
🐉 龙哥读论文知识星球来了!公众号每日8篇拆解不够看?星球无上限更AI领域论文、资讯、招聘、招博、开源代码,一站式干货,每日2分钟刷完即赚!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
自动驾驶最怕啥?不是复杂路口,而是下雨天、夜晚、雪地这种“看不清路”的时候。现有的BEV感知网络一遇到标线缺失就抓瞎,强行训练增强效果有限。丰田的这篇工作就很聪明,它不去改模型结构,而是做了一个“外挂”模块——LG-FA。这个模块像个智能的拼图高手:先用历史帧的感知结果拼出一张稀疏的全局向量地图,再通过带类别约束的定位找到自己的准确位置,然后用这张地图补上当前帧缺失的标线,最后把自车和障碍物重投影到补全后的地图上。整个过程不需要修改骨干网络,也不需要昂贵的HD地图,就像给感知系统配了一副“夜视镜”。实验结果也很亮眼,在nuScenes数据集上,三种标线类别的完成率都接近100%,比单纯用位姿合并的baseline平均提升了70%。实用性和创新性兼备,值得关注!
原论文信息如下:
论文标题:
Localization-Guided Foreground Augmentation in Autonomous Driving
发表日期:
2026年04月
发表单位:
Toyota Motor Corporation, Japan; Toyota Motor North America, USA
原文链接:
https://arxiv.org/pdf/2604.18940v1.pdf
恶劣天气下,自动驾驶的“眼睛”如何更锐利?
自动驾驶汽车在路上跑,最怕啥?不是复杂的十字路口,也不是突然窜出的行人,而是——下雨、下雪、大雾或者夜晚。这些恶劣天气下,摄像头拍到的车道线、路沿、人行横道线这些“几何路标”要么变得断断续续,要么干脆“隐身”。没有了这些结构线索,车辆就像蒙上了眼睛,不仅自己定位不准,对周围环境的感知也大打折扣。
传统做法是通过训练时的数据增强或者域自适应来提高模型鲁棒性,但这些方法只是在图像或特征层面“打补丁”,没法从根本上去恢复那些丢失的全局道路几何结构。而且,高清地图(HD Map)虽然能提供厘米级的精确结构,但建图和维护成本高得吓人,大规模部署基本不现实。
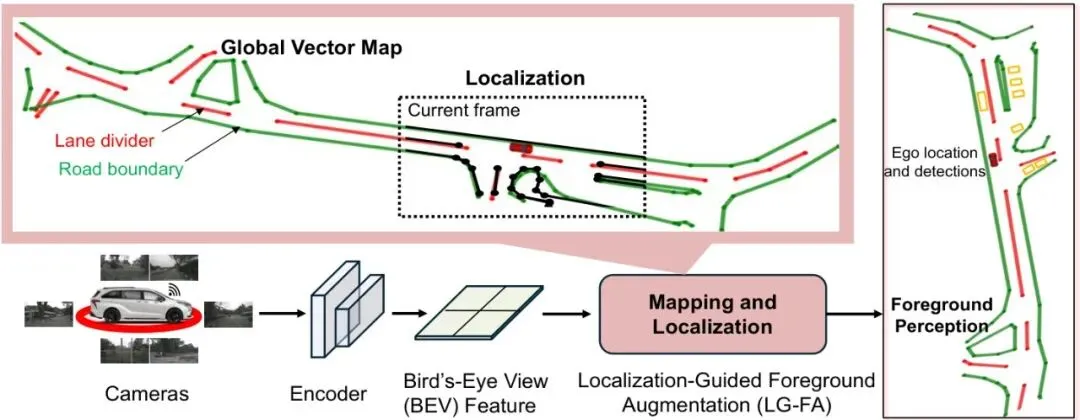
那么,有没有一种既轻量又有效的方法,能在不修改现有模型的前提下,帮自动驾驶汽车在恶劣天气下“画”出完整的地面标线呢?丰田的工程师们给出了一个漂亮的答案——Localization-Guided Foreground Augmentation(LG-FA),翻译过来就是“定位引导的前景增强”模块。它就像一个聪明的拼图高手,利用历史帧的信息拼出全局地图,然后帮你找到准确的位置,再补上缺失的标线,最后把感知结果都对齐到这幅完整的地图上。整个过程完全即插即用,不需要改动现有的神经网络骨干。图1:雨雪天气下车道线模糊或缺失的场景。LG-FA将当前帧与轻量级全局向量地图对齐,补全连续的车道分隔线(红色)和道路边界(绿色),为下游任务提供稳定的增强前景感知。即插即用!LG-FA模块实现“无痛”鲁棒性升级
