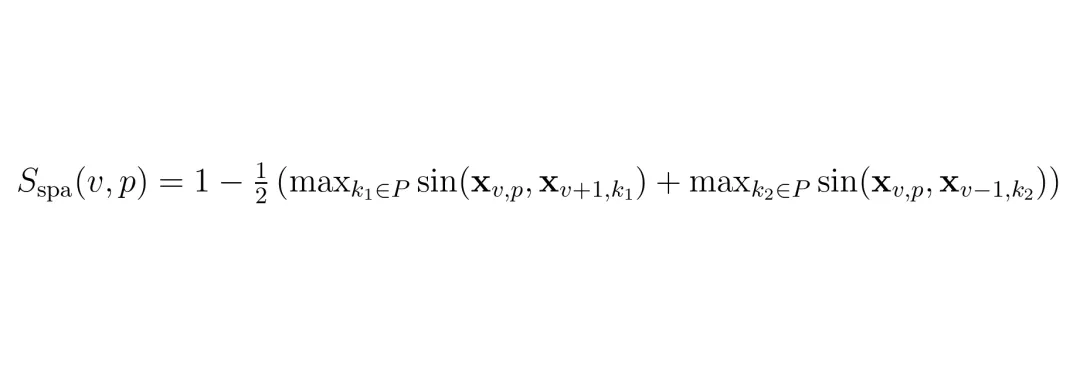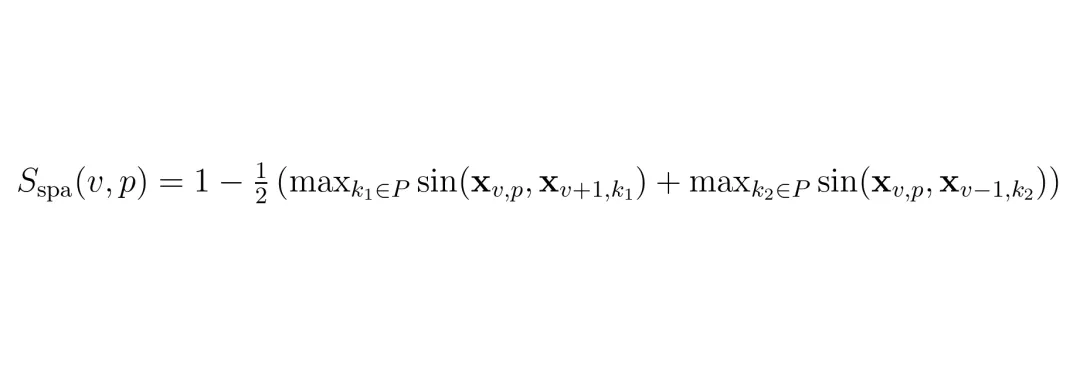龙哥推荐理由:
当前自动驾驶VLM模型面临巨大的算力瓶颈,主要来源于多视角、多帧的输入带来的海量视觉token。现有的剪枝方法大多针对单图设计,忽视了自动驾驶场景中固有的时空冗余。来自中科院等机构的研究者提出了ST-Prune,这是一个优雅且高效的解决方案,通过“运动感知”和“环视几何”两个视角,在无需重新训练的情况下,实现极致的token压缩。本文创新性强,实验扎实,在四个主流自动驾驶基准上全面超越现有方法,实用性极高。
原论文信息如下:
论文标题:
ST-Prune: Training-Free Spatio-Temporal Token Pruning for Vision-Language Models in Autonomous Driving
发表日期:
2026-04-22
发表单位:
中国科学院大学、中国科学院自动化研究所、Carizon
原文链接:
https://arxiv.org/pdf/2604.19145v1.pdf
自动驾驶VLM的算力瓶颈:时空冗余的“诅咒”
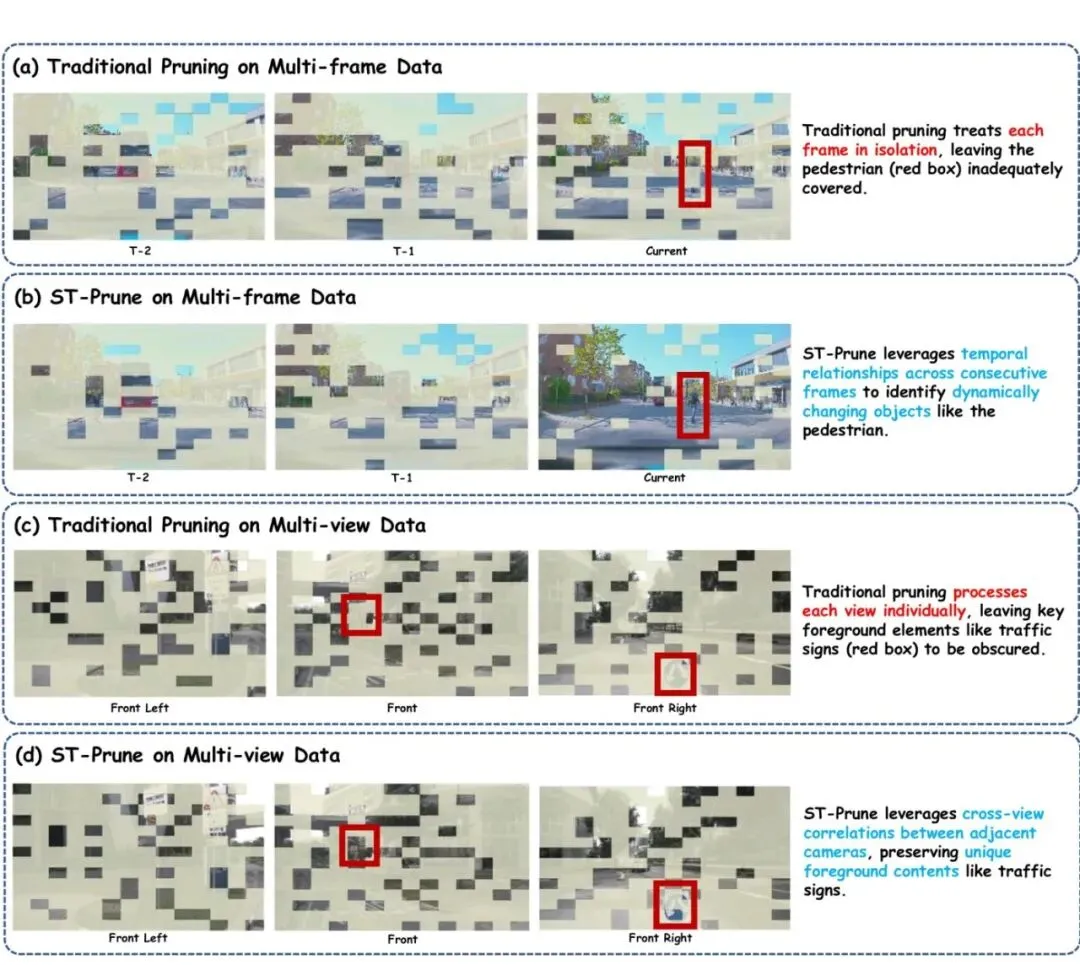
大伙儿都知道,传统的感知方案(目标检测、语义分割)已经不够看了,顶级的玩家都在搞端到端——直接用大模型(Vision-Language Models, VLMs)来做感知、预测、规划一体化。特斯拉的FSD、国内的各种“无图智驾”,背后都有VLM的影子。一辆自动驾驶车,通常装有6个甚至更多的环视摄像头,每个摄像头每秒要处理多帧图像。这些图像被切成一个个小patch,送入视觉编码器变成视觉token(可以理解成图片的“文字”)。一算下来,每次推理可能产生成千上万个token。而这些token,都要喂给后面的大语言模型(LLM)去处理——那计算量,想想都头疼。