
在自动驾驶的研发中,进来人们希望寻找一种平衡:既希望模型像人类一样拥有深思熟虑的“思维链”(Chain-of-Thought, CoT),能解释为什么要左转或减速;又要求它反应极快,不能因为“思考”太久而错过刹车时机。
传统的显式思维链虽然聪明,但它必须一个词一个词地吐出推理过程,这种自回归(Autoregressive, AR)的特性带来了巨大的延迟。而之前的隐式推理(Latent CoT)虽然快,但在复杂的驾驶任务中往往表现不佳。
近日,小米具身智能团队(Xiaomi Embodied Intelligence Team)提出了一种名为 OneVL 的新框架,全称为 One-step latent reasoning and planning with Vision-Language explanations。其核心寓意在于实现“一步到位”的潜空间推理与规划,同时保留视觉和语言双重解释能力,旨在打破自动驾驶中“解释性”与“实时性”不可兼得的僵局。

- 论文地址: https://arxiv.org/abs/2604.18486
- 项目主页: https://xiaomi-embodied-intelligence.github.io/OneVL/
- huggingface: https://huggingface.co/papers/2604.18486
为什么之前的隐式推理行不通?
之前的潜思维链方法在自动驾驶上“水土不服”。
像 COCONUT 或 SIM-CoT 这样的方法,主要是针对纯文本任务设计的。它们试图将推理过程压缩进几个连续的向量,即潜令牌(Latent Tokens)中。但自动驾驶不仅仅是语言逻辑,它本质上是一个时空预测任务。