你可能要问:这个LG-FA到底有什么神奇之处?简单来说,它不改变你车上已有的感知网络(比如经典的BEV感知模型),而是像一个“外挂”一样,在推理阶段偷偷干活。论文的作者来自丰田汽车公司和丰田北美研究所,他们显然深谙工程落地的痛点——改动骨干网络会带来巨大的验证成本和算力开销,而一个轻量级的后处理模块则容易部署得多。
LG-FA的核心思路是:利用车辆行驶过程中持续不断产生的BEV感知结果(也就是每一帧预测出的车道线、路沿等),一点点构建出一张轻量级的全局向量地图。然后,当车辆行驶到某个位置时,通过带类别约束的几何对齐,确定自车在全局地图中的精确位姿,再借助这个完整的全局地图,把当前帧中那些被恶劣天气“吃掉”的标线补回来。最后,把自车和检测到的障碍物都“重投影”到补全后的地图上,形成一幅“增强前景感知”画面。整个过程就像是给感知系统配了一副“夜视镜”,让它即使在漆黑或大雨中也“看”得清楚。
值得一提的是,LG-FA的三个关键步骤都是模块化的,可以单独使用。比如,如果你只想要更好的定位结果,可以只跑定位和线补全;如果你只需要全局地图,也可以只做地图构建。这种灵活性让它在实际应用中非常友好。一张图看懂LG-FA:从全局地图到前景增强
图2:提出的LG-FA框架整体架构。多相机输入首先被编码为BEV表示。LG-FA通过增量聚合阶段,从每帧车道线和拓扑预测中逐步构建稀疏全局向量地图。在线推理时,构建的地图通过带类别约束的几何对齐来估计自车位姿,同时改善车道级定位精度并补全缺失的局部拓扑。增强后的前景表示然后被送入下游模块用于运动预测和决策。这种定位引导的增强将在线感知与轻量级地图先验连接起来,有助于在单帧几何线索稀疏或碎片化时保持时间一致性。
架构图清晰地展示了三条流水线:最左边是感知网络,它处理多相机输入并输出BEV下的向量化地图预测(包括车道分隔线、路沿、人行横道)。中间是LG-FA模块的三个核心组件:① 全局向量地图构建(在线增量融合);② 定位与线补全(带类别约束的对齐+补全);③ 增强前景感知(将自车和障碍物重投影到补全后的地图上,形成统一的全局参考系)。右侧是下游任务,如运动预测和规划。整个流程形成了一个闭环:感知产生地图,地图辅助定位,定位帮助补全,补全后的地图又改善了感知的几何完整性。
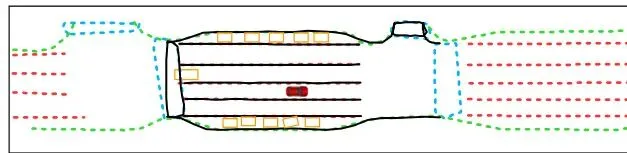
下面这张图则直观地展示了“增强前景感知”的最终效果——自车位置(红色图标)和检测到的障碍物(黄色框)都被精确地重投影到了补全后的地图上:图3:自车位置(红色图标)和检测到的障碍物(黄色框)被重投影到补全后的地图上。彩色虚线表示构建的全局向量地图,黑色实线表示当前帧的不完整地图预测。它们共同构成增强前景感知。自车定位与缺失标线的“完形填空”
