开车时,我们需要快速判断:前方行人离我多远?旁边的车会不会超车?3秒后它会出现在哪个位置?这些看似简单的时空推理能力,却是自动驾驶视觉语言模型的“老大难”。近日,一篇聚焦城市驾驶场景时空推理的论文,带来了突破性解决方案——STRIDE-QA数据集,让自动驾驶的“眼睛”和“大脑”终于能精准理解动态交通世界。
论文信息
题目:STRIDE-QA: Visual Question Answering Dataset for Spatiotemporal Reasoning in Urban Driving Scenes
STRIDE-QA:面向城市驾驶场景时空推理的视觉问答数据集
作者:Keishi Ishihara, Kento Sasaki, Tsubasa Takahashi, Daiki Shiono, Yu Yamaguchi
为什么自动驾驶需要“时空推理”能力?
当下的视觉语言模型,大多靠静态网络图片训练。它们能识别“这是一辆车”,却答不出“这辆车3秒后离我多远”。自动驾驶面对的是瞬息万变的城市道路:东京的拥堵路口、突然窜出的行人、抢道的非机动车……没有精准的空间定位和短期运动预测,安全驾驶就是空谈。
现有驾驶场景VQA数据集要么缺3D空间信息,要么只关注单帧画面,没法兼顾“以对象为中心”(比如两辆车的相对位置)和“以自我为中心”(比如自车与行人的距离)的推理,更别提预测未来几秒的动态。这就像让驾驶员只看一张照片开车,风险可想而知。
STRIDE-QA:给自动驾驶装上“时空推理大脑”
这篇论文的核心贡献,就是打造了STRIDE-QA——首个针对城市驾驶场景的大规模时空推理VQA数据集。它不是简单的图片+问题组合,而是真正贴合真实驾驶的“动态知识库”。