作者观察到:纯语言的潜表征太抽象了。它压缩的是世界的符号化表达,而不是驱动现实的因果动力学。简单来说,模型可能学会了说“前面有车”,但它并没有真正“理解”车辆运动的物理规律。这种“符号化压缩”满足了效率,却丢掉了智能的深度。
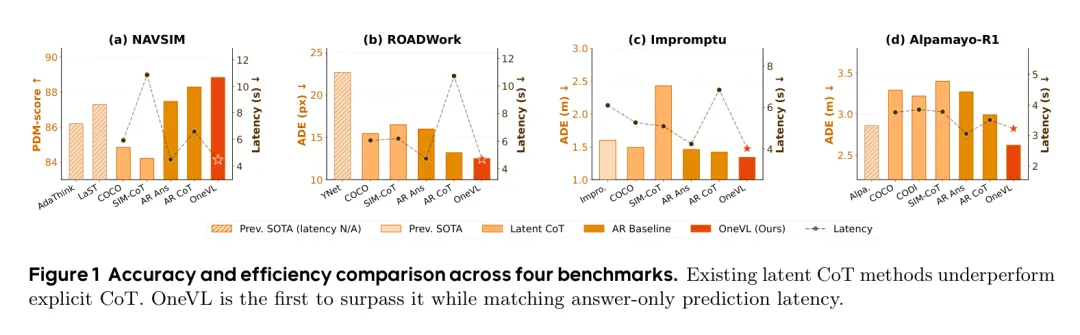 图1展示了OneVL在四大基准测试中不仅超越了显式CoT,还保持了极低的延迟
图1展示了OneVL在四大基准测试中不仅超越了显式CoT,还保持了极低的延迟OneVL:给推理装上“世界模型”
为了解决这个问题,OneVL 引入了一个非常精妙的设计:双模态辅助解码器。
在训练阶段,OneVL 不仅要求潜令牌能还原出推理文字(通过语言辅助解码器),还要求它们能预测出未来 0.5 秒和 1.0 秒的视觉画面(通过视觉辅助解码器)。
 图2对比了三种CoT范式,OneVL通过预填充(Prefill)实现了速度与精度的双赢
图2对比了三种CoT范式,OneVL通过预填充(Prefill)实现了速度与精度的双赢这个视觉解码器实际上扮演了世界模型(World Model)的角色。它强制模型在潜空间内消化道路几何、物体运动和环境变化。如果潜令牌能成功预测出未来的画面,说明它已经捕捉到了物理世界的因果逻辑。这种物理层面的“验证”,正是语言辅助推理所欠缺的“灵魂”。
核心架构与输入输出流程
OneVL 的主干是 Qwen3-VL-4B-Instruct。其核心在于将推理路径路由到紧凑的潜令牌中,并由辅助解码器进行监督。