LG-FA最精彩的部分在于它如何把定位和线补全这两个任务巧妙地结合在一起。我们先说说全局向量地图的构建。
在车辆行驶过程中,每一帧BEV感知网络都会输出当前帧的向量化地图,包括三条类别的多段线:人行横道(pedestrian crossing)、车道分隔线(divider)和道路边界(boundary)。LG-FA利用外部提供的自车位姿参考(比如GNSS/IMU),把这些当前帧的多段线投影到全局坐标系下,然后通过一个增量融合算法,逐步将这些片段拼接成一个稀疏但连贯的全局向量地图。这个地图不需要像HD地图那么精细,但足以提供稳定的几何先验。
融合时,对于每个类别,使用一个对称最近邻差异度量来判断当前帧的多段线是否与已有的全局多段线匹配。如果匹配上,就合并更新;如果没匹配上,就新建一条全局多段线。短小的孤立片段会被抑制,以减少噪声。合并后还会进行端点邻接检查和拓扑保持操作(比如近距离端点连接),以及重采样和简化,保证地图既紧凑又几何保真。
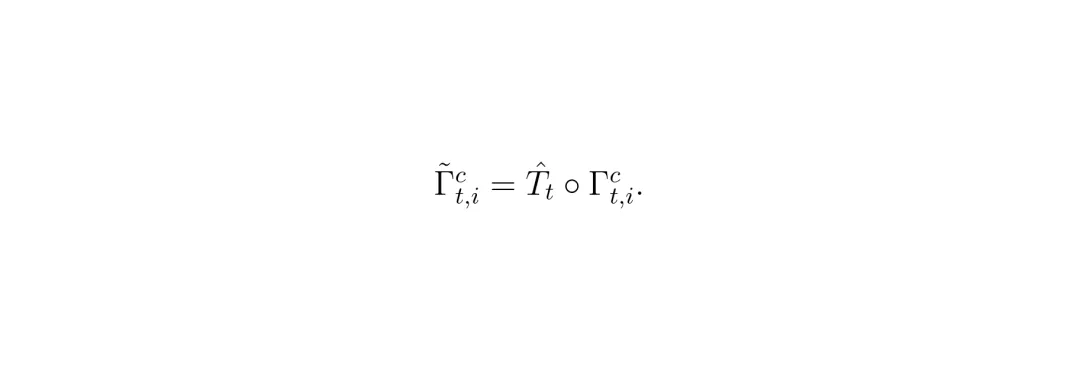 其中,
其中,Γ̂是当前帧第i个类别c的多段线,Ṫ̂_t是外部提供的自车位姿,∘表示坐标变换。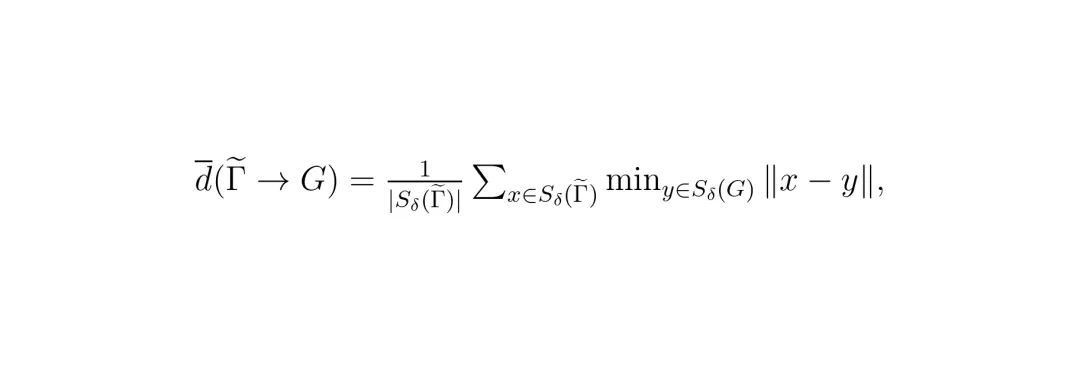
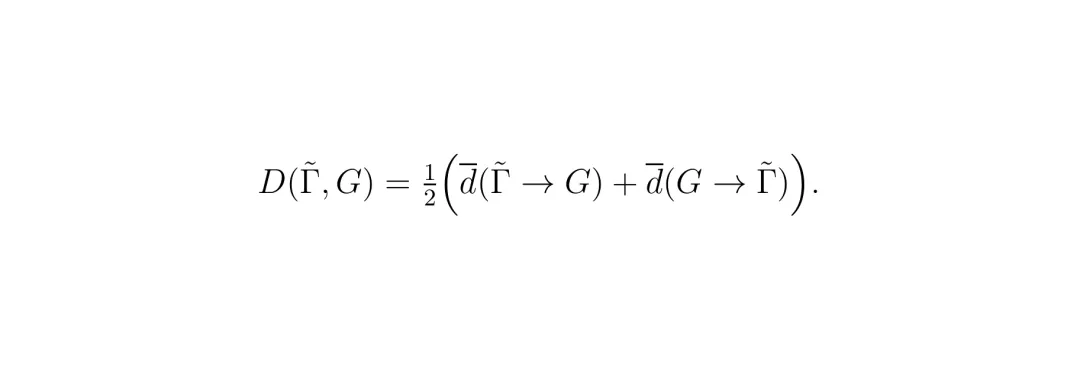 这里,Sδ表示按照步长δ采样,d→是单向平均距离,D是对称平均距离,用于衡量两条多段线的几何相似度。
接下来是定位与线补全。这是整个模块的“灵魂”。当车辆行驶到某个位置时,当前帧的BEV预测可能因为恶劣天气而残缺不全。LG-FA的做法是:先利用之前构建好的全局向量地图,通过一个“带类别约束的几何对齐”算法,精准估计出自车在当前全局地图中的位置(包括平移和航向角)。这个算法本质上是一种改进的ICP(Iterative Closest Point,迭代最近点),但它加入了类别约束:同一类别的点才能互相匹配(比如车道线只跟车道线对齐),并且使用了双向损失函数(前向从当前帧到全局,后向从全局到当前帧),提高了鲁棒性。
定位的目标是优化参数θ = (tx, ty, φ),使当前帧的采样点与全局地图的匹配误差最小。前向误差(点到线段):
这里,Sδ表示按照步长δ采样,d→是单向平均距离,D是对称平均距离,用于衡量两条多段线的几何相似度。
接下来是定位与线补全。这是整个模块的“灵魂”。当车辆行驶到某个位置时,当前帧的BEV预测可能因为恶劣天气而残缺不全。LG-FA的做法是:先利用之前构建好的全局向量地图,通过一个“带类别约束的几何对齐”算法,精准估计出自车在当前全局地图中的位置(包括平移和航向角)。这个算法本质上是一种改进的ICP(Iterative Closest Point,迭代最近点),但它加入了类别约束:同一类别的点才能互相匹配(比如车道线只跟车道线对齐),并且使用了双向损失函数(前向从当前帧到全局,后向从全局到当前帧),提高了鲁棒性。