先看核心数据:够大、够真实
数据集基于东京100小时的真实驾驶数据构建,覆盖市中心、居民区、郊区等复杂场景。包含27万帧图像、26.8万个独特物体对,以及1600万个问答对——相当于给模型喂了海量的“驾驶经验”。
采集数据的车辆配备了64通道激光雷达、6个全景摄像头,还有惯性测量单元和卫星定位设备。传感器每秒采集2帧数据,360°覆盖周边环境,连车辆的速度、航向角都精准记录,为后续标注打下了扎实基础。
三大核心任务:直击自动驾驶推理痛点
论文没有泛泛做问答,而是针对性设计了三类核心任务,精准匹配自动驾驶的实际需求:
- 以对象为中心的空间问答:关注道路上两个物体的空间关系。比如“这辆车和那个行人相距多远?”“公交车在卡车的左侧还是右侧?”,考验模型对物体间相对位置的判断。
- 以自我为中心的空间问答:聚焦自车与周边物体的关系。比如“前方行人离自车有多少米?”“摩托车在自车的几点钟方向?”,这是自动驾驶决策的核心依据。
- 以自我为中心的时空问答:最难也最关键的任务——预测未来。模型需要根据4帧历史画面,回答“3秒后,那辆自行车离自车多远?”“自车和前方车辆的速度分别是多少?”,直接对接驾驶规划需求。
下图清晰展示了三类任务的区别,从静态空间关系到动态时间预测,层层递进: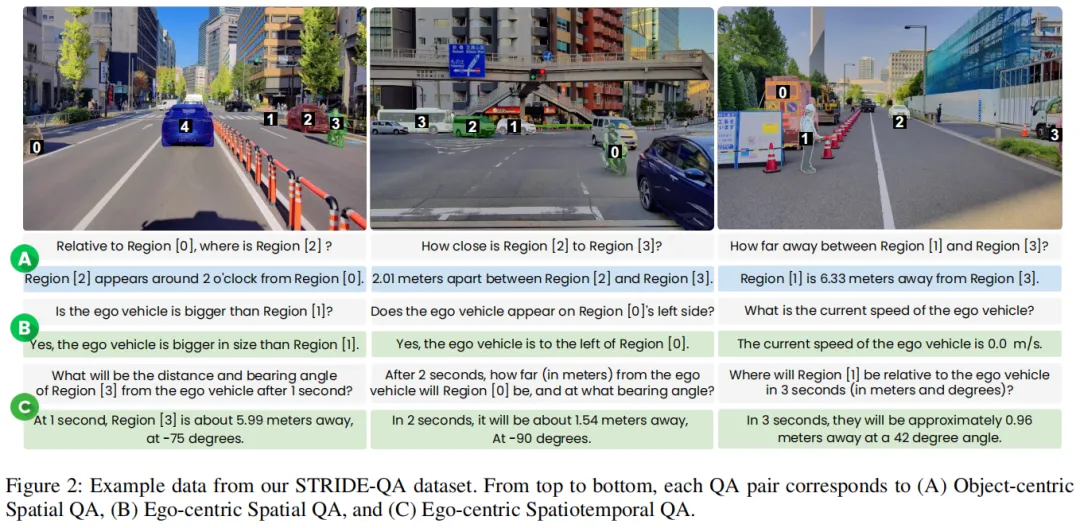
全自动标注流水线:高效又精准
要生成1600万个高质量问答对,人工标注根本不现实。论文设计了一套模块化的全自动标注流程,把先进的3D检测、目标跟踪、实例分割技术整合起来,让机器自己完成“标注-提问-作答”全流程。
整个流程像一条精密的生产线(如下图),包含7个核心步骤:
- 关键帧采样:选定时间锚点,为每个问题划定时间范围;
