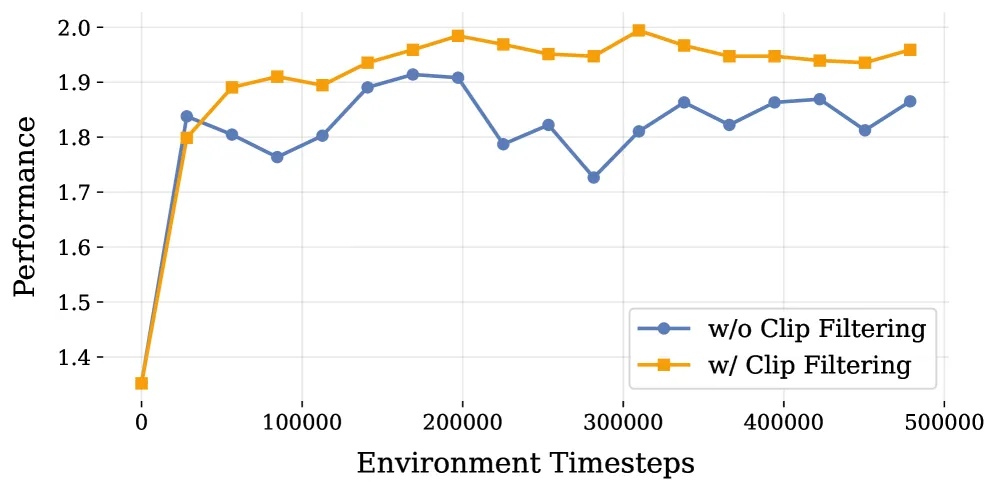
这印证了一个在 RL 规划里反复出现的经验:安全和效率必须同时训,任一单训都会导致行为极化。论文还专门做了奖励方差过滤(reward-variance clip filtering)——丢掉那些 rollout 之间奖励差距很小的"无信息场景",EP@1.0[7] 从 0.662 提到 0.728,训练曲线也显著更稳(图 8)。
定性对比
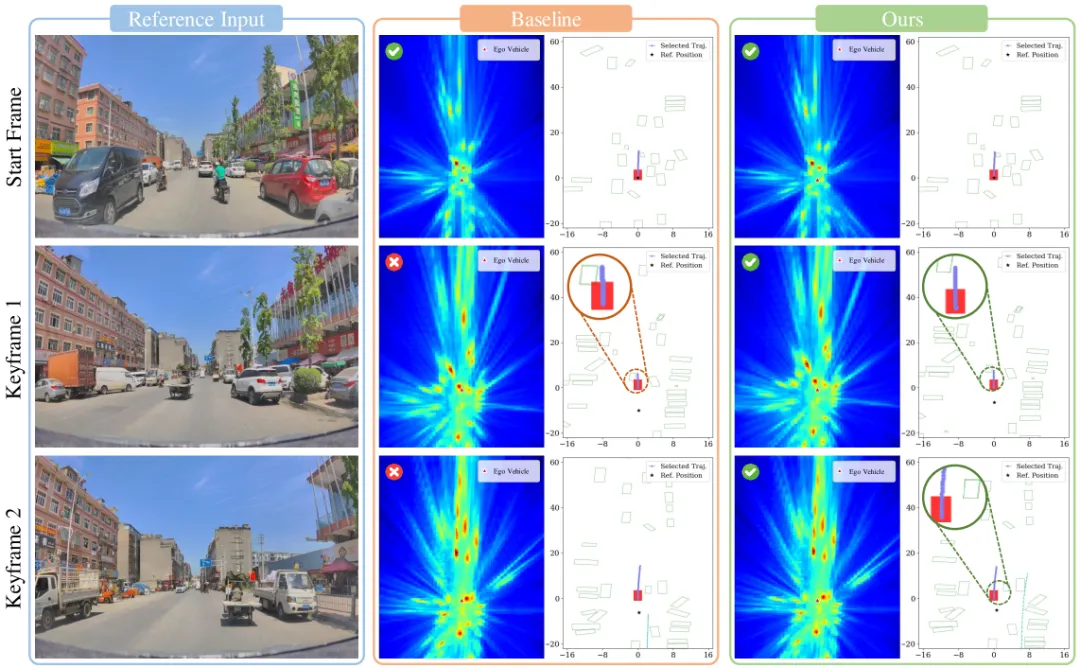
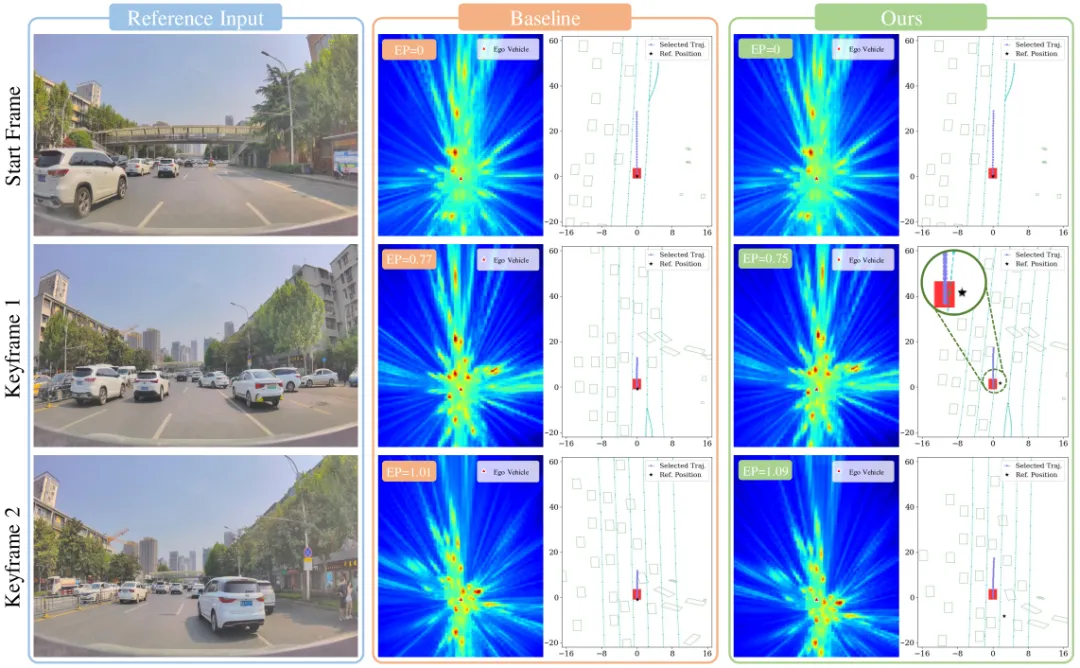
两组 qualitative case:上图是侧向来车场景,baseline 选了一条直冲轨迹撞上、RAD-2 主动让行;下图是路口直行,baseline 在关键帧速度滞后(EP=0.75),RAD-2 维持稳定加速完成通过(EP=1.0)。BEV 特征热力图也能看到判别器的注意力随环境变化在不同 agent 之间迁移。
讨论与思考
一、真正的创新点:把规划 RL 的两个根本难题"解耦"了
如果把这篇文章压缩成一句话,它的技术核心是:"不要试图用一个 RL 问题同时解决两件事"。
所谓两件事:
- 评估哪条轨迹更好(判别任务,监督信号清晰、维度低);
- 改进生成什么样的轨迹(生成任务,维度高、物理约束强)。
传统的端到端 RL 规划把两件事合在一个网络一个 loss 里,奖励维度和动作维度不匹配,梯度天然不稳定。RAD-2 把第 1 件交给 GRPO 一类"奖励驱动的 reranking"——这正是 LLM 后训练证明过好用的场景;把第 2 件退化成"纵向速度剖面的 DAgger"——既保留扩散模型的多模态横向能力,又让速度剖面得到闭环反馈。这种"把 RL 只施加在能稳定施加的地方"的工程哲学,可能比 TC-GRPO 或 BEV-Warp 任何单点都更有迁移价值。
二、BEV-Warp:自驾界的"特征级仿真"拐点