更要命的是,这成千上万个token里,绝大多数都是没用的信息,比如:时间维度:连续几帧里,背景(道路、建筑)几乎一模一样,只有移动的车辆和行人才是关键的。空间维度:6个摄像头之间有重叠的视野,同一个物体或者同一条马路,被多个摄像头拍到,产生大量重复的token。这种时空冗余,就是自动驾驶VLM的“算力诅咒”。既浪费计算资源,又拖慢推理速度,甚至可能把真正重要的“长尾事件”(比如突然冲出的行人、变红的信号灯)给淹没了。传统的方法怎么剪枝?大部分是“一把抓”:把所有的token混在一起,根据某些规则(比如注意力分数、相似度)丢掉一部分。但这些方法都是为单张图片设计的,根本不知道哪个token来自第几帧、哪个token来自哪个摄像头。结果呢?看下面这张图,传统的剪枝方法(左边)丢了行人,保留了背景;而新方法(右边)则完美地保留了关键的行人。这就是差距。图1:传统剪枝方法在时空驾驶输入上的失效模式以及ST-Prune的改进。那怎么办?难道要重新训练一个针对时空的剪枝模块?不需要!中科院等团队带来的 ST-Prune 给了一个漂亮得令人拍大腿的答案。
ST-Prune:无需训练,即插即用的“双刀流”剪枝方案
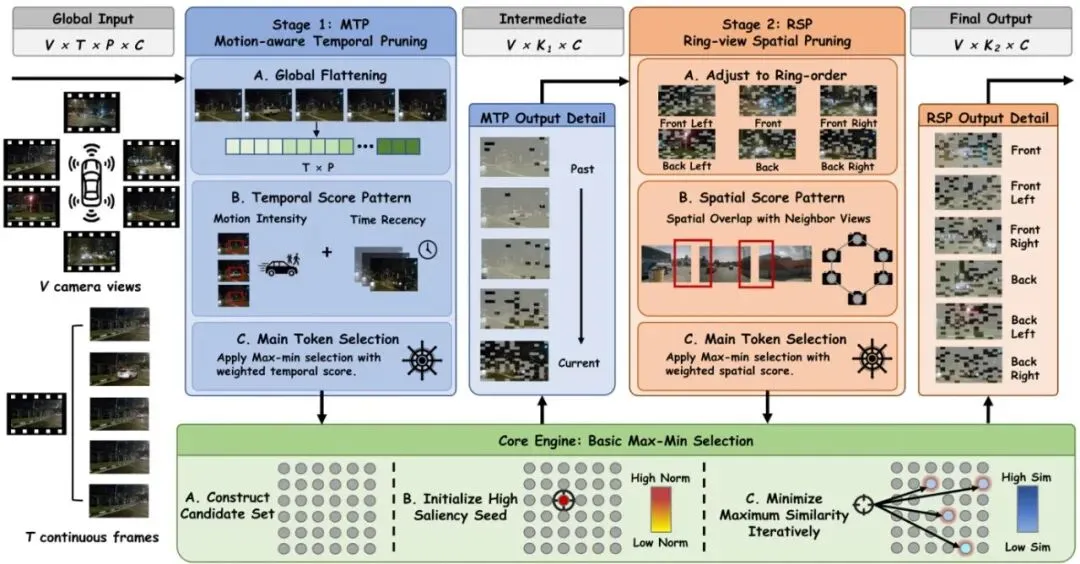
ST-Prune的全称是 Spatio-Temporal Pruning(时空剪枝),由中国科学院大学、中科院自动化所和Carizon团队共同提出。它的最大卖点就是:无需重新训练,即插即用。什么意思?就是你在已有的VLM模型(比如DriveMM)上,什么都不用改,直接插个插件,就能把输入的视觉token数量压缩到原来的1/4甚至1/10,而性能几乎不掉,甚至有些指标还涨了!ST-Prune由两个互补的模块组成,作者戏称为“双刀流”:MTP (Motion-aware Temporal Pruning) —— 运动感知的时间剪枝:专门对付时间维度上的冗余。它会优先保留动态的、最近帧的token,丢掉重复的静态背景。RSP (Ring-view Spatial Pruning) —— 环视空间剪枝:专门对付空间维度上的冗余。