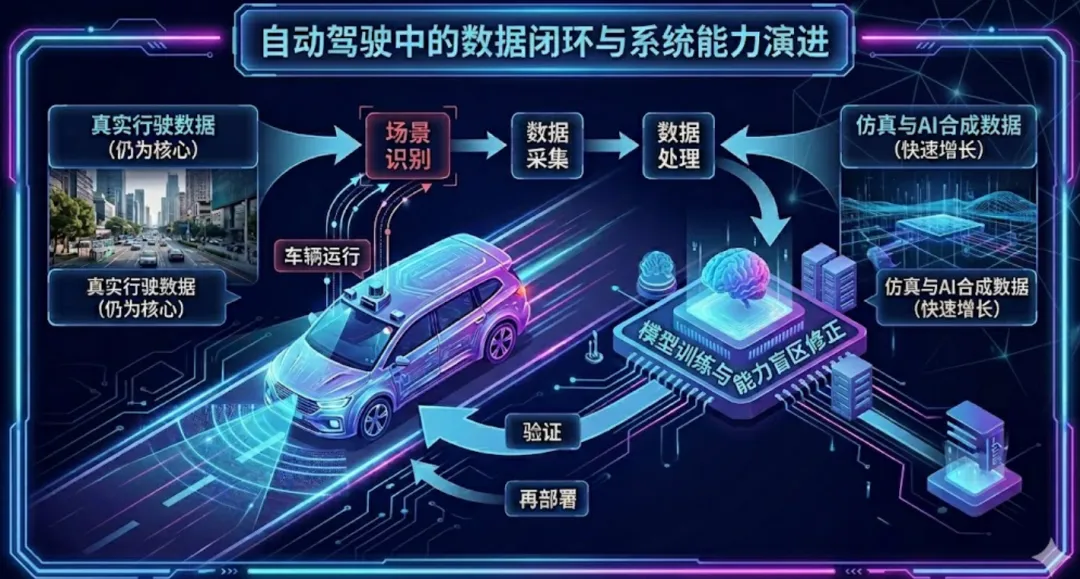
在自动驾驶领域,"数据闭环"是个被反复提及的词,但它究竟在解决什么问题,很多人并不清楚。
根本原因在于:自动驾驶系统不可能在第一次设计时就覆盖真实世界。
道路环境高度开放、不可穷举,系统能力只能通过持续运行和修正逐步完善。这套持续修正的机制,就是数据闭环。
从工程实现来看,数据闭环包含以下几个环节:
车辆运行 | → | 场景识别 | → | 数据采集 | → | 数据处理 | → | 模型训练 | → | 验证 | → | 再部署 |
数据只是手段,真正要修正的是系统在现实中暴露出的能力盲区——场景覆盖的盲区、模型能力的不足、工程假设与现实的偏差。
1. 真实行驶数据仍是核心来源
目前行业内,80%以上的训练数据仍来自真实道路行驶(注:此数据为行业估算,非官方统计),主要包括测试车队采集数据、量产车辆在限定条件下回传的数据,以及问题场景触发后的定向采集数据。
真实数据的好处是包含真实噪声和环境不确定性,能暴露系统在现实中的失败模式;但成本高、长尾场景出现概率低、数据分布不可控,这些问题同样明显。
2. 仿真与AI合成数据正在快速增长
为弥补真实数据不足,行业普遍引入仿真环境生成数据,以及AI合成的极端或罕见场景。目前行业的普遍做法是:真实数据用于发现问题,合成数据用于放大问题、补齐覆盖。但合成数据无法替代真实数据,只能作为补充。
根据佐思汽研《2025年中国智能辅助驾驶数据闭环研究报告》,2023年至2025年,合成数据在训练数据中的占比从20%—30%升至50%以上,已成为填补长尾场景的核心手段。
案例:理想汽车的成本变化 2023年全年实车有效测试里程约157万公里,每公里成本约18元。到2025年上半年,总测试里程达4000万公里,其中实车仅2万公里,合成数据3800万公里,平均每公里成本降至约5毛钱,且测试场景可举一反三、完全复测。 数据来源:理想汽车郎咸朋公开介绍 |
在实践中,不少团队积累了PB级的数据,系统能力却难以持续提升。根本原因在于:数据采集缺乏问题导向,无法精准定位模型的失败场景,数据、算法和工程流程彼此割裂,模型更新也缺乏有效的验证机制。
真正有效的闭环,是从问题出发去采集数据,而不是先堆数据再反推问题出在哪里。 |
从行业整体看,头部自动驾驶公司已形成相对完整的数据闭环体系,数据采集越来越精细化、事件化,回传数据比例逐步降低,但有效数据密度提高,仿真与真实数据协同使用成为主流。
以小鹏为例,其自建的云端模型工厂2025年算力储备达10 EFLOPS,全链路迭代周期缩短至平均5天,支持从云端预训练到车端模型部署的快速闭环。(数据来源:小鹏汽车公开信息)
对于多数企业而言,数据闭环仍是能力差距的主要来源之一。
数据闭环并不意味着系统不会出错,但它让系统具备了持续发现自身盲区的能力,让能力提升有了工程上的可控性,也让自动驾驶从"版本迭代"逐步走向"能力演进"。
自动驾驶的数据闭环,本质是一种持续修正系统认知的工程机制,连接了真实世界与模型能力。
没有数据闭环,系统能力很难突破演示阶段;有了它,自动驾驶才有长期进化的基础。 |
数据来源说明
本文引用数据来源包括:佐思汽研《2025年中国智能辅助驾驶数据闭环研究报告》、理想汽车郎咸朋公开介绍、小鹏汽车公开信息。其中"80%以上训练数据来自真实道路"为行业估算数据,非官方统计,仅供参考。