- Input(输入):当前帧图像、自车状态(Ego State)、导航命令(Command)以及历史轨迹(Historical Trajectory)。
- 潜空间处理:在模型生成答案之前,插入了 4 个视觉潜令牌(Visual Latent Tokens, )和 2 个语言潜令牌(Language Latent Tokens, )。
- 主要输出:未来轨迹点(Trajectory Waypoints)。
- 辅助输出(仅训练或审计时):人类可读的 CoT 推理文本、未来帧视觉预览。
 图3详细展示了OneVL的架构,训练时使用双解码器,推理时则丢弃它们以保证速度
图3详细展示了OneVL的架构,训练时使用双解码器,推理时则丢弃它们以保证速度三阶段训练:稳扎稳打的进化
让一个模型同时学会开车、写推理还要预测未来,这在优化上是个挑战。研究团队设计了一个三阶段的训练流水线:
- 阶段 0:主模型预热。让视觉语言模型(VLM)先学会基本的轨迹预测,并在对应位置生成潜令牌。
- 阶段 1:辅助解码器预热。固定主模型,专门训练两个辅助解码器,让它们学会从潜令牌中提取文字和画面。此时视觉解码器开始展现其作为“世界模型”的预测能力。
- 阶段 2:联合端到端微调。全量训练,让辅助解码器的梯度回流,真正塑造潜空间的表征能力。
这种策略避免了训练初期的“梯度冲击”,确保了模型能够收敛到最优解。消融实验显示,如果不采用这种三阶段策略,模型的性能会发生灾难性下降(PDM-score 从 88.84 跌至 67.13)。
实验结果:速度与精度的双重提高