它会利用环视摄像头的几何排列(前左、前、前右、后右、后、后左),把相邻摄像头之间重复的token干掉。整个流程如图2所示:输入的 V x T x P 个token(V是视角数,T是帧数,P是每帧的patch数),先经过MTP,在每个视角内独立地压缩到K1个token,再经过RSP,进一步压缩到K2个token。最终每个视角只剩K2个token,总计VxK2个,大大减少了计算量。图2:ST-Prune用于时空token缩减的pipeline。框架通过双阶段选择过程处理多视角、多帧输入:(1) MTP,利用运动和近因先验处理时间冗余;(2) RSP,处理多视角空间几何中的空间冗余。每个阶段都利用迭代的Max-Min Selection引擎,通过优化经过相应时间或空间加权分数增强的多样性目标,来维持一个多样且语义丰富的token集合。这个“双刀流”不仅效果好,而且计算开销极低。整个剪枝过程是纯贪心算法,不需要任何训练数据,直接就能用。下面我们分别看看这两个模块是怎么做到的。MTP模块:看“动”不看“静”,时间维度的智能剪枝
假设你有连续3帧的画面,每帧有7x7=49个patch。如果不做剪枝,3帧总共147个token。MTP的任务就是从这147个里选出最有用的K1个。运动敏感度:如果一个patch在帧与帧之间变化很大(比如行人走过),那它很可能就是动态目标,值得保留。怎么衡量变化?很简单,计算每个patch的特征向量在时间维度上的方差。方差越大,越“运动”。时间近因:越靠近当前帧的token越重要。比如第3帧是最新帧,它的token应该得到更高的保留优先级。怎么建模?用指数函数对帧索引进行加权,帧越新,权重越大。MTP把这两个信号融合成一个统一的 时间重要性分数 Stem(t,p):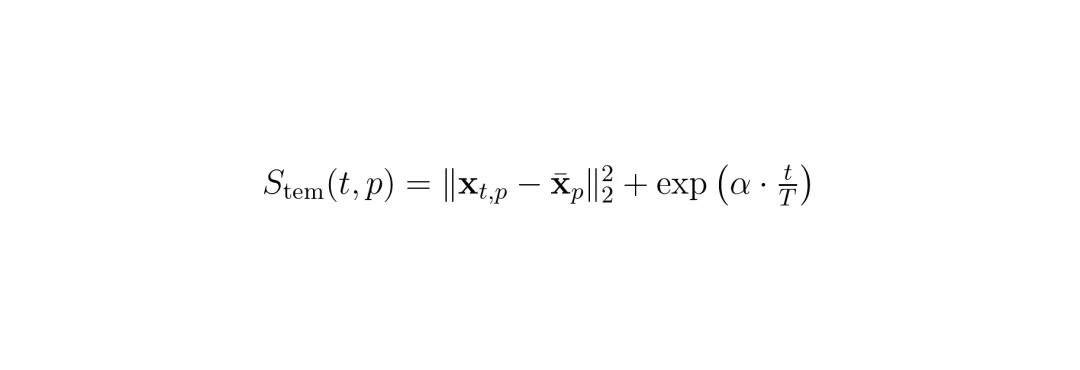 其中,第一项是运动方差(特征向量相对于时间均值的L2距离的平方),第二项是时间近因,α是缩放因子(实验中设为2),t是帧索引(0到T-1)。两个部分独立进行min-max归一化后相加。有了这个分数,MTP在贪心选择种子token时就偏向于高分数token:
