最近科技圈、汽车圈都在疯狂讨论一个新词 ——世界模型。很多人听完一头雾水:听起来高大上,它到底是什么?和我们常说的自动驾驶又有什么关系?今天来聊聊世界模型的底层概念、技术原理和行业未来。
世界模型:人类与生俱来的 “预测梦境”
世界模型这个概念,并不是 AI 诞生后才凭空出现的新鲜事物。
早在上世纪四五十年代,心理学领域就已经提出了相关理论。简单来说,世界模型就是我们大脑里内置的一套 “模拟器”。我们不用看清事物全貌,就能基于过往经验和常识,预判接下来会发生什么。
举个最直观的例子:
棒球比赛里,投手投出球后,球飞到击球手眼前,全程只有毫秒级的时间。人的视觉信号从眼睛传到大脑,根本来不及看完球的完整轨迹、再临时思考挥棒动作。击球手之所以能精准击中来球,靠的就是大脑里的 “世界模型”—— 在球还在空中飞行时,大脑就已经提前推演完球的落点、速度、轨迹,提前控制身体肌肉完成挥棒动作。
2018 年,一篇重磅论文《World Models》正式把这个概念系统化:人类只会用眼睛捕捉零散、有限的外界信息,真正指导我们所有行动的,是大脑里构建的、模拟真实世界运转的 “内部小世界”。
我们在脑子里先 “预演” 一遍未来,现实里的行动才会跟上。
论文还通过实验验证:如果 AI 模型能学会在 “梦境” 里提前推演未来,它的游戏、决策能力会得到质的飞跃。
人工智能泰斗 Yann LeCun 也提出过相似观点:
人类和动物远超 AI 的快速学习能力,根源就在于这套 “世界常识”。
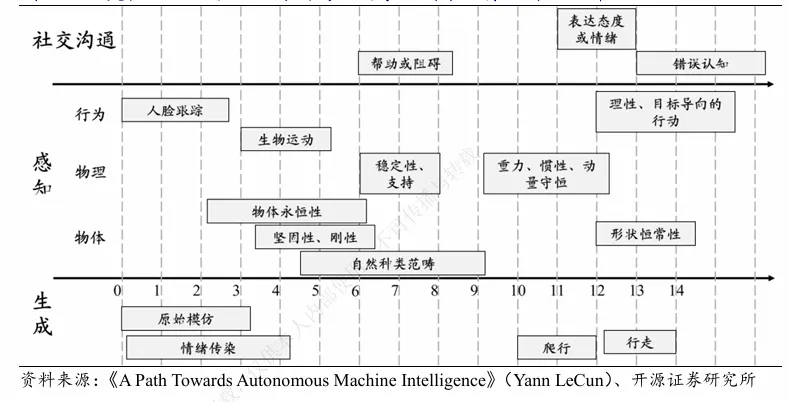
人类婴儿出生后短短几个月,就会自动学会一整套世界运行的底层规则:东西不会凭空消失、物体有重量、重力永远向下、运动有惯性、物体形状不会随便改变…… 这些看不见的常识,就是人类自带的 “世界模型底座”。
靠着这套底座,我们接触任何新事物,都能快速理解、快速预判,而 AI 哪怕看了海量数据,很长一段时间都学不会这种 “与生俱来的常识感”。
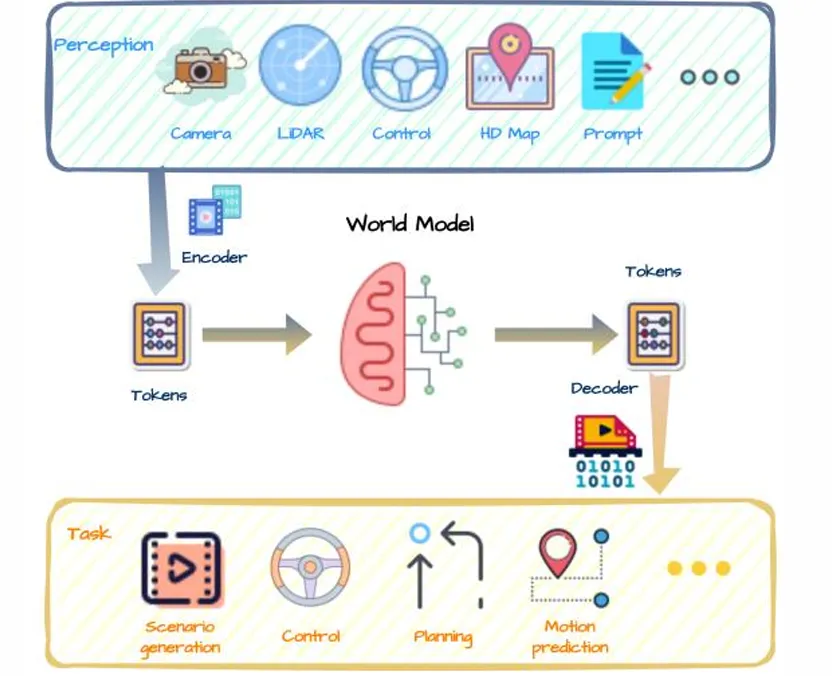
拆解世界模型的底层架构:感知、记忆、控制三件套
一套完整的世界模型,核心由三大模块组成,和人类大脑的工作逻辑几乎一模一样。
相当于我们的眼睛和感官。它不会死板记录画面里的每一个像素,而是会把复杂的现实画面,压缩提炼成抽象信息,比如物体位置、相对关系、运动趋势,就像人类看东西只会抓重点,不会死记绝对尺寸和细节。这个模块一般用变分自编码器(VAE)来实现信息压缩提炼。相当于我们的大脑记忆。它会把之前所有感知到的历史信息串联起来,记住事物变化的规律,同时基于现在的状态,推演预测下一步会变成什么样,还会根据现实结果的反馈,不断修正自己的判断,越变越聪明。相当于我们的手脚和决策。它结合感知到的当下、记忆推演的未来,判断现在应该做出什么动作,来达成想要的结果。三者配合起来,整个 AI 就能像人一样:看懂当下、记住过往、预判未来、做出最优行动。实验数据显示,搭载这套完整世界模型的 AI,在赛车类自主决策任务里,表现远超其他传统 AI 方案。
世界模型,为什么是自动驾驶的必答题?