OneVL 在 NAVSIM、ROADWork、Impromptu 和 APR1 四个主流基准上都展现了极强的统治力。
在最受关注的 NAVSIM 榜单上,OneVL 取得了 88.84 的 PDM-score。这个分数不仅超过了此前的 SOTA 模型 AdaThinkDrive(86.20),更是第一次在潜空间推理中超越了显式 CoT(88.29)。
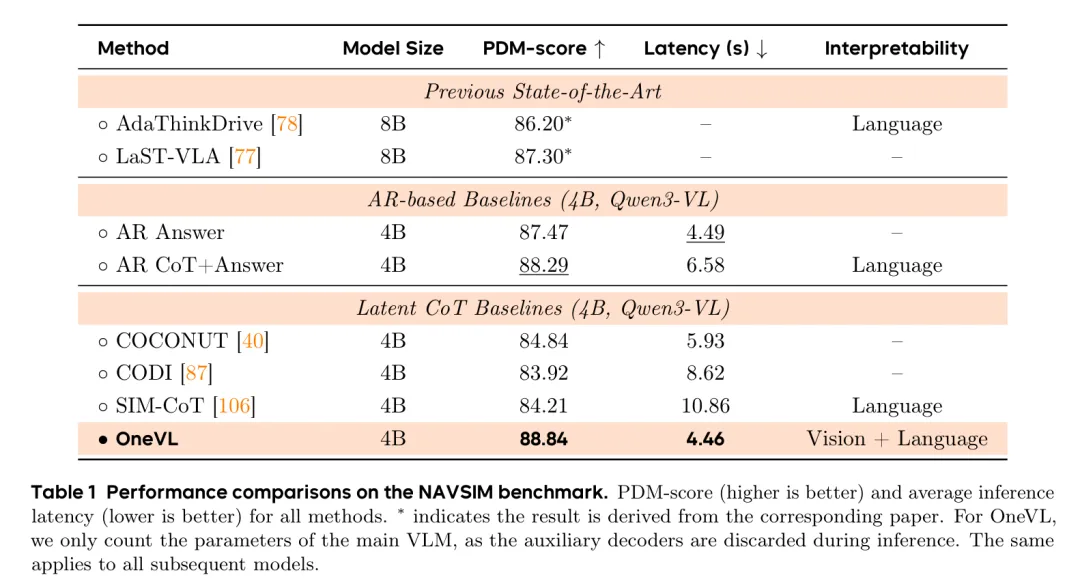 表1展示了NAVSIM上的详细对比,OneVL在精度和延迟上都表现优异
表1展示了NAVSIM上的详细对比,OneVL在精度和延迟上都表现优异延迟表现当然是重头戏。得益于预填充推理(Prefill Inference)技术,OneVL 在推理时将潜令牌作为 Prompt 的一部分并行处理,其延迟仅为 4.46s。这与完全不进行推理的“仅答案”模型(4.49s)几乎一样快,而比显式 CoT 模型(6.58s)快了近 1.5 倍。
在处理施工区域等复杂场景的 ROADWork 任务中,OneVL 的优势更加明显,其推理速度比显式 CoT 快了 2.3倍。
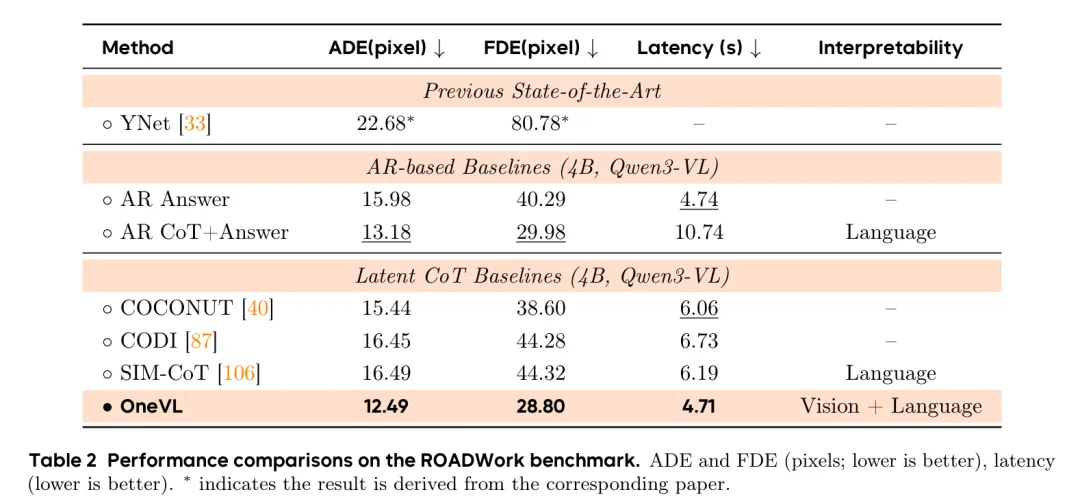 表2展示了ROADWork上的性能,OneVL在ADE和FDE指标上均大幅领先
表2展示了ROADWork上的性能,OneVL在ADE和FDE指标上均大幅领先此外,在 Impromptu 和 APR1 等长尾场景和复杂因果链任务中,OneVL 同样刷新了性能标杆,证明了视觉世界模型监督带来的泛化能力。
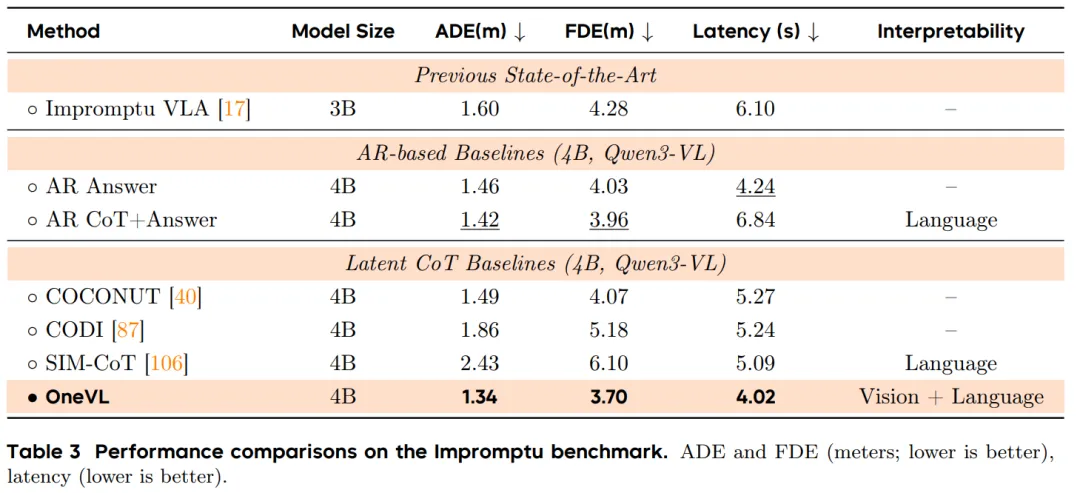