其中,第一项是运动方差(特征向量相对于时间均值的L2距离的平方),第二项是时间近因,α是缩放因子(实验中设为2),t是帧索引(0到T-1)。两个部分独立进行min-max归一化后相加。有了这个分数,MTP在贪心选择种子token时就偏向于高分数token: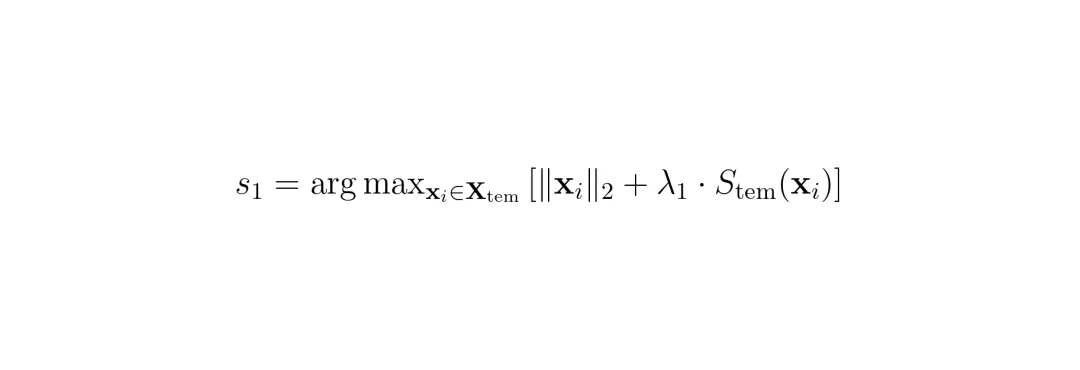 后面每一步,都选一个与已选集合最不相似、同时时间重要性也高的token:
后面每一步,都选一个与已选集合最不相似、同时时间重要性也高的token: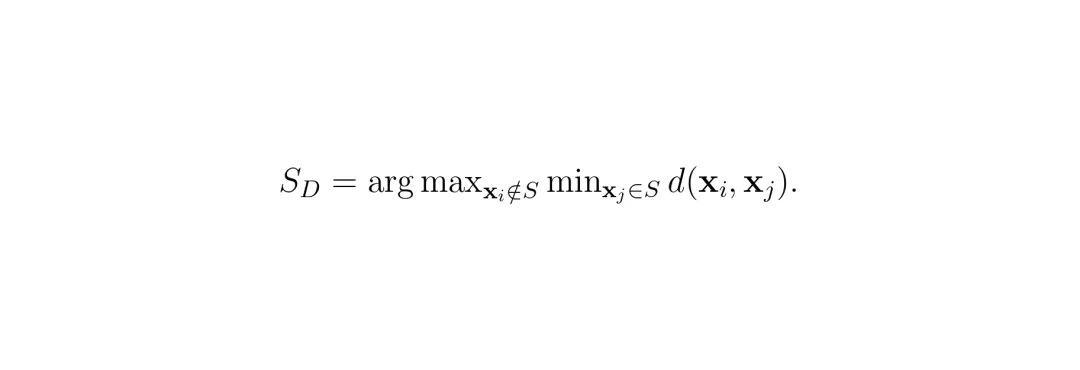
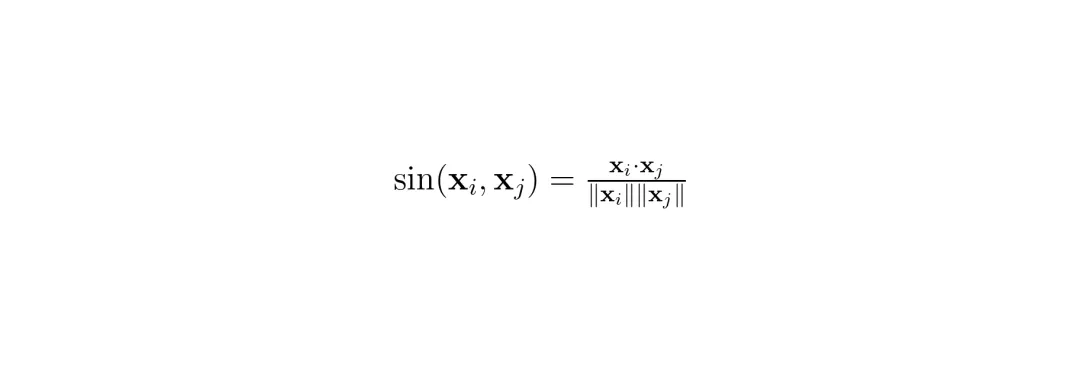 这样,MTP就能从连续的几帧中,挑出那些真正在运动的、最新的token,而把几乎一样的静态背景大片大片地丢掉。这可是传统的单帧剪枝做不到的。
这样,MTP就能从连续的几帧中,挑出那些真正在运动的、最新的token,而把几乎一样的静态背景大片大片地丢掉。这可是传统的单帧剪枝做不到的。RSP模块:击破“环视”冗余,空间维度的几何先验剪枝
MTP处理完时间冗余后,每个视角还剩下K1个token。但是这些token里,仍然包含大量跨视角冗余:相邻摄像头之间重叠的视野,导致同一个物体(比如远处的天桥、路边的栏杆)被多个视角同时拍到,造成重复。RSP模块就是为解决这个问题而生的。它的关键洞察是:利用环视摄像头的物理几何结构。假设6个摄像头按顺序排列:F_L(前左)、F(前)、F_R(前右)、B_R(后右)、B(后)、B_L(后左)。相邻的视图之间(比如前左和前)有很大一部分视野重叠。如果一个patch在前左视图中,它在前右视图中很可能也有一个几乎一样的对应patch。RSP定义了一个双边空间重要性分数 Sspa(v,p),衡量当前视角v中的第p个patch与它左右两个邻居视角中最相似的patch的相似度:这个分数的范围是[0,1]。