- 3D目标检测:用BEVFusion精准识别每个物体的3D位置、大小;
- 多目标跟踪:靠PubTracker给每个物体分配唯一ID,跟踪运动轨迹;
- 语义分割:用SAM 2.1生成像素级分割掩码,锁定物体位置;
这套流程确保了所有标注“物理一致、时间对齐”,给模型训练提供了精准的“标准答案”。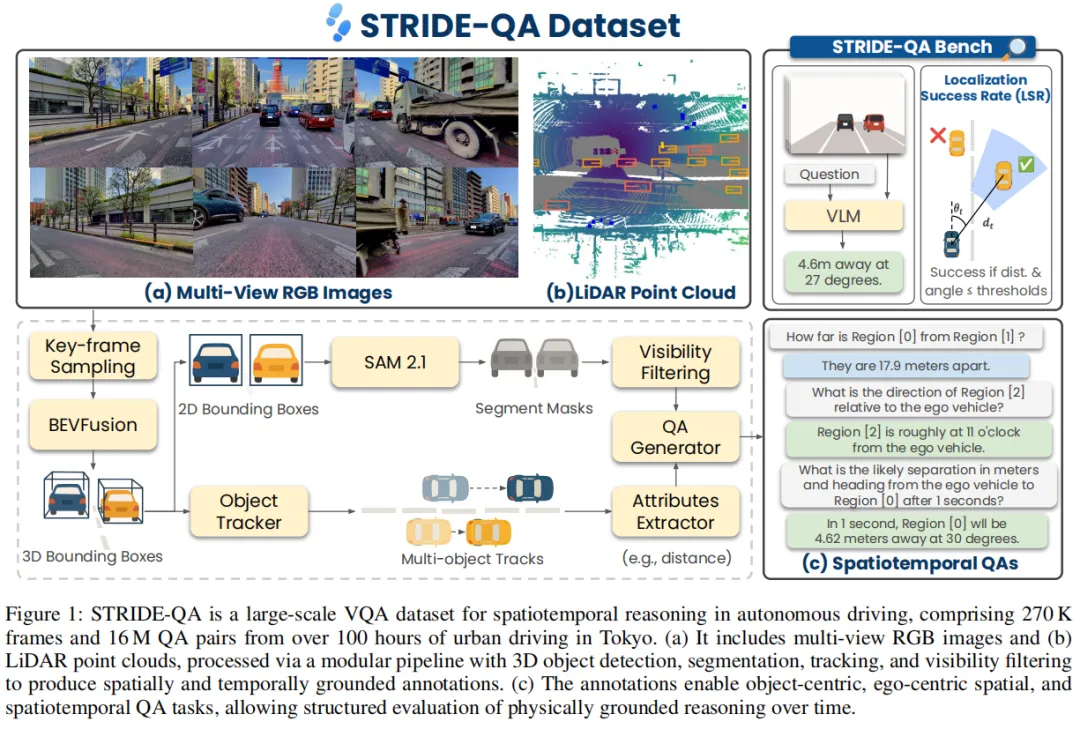
实测结果:性能提升数十倍,效果立竿见影
论文用多个主流视觉语言模型做了测试,结果让人眼前一亮:
空间推理能力大幅提升
在SpatialRGPT-Bench室外分割测试中,基于STRIDE-QA微调的模型表现远超基础版本:
- STRIDE-Qwen2.5-VL-7B在定量以对象为中心的问答中,准确率从12.8%飙升到61.5%,提升了4.8倍;
- 以自我为中心的定量问答,准确率从29.3%涨到70.3%,足足提升41个百分点。
哪怕是GPT-4o这类顶尖通用模型,在驾驶场景的细分任务中,也远不如针对性微调的模型——通用模型的“通用”,在专业场景里反而成了短板。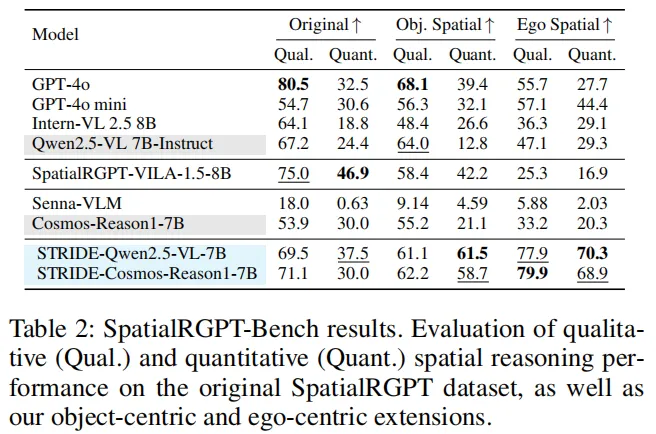
时空推理:从“接近零”到“能预测”
在STRIDE-QA专属基准测试中,差距更明显:
- 所有通用基线模型的时间定位一致性(TLC)几乎为0,根本没法稳定预测物体的动态;
- 微调后的STRIDE-Qwen2.5-VL-7B表现惊人:
- t=0秒时,空间定位成功率(LSR)达96.3%,是基线的96倍;
- t=3秒时,LSR仍有38.9%,是基线的39倍;
- 平均定位成功率(MLSR)55.0%,时间定位一致性(TLC)28.4%——看似不高,但对比接近零的基线,已是质的飞跃。