BEV-Warp 不是一个"更好的仿真器",它代表的是一种范式迁移:**既然下游模型只消费 BEV 特征,为什么非得从像素开始一路渲染?**这一点在 AIGC 领域其实早有类似动作——latent diffusion 就是把扩散搬到 VAE latent 空间,绕开像素。现在自驾仿真正在走同样的路。
它的限制也很明确:
- 不支持相机视角跳变(如远方新车辆"突然"驶入视野时,BEV 特征来源不存在);
- 依赖空间等变的 BEV backbone,对于非 BEV 派的 end-to-end 模型不适用。
但对"让 RL 规划 scale 到 10 万级 clip"这个目标来说,它已经够了。这是一个典型的"够用就好,快比真实更重要"的工程取舍。
三、TC-GRPO 的意义:让 LLM RL 后训练的成果向自驾迁移
GRPO 在 LLM 领域的成功(DeepSeek-R1 那一系)验证了"无 critic、组内归一化优势"的可行性,但直接搬到驾驶会因为动作时序相关、奖励稀疏延迟而失败。TC-GRPO 通过 latched execution 和时间一致性采样,把 LLM 那一套算法"驾驶化"了——这不只是一个 trick,它说明LLM 后训练和具身智能 RL 之间的算法桥梁可以搭,而且关键在于"尊重物理世界的时间结构"。
接下来一定会看到更多工作把 LLM 后训练里的其他 trick(reward modeling、DPO、Constitutional AI)往 VLA/驾驶域迁移,TC-GRPO 是一个很好的模板。
四、局限与开放问题
- 奖励仍是手工设计的: 用 TTC 瓶颈、 用进度窗口——很好用,但长期看需要可学习的 reward model(比如从人类接管次数、舒适度反馈里学);
- BEV-Warp 不覆盖长时域分布漂移:超过某个时长,warp 后的场景会偏离 log 中记录的真实世界动态(比如其他 agent 仍按原轨迹走、不会对自车反应);
- 多智能体交互:论文的 BEV-Warp 里其他 agent 是"木头人",真正的闭环多智能体博弈还没覆盖;
- 纵向优化回避了横向交互:变道、绕行等横向决策并没有直接被 RL 优化,这部分完全靠扩散生成器的横向多模态先验。
五、对行业的启发