分数越低,表示这个patch在邻居中能找到非常相似的token,说明它是冗余的,应该优先被丢掉。分数越高,表示这个token在当前视角中是独一无二的,应该被保留。然后,在每个视角内部独立地运行贪心选择,种子token的选择公式为: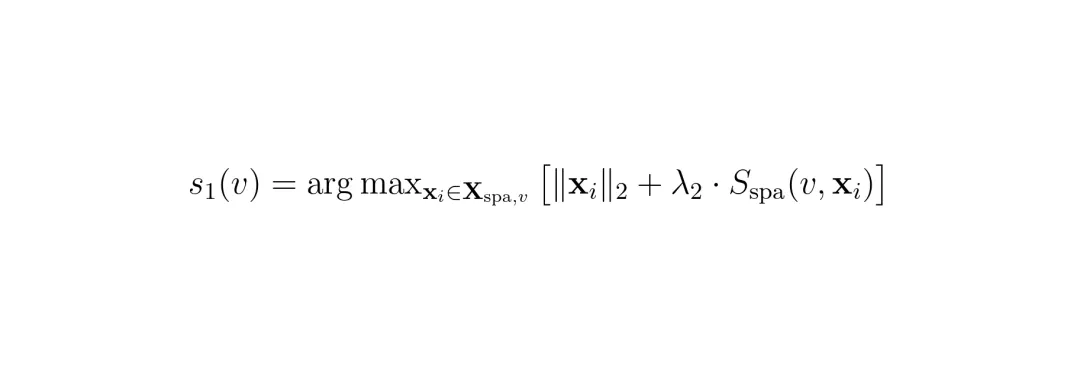 后续的步骤同样结合了最大-最小多样性目标和空间重要性惩罚项:注意,RSP只在相邻视角之间做比较,避免了把在不同视角中但位置不同的相似物体(比如两辆黑车在不同的视角)错误地当作冗余。整个ST-Prune的复杂度分析也表明,额外计算只有RSP的一次性双边相似度计算 O(V·P²),相对于整体的贪心过程来说非常轻量。
后续的步骤同样结合了最大-最小多样性目标和空间重要性惩罚项:注意,RSP只在相邻视角之间做比较,避免了把在不同视角中但位置不同的相似物体(比如两辆黑车在不同的视角)错误地当作冗余。整个ST-Prune的复杂度分析也表明,额外计算只有RSP的一次性双边相似度计算 O(V·P²),相对于整体的贪心过程来说非常轻量。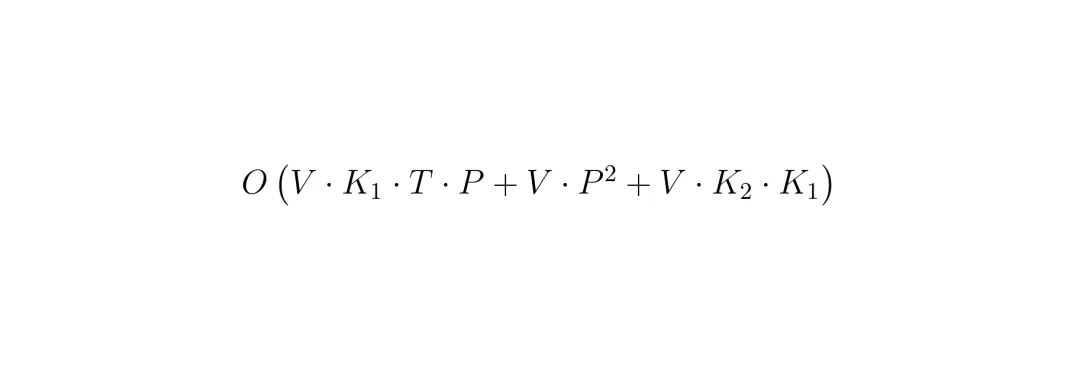 而且,模块的执行顺序是先MTP后RSP,这样RSP只需要在MTP留下的K1个token上计算,进一步降低了计算量。消融实验也证实了这种顺序是最优的。
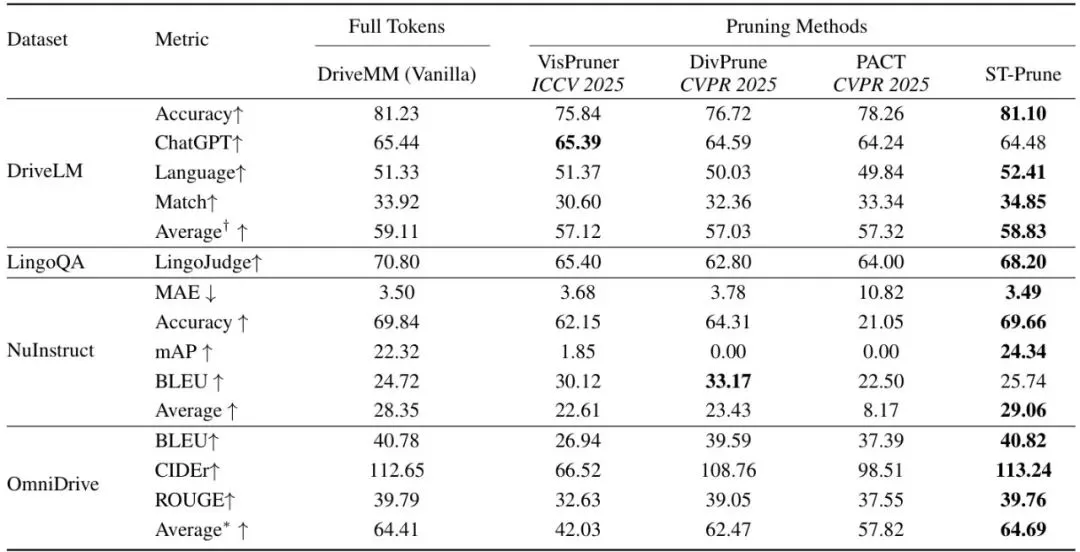
而且,模块的执行顺序是先MTP后RSP,这样RSP只需要在MTP留下的K1个token上计算,进一步降低了计算量。消融实验也证实了这种顺序是最优的。全面超越:四个自动驾驶主流榜单,性能与效率的最佳平衡
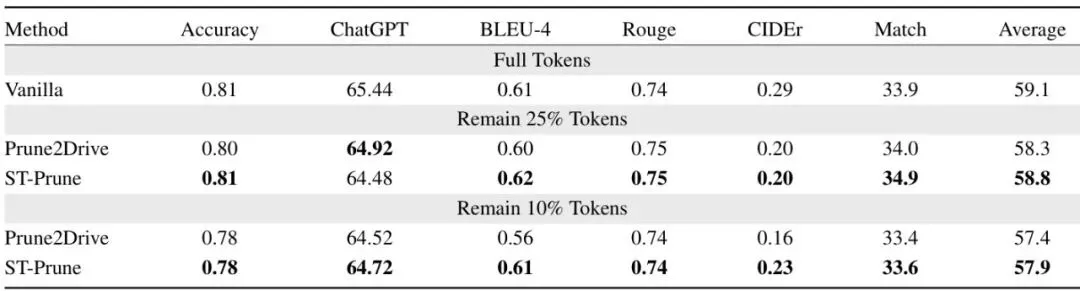
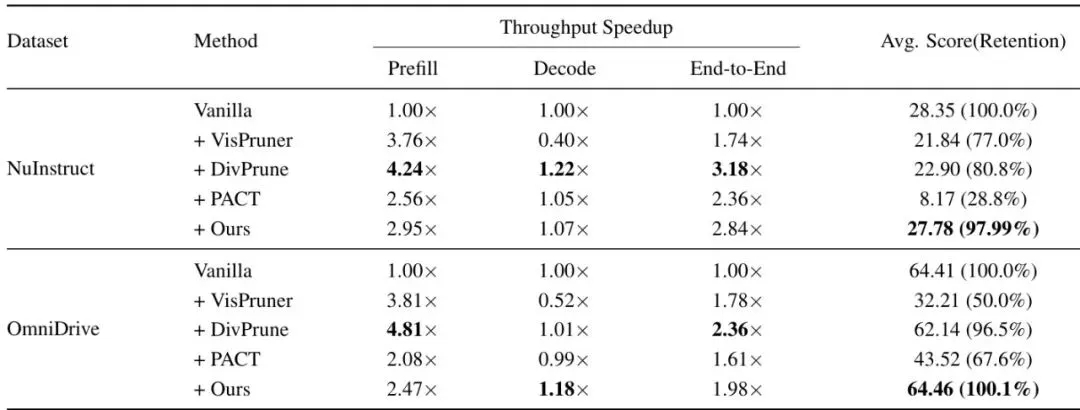