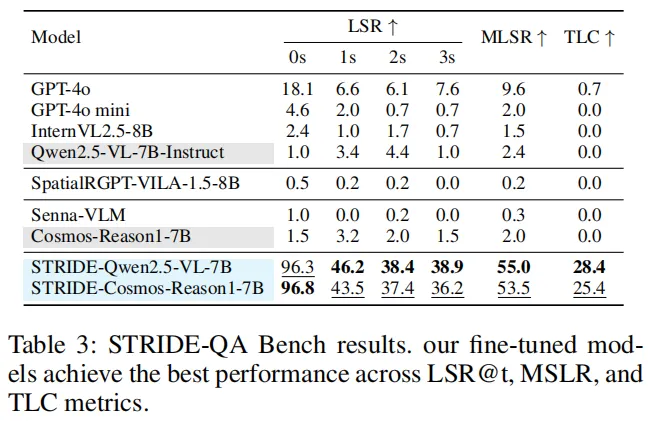 表3
表3下图能直观看到模型的预测效果:微调后的模型能精准定位物体,生成密集、连续的预测;而基线模型只能胡乱猜测,完全脱离视觉上下文。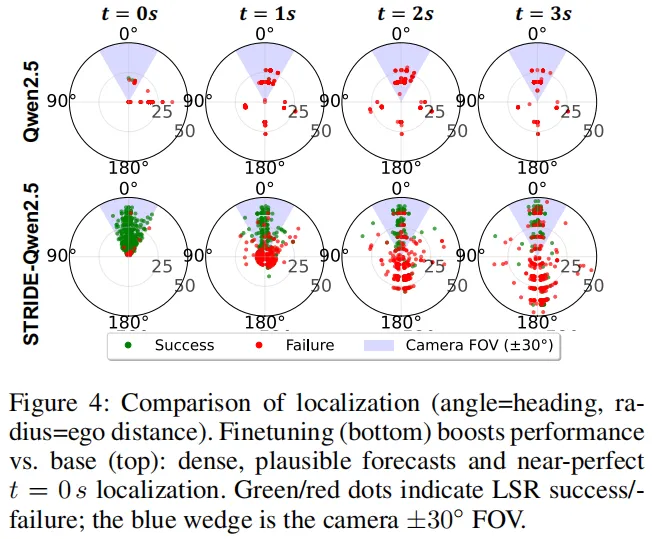
还需突破的难点:视场外推理是最大挑战
当然,论文也坦诚指出了当前的不足。分析发现,模型在预测时,最大的失败原因是“视场外推理”:
- 当目标物体留在摄像头视野内(比如和自车保持同速的车辆),模型的准确率缓慢下降;
- 当物体离开视野(比如超车的车辆、对向行驶的行人),准确率断崖式下跌。
下图清晰展示了不同场景下的性能变化,也指明了未来的研究方向——整合多摄像头信息,才能解决单视角的局限。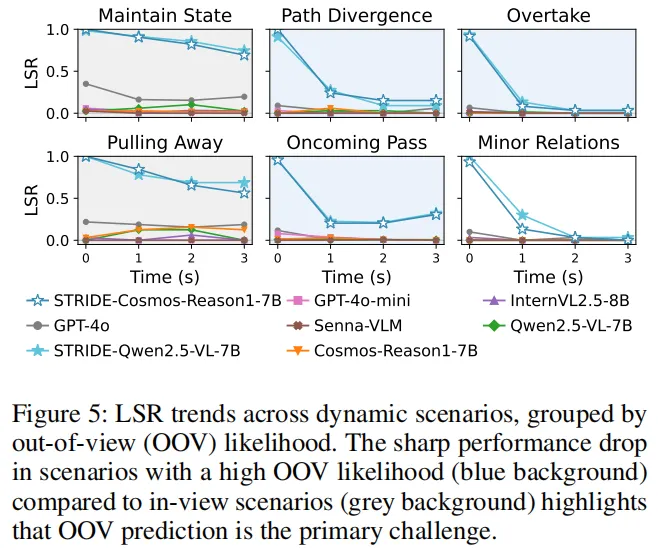
总结:给自动驾驶的“智能”打下坚实基础
STRIDE-QA的出现,填补了自动驾驶视觉语言模型时空推理的关键空白。它不只是一个数据集,更是一套“训练+评估”的完整体系:
从实际应用角度看,这意味着自动驾驶系统终于能像人类驾驶员一样,不仅“看见”物体,还能“理解”物体的位置、运动趋势,甚至“预测”几秒后的状态。虽然目前在视场外推理等方面还有不足,但这篇论文已经为安全关键的自主驾驶系统,铺好了通往更可靠、更智能的道路。
未来,随着多摄像头融合、更精细的动态建模等技术的加入,自动驾驶的“时空推理”能力还会持续提升。而STRIDE-QA,就是这场技术突破的重要起点。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