定位的目标是优化参数θ = (tx, ty, φ),使当前帧的采样点与全局地图的匹配误差最小。前向误差(点到线段):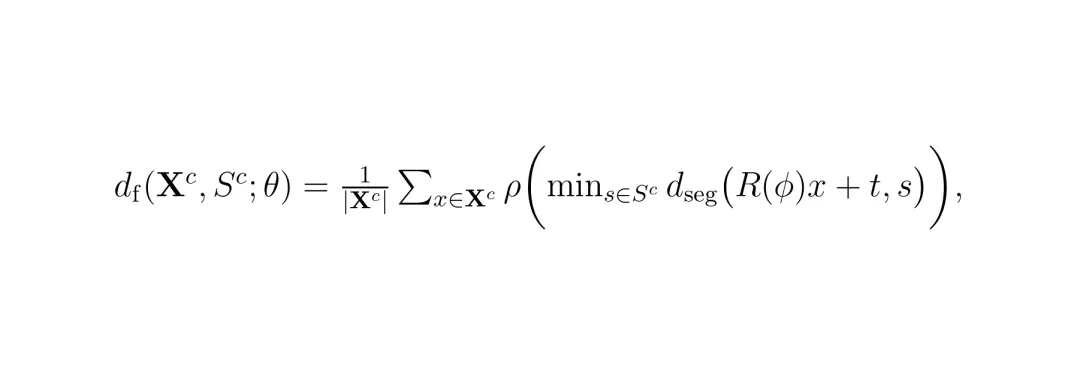
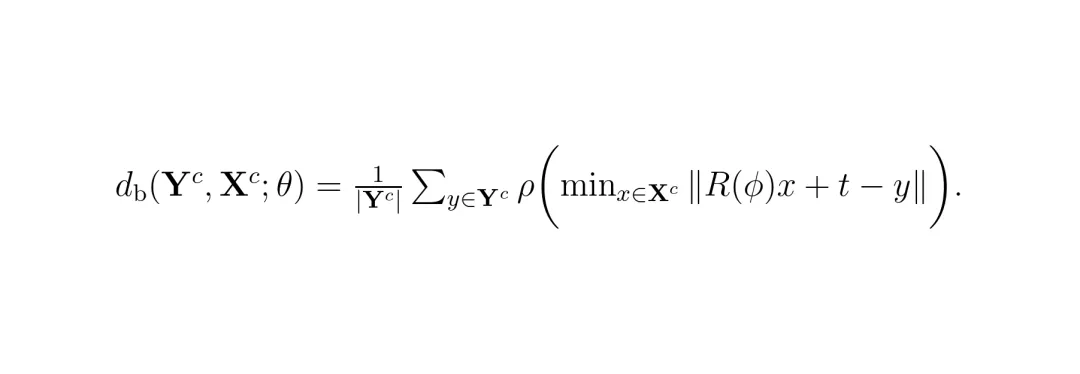
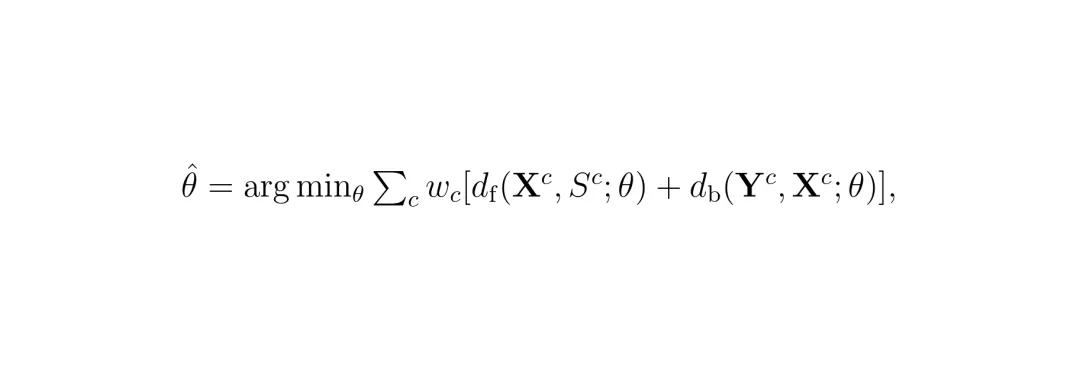 其中wc是类别权重,ρ是鲁棒损失函数,用来抑制离群点的影响。整个优化过程通过算法1描述的迭代过程求解,采用粗到精的策略:先用道路边界类别做粗对齐,再用所有类别做精细对齐。
定位完成后,接下来是线补全——也就是“完形填空”。将当前帧的向量利用估计出的位姿变换到全局坐标后,检查全局地图中哪些路段没有被当前帧覆盖。对于短的缺口(小于阈值η)直接桥接;对于长缺口,从全局地图中截取对应部分拼接上去,同时保持端点连续性和切线方向一致。这样,最终得到的线补全地图就拥有了连续的车道线和路沿。
其中wc是类别权重,ρ是鲁棒损失函数,用来抑制离群点的影响。整个优化过程通过算法1描述的迭代过程求解,采用粗到精的策略:先用道路边界类别做粗对齐,再用所有类别做精细对齐。
定位完成后,接下来是线补全——也就是“完形填空”。将当前帧的向量利用估计出的位姿变换到全局坐标后,检查全局地图中哪些路段没有被当前帧覆盖。对于短的缺口(小于阈值η)直接桥接;对于长缺口,从全局地图中截取对应部分拼接上去,同时保持端点连续性和切线方向一致。这样,最终得到的线补全地图就拥有了连续的车道线和路沿。
算法1:带类别约束的定位
输入:每类当前帧采样点{X^c},每类全局采样点{Y^c},每类全局线段{S^c},初始位姿θ0,最大迭代次数K,收敛阈值ε_conv
输出:估计的位姿θ
1: θ ← θ0
2: for k = 1 to K do
3: P ← BuildCorr(θ)
4: if P = ∅ then break
5: w ← RobustWeights(P, θ)
6: θ_new ← WeightedProcrustes(P, w)
7: if PoseDiff(θ_new, θ) < ε_conv then
8: θ ← θ_new; break
9: end if
10: θ ← θ_new
11: end for
12: return θ
BuildCorr函数根据当前位姿建立类别受限的对应关系,RobustWeights根据残差计算权重,WeightedProcrustes求解加权后的刚体变换。实验结果亮眼:完成率飙升至近100%
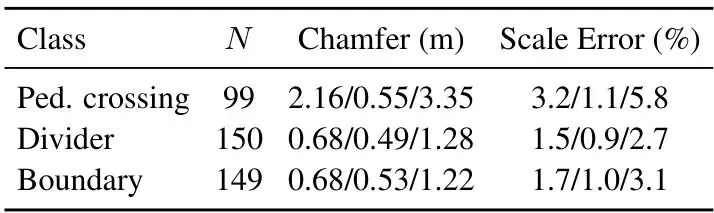
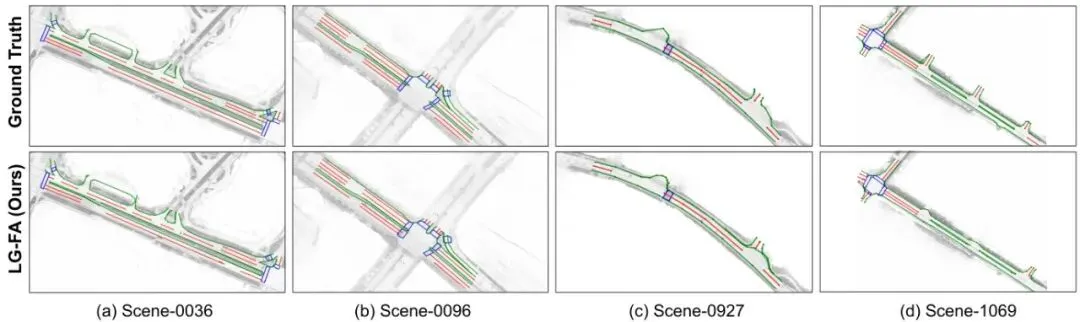
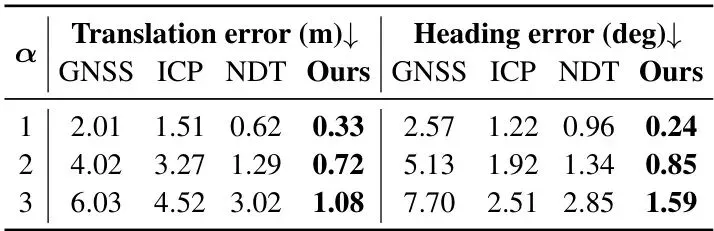