光说理论好不行,咱们来看看实验结果。ST-Prune在四个主流的自动驾驶VLM基准上进行了测试:DriveLM、LingoQA、NuInstruct、OmniDrive,涵盖了感知、预测、规划等任务。对比的方法有VisPruner、DivPrune、PACT等,都是训练-free的剪枝方法。另外还有一个专门的驾驶剪枝方法Prune2Drive。实验在两种token保留比例下进行:保留25%(丢掉75%)和保留10%(丢掉90%)。表1:不同token保留比例下四个基准的性能对比。†表示官方在线评估系统提供的综合分数,*表示(Accuracy + MAP + BLEU - MAE)/4。看这个表格,简直吓人。在保留25% token的情况下,ST-Prune在DriveLM上的Average得分达到了58.83,只比全量baseline(59.11)低了0.28个点,而其他方法都掉到了57左右。在LingoQA上,ST-Prune拿到68.2,比第二名高了近3个点。在NuInstruct上更是离谱:MAE(误差)不升反降,从3.50降到了3.49,而其他方法都涨到了3.68甚至10.82。在OmniDrive上,所有任务指标几乎都是最好的。即使保留10% token(丢掉90%),ST-Prune依然坚挺:DriveLM的Average只降了1个多点,LingoQA依然有63.6,NuInstruct的MAE也仅微涨到3.57。而其他方法在NuInstruct上几乎崩了,Accuracy掉到20%多,MAE飙到十几。这充分说明ST-Prune在面对极端压缩时依然能保留关键信息。表2:与Prune2Drive在不同保留比例下的性能对比。ST-Prune在各项指标上全面超越,且不需要任何训练或搜索。表3:NuInstruct和OmniDrive上的效率对比。所有方法在10% token保留率下评估。吞吐量指标以相对于DriveMM基线的相对加速倍数呈现,1.00表示基线性能。ST-Prune的吞吐量加速比与DivPrune相近(约1.5-1.8倍),但性能却好得多。RSP的额外计算量极小,几乎没有影响推理速度。深入解读原理与消融:为什么时空协同剪枝这么有效?