回到大家最关心的汽车领域:为什么现在整个自动驾驶行业,都在疯狂押注世界模型?
现在自动驾驶已经进入发展 “深水区”,曾经的传统方案逐渐走到瓶颈。过去的自动驾驶,是拆分式工作:单独做图像识别、单独做规控算法、单独做逻辑判断,只能应对规则内、见过的常规路况。
但真实路况千变万化:突然横穿的行人、恶劣天气视线遮挡、极端罕见的长尾危险场景,传统自动驾驶很容易 “卡壳”。
而世界模型,就是自动驾驶的 “能力破局钥匙”。它就相当于给汽车装上了人类级别的 “路况预判大脑”:
- 提前预判周边车辆、行人、障碍物接下来几秒的所有运动趋势,提前规划最优行驶路线,而不是等危险发生了再紧急反应;
- 自主理解现实世界的物理常识,懂重力、懂惯性、懂交通逻辑,面对从没见过的突发场景,也能做出安全合理的决策;
- 自主生成海量仿真路况,完美解决自动驾驶行业最大的痛点之一 —— 真实危险场景数据太少、太难采集、标注成本极高。
具体来说,世界模型给自动驾驶带来三大核心价值:
第一,解决训练数据难题。它可以无限生成逼真、极端、稀有的驾驶场景,给自动驾驶系统做无限次训练,不用冒着真实上路的风险去采集数据;
第二,完成闭环安全测试。生成的仿真场景,可以用来无限次验证自动驾驶算法的可靠性,在虚拟世界里把 bug 全部打磨干净,再落地真实道路;
第三,直接指导自动驾驶行动。成熟的多模态世界模型,可以直接输出完整的驾驶策略,完成路径规划、运动控制全套操作。
同时现在自动驾驶的大趋势,是从传统模块化方案,转向端到端自动驾驶。端到端模式下,算法直接从传感器输入,输出最终车辆控制指令,整个过程不再拆分环节。这种趋势下,传统仿真、验证方案已经跟不上需求,而世界模型,就是目前行业公认的最优解法。
全球大厂扎堆布局,行业落地大爆发
意识到世界模型的颠覆性价值后,全球科技、车企巨头,早已全员下场发力抢跑。
- 特斯拉:在 2023 年 CVPR 国际计算机视觉大会上,公开介绍自家端到端模型,目标搭建完整 4D 神经网络,深度理解真实世界运行规律,落地车载世界模型;
- Wayve.ai:英国头部自动驾驶企业,2023 年发布 GAIA-1 模型,仅靠视频、文本、动作输入,就能生成高度逼真的完整驾驶场景画面;
- 英伟达:在 2024 年 GTC 全球科技大会上,展出了最新世界模型技术进展。它可以把天气、路况、障碍物、道路布局等多维度海量数据输入模型,精准预测未来路况变化,生成极其真实的动态驾驶场景演变。
随着技术持续迭代,未来世界模型,一定会成为自动驾驶系统的标准核心组件,彻底重构整个智能汽车行业。
世界模型的能量,远不止汽车领域。
它本质是让 AI 真正 “看懂、弄懂人类真实世界”,从只会统计、拼接已有数据,升级为可以理解常识、推演未来、自主决策的通用智能。除了智能汽车,机器人、高端制造、仿真测试等众多领域,都会被这一技术彻底赋能。
也正因如此,资本市场、产业端早已提前预判赛道机会,智能汽车、高端制造等相关产业链,都迎来了全新的发展机遇与成长空间。
很多人说,大语言模型,让 AI 学会了 “说话”;而世界模型,会让 AI 真正学会 “看懂和理解这个真实世界”。
我们正在亲历的,不只是一项车载技术的升级,而是整个人工智能从 “感知智能” 走向 “通用认知智能” 的关键转折点。不远的未来,当世界模型真正大规模落地,我们坐上自动驾驶汽车的那一刻,就会真切感受到:AI 已经真的,像人类一样,看懂并预判了这个世界。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