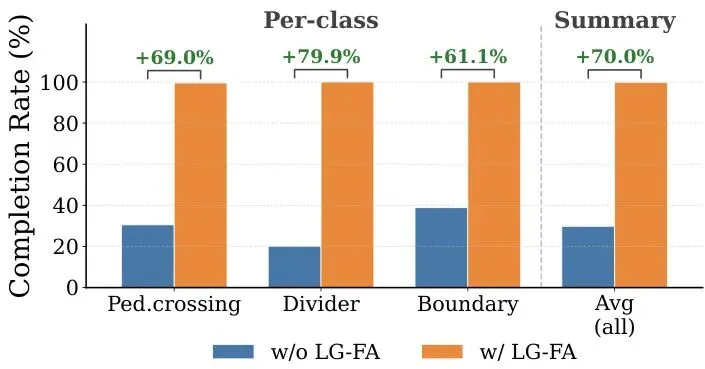
论文在nuScenes数据集上进行了全面的实验验证。我们先看全局向量地图的质量——这是后续定位和补全的基础。表1:nuScenes验证集上的全局向量地图质量。报告每类的均值/中位数/90百分位数(仅在有ground truth和预测共存的场景上计算)。其中,Chamfer距离衡量几何精度,Scale Error衡量尺度稳定性。可以看出,车道分隔线和道路边界的中位数Chamfer距离均在0.5米左右,90百分位数在1.3米以内,说明地图构建精度很高。人行横道中位数0.55米,但均值较大(2.16米),说明少数困难场景拖累了平均表现。尺度误差方面,三类的中位数都在1.1%以下,表明地图的全局尺度非常稳定。下面的可视化图展示了构建的全局地图(彩色虚线)与真值(同样颜色方案)的对比,可以看到在直道和缓弯上高度吻合,在复杂交叉口也能大致对齐,只有少量遮挡或磨损区域存在微小偏移:图4:在nuScenes四个场景中,构建的全局向量地图与真值的定性对比。红色为车道分隔线,绿色为道路边界,蓝色为人行横道。接下来是定位精度的测试。论文对比了LG-FA的定位模块与经典的ICP和NDT方法,在不同噪声水平下的表现:表2:定位鲁棒性与噪声尺度α的关系(σxy=1m,σθ=2°乘以α)。GNSS表示带噪声的初始位姿。可以看到,在初始噪声较小(α=1)时,ICP和NDT表现尚可,但LG-FA的平移误差仅0.33m,航向误差0.24°,大幅优于其他方法。随着噪声加大(α=2,3),ICP和NDT迅速恶化,而LG-FA依然保持稳定(α=3时平移0.72m,航向1.59°),证明了其强大的鲁棒性。下图展示了几种典型场景下的定位与线补全效果,包括晴天、夜晚和雨天,可以看到LG-FA成功补全了缺失的标线:图5:在nuScenes验证集多种条件下LG-FA定位与线补全的可视化。每个案例展示了当前帧向量地图(黑色实线)与全局地图(彩色虚线)的对齐,以及缺失结构的恢复,显著改善了人行横道、车道分隔线和道路边界的连续性。最后看前景感知的量化评估——即完成率(Completion Rate),衡量当前帧中与全局地图匹配上的标线比例。下图显示了LG-FA相比纯位姿合并(w/o LG-FA)的显著提升:图6:在nuScenes验证集(150个场景)上,纯位姿基线(w/o LG-FA)与完整LG-FA管线的完成率对比。LG-FA一致地提升了所有三个类别的几何完整性,尤其在行人横道、车道分隔线和道路边界上分别提升了69.0%、79.9%和61.1%。实际上,LG-FA将所有三个类别的完成率都推到了接近100%,而基线不到50%。这个提升非常惊人,意味着LG-FA几乎完美地补全了恶劣天气下缺失的标线。论文还展示了一个下游规划的示例,验证LG-FA对规划模块的支撑作用:图7:基于LG-FA增强前景感知的下游规划定性示例。预测的物体轨迹和规划的自车路径叠加在增强的车道线和道路边界上。左:前视相机视图;右:BEV视图。