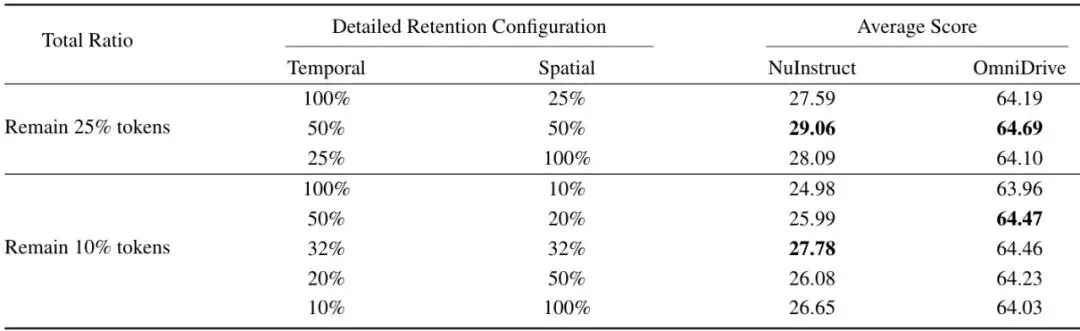
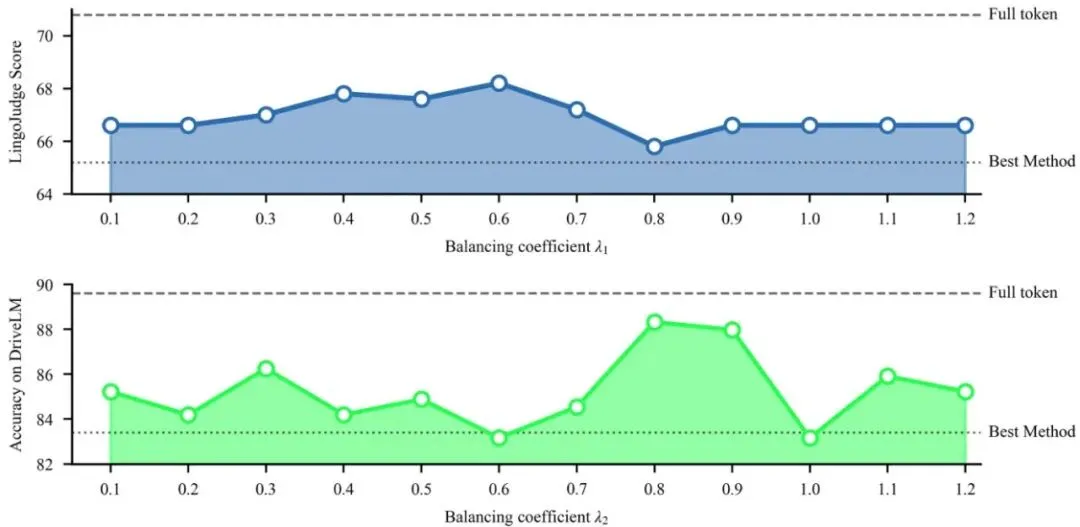
为了搞清楚ST-Prune每个部件的贡献,作者做了一系列消融实验。先看表4:表4:各领域特定评分函数的贡献消融。Average Gain在NuInstruct和OmniDrive上计算。破折号表示该模块组合不适用于该基准(由于单模态输入限制)。只看25%保留的情况。基线(Baseline)就是简单的max-min选择,没有任何时间或空间先验。加入时间分数后(MTP),在NuInstruct上平均增益从8.23提升到12.78,在OmniDrive上从7.99提升到9.13。加入空间分数后(RSP),在NuInstruct(多视角)上从8.23提升到10.38。而两者都加上(ST-Prune),在NuInstruct上达到13.16,在OmniDrive上达到9.70,都是最高。这证明时间先验和空间先验是互补的,两者结合效果最好。表5:固定总token保留率下预算分配的消融(保留25%和10%)。在总保留token数固定的前提下,MTP和RSP之间的预算分配也会影响性能。实验发现,当总保留25%时,将大部分预算(约80%)分配给MTP,少部分(20%)给RSP,效果最好。这符合直觉:时间维度的冗余更严重,需要更多的token来覆盖动态信息;空间维度上,因为相邻视角重叠区域很多,少量token就足以代表那些重复区域。还能继续优化:如果再把MTP和RSP各自内部的超参数λ1和λ2调一调,还能更好。图3展示了这两个超参数的敏感性分析:图3:MTP的λ1(上)和RSP的λ2(下)在LingoQA和DriveLM上的敏感性分析。可以看到,λ1在0.6附近、λ2在0.8附近性能达到峰值,而且曲线比较平缓,说明方法对超参数不太敏感,好调。最后,作者还验证了模块顺序(表6)和插入位置(表7)。先MTP后RSP(时间优先)在计算效率和性能上都略优于先空间后时间,而且在单帧基准(DriveLM)上也能直接应用。插入位置方面,在视觉编码器之后、LLM之前进行剪枝效果最好,与现有方法保持一致。表6:剪枝顺序消融(25%保留率)。时间优先(MTP→RSP)略优于空间优先。表7:剪枝插入位置消融。在projector之后、LLM之前剪枝效果最佳。龙迷三问
ST-Prune的剪枝原理和DivPrune有什么区别?DivPrune是基于最大-最小多样性(max-min diversity)在一个bag里选择最不相似的token。但DivPrune不知道每个token来自哪帧、哪个视角。ST-Prune在DivPrune的基础上,加入了时间和空间的先验分数,使得剪枝不仅考虑多样性,还优先保留动态的、最新的、本视角独特的token。
MTP里的运动分数具体怎么计算的?对于每个patch位置p,计算它在T帧上的特征向量集合的平均值x̄_p。然后对于每一帧t,求它与该平均值的L2距离的平方。这个值越大,说明这个patch在该帧处变化越大(运动越激烈)。同时结合指数近因权重 exp(α * t/T)。两者归一化后相加。
RSP为什么要用双边(左右邻居)而不是单边?因为环视摄像头的重叠是发生在相邻的两个视角之间的。只用左侧邻居可能会导致右侧的重复无法检测,反之亦然。双边同时检查能够更全面地识别跨视角冗余。同时,RSP只在当前视角内部做选择,避免了跨视角的物体混淆。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★★