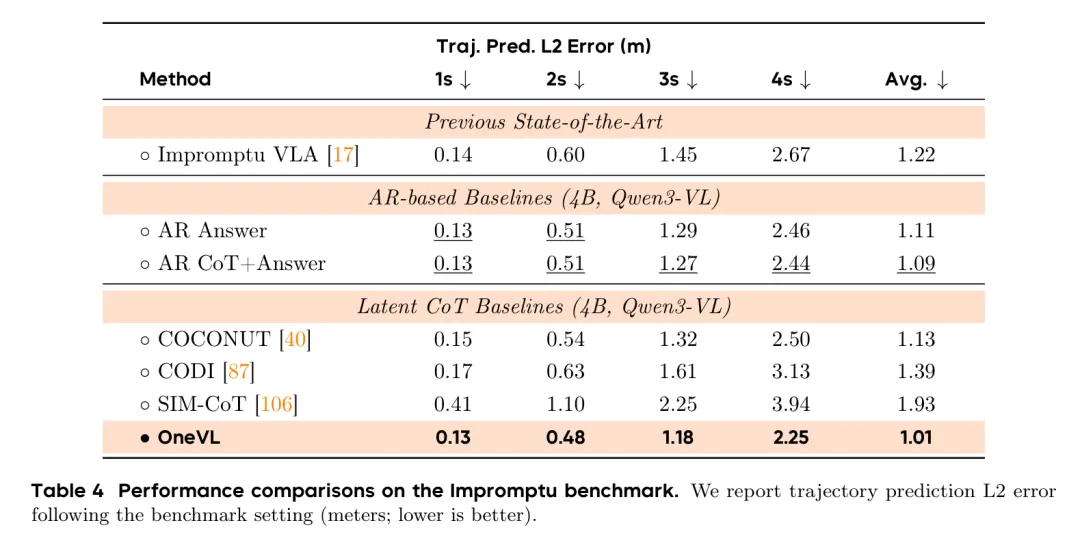 表3/表4展示了Impromptu基准上的表现,OneVL在轨迹误差上达到了最低
表3/表4展示了Impromptu基准上的表现,OneVL在轨迹误差上达到了最低看得见的推理:不只是黑盒
OneVL 另一优点是它的可解释性。虽然我们在推理时丢弃了辅助解码器以追求速度,但在需要审计或调试时,我们可以随时挂载解码器,看看模型当时在“想”什么,以及它“预见”到了什么样的未来。
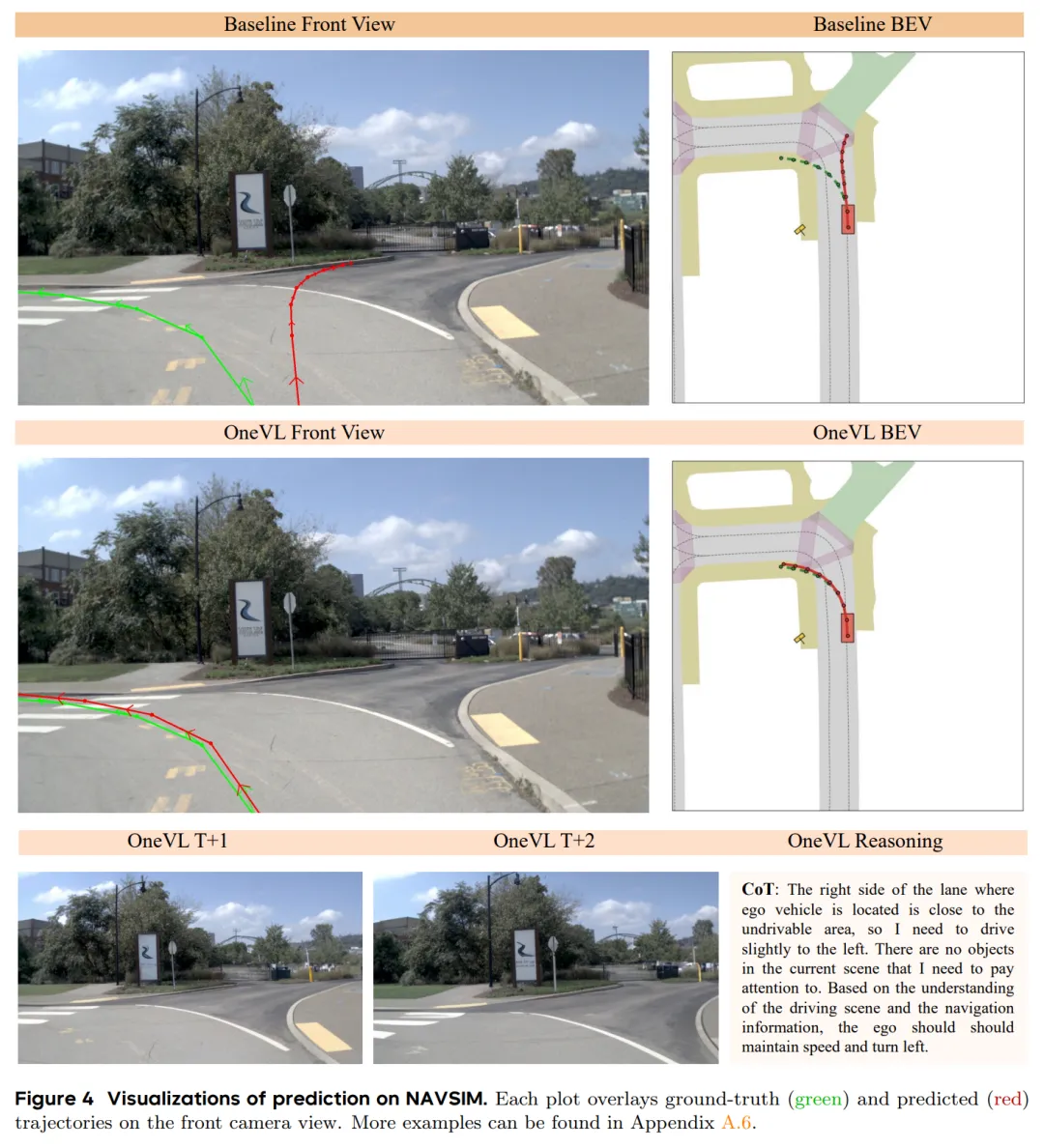 图4展示了OneVL在NAVSIM上的可视化,模型不仅能预测轨迹,还能生成连贯的推理文字和未来帧预览
图4展示了OneVL在NAVSIM上的可视化,模型不仅能预测轨迹,还能生成连贯的推理文字和未来帧预览从图 4 中可以看到,OneVL 能够准确识别出车道边缘的不可行驶区域,并给出“需要稍微向左行驶”的合理建议。
对于实时部署的测试,论文还尝试了挂载一个轻量级的 MLP 回归头,将推理延迟进一步压低到了 0.24s(约 4.16 Hz),这已经非常接近真实道路部署的要求了。
一点思考
当模型被强制将冗长的推理过程压缩进几个紧凑的向量中时,它不得不抛弃那些无关紧要的废话,转而提取最核心的因果特征。而视觉辅助(世界模型)的加入,则为这种压缩提供了一个坚实的物理底座。

 入群加好友(v:xiao-ma-baoli),请备注你感兴趣的技术方向
入群加好友(v:xiao-ma-baoli),请备注你感兴趣的技术方向