综上所述,LG-FA在定位精度、线补全质量和前景感知完成率上都取得了非常优异的结果,而且完全不需要修改感知骨干网络,真正做到“即插即用”。
龙迷三问
LG-FA模块需要事先构建好全局地图吗?不需要。LG-FA在行车过程中实时、增量地构建全局向量地图。它利用已有的BEV感知网络输出的每一帧预测,逐步融合成一张稀疏的全局地图。第一次使用时会有一段“预热”期,但很快就能积累足够多的结构信息。之后的地图会随着车辆行驶不断更新和优化。所以不需要提前采集所有数据。
LG-FA中的“类别约束”具体指什么?为什么重要?类别约束意味着在定位和线补全过程中,只允许相同语义类别的几何元素进行匹配和融合。比如,当前帧预测的车道分隔线只能与全局地图中的车道分隔线匹配,不能与道路边界或人行横道匹配。这样做的好处是避免了不同类别的误匹配,尤其在恶劣天气下某些类别可能非常稀疏时,能有效提高对齐的鲁棒性和精度。
LG-FA对感知网络的输出有什么要求?要求感知网络能输出每帧的向量化地图,包括至少三种类别(人行横道、车道分隔线、道路边界)的多段线,并且最好能提供每条多段线的持久化ID(persistent ID)。如果ID可用,地图融合会非常简单;如果没有ID,LG-FA会通过几何匹配自动关联。此外,感知网络输出的多段线顶点坐标应在自车BEV坐标系下。LG-FA对感知网络本身没有任何其他约束,因此可以与绝大多数BEV感知方法配合使用。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆
LG-FA的创新点在于将在线地图构建、定位增强和前景感知补全有机融合为一个即插即用的推理模块,避免了昂贵的高清地图依赖和骨干网络修改。思路新颖,充分体现了工程与算法的结合。
实验合理度:★★★★☆
实验设计严谨,包括地图质量、定位鲁棒性、完成率提升等多维度评估,对比了经典ICP和NDT方法,定量结果和定性可视化都很充分。唯一略遗憾的是缺少与更多端到端方法的直接对比,但考虑到LG-FA是模块而非整网络,目前的对比已足够有说服力。
学术研究价值:★★★★☆
论文揭示了一个重要的方向:利用轻量级地图先验来增强恶劣天气下的感知,而不是一味追求训练数据增强或模型复杂度。这个方法启发性强,能够引导后续研究关注“推理时”的几何自愈能力。
稳定性:★★★★☆
LG-FA在多种噪声水平和恶劣天气条件下都表现出一致的性能提升,算法收敛稳定。不过其稳定性高度依赖感知网络的质量和全局地图的逐渐积累,在极端的从未见过场景下可能会有问题(比如地图从未覆盖的区域)。
适应性以及泛化能力:★★★★☆
模块设计与具体网络无关,理论上可以适配任何输出向量化地图的BEV感知方法。当前实验仅基于nuScenes数据集,但方法本身不假设任何特定地理位置,因此有望泛化到其他场景。对新增车道线类别也容易扩展。
硬件需求及成本:★★★☆☆