ST-Prune是第一个专门针对自动驾驶多视角、多帧输入的训练-free剪枝框架,巧妙地将时间运动和空间几何先验融入到贪心选择中,思路新颖,完全符合训练-free、即插即用的需求。实验合理度:★★★★★
在四个主流自动驾驶基准上进行测试,与多种最新训练-free剪枝方法(VisPruner、DivPrune、PACT)以及专门的驾驶剪枝方法Prune2Drive进行了公平对比。消融实验完整,超参数分析详尽,结果令人信服。学术研究价值:★★★★✰
开创性地将时空结构先验引入token剪枝,为后续VLM高效部署提供了新思路。但主要贡献是工程化的剪枝策略,理论深度一般。稳定性:★★★★✰
在保留10% token时性能下降相对明显,尤其是LingoQA和NuInstruct上的分类任务,但依然远好于其他方法。整体稳定性良好,但极端压缩下仍需谨慎。适应性以及泛化能力:★★★★✰
需要多视角和多帧输入才能发挥最大优势。对于单帧单视角场景(如DriveLM),RSP无法使用,只能靠MTP。不过作者也验证了仅使用MTP也能获得提升。总体泛化能力较好,但依赖特定输入结构。硬件需求及成本:★★★★★
训练-free,不需要额外GPU时间训练。推理时增加的计算量极小(一次双边相似度计算),与DivPrune等持平。即使在高压缩比下,加速效果明显。复现难度:★★★★✰
方法不复杂,但依赖DriveMM模型(目前是闭源?论文说DriveMM是唯一公开的满足需求的开源模型)。如果DriveMM不开源,复现需要自己找替代模型。算法本身实现简单,但需要适配具体的数据预处理流程。产品化成熟度:★★★★✰
已经接近可产品化:训练-free、即插即用、效率高。但需要进一步验证在真实车载芯片(如Orin)上的延迟、功耗表现,以及与其他系统模块的集成。在极端压缩(90%)下性能略有下降,可能需要保留更多token以保证安全。可能的问题:依赖DriveMM模型,泛化到其他VLM驾驶模型(如Qwen-based)时可能需要调整超参数。时间先验中的指数近因参数α固定为2,没有做自适应。双边相似度计算中,匹配搜索是暴力穷举,对于更大的token数量(如更多视角)可能成为瓶颈。[1] Sha L, Guo H, Wang T, et al. ST-Prune: Training-Free Spatio-Temporal Token Pruning for Vision-Language Models in Autonomous Driving. arXiv:2604.19145, 2026.[2] DriveMM: All-in-One Large Multimodal Model for Autonomous Driving. (文中引用的baseline模型)[3] DivPrune: Diversity-based Visual Token Pruning. CVPR 2025.[4] VisPruner: Visual Token Pruning via Self-Attention. ICCV 2025.[5] PACT: Pruning and Clustering Tokens. CVPR 2025.*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

这剪枝效率,就问你服不服?想跟我们一起“烧脑”探讨更多自动驾驶黑科技吗?欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:自动驾驶+地点+学校/公司+昵称(如 智驾+上海+中科院+龙哥),根据格式备注,可更快被通过且邀请进群。群里不仅有最新的论文解读,还有行业大咖在线答疑,一起解锁自动驾驶的未来!