对做自驾的人来说,RAD-2 提供了三条可以直接拿走用的经验:
- 扩散规划器单独训不行,必须配一个 RL 判别器做闭环兜底;
- RL 只施加在能稳定施加的维度上——全轨迹 RL 的痛苦完全可以通过"纵向 offset"这种低维代理规避;
- 仿真器值得在特征级别上重新设计——对你的 backbone 什么层上是空间等变的,就在那一层做仿真。
对做 LLM / VLA 后训练的人来说,RAD-2 是一个很好的"具身版 GRPO"参考——怎么把组相对策略优化落到连续动作、长时域、稀疏奖励的环境里。
总结
- RAD-2 = 扩散生成器 + RL 判别器 + BEV-Warp 特征级仿真,把"不稳定的高维轨迹 RL"拆成两个维度对齐的子问题。
- 在 BEV-Warp 512 个安全场景上碰撞率相对扩散基线降低 56%(0.533 → 0.234),自责碰撞率降低 65%(0.264 → 0.092),同时导航完成率反升(EP@1.0[8]: 0.516 → 0.736)。
- TC-GRPO(锁存执行 + 组相对优势 + 自适应熵正则)解决了驾驶连续动作空间的信用分配;OGO(纵向加速度偏移 + MSE 微调)把生成器也拉进 RL 训练循环。
- BEV-Warp 通过在 BEV 特征空间做 warp 替代像素级 rendering,让 50k clip 规模的闭环 RL 训练成为现实,是特征级仿真范式的标志性案例。
- 真正的遗产可能不是某个模块,而是"RL 只作用于低维可稳定维度 + 判别器做 reranking"这种范式——它把 LLM 后训练的成熟经验成功跨域迁移到了自动驾驶。
本文基于 RAD-2: Scaling Reinforcement Learning in a Generator-Discriminator Framework[9] 解读。
引用链接
[1]RAD-2: Scaling Reinforcement Learning in a Generator-Discriminator Framework: https://arxiv.org/abs/2604.15308