LG-FA本身是轻量级的,仅涉及少量几何运算和迭代优化,不需要GPU,可以在CPU上实时运行。但它的前置条件是感知网络必须已经完成BEV推理,而BEV推理本身通常需要较大算力。整体系统硬件需求由感知网络决定,LG-FA附加成本很低。
复现难度:★★★★☆
论文给出了清晰的算法伪代码和详细参数设置(步长、阈值等),实验设置透明。但完整复现需要原始感知网络的输出,而该网络的训练代码未公开。好在LG-FA模块本身实现简单,基于典型ICP方法扩展即可,复现核心逻辑不算难。
产品化成熟度:★★★☆☆
LG-FA目前是推理模块,但结合成熟的BEV感知网络,可以很快在产品中试用。主要障碍是对感知网络输出质量的依赖——如果感知网络在高动态场景下出现严重错误,LG-FA的补全也会受影响。此外,全局地图的增量更新需要处理大规模行驶数据时的存储和查询效率问题,论文尚未讨论。
可能的问题:论文缺少与端到端感知增强方法(如基于Transformer的时序融合)的直接对比;全局地图依赖初始的GNSS/IMU位姿,如果初始位姿偏差过大,地图构建会失败;对长时运行下的地图退化(如重复区域)没有讨论。
[1] P. J. Besl and N. D. McKay. A method for registration of 3-D shapes. IEEE TPAMI, 1992.[2] M. Magnusson et al. The three-dimensional normal-distributions transform — an efficient representation for registration, surface analysis, and loop detection. Doctoral thesis, 2009.[3] H. Caesar et al. nuScenes: A multimodal dataset for autonomous driving. CVPR, 2020.[4] C. Campos et al. ORB-SLAM3: An accurate open-source library for visual, visual-inertial, and multimap SLAM. IEEE TRO, 2021.[5] Y. Lu et al. Cooperative localization for autonomous driving with local and global mapping. IROS, 2019.[6] J. Ziegler et al. Making Bertha drive—An autonomous journey on a historic route. IEEE Intelligent Transportation Systems Magazine, 2014.[8] S. Hu et al. ST-P3: End-to-end vision-based autonomous driving via spatial-temporal feature learning. ECCV, 2022.[9] Y. Hu et al. Planning-oriented autonomous driving. CVPR, 2023.[10] B. Jiang et al. VAD: Vectorized autonomous driving. CVPR, 2023.[11] Y. Zhang et al. MapUnveiler: Inverting the black-box for open-world map generation. CVPR, 2024.[13] Q. Li et al. HDMapNet: An online HD map construction and evaluation framework. ICRA, 2022.[14] B. Liao et al. MapTR: Structured modeling and learning for online vectorized HD map construction. ICLR, 2023.[16] Y. Liu et al. VectorMapNet: End-to-end vectorized HD map learning. CoRL, 2022.[20] Z. Li et al. ViDAR: Vision-based differentiable architecture for 3D object detection and tracking. CVPR, 2024.[22] Z. Liu et al. StreamMapNet: Streaming mapping network for real-time vectorized map construction. NeurIPS, 2023.[24] Y. Li et al. Domain generalization for vision-based autonomous driving in adverse weather. ICCV, 2023.*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

👀 想和龙哥一起追踪最前沿的自动驾驶感知技术?扫码加入龙哥读论文粉丝群,与各路高手切磋,一起完成自动驾驶的“缺线填空”!
欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:自动驾驶+地点+学校/公司+昵称(如 自动驾驶+上海+清华+龙哥),根据格式备注,可更快被通过且邀请进群。
『龙哥读论文』微信群目前包含:图像处理、大模型及智能体、自动驾驶及机器人、AI医疗及AI金融5个群